ВУЗ: Томский государственный университет систем управления и радиоэлектроники
Категория: Методичка
Дисциплина: Базы данных
Добавлен: 28.11.2018
Просмотров: 2395
Скачиваний: 8
16
•
Хотя индексно-последовательный доступ (или последовательная орга-
низация данных) наглядно и легко воспринимается (а кроме того требует
меньший индекс). Этот способ более сложен для эксплуатации.
•
При включении новых записей возникает необходимость пересорти-
ровки файла (если мы рассматриваем файл), либо внесения новых записей в
отдельную область (область переполнения) или организации указателей на
эти записи. (Пример фамилии в алфавитном порядке).
1
2
46
3
относительный адрес
указатель на область переполнения
Эти записи помещаются в область переполнения.
4.4.
Индексно
-
произвольный
метод
доступа
Данный метод обеспечивает доступ к экземплярам записей на основе ис-
пользования индекса. Поэтому метод называется также «метод доступа с
полным индексом».
Полный индекс представляет собой такую организацию файла, при ко-
торой для каждого конкретного экземпляра записи предусмотрен соответст-
вующий индекс. Этот индекс составляется из значения первичного ключа и
указателя экземпляра записи, содержащий это значение.
Обычно, для ускорения поиска индексы упорядочиваются и физически
близкое размещение хранимых записей не требуется.
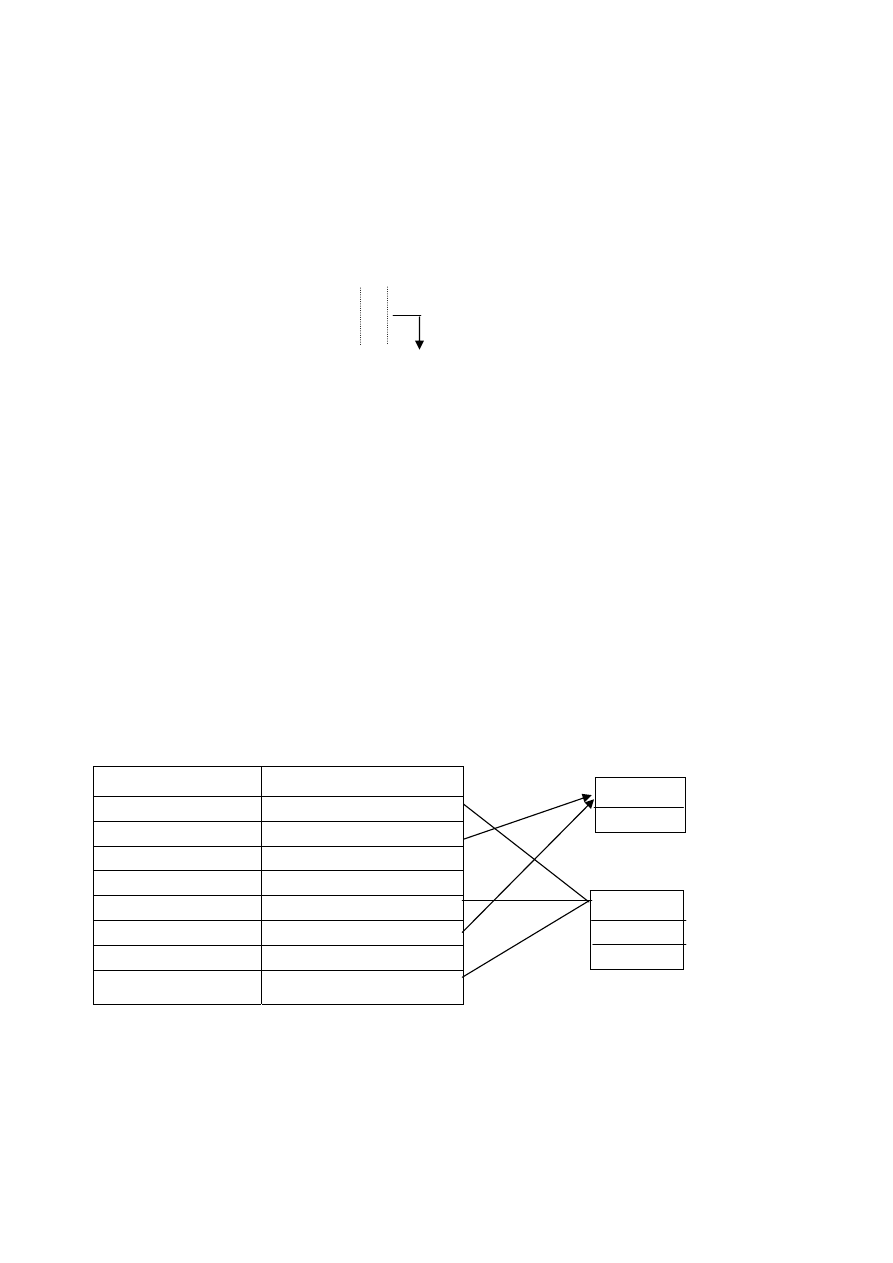
Полный индекс.
Значение ключа Значение указателя
А 1000
2
А 1001
1
….. …..
А 1999
3
В 3000
2
В 3001
1
В ….
….
В 3500
2
После того, как в индексе обнаружено искомое значение ключа, доступ к
записи можно осуществить с помощью указателя, который хранится в индек-
се рядом со значением ключа (в этом случае, если искомое значение ключа в
индексе не найдено, поиск завершается на уровне индекса).
А 1001
В 3001
А 1000
В 3000
В 3500

17
Допускается произвольный доступ к индексу посредством хэширования.
Метод доступа с полным индексом обеспечивает эффективную выборку еди-
ничных записей, а также простоту операций обновления( т.е. новые записи
просто включаются в конец файла и при этом не требуется вводить указатели
на область переполнения).
4.5.
Метод
доступа
,
основанный
на
использовании
древовидных
структур
Имеют место методы представления в памяти ЭВМ данных в виде дре-
вовидных сетевых структур и соответствующие методы доступа к ним.
Эти методы стали конкурентами классических (перечисленных выше)
методов. К основным древовидным структурам относятся:
-
бинарное дерево;
-
В- дерево.
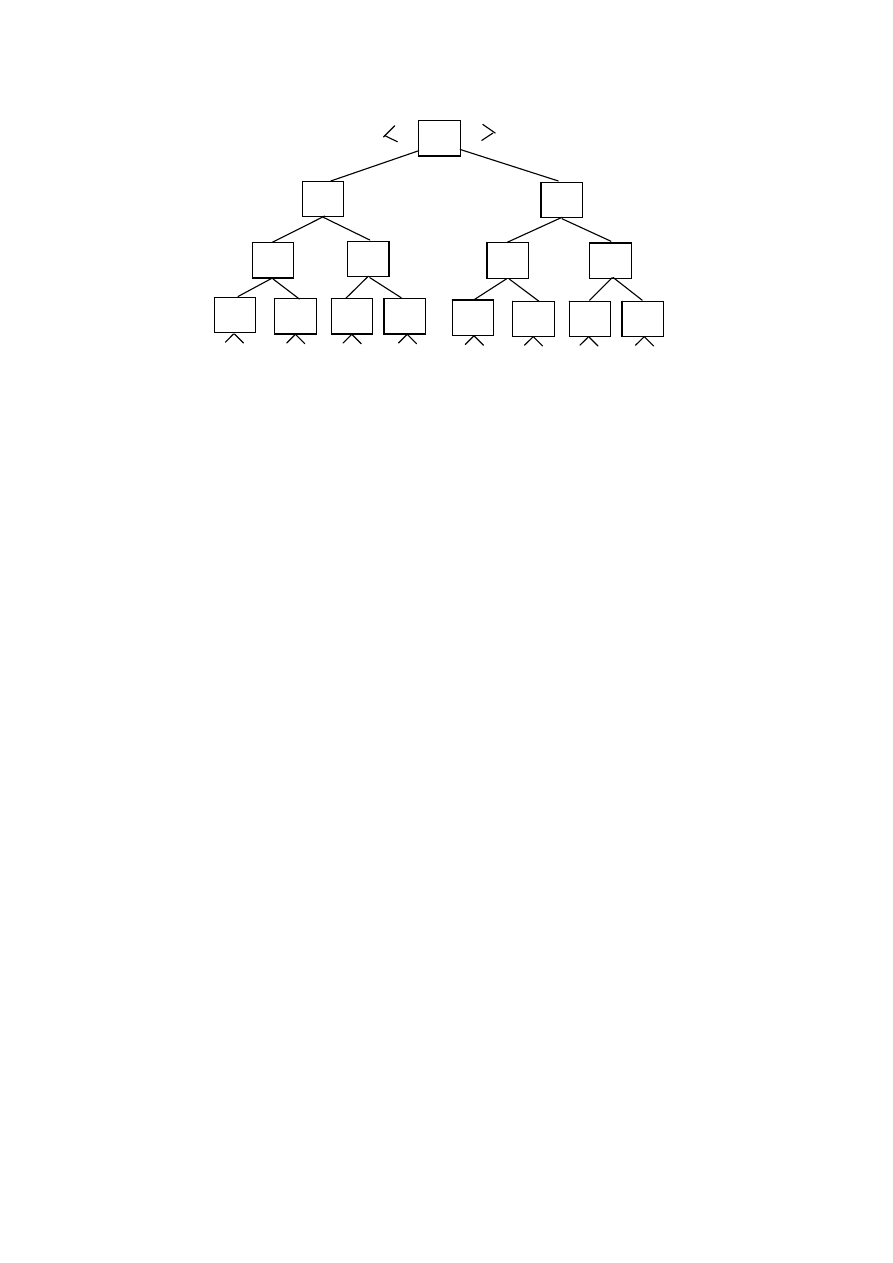
Бинарным (двоичным) деревом называется древовидный граф с двоич-
ным ветвлением, когда из каждой вершины (кроме концевых) выходят две
дуги.
Бинарные деревья (двоичные) представляют собой широко используе-
мый вид структур баз данных, обеспечивающий как произвольный, так и по-
следовательный выбор данных.
Важную роль проектирования древовидных структур данных играет по-
нятие сбалансированного дерева.
Сбалансированным, называется дерево, если разница уровней любых
двух конечных вершин не превышает единицы.
Уровень вершины (i) – определяется длиной пути от корневой вершины
(Т) до вершины (i).
Корневая вершина (Т) имеет нулевой уровень.
Построение сбалансированного дерева делает равномерным обращение к
любой из его вершин, что позволяет минимизировать среднюю длину досту-
па.
Механизм поиска по бинарному дереву основан на том, что каждая
вершина дерева помечена отдельным ключом. Ключи упорядочены следую-
щим образом: k
i1
≤k
i
≤k
i2
, где k
i
– ключ i-ой вершины; k
i1
– ключ i
1
-ой вершины,
соответствующей левой дуге i-ой вершины; k
i2
– ключ вершины, лежащей на
правой дуге.
При поиске некоторого ключа k вначале просматривается корневая вер-
шина дерева Т и сравнивается ключ k с ключом k
т
корневой вершины:
а) в случае k=k
т
– поиск завершен успешно;
б) если k<k
т
– поиск продолжается в левом поддереве;
в) если k>k
т
– поиск продолжается в правом поддереве.
18
В – деревья.
В-дерево представляет собой обобщение понятия бинарного дерева.
В нем из каждой вершины могут выходить более двух ветвей. Обычно
В-деревья используются только для организации индекса. Записи данных
располагаются в отдельной области, для которой возможен произвольный
доступ.
Каждая вершина В-дерева состоит из совокупности значений первичного
ключа, указателей индексов и ассоциированных данных.
Указатели индексов используются для перехода на следующий, более
низкий уровень в В-дереве.
Асcоциированные данные фактически представляют собой совокупность
указателей данных и служат для определения физического местоположения
данных, ключевые значения которых хранятся в этой вершине индекса.
Сжатие данных.
Для сокращения объема памяти, занимаемой данными, используются
разнообразные методы сжатия.
Во многих случаях сжатие данных дает огромную экономию (размер
может быть уменьшен в 2 раза), а иногда и до 80%.
Методы сжатия можно разбить на 2 группы (класса):
1)
методы ориентированные на конкретную структуру или содержание
записей и разрабатываемые в расчете на конкретное приложение;
2)
методы, которые используются во многих приложениях и поэтому
могут быть встроены в общее программное обеспечение, аппаратуру или
микропрограммы.
Существуют следующие способы:
1)
исключение избыточных элементов;
2)
переход от естественных обозначений к более компактным;
3)
подавление повторяющихся символов;
4)
ликвидация пустых мест в файле;
5)
кодирование часто используемых элементов данных;
6)
сжатие упорядоченных данных.
20
12
43
7
16
29
53
2
9
14
18
24
40
46
57
19
Исключение избыточности элементов.
Является важным методом сокращения расходов памяти при организа-
ции базы данных.
Этот способ состоит в исключении одних и тех же элементов данных в
составе нескольких файлов и устранение избыточных связующих элементов.
Например,
Если использовать для изображения связей одиночные стрелки, можно
установить те связи, которые избыточны.
Но прежде, чем удалять связующий элемент необходимо оценить смысл
ассоциаций элементов.
Ассоциация элементов не дает однозначного определения для исключе-
ния избыточных связующих данных.
4.6.
Схема
физического
доступа
к
базе
данных
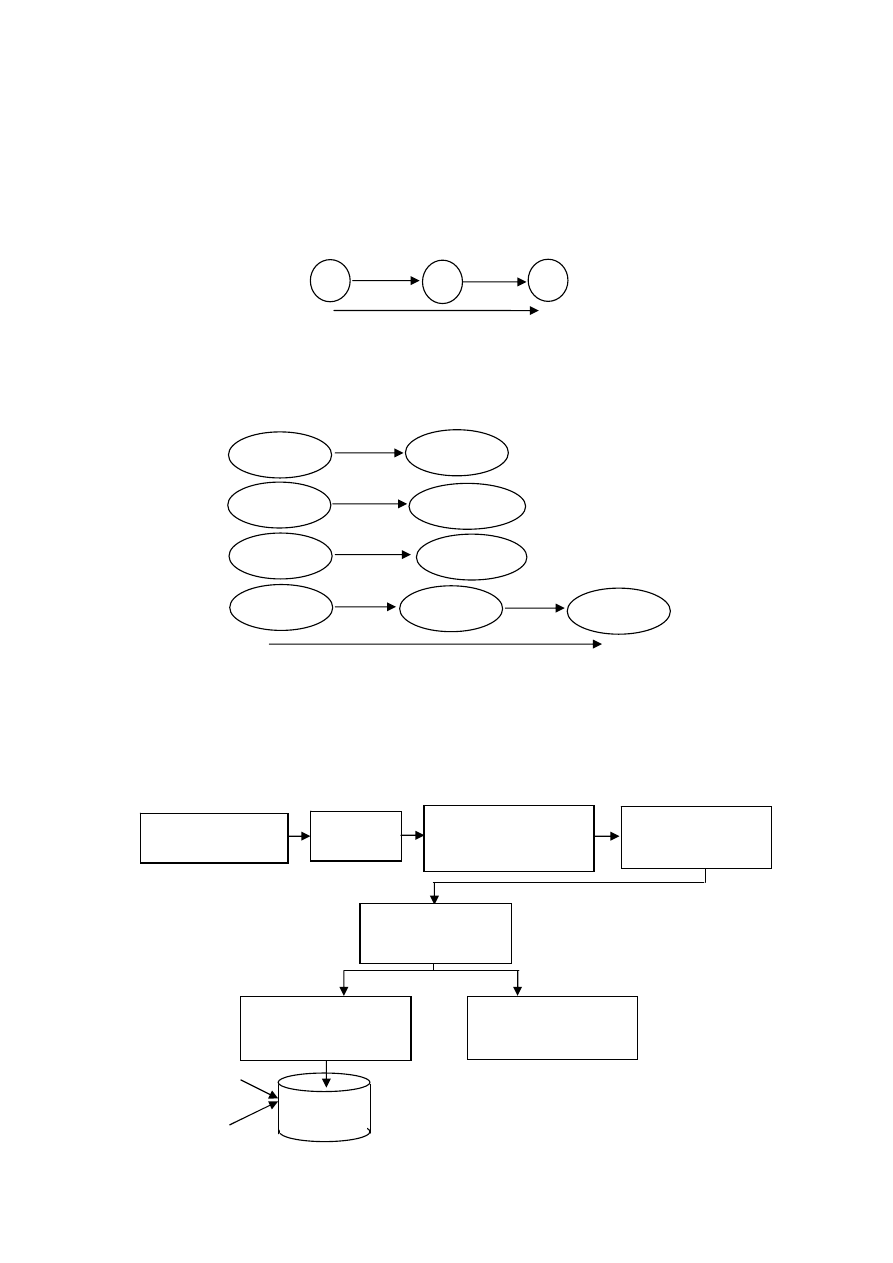
Схему физического доступа к данных можно представить следующей
структурой:
x
y
z
Служ.
Упр.
Служ.
Телеф.
Упр.
Телеф.
Служ.
Упр.
N
тел.
Пользователь
Запрос
Стратегический
селектор
Диск
Словарь
данных
Пользова-
тельские данные
Преобразова-
тель запросов
Управление
буферами
Диспетчер
файлов
Оперативная
память

20
Итак, пользователь взаимодействует с системой баз данных, запуская ин-
струкции.
Стратегический селектор – программное обеспечение, преобразование
запроса в эффективную для исполнения форму.
Преобразованное требование активизирует буферный диспетчер – про-
граммное обеспечение, контролирующее перемещение данных между ОЗУ и
диском.
Диспетчер файлов - поддерживает буферный диспетчер, управляя раз-
мещением данных на диске и связанными с ним структурами данных.
Кроме пользовательских данных диск содержит словарь данных – оп-
ределяет структуру пользовательских данных и возможности их использова-
ния.
Пользовательские данные хранятся в виде физической базы данных или
совокупности данных.
5.
РАСПРЕДЕЛЕННЫЕ
БАЗЫ
ДАННЫХ
Основные вопросы, включаемые в рассмотрение распределенных баз
данных:
1)
различные формы прозрачности;
2)
выполнение запросов;
3)
параллельные обновления информации.
На уровне пользователя распределенная база данных представляет со-
бой логическую совокупность локальных и удаленных (т.е. распределенных
данных).
Строгое физическое определение следующее: распределенная база
данных – это набор файлов (отношений), хранящихся в разных узлах инфор-
мационной сети и логически связанных таким образом, чтобы составлять
единую совокупность данных (связь может быть функциональной или через
копии одного и того же файла). (ИПС – информационно-поисковые системы
базируются на распределенных СУБД и др.)
Итак, СУБД и централизованная обработка информации, позволяют уст-
ранять такие недостатки традиционных файловых структур:
-
несвязанность;
-
несогласованность;
-
избыточность данных.
По мере роста баз данных и их использовании в территориально разде-
ленных организациях появляются другие проблемы. Так, для централизован-
ной СУБД, находящейся в узле телекоммуникационной сети, с помощью ко-
торой различные подразделения организации получают доступ к данным, с
ростом объема информации и количество транзакций (запросов) появляются
следующие проблемы:
-
большой поток обменов данными;