Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 355
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Процедуры РОЦ-технологии можно разделить на три уровня:
верхний уровень, базирующийся на дереве целей, обеспечивает предварительное определение варианта принятия решения.
средний ориентируется либо на дерево решений, либо на таблицу решений, либо на то и другое одновременно. Задача данного уровня состоит в определении окончательного решения.
нижний предназначен для обеспечения исполнения принятого решения (интеллектуальная информационная поддержка).
Выбор цели является исходной точкой в процессе приня-
тия решений. Ее знание позволяет приступить к процедурам подго-
товки информации и поиска альтернатив. Для этого следует выполнить этапы:
1. Формулировка главной цели управления и подцелей, достижение которых обеспечит реализацию идей ЛПР.
2. Определение ресурсов и резервов, имеющихся в распоряжении ЛПР, а также ограничений, накладываемых внешними условиями на их использование.
3. Формулировка альтернативных вариантов достижения главной цели и расчет возможных последствий для каждого из вариантов.
4. Выбор одного из решений в соответствии с критерием оценки ЛПР.
РОЦ-технология содержит четыре комплекса проектных процедур:
-
Формулирование цели создания ЭСС. -
Разработка структур БЗ и БД. -
Наполнение ЭСС знаниями. -
Тестирование и внедрение ЭСС.
При построении ЭСС используется БЗ в виде дерева целей, снабженная коэффициентами относительной важности и направлениями изменений каждой из вершин дерева. Числовая характеристика важности целей измеряется в шкале 0
Пусть имеется n целей
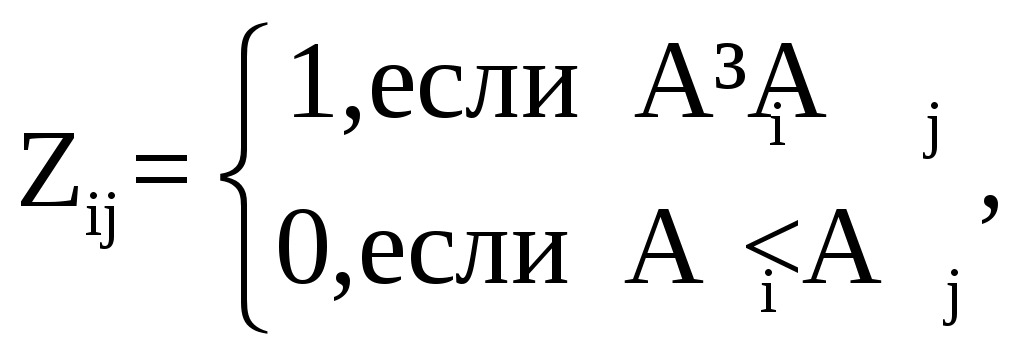
т.е.
указывает на предпочтительность цели (не меньшую важность) по сравнению с другой. Тогда
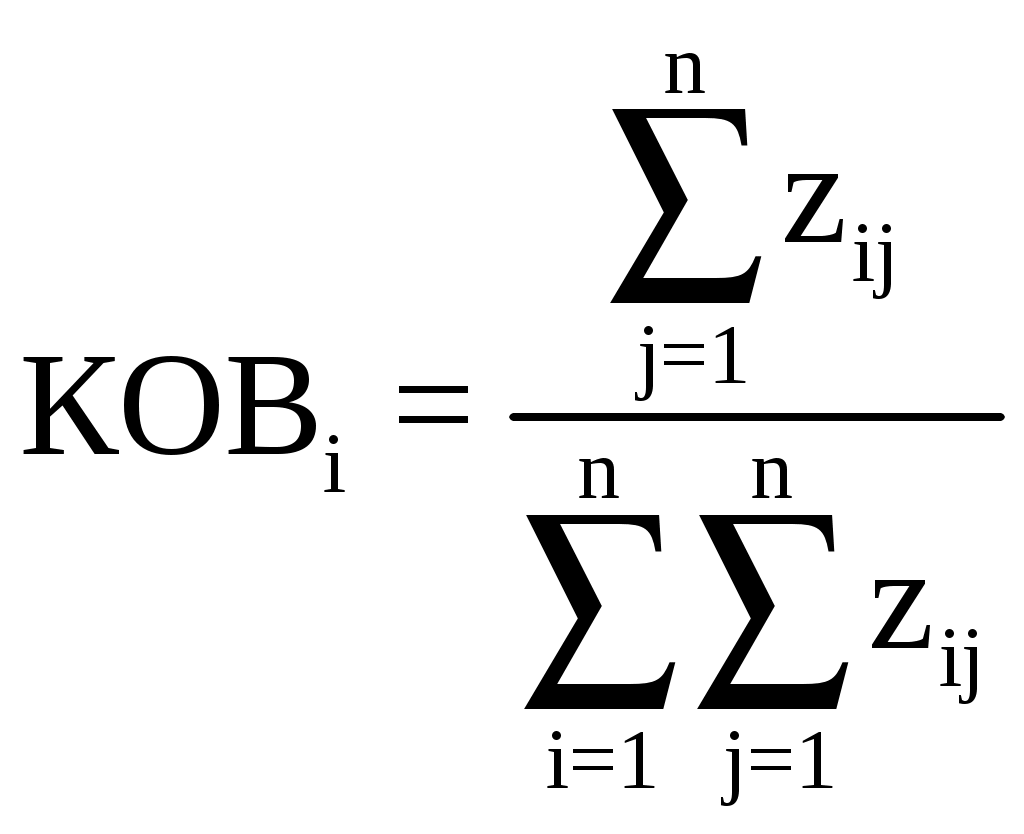 . (4.1)
. (4.1)Пример 4.4. Пусть n = 4.
А1 – обеспечить повышение производительности труда;
А2 – увеличить коэффициент сменности оборудования;
А3 – повысить обратную величину к стоимости установленного оборудования;
А4 – обеспечить повышение удельного веса машин и оборудования
в стоимости основных производственных фондов.
Задана матрица Z:
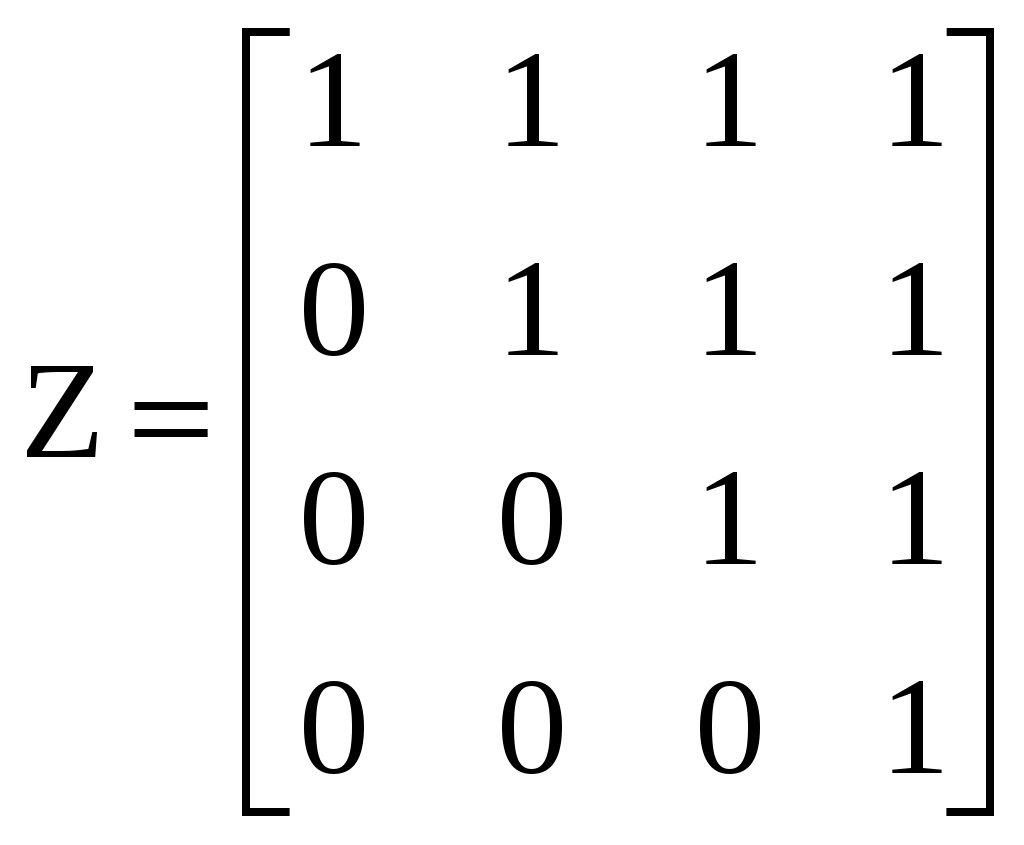
Тогда в соответствии с выражением (4.1) получим: КОВ1 = 4; КОВ2 = 0,3; КОВ3 = 0,2; КОВ4 = 0,1.
Глава 5. Программный инструментарий разработки систем, основанных на знаниях
5.1. Цели и принципы технологии разработки
программных средств
Технология – это наука о мастерстве (от греч. «технос» – мастерство; «логос» – слово, наука). Под технологией программирования понимается совокупность знаний о способах и средствах достижения целей в области ПО. Изменения являются постоянным фактором разработки ПО. Для того чтобы преодолеть их разрушающий эффект, в качестве целей технологии разработки ПО принимаются следующие свойства программных средств (ПС) [5, 24]:
модифицируемость необходима для того чтобы отразить в системе изменение требований или исправить ошибки;
эффективность системы подразумевает, что при функционировании оптимальным образом используются имеющиеся в ее распоряжении ресурсы (время, память);
надежность системы означает, что последняя способна предотвращать концептуальные ошибки, ошибки в проектировании и реализации, а также ошибки, возникающие при функционировании системы;
понимаемость является мостом между конкретной проблемной областью и соответствующим решением. Для того чтобы система была понимаемой, она должна быть прозрачной.
По мере выполнения работ необходимо придерживаться определен-ного набора принципов, которые обеспечивают достижение поставленных целей:
абстракция – выделение существенных свойств с игнорированием несущественных деталей. По мере декомпозиции решения на отдельные компоненты каждый из них становится частью абстракции на со-ответствующем уровне. Абстрагирование применяется и к данным, и к алгоритмам. На любом уровне абстракции могут
фиксироваться аб-страктные типы данных, каждый из которых характеризуется множеством значений и множеством операций, применимых к любому объекту данного типа;
сокрытие информации имеет целью сделать недоступными детали, которые могут повлиять на остальные, более существенные части системы. Обычно скрывает реализацию объекта или операции и позволяет фиксировать внимание на более высоком уровне абстракции. Сокрытие проектных решений нижнего уровня оберегает стратегию принятия решений верхнего уровня от влияния деталей. Абстракция
и сокрытие информации способствует модифицируемости и понимае-мости ПО;
модульность реализуется целенаправленным конструированием. Модули могут быть функциональными (процедурно-ориентированными) или декларативными (объектно-ориентированными). Связность модулей определяется как мера их взаимной зависимости. В идеале должны разрабатываться слабосвязанные модули;
локализация помогает создавать слабо связанные и весьма прочные модули. По отношению к целям технологии разработки ПО принципы модульности и локализации способствуют достижению модифици-руемости, надежности и понимаемости.
Абстракция и модульность считаются наиболее важными прин-ципами, используемыми для управления сложностью систем ПО. Однако они не являются достаточными, поскольку не гарантируют получения согласованных и правильных систем. Для обеспечения этих свойств необходимо обеспечивать соблюдение принципов единообразия, полноты и подтверждаемости.
5.2. Технология и инструментарий разработки
программных средств
Подсистема разработки и реализации
Спецификация, тесты
Подсистема управления

документиро-вания




Рис. 5.1. Общая структура типовой технологической системы
поддержки разработки ПС
Новой ветвью в технологии разработки ПО является CASE-технология (Computer Aided Software Engineering). Первоначально CASE-технология появилась в проектах создания систем обработки данных. Все средства поддержки CASE-технологии делятся на две группы: CASE-Tool Kits и CASE-Work Benches. Отечественных эквивалентов нет, но первую группу называют «инструментальные сундучки» (технологические па-кеты), а вторую – «станки для производства программ» (технологические линии) (рис. 5.2).
Стиль программирования в ИИ-системах существенно отли-
чается от такового с использованием обычных алгоритмических языков (рис. 5.3).
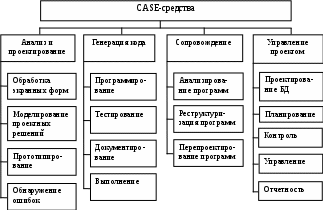
Рис. 5.2. Типовая система поддержки CASE-технологии
| Характеристики программирования | Программирование в ИИ-системах | Программирование традиционное |
| Тип обработки | Символьная | Числовая |
| Методы | Эвристический поиск | Алгоритм |
| Задание шагов решения | Неявное | Точное |
| Искомое решение | Удовлетворительное | Оптимальное |
| Управление и данные | Перемешаны | Разделены |
| Знания | Неточные | Точные |
| Модификации | Частые | Редкие |
1 2 3 4 5 6 7 8 9 ... 13
Рис. 5.3. Сравнительные характеристики программирования
в ИИ-системах и традиционного программирования
Разработка системы ИИ начинается с формирования полных, непротиворечивых и однозначных требований. При проектировании используются принципы технологии разработки ПО: сокрытие ин-формации, локализация и модульность. Система ИИ проектируется как композиция уровней, любой из которых чувствителен лишь к ниже-стоящим уровням. Такое проектирование упрощает реализацию и тести-рование системы ИИ.
Тестирование ПО ИИ отличается от тестирования обычных систем, так как для ИИ-систем характерно недетерминированное поведение вследствие использования стратегии разрешения конфликтов, зависящей от параметров периода исполнения программы. Поэтому единственным эффективным способом тестирования систем ИИ является прототипизация.
Фаза сопровождения, включающая выполнение различных моди-фикаций системы, является важнейшим этапом процесса разработки любой системы, но имеет свою специфику для систем ИИ. Здесь БЗ наи-более динамичный компонент, меняющийся в течение всего жизненного цикла. Поэтому сопровождение ИИ-систем является сложной задачей. Приобретение знаний ключевая задача во всех технологиях построения систем, основанных на знаниях. Производительность ИИ-систем на-прямую зависит от количества знаний, содержащихся в системе.
В области создания средств автоматизации ИИ-систем существуют две тенденции:
«восходящая» – классический путь развития средств автоматизации программирования: автокоды => языки высокого уровня => языки сверхвысокого уровня => языки спецификаций;
«нисходящая», связанная со специальными средствами, изначально ориентированными на определенные классы задач и методы ИИ.
Эти стратегии, обогащая друг друга, должны привести к созданию мощного и гибкого инструментария интеллектуального программиро-вания. Основными направлениями в данной области являются:
-
Разработка систем построения знаний (СПЗ) путем прямого использования широко распространенных языков обработки символьной информации и языков программирования общего назначения. -
Расширение базисных языков ИИ до СПЗ за счет специали-зированных библиотек и ППП. -
Создание языков представления знаний (ЯПЗ), специально ориен-тированных на поддержку определенных формализмов, и реализация соответствующих трансляторов с этих языков.