Файл: Операции, производимые с данными (1. Получение данных).pdf
Добавлен: 30.06.2023
Просмотров: 63
Скачиваний: 3
Введение
Важность обладания информацией сложно преувеличить.
Даже в животном мире общение играет важную роль. А общение есть ни что иное как обмен информацией. Так же с обменом информацией неразрывно связан прогресс человечества. Мало придумать новый способ добычи. Для развития человечества в целом, важно этому новому способу обучить других людей. То есть информацию нужно сохранить. С развитием общество начало ценить не только материальные плоды труда, но и интеллектуальные. И этот процесс обусловил появление таких понятий как обладание информацией и ее защита.
До настоящего времени не существует единого толкования слова «информация»: в различных источниках приводятся различные определения. Так же часто смешиваются и путаются слова «информация», «данные», «знания». Даже специалисты в области информационных технологий зачастую путаются в этих понятиях. Сегодня существует очень много определений данных терминов, зависящих от профессиональных интересов и целей.
Рассмотрим несколько определений из свободной энциклопедии «Википедия»:
Информа́ция (от лат. informātiō «разъяснение, представление, понятие о чём-либо», informare «придавать вид, форму, обучать; мыслить, воображать») — сведения независимо от формы их представления.
Да́нные — зарегистрированная информация; представление фактов, понятий или инструкций в форме, приемлемой для общения, интерпретации, или обработки человеком или с помощью автоматических средств.
– поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи или обработки.
– формы представления информации, с которыми имеют дело информационные системы и их пользователи.
– совокупность значений, сопоставленных основным или производным мерам и/или показателям.
В обоих статьях Википедии после определений приводится следующий абзац:
Хотя информация должна обрести некоторую форму представления (то есть превратиться в данные), чтобы ею можно было обмениваться, информация есть в первую очередь интерпретация (смысл) такого представления. Поэтому в строгом смысле информация отличается от данных, хотя в неформальном контексте эти два термина очень часто используют как синонимы.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
Однако, информация — это интерпретация данных, и, казалось бы, перефразируя Ротшильда, можно сказать: «Кто владеет данными, тот владеет миром». Но данные без интерпретации — это просто набор фактов. К примеру, пазлы (данные) — просто набор кусочков картона, но после сбора (интерпретации) мы можем увидеть картину (информацию).
Аналогично, обладать информацией мало — необходимо донести ее до других. А для этого ее необходимо превратить в данные.
Так же в различных источниках встречается мнение что «данные» — это различные состояния носителя. Носители могут быть самыми разными. От старинных: глиняные таблички, папирус, кожа, береста; до более современных: бумага, магнитные ленты и диски, оптические и электрические носители, а также экран, радио и телевизионный эфир и многие другие. Для того чтобы различать состояния носителей, человек использует свои органы чувств: зрение, слух и осязание (алфавит Л. Брайля). Можно представить себе передачу информации и с применением обоняния или вкуса.
У компьютера также есть свои «органы чувств», позволяющие состояния доступных ему носителей (магнитные, электрические и оптические).
Также необходимо подчеркнуть важность возможности интерпретировать имеющиеся данные. Если человек получит электронное письмо на китайском языке, то, чтобы суметь прочесть письмо, во-первых, на устройстве в качестве системного должен быть установлен шрифт, включающий китайские иероглифы, во-вторых, человек должен знать китайский язык. Таким образом, и компьютер, и человек могут обладать данными, но не иметь возможности извлечь из них информацию.
Вышесказанное можно обобщить следующим алгоритмом:
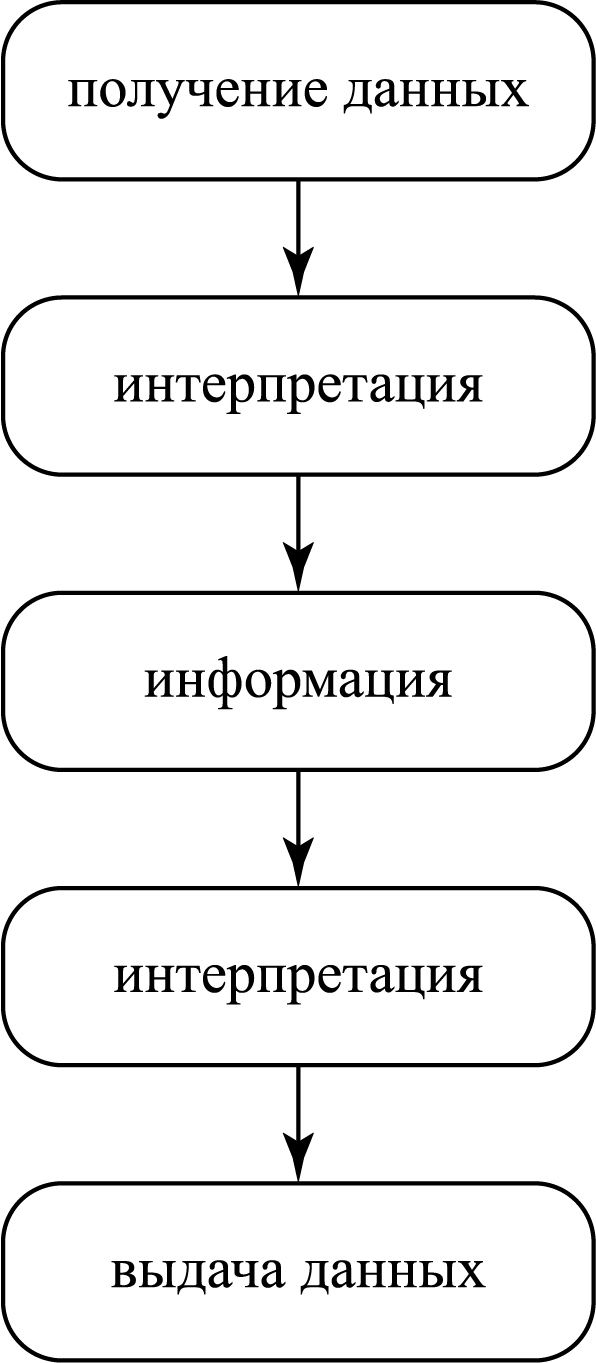
1. Получение данных
Получение данных можно рассматривать под разными углами.
1. Откуда.
Данные могут быть получены как из внешних источников, так и в результате обработки уже имеющихся данных.
При получении данных из внешних источников необходимо убедиться в их правдоподобности, адекватности. Например, при вводе с клавиатуры оператор может допустить опечатку. Желательно обеспечить некую автоматическую первичную проверку (контрольные суммы, подтверждение ввода).
При автоматическом получении данных может возникать погрешность или помехи (хорошим вариантом будет съем результатов нескольких тестов и усреднение показателей, а также накапливание информации о погрешностях).
При получении информации от постоянных поставщиков можно ввести индекс доверия.
При получении данных в результате обработки уже имеющихся, так же необходимо проводить операции по контролю правильности расчетов.
2. В каком виде.
Данные могут поступать в различных формах. Самым банальным примером может служить способ записи даты (30.11.1990, 30 ноября 1990, 11/30/90 и т.д.). Если все эти виды записи даты мы оставим в таком виде, это очень усложнит поиск. Поэтому желательно преобразовывать получаемые данные. Также необходимость преобразовывать возникает при изменении типа носи-
теля. Например, автор принес в издательство рукопись книги на бумаге. Для
того чтобы напечатать эту книгу, рукопись необходимо либо отдать наборщику, чтобы он набрал ее на компьютере, либо отсканировать и распознать.
Преобразование данных — перевод данных из одной формы в другую.
Очень часто данные поступают в виде пакетов и из разных источников порядок формирования этих пакетов может быть разным. Например:
AABBBCDDEFF
FFEDDCBBBAA
2A3B1C2D1E2F
1:C,E / 2:A,D,F / 3:B
…
И, несмотря на то, что все эти 4 строки содержат одни и те же данные, оперировать ими сложно. Поэтому желательно проводить формализацию
данных.
Формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме для того, чтобы сделать их сопоставимыми между собой.
Нередко пакеты данных содержат лишнюю информацию. Например, фирма занимается продажей игрушек. Раз в неделю принято проводить анализ цен на рынке. Для этого скачиваются прайсы нескольких конкурентов, которые продают не только игрушки, но и другие детские товары. Для анализа необходима фильтрация данных.
Фильтрация данных — отсеивание лишних данных, в которых нет необходимости для принятия решений; при этом достоверность и адекватность данных должны возрастать.
3. Когда.
Данные мы можем получить в один момент времени, а понадобиться они могут в другой. Таким образом, данные необходимо хранить.
2. Структурирование данных
Для удобства хранения и поиска полученные данные желательно структурировать.
Структурирование данных — размещение данных по определенному макету. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Структуры данных являются важнейшим компонентом программирования. Еще в 1976 году швейцарский ученый Никлаус Вирт написал книгу «Алгоритмы + структуры данных = программы». Формула актуальна и сейчас.
Структуры данных могут быть линейными и нелинейными.
Линейные: элементы образуют последовательность или линейный список, обход узлов линеен. Например: массив, связанный список, стек, очередь.
Нелинейные: данные не последовательны, обход узлов нелинейный. Например: граф, деревья.
Основные структуры данных
Массивы
Массив — это простейшая и наиболее распространенная структура данных. Другие структуры данных, например, стеки и очереди, производны от массивов. Любая таблица есть пример массива.
Здесь показан простой массив размером 4, содержащий элементы (1, 2, 3 и 4).

Каждому элементу данных присваивается положительное числовое значение, которое называется индекс и соответствует положению этого элемента в массиве. В большинстве языков программирования элементы в массиве нумеруются с 0.
Существуют массивы двух типов:
Одномерные (такие, как показанный выше).
Многомерные (массивы, в которые вложены другие массивы).
Стеки
Все привыкли пользоваться сочетанием клавиш «CTRL+Z». Оно предусмотрено практически во всех приложениях. Задумывались ли вы когда-нибудь, как это работает? Алгоритм выглядит так: в программе сохраняется история последних ваших действий (количество сохраняемых записей ограничено), причем, они располагаются в памяти в таком порядке, что последний сохраненный элемент идет первым. И, нажав «CTRL+Z» вы можете вернуться к предыдущему шагу. Массивами такую задачу решить проблематично. В подобной ситуации используется стек.
Стек можно сравнить со стопкой белья. Если вам нужна какая-то вещь, лежащая в конце стопки, вам сначала придется снять все белье, лежащее выше. Именно так работает принцип LIFO (Последним пришел — первым вышел).
Так выглядит стек, содержащий три элемента данных (1, 2 и 3), где 3 находится сверху — поэтому будет убран первым:

Очереди
Классический пример очереди — это и есть очередь покупателей. Новый покупатель становится в самый хвост очереди, а самый первый покупатель будет обслужен первым и первым покинет очередь.
Очередь, как и стек — это линейная структура данных, элементы в которой хранятся в последовательном порядке. Единственная существенная разница между стеком и очередью заключается в том, что в очереди действует принцип FIFO (Первым пришел — первым вышел).
На рисунке изображена очередь с четырьмя элементами данных (1, 2, 3 и 4), где 1 идет первым и первым же покинет очередь:

Связные списки
В качестве примера связного списка можно рассматривать любой адрес. Будь то ссылка в адресной строке браузера или заполненные адресные графы на конверте.
|
Область |
Московская |
|
|
Город |
Электросталь |
|
|
Улица |
Ленина |
|
|
Дом |
17 |
|
|
Квартира |
34 |
Связный список — еще одна важная линейная структура данных, на первый взгляд напоминающая массив. Однако, связный список отличается от массива по выделению памяти, внутренней структуре и по тому, как в нем выполняются базовые операции вставки и удаления.
Связный список это цепочка узлов, содержащих данные и указатель на следующий узел в цепочке. Есть головной указатель, соответствующий первому элементу в связном списке, и, если список пуст, то он направлен просто на null (ничто).
Вот так можно наглядно изобразить внутреннюю структуру связного
списка:

При помощи связных списков реализуются файловые системы,
хеш-таблицы и списки смежности.
Существуют такие типы связных списков:
- Односвязный список (однонаправленный)
- Двусвязный список (двунаправленный)
Графы
Графы — это совокупности узлов (вершин) и связей между ними (рёбер). Также их называют сетями.
Примером графа может служить любое предприятие. В качестве вершин будут выступать отделы, в качестве рёбер — их взаимодействие.
Графы делятся на два основных типа: ориентированные и неориентированные. У ориентированных графов рёбра имеют направления, у неориентированных — нет.

Чаще всего граф изображают в одном из двух видов: список смежности или матрица смежности.
Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соеди-няется.
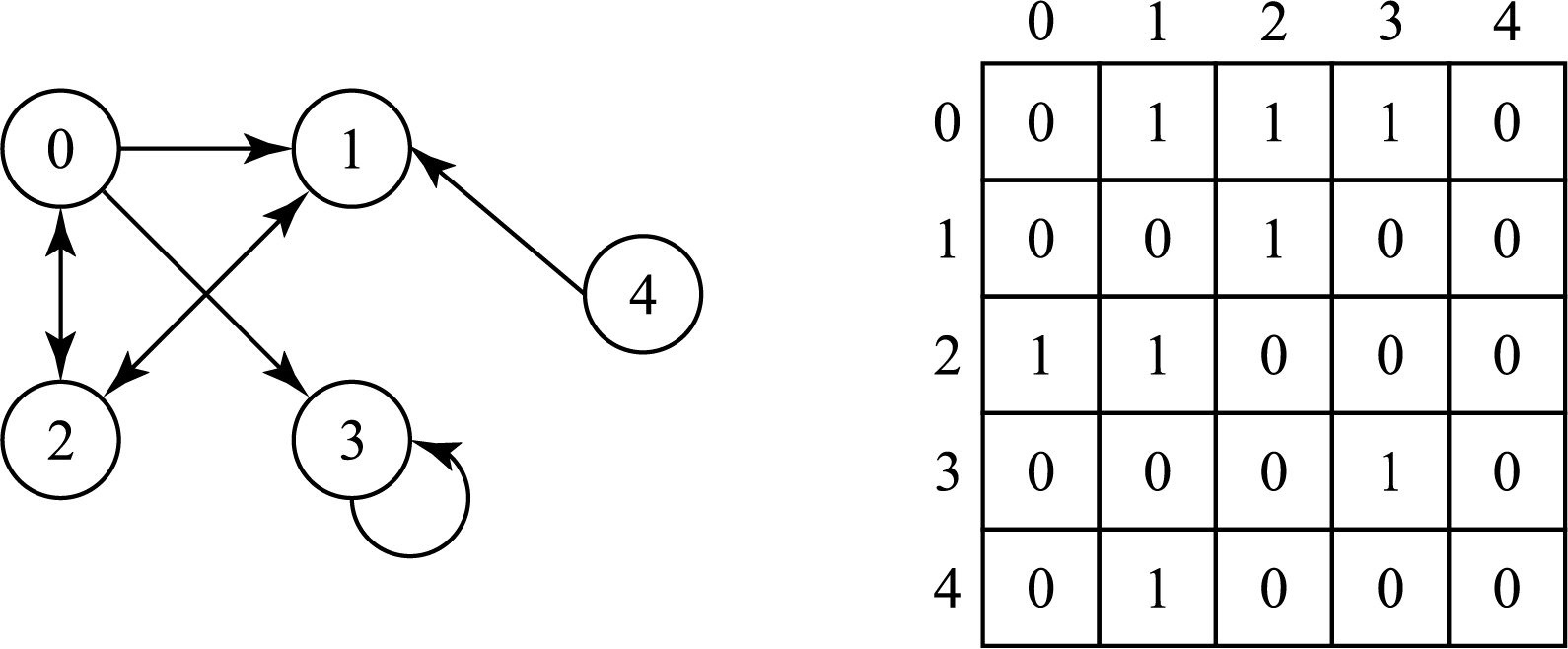
Граф в виде матрицы смежности
Матрица смежности — это таблица с числами, где каждый ряд или колонка соответствуют отдельному узлу графа. На пересечении колонки и ряда располагается число, которое указывает на наличие (1) или отсутствие (0) связи. Для обозначения веса связи используются числа больше единицы.
Существуют специальные алгоритмы для просмотра рёбер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и в глубину (depth-first search).
Деревья
В качестве примера дерева может служить любая иерархическая струк-тура.
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья похожи на графы, главное отличие состоит в том, что в дереве не бывает циклов.
Деревья широко используются в области искусственного интеллекта и в сложных алгоритмах, выступая в качестве эффективного хранилища информации при решении задач.
На рисунке показана схема простого дерева и базовая терминология, связанная с этой структурой данных: