Добавлен: 06.11.2023
Просмотров: 105
Скачиваний: 3
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Федеральное государственное бюджетное образовательное учреждение высшего образования
«НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ СТРОИТЕЛЬНЫЙ УНИВЕРСИТЕТ»
Институт цифровых технологий и моделирования в строительстве
Кафедра Информатики и прикладной математики
ДОМАШНЕЕ ЗАДАНИЕ
по дисциплине
«Математические методы обработки больших данных»
Тема: «Разведывательный анализ данных»
Выполнил студент
ИСАм 1-4, Богачев А.В.
Проверила:
доц. Горбунова Т.Н.
Москва 2022
СОДЕРЖАНИЕ
ВВЕДЕНИЕ 3
ОСНОВНАЯ ЧАСТЬ 4
1.Первичный анализ данных 4
2.Выявление ошибок и выбросов 7
3.Устранение ошибок и выбросов 8
4.Сортировка данных 9
5.Построение модели 9
ЗАКЛЮЧЕНИЕ 12
СПИСОК ЛИТЕРАТУРЫ 13
ВВЕДЕНИЕ
Цель этого курса — научиться писать программы, решающие научные задачи. Язык программирования Python обладает ясным и понятным синтаксисом, и потому легко учится и хорошо подходит для введения в программирование. Это позволит нам не отвлекаться от решаемой задачи на особенности языка и их объяснение, позволит естественным образом последовательно вводить новые инструменты.
Целью домашней работы является освоение таких элементов разведывательного анализа данных, как первичный анализ данных выбранного файла, выявить наличие ошибочных данных и выбросов, их фильтрация (сортировка), построение качественной модели данных.
ОСНОВНАЯ ЧАСТЬ
Для анализа данных был выбран датасет состоящий из данных о технических характеристиках персональных компьютеров и их стоимости (Computers.csv). Данный датасет был получен с бесплатного сайта с базами данных https://vincentarelbundock.github.io/Rdatasets/datasets.html.
-
Первичный анализ данных
Импортируем файл Computers.csv для того, чтобы просмотреть его данные в пространстве «Юпитер». Программ для просмотра данных, а также общий вид таблицы с данными представлен на рисунке 1.
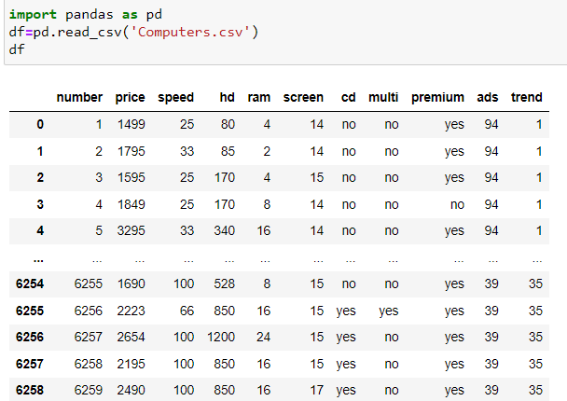 |
| Рисунок 1. Общий вид датасета |
Определяем, что данный датесет состоит из 6258 строк и 11 столбцов. Так как столбец «Numbers» дублирует столбец с порядковым номером строки, который создает подгруженная библиотека «pandas», удаляем данный столбец из датасета, алгоритм приведен на рисунке 2. Далее нам необходимо определить наличие ячеек с отсутствующей информацией, алгоритм по поиску данных ячеек приведен на рисунке 3.
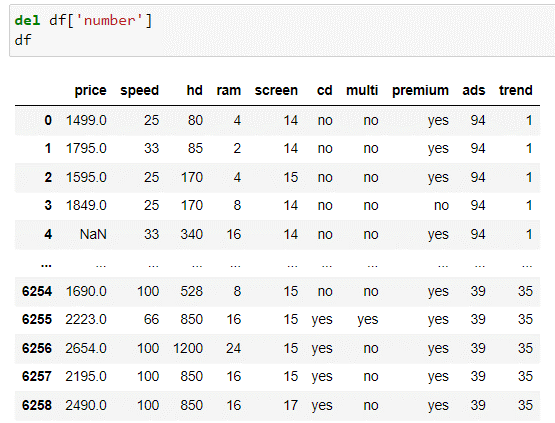 |
| Рисунок 2. Исправленная шапка датасета |
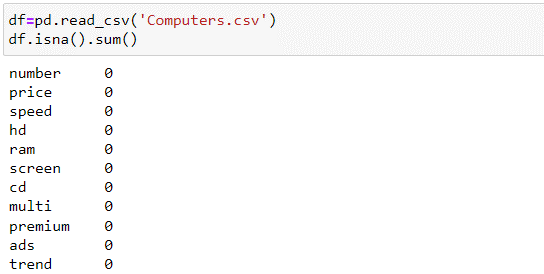 |
| Рисунок 3. Количество ячеек с отсутствующей информацией в каждом столбце |
Согласно алгоритму, приведенному на рисунке 3, мы определили, что в данном датасете отсутствуют пустые ячейки без данных. Для учебных целей добавим в загруженный датасет пустые ячейки, а также обнулим некоторые числовые данные с целью создания ошибочных данных. Определим количество пустых ячеек в искусственно обновленном файле (см. рис. 4).
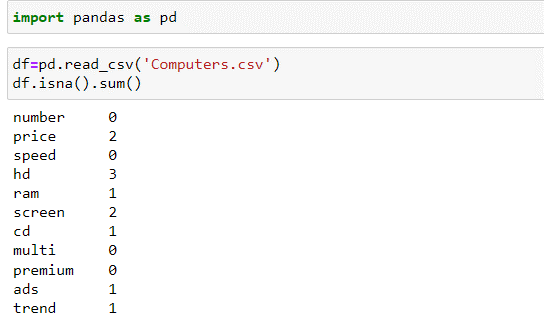 |
| Рисунок 4. Новое количество ячеек с отсутствующей информацией в каждом столбце |
Далее определяем тип информации в каждом столбце, текстовая или числовая (см. рис. 5).
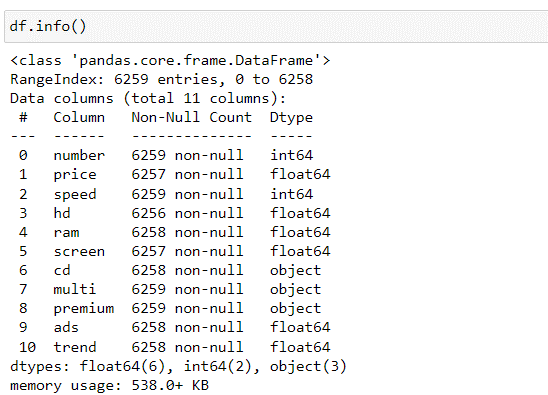 |
| Рисунок 5. Информация о данных столбцов в датасете |
Далее определим, данные по каждому столбцу (количество занятых ячеек, среднее значение, минимальное значение, максимальное значение и т.д.) (см.рис.6).
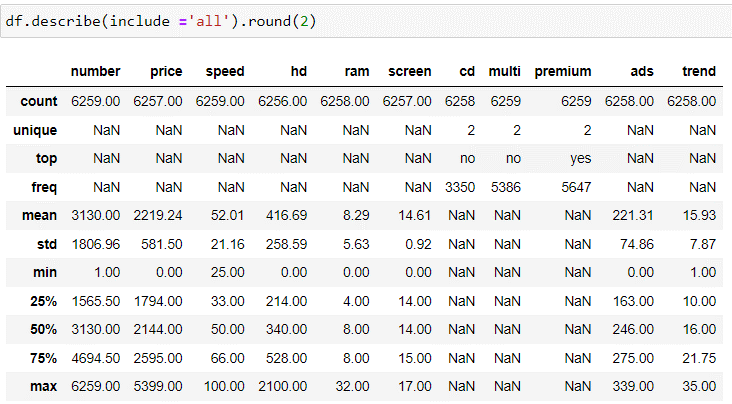 |
| Рисунок 6. Данные об информации в каждом столбце |
-
Выявление ошибок и выбросов
Определяем наличие выбросов для столбца «price» (см. рис. 7). Полученные результаты показывают, что выбросы в данном столбце присутствуют. Также согласно рисунку 6 мы можем определить, что в некоторых столбцах есть ошибочные значения равные нулю.
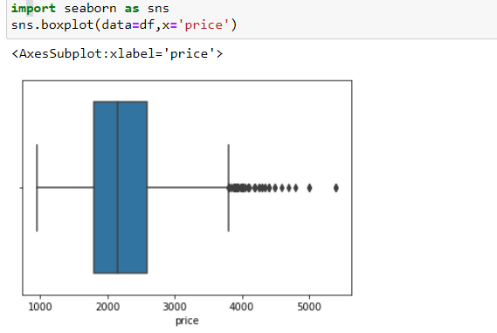 |
| Рисунок 7. Новое количество ячеек с отсутствующей информацией в каждом столбце |
-
Устранение ошибок и выбросов
Устраняем строки с пропущенной информацией в ячейках столбцов датасета и определяем новое количество строк в датасете (см. рис. 8).
 |
| Рисунок 8. Удаление строк с пустыми ячейками и новое количество строк |
Определяем границы выбросов (см. рис. 9).
 |
| Рисунок 9. Определение границ выбросов |
Устраняем выбросы, выходящие за границы квартилей (границы допустимых значений) (см. рис. 10). Также по рисунку 10 видно, что строки с нулевым значением также отброшены. Повторяем данный алгоритм ко всему датасету.
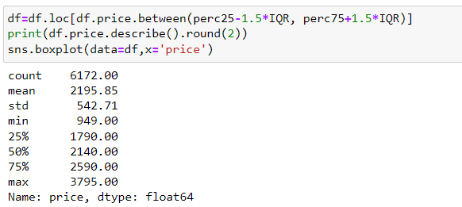 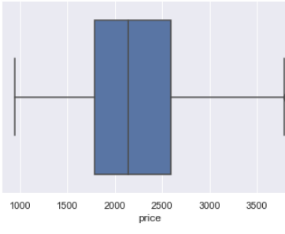 |
| Рисунок 10. Данные об обновленных значениях столбца «price» |
-
Сортировка данных
Отфильтруем значения по показателю «price» и определим новое количество строк в датасете (см. рис. 11).
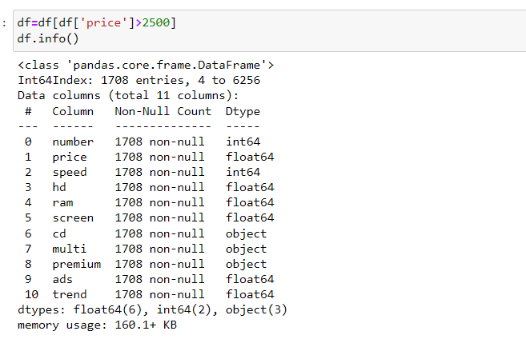 |
| Рисунок 11. Отфильтрованные данные |
-
Построение модели
Построим корреляционную матрицу для всех столбцов датасета (см. рис.12).
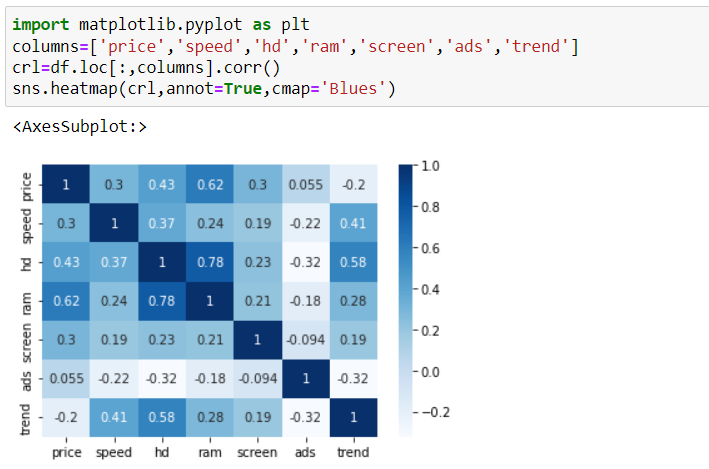 |
| Рисунок 12. Корреляционная матрица для всего датасета |
Построим отдельную матрицу с наиболее коррелирующими столбцами «price», «hd» и «ram» (см. рис. 13).
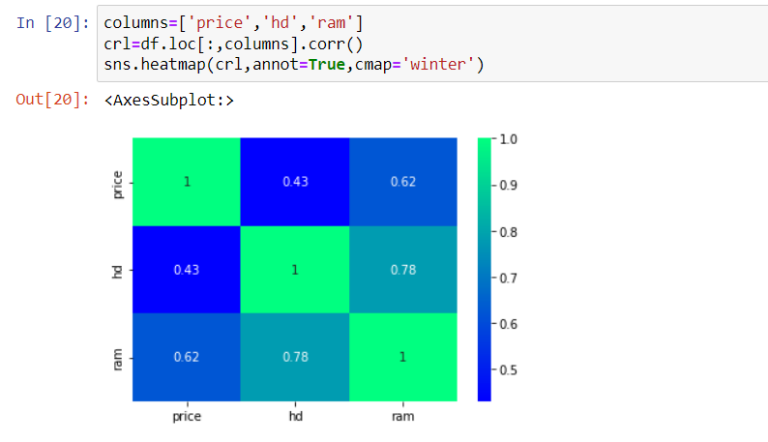 |
| Рисунок 13. Корреляционная матрица для наиболее подходящих столбцов |
Строим модель и определяем ее качество (см. рис. 14).
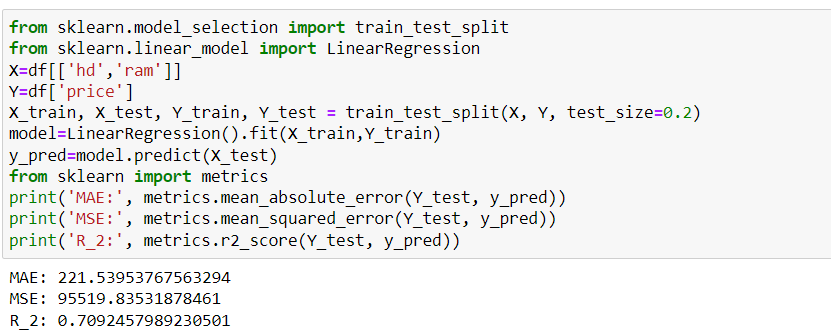 |
| Рисунок 14. Показатели качества созданной модели |
Так как коэффициент детерминации заключен в пределах от 0,5 до 0,8, согласно рисунку 14, то качество полученной модели является удовлетворительным.
ЗАКЛЮЧЕНИЕ
В результате выполнения домашней работы и оформления отчета мною были освоены такие элементы разведывательного анализа данных, как первичный анализ данных выбранного файла, выявить наличие ошибочных данных и выбросов, их фильтрация (сортировка), построение качественной модели данных.
СПИСОК ЛИТЕРАТУРЫ
-
Python в рамках курса Big Data [электронный ресурс] // ПЯВУ для студентов МГСУ : [сайт]. URL: https://www.sites.google.com/site/mgsuzsp/python-big-data (дата обращения: 04.06.2022). -
Программирование и научные вычисления на языке Python [электронный ресурс] // Викиверситет : [сайт]. URL: https://ru.wikiversity.org/wiki/Программирование_и_научные_вычисления_на_языке_Python (дата обращения: 04.06.2022). -
Datasets : [сайт]. URL: https://vincentarelbundock.github.io/Rdatasets/datasets.html (дата обращения: 04.06.2022).