ВУЗ: Смоленский областной казачий институт промышленных технологий и бизнеса
Категория: Лекция
Дисциплина: Моделирование систем
Добавлен: 19.11.2018
Просмотров: 600
Скачиваний: 15
Этапы корреляционно-регрессионного анализа данных
Полученные в результате каких-либо исследований данные почти всегда представлены в виде таблиц. Числовые данные, содержащиеся в таблицах, обычно имеют между собой явные (известные) или неявные (скрытые) связи.
Явно связаны показатели, которые получены методами прямого счета, т. е. вычислены по заранее известным формулам. Например, проценты выполнения плана, уровни, удельные веса, отклонения в сумме, отклонения в процентах, темпы роста, темпы прироста, индексы и т. д.
Связи же второго типа заранее неизвестны. Однако люди должны уметь объяснять и предсказывать (прогнозировать) сложные явления, поведение объектов или систем для того, чтобы управлять ими. Поэтому специалисты с помощью наблюдений стремятся выявить скрытые зависимости и выразить их в виде формул, т. е. математически смоделировать явления или процессы. Одну из таких возможностей предоставляет корреляционно-регрессионный анализ.
Пользуясь методами корреляционно-регрессионного анализа, аналитики измеряют тесноту связей показателей с помощью коэффициента корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые, умеренные и др.) и различные по направлению (прямые, обратные). Если связи окажутся существенными, то целесообразно будет найти их математическое выражение в виде регрессионной модели и оценить статистическую значимость модели. В экономике значимое уравнение используется, как правило, для прогнозирования изучаемого явления или показателя.
Корреляционно-регрессионный анализ связей между переменными показывает, как один набор переменных (X) может влиять на другой набор (У). Таким образом, регрессионные вычисления и подбор хороших уравнений - это ценный, универсальный исследовательский инструмент в самых разнообразных отраслях деловой и научной деятельности (маркетинг, торговля, медицина, техника и т. д.).
Рассмотрим этапы корреляционно-регрессионного анализа данных.
Нулевой этап - это сбор данных. Как в строительстве нулевой цикл обеспечивает фундамент будущему зданию, так в корреляционно-регрессионном анализе решающую роль играет качество данных. Сбор данных создает фундамент прогнозам. Поэтому имеется ряд требований и правил, которые следует соблюдать при сборе данных.
Данные должны быть наблюдаемыми, т. е. полученными в результате замера, а не расчета. Наблюдения следует спланировать. Чем больше неодинаковых (не повторяющихся) данных, и чем они однороднее, тем лучше получится уравнение, если связи существенны. Подозрительные данные могут быть вызваны ошибками наблюдений и экспериментов.
Первый этап - корреляционный анализ. Его цель - определить характер связи (прямая, обратная) и силу связи (связь отсутствует, связь слабая, умеренная, заметная, сильная, весьма сильная, полная связь). Корреляционный анализ создает информацию о характере и степени выраженности связи (коэффициент корреляции), которая используется для отбора существенных факторов, а также для планирования эффективной последовательности расчета параметров регрессионных уравнений. При одном факторе вычисляют коэффициент корреляции, а при наличии нескольких факторов строят корреляционную матрицу, из которой выясняют два вида связей: связи зависимой переменной с независимыми, связи между самими независимыми.
Для определения тесноты связи результативного признака у с определяющими его х1, х2, х3 и влияния определяющих признаков друг на друга вычисляются парные коэффициенты корреляции ryx1, ryx2, ryx3, rx1x2, rx1x3, rx2x3.
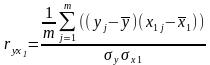 , где
, где
 -
выборочное среднее значение переменных
х1, у
по всем группам значений переменных,
-
выборочное среднее значение переменных
х1, у
по всем группам значений переменных,
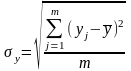 ,
,
 ,
где m – количество групп
исследуемых изделий, размерность
выборки. Аналогично рассчитываются
значения ryx2,
ryx3
по приведённым выше формулам, только
переменная х1
заменяется на х2
или на х3 соответственно.
Аналогично рассчитываются коэффициенты
корреляции определяющих признаков друг
на друга:
,
где m – количество групп
исследуемых изделий, размерность
выборки. Аналогично рассчитываются
значения ryx2,
ryx3
по приведённым выше формулам, только
переменная х1
заменяется на х2
или на х3 соответственно.
Аналогично рассчитываются коэффициенты
корреляции определяющих признаков друг
на друга:
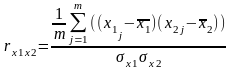
,
где
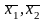 -
выборочное среднее значение переменных
х1,
x2 по
всем группам значений переменных,
-
выборочное среднее значение переменных
х1,
x2 по
всем группам значений переменных,
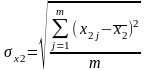 ,
,
где m – количество групп
исследуемых изделий, размерность
выборки.
,
,
где m – количество групп
исследуемых изделий, размерность
выборки.
В библиотеке функций табличного процессора MS Excel есть статистическая функция КОРРЕЛ() для вычисления парных коэффициентов корреляции.
Второй этап - расчет параметров и построение регрессионных моделей. Здесь стремятся отыскать наиболее точную меру выявленной связи, для того чтобы можно было прогнозировать, предсказывать значения зависимой величины Y, если будут известны значения независимых величин Х1, Х2, …, Хn. Эту меру можно выразить математической моделью линейной множественной регрессионной зависимости: у = а0 + b1x1 + b2x2 + … + bn xn.
Для
нахождения коэффициентов
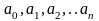
 используют
метод наименьших квадратов.
Смысл метода в том, что
строят функционал:
используют
метод наименьших квадратов.
Смысл метода в том, что
строят функционал:
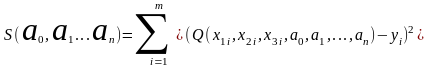 , затем
он минимизируется
, затем
он минимизируется
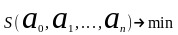 .
.
Для решения поставленной задачи составляется система уравнений:
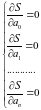 , что
эквивалентно
, что
эквивалентно
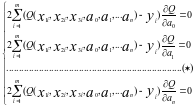
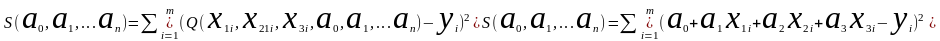
Для
система
уравнений
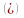 имеет вид:
имеет вид:
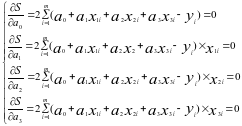
После выполнения несложных эквивалентных преобразований получаем систему уравнений:

Решением данной системы являются коэффициенты уравнения регрессии а0, а1, а2, а3. Их значения можно получить, например, методом Крамера.
Осуществление второго этапа сильно зависит от выводов, которые получены при анализе корреляционной матрицы. Можно значительно ускорить проведение регрессионного анализа и снизить затраты на исследование, если принять правильную стратегию поиска наилучшего уравнения. Для этого необходимо знать основные и наиболее эффективные методы поиска наилучшего уравнения.
После получения каждого варианта уравнения обязательной процедурой является оценка его статистической значимости, поскольку главная цель - получить уравнение наивысшей значимости, поэтому второй этап корреляционно-регрессионного анализа неразрывно связан с третьим. Однако в связи с тем, что расчеты выполняет ЭВМ, а решение на основе оценки значимости уравнения принимает исследователь (принять или отбросить уравнение), условно можно выделить третий этап этой человеко-машинной технологии как интеллектуальный немашинный этап, для которого почти все данные по оценке значимости уравнения подготавливает ЭВМ.

На
третьем этапе выясняют
статистическую значимость, т. е.
пригодность постулируемой модели для
использования ее в целях предсказания
значений отклика. Задачей третьего
этапа построения регрессионных моделей
является вычисление коэффициента
детерминации или коэффициента
множественной корреляции, на основании
которого можно сделать заключение о
значимости построенной регрессионной
модели и возможности её дальнейшего
использования для объяснения и
анализа процессов, проявляющихся, в
данной задаче. Коэффициент множественной
корреляции определяется по формуле:
Rxy =
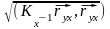 ,
где Kx- 1
– обратная матрица корреляции, а матрица
корреляции для трёх факторных признаков
x1, x2
имеет вид:
,
где Kx- 1
– обратная матрица корреляции, а матрица
корреляции для трёх факторных признаков
x1, x2
имеет вид:
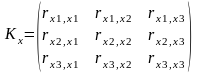 .
Причём корреляционная
матрица любой размерности будет
симметричной, так как rxiхj
= rxjхi.
Для трёх факторных признаков вектор
.
Причём корреляционная
матрица любой размерности будет
симметричной, так как rxiхj
= rxjхi.
Для трёх факторных признаков вектор
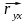 =
=
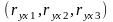 -
вектор коэффициентов парной регрессии
результативного признака Y
и факторных признаков X1,
X2,
X3.
-
вектор коэффициентов парной регрессии
результативного признака Y
и факторных признаков X1,
X2,
X3.
На этом этапе исключительно важную роль играют коэффициент детерминации и F-критерий значимости регрессии. Rxy2 = D = Rxy Squared - коэффициент детерминации - это квадрат множественного коэффициента корреляции между наблюдаемым значением Y и его теоретическим значением, вычисленным на основе модели с определенным набором факторов. Коэффициент детерминации измеряет действительность модели. Он может принимать значения от 0 до 1. Эта величина особенно полезна для сравнения ряда различных моделей и выбора наилучшей модели.
На четвертом этапе корреляционно-регрессионного исследования, если полученная модель статистически значима, ее применяют для прогнозирования (предсказания), управления или объяснения.
Влияние отдельных факторов в многофакторных моделях может быть охарактеризовано с помощью частных коэффициентов эластичности, которые в случае линейной трёхфакторной модели рассчитываются по формулам:
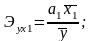
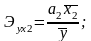
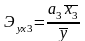 .
Частные коэффициенты эластичности
показывают на сколько процентов изменится
результативный признак, если значение
одного из факторных признаков изменится
на 1 %, а значения других признаков
останутся неизменными.
.
Частные коэффициенты эластичности
показывают на сколько процентов изменится
результативный признак, если значение
одного из факторных признаков изменится
на 1 %, а значения других признаков
останутся неизменными.
Если же обнаружена незначимость, то модель отвергают, предполагая, что истинной окажется какая-то другая форма связи, которую надо поискать. Например, с самого начала работы (как бы по умолчанию) строилась и проверялась линейная регрессионная модель. Незначимость ее служит основанием для того, чтобы отвергнуть только линейную форму модели. Возможно, что более подходящей будет нелинейная форма модели.
Для выполнения всех перечисленных выше этапов корреляционно - регрессионного анализа данных можно средствами MS Excel построить имитационную модель. Алгоритм разработки имитационной модели можно представить следующим образом.
1) Оформление главного листа приложения. Размещения на нём названия приложения и кнопок для вызова необходимых модулей. На главном листе содержатся следующие кнопки «Вспомогательные расчёты», «Расчёт коэффициентов корреляции», «Расчёт коэффициентов модели», «Оценка значимости уравнения», «Построение графика».
2) Разработка макроса «Oforml» для оформления базовой таблицы данных для проведения корреляционно – регрессионного анализа. Опция «Сервис», закладка «Макрос», закладка «Начать запись». Осуществляется оформление границ таблицы, ввод наименований столбцов (зависимой и независимых переменных), наименований строк таблицы. Здесь же производятся вспомогательные расчёты, связанные с перемножением столбцов исходных данных, нахождением их сумм. Выполнение этих расчётов требуется для нахождения значений коэффициентов будущей системы нормальных уравнений. После завершения всех указанных действий нажимается кнопка «Остановить запись». Макрос считается созданным, его можно вызывать по нажатию кнопки «Вспомогательные расчёты» (см. рис. 1).
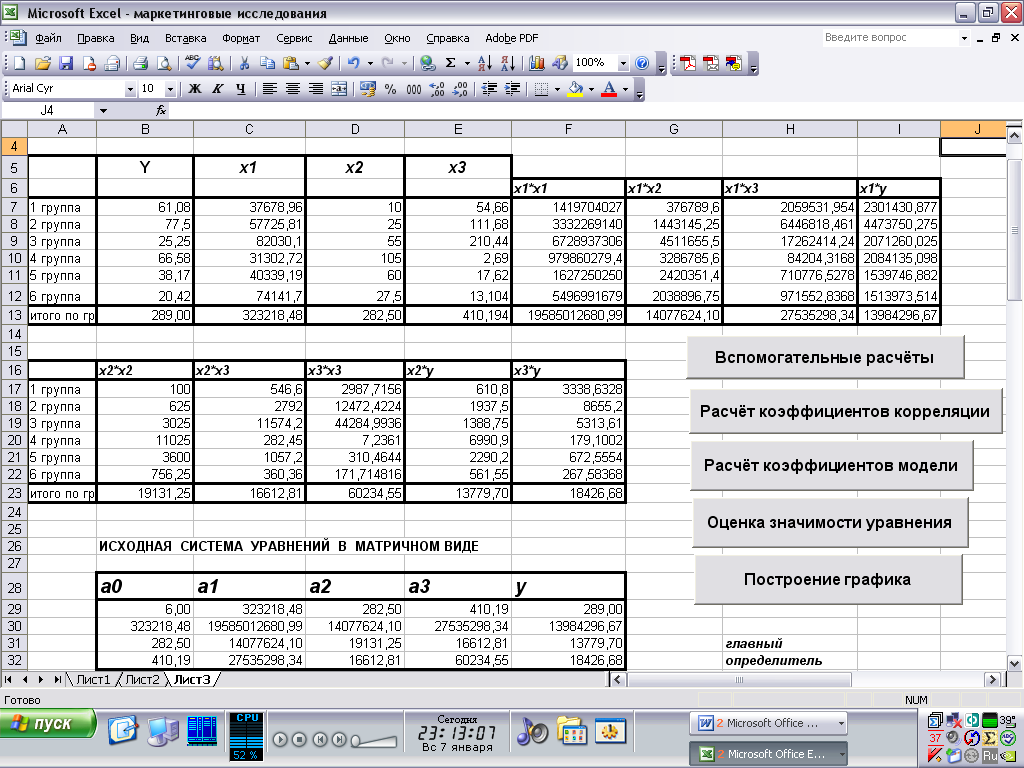
Рис. 1. Главный лист приложения на VBA for Excel для проведения корреляционно - регрессионного анализа данных
3) Запись макроса
“Rasch_kor”
для расчёта коэффициентов корреляции.
Опция «Сервис», закладка «Макрос»,
закладка «Начать запись». С помощью
функции КОРЕЛЛ() табличного процессора
MS Excel'2000 по формулам вида:
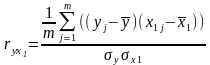 (вместо y и x1
могут быть использованы переменные xi xj)
рассчитываются парные коэффициенты
факторных признаков и результирующего
и каждого из факторных признаков. После
окончания ввода формул для расчёта
парных коэффициентов корреляции
нажимается кнопка «Остановить запись».
Макрос считается записанным и назначается
кнопке «Расчёт коэффициентов корреляции»,
размещённой на главном листе приложения.
(вместо y и x1
могут быть использованы переменные xi xj)
рассчитываются парные коэффициенты
факторных признаков и результирующего
и каждого из факторных признаков. После
окончания ввода формул для расчёта
парных коэффициентов корреляции
нажимается кнопка «Остановить запись».
Макрос считается записанным и назначается
кнопке «Расчёт коэффициентов корреляции»,
размещённой на главном листе приложения.
4) Запись макроса
«Rasch_koef»,
который осуществляет расчёт коэффициентов
регрессионного уравнения линейного
вида. Запись макроса производится из
опции «Сервис», закладки «Макрос»,
закладки «Начать запись». Далее с
применением стандартной функции MS
Excel’2000 МОПРЕД() осуществляется
расчёт главного и остальных определителей,
соответствующих системе линейных
уравнений, полученной на основе метода
наименьших квадратов, из которой будут
определяться коэффициенты уравнения
регрессии с помощью метода Крамера.
После выполнения расчётов определителей
системы линейных уравнений выполняется
расчёт коэффициентов регрессионного
уравнения по формуле:
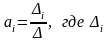 - определитель, соответствующий i – й
переменной, -
главный определитель системы. По
заверешении всех указанных действий
необходимо остановить запись макроса
нажатием кнопки «Остановить запись».
Созданный макрос назначается кнопке
«Расчёт коэффициентов модели», размещённой
на главном листе приложения.
- определитель, соответствующий i – й
переменной, -
главный определитель системы. По
заверешении всех указанных действий
необходимо остановить запись макроса
нажатием кнопки «Остановить запись».
Созданный макрос назначается кнопке
«Расчёт коэффициентов модели», размещённой
на главном листе приложения.
5) Запись макроса
«Koef_Det»,
который позволяет вычислить множественный
коэффициент корреляции и коэффициент
детерминации по формулам: Rxy
= -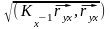 -
коэффициент множественной корреляции,
где Kx-
1 – обратная матрица корреляции;
Rxy2
= D – коэффициент
детерминации. Обратная матрица корреляции
вычисляется с помощью функции MS
Excel’2010 МОБР(). Запись
макроса осуществляется из опции «Сервис»,
закладки «Макрос», закладки «Начать
запись». После ввода расчётных формул
для коэффициентов множественной
корреляции и детерминации необходимо
остановить запись макроса нажатием
кнопки «Остановить запись». Созданный
макрос назначается кнопке «Оценка
значимости уравнения», размещённой на
главном листе приложения.
-
коэффициент множественной корреляции,
где Kx-
1 – обратная матрица корреляции;
Rxy2
= D – коэффициент
детерминации. Обратная матрица корреляции
вычисляется с помощью функции MS
Excel’2010 МОБР(). Запись
макроса осуществляется из опции «Сервис»,
закладки «Макрос», закладки «Начать
запись». После ввода расчётных формул
для коэффициентов множественной
корреляции и детерминации необходимо
остановить запись макроса нажатием
кнопки «Остановить запись». Созданный
макрос назначается кнопке «Оценка
значимости уравнения», размещённой на
главном листе приложения.
6) Запись макроса «Grafik», позволяющего построить график полученного уравнения и исходные значения результирующего в одной системе координат. Запись макроса осуществляется из опции «Сервис», закладки «Макрос», закладки «Начать запись». После этого из опции «Вставка», закладки «Диаграмма» осуществляется выбор типа графика, задание диапазона исходных данных для его построения и непосредственно его построение. По завершении указанных действий остановить запись макроса нажатием кнопки «Остановить запись». Созданный макрос назначается кнопке «Построение графика», размещённой на главном листе приложения.
7) Проверка работоспособности имитационной модели путём нажатия всех кнопок и проверки правильности выполненных модулями VBA расчётов (учитывая, что правильно рассчитанные коэффициенты парной и множественной корреляции должны находиться в диапазоне от –1 до 1, а коэффициент детерминации – в диапазоне от 0 до 1 (см. рис. 2)), визуальный контроль построенного графика.
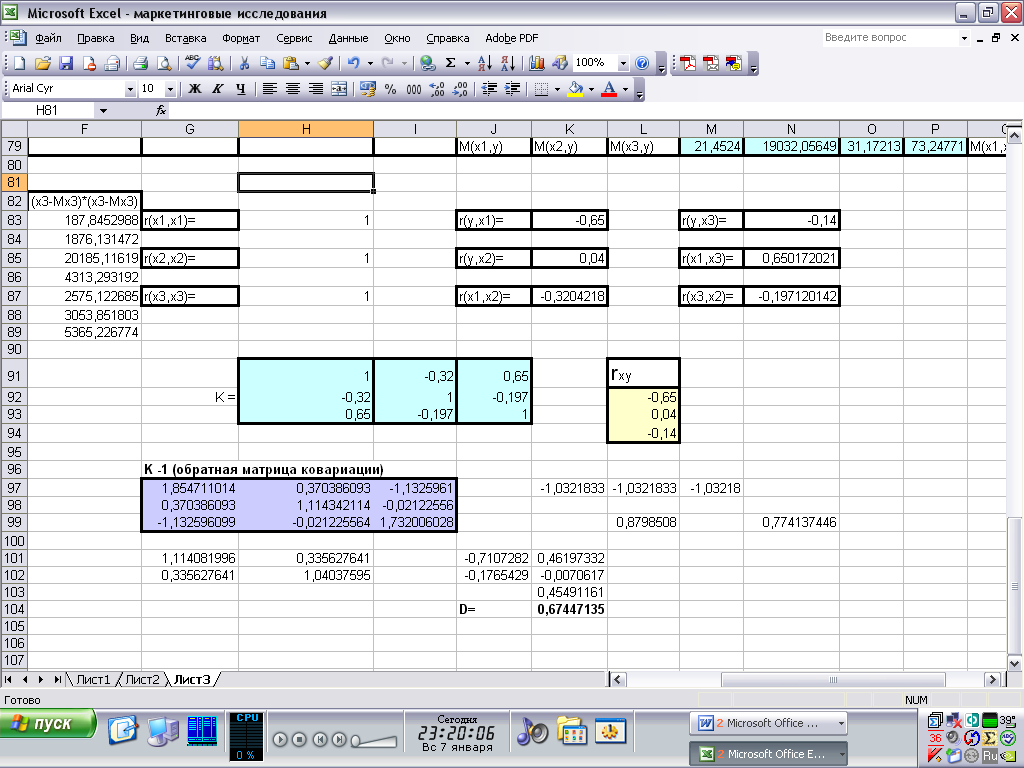
Рис. 2. Результаты расчётов коэффициентов парной корреляции и детерминации