Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 343
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
обеспечение доступа пользователя к сетевым протоколам в сети Интернет;
возможность параллельного решения нескольких задач;
выполнение поиска информации после отключения пользователя от сети;
увеличение скорости и точности поиска, а также уменьшение загрузки сети за счет поиска информации непосредственно на сервере;
создание собственных баз информационных ресурсов, постоянно обновляемых и расширяемых;
реализацию возможности сотрудничества между агентами, что по-зволяет использовать накопленный опыт;
возможность автоматически корректировать и уточнять запросы, используя контекст и применяя модели пользователей.
В настоящее время существует несколько коммерческих МАС, предназначенных для интеллектуального поиска и обработки информации в сети Интернет, в частности системы Autonomy и Web Compass. Недостатком их является слабая способность к обучению. Поэтому основные усилия по совершенствованию интеллектуальных систем информационного поиска в сети Интернет направлены на развитие моделей представления знаний, механизмов вывода новых знаний, моделей рассуждения и способов обучения агентов.
Одним из успешных исследовательских проектов, выполненных в этом направлении, стал проект системы MARRI, разработанной для поиска Web-страниц, релевантных запросам в определенной предмет-
ной области. Для решения поставленной задачи система использует знания, представленные в виде онтологии, под которой понимается упорядоченное множество понятий предметной области.
Типы агентов системы MARRI:
агент пользователя (интерфейсный агент) обеспечивает
интеллектуальное взаимодействие с пользователем, поддерживает процесс формулирования запросов и представляет результаты поиска в виде списка URL или Web-страниц;
агенты-брокеры двух типов:
брокер типа URL предназначен для формирования списков интернет-адресов, поставляемых браузером (специальная клиентская программа, предназначенная для просмотра Web-узлов);
брокер типа HTML выполняет функции запоминания полученных Web-страниц и их распределения между агентами обработки текста;
интернет-агент (агент сети) обеспечивает считывание и анализ заданной страницы URL или Web-страницы (URL – автономная Java-программа с собственным сетевым адресом), выполняет обработку исключительных ситуаций (страница недоступна);
агент обработки текста сначала преобразует HTML-текст к пред-ставлению, с которым работают морфологический и синтаксический анализаторы, а затем проводит семантический анализ Web-страниц
для проверки их релевантности запросу на основе соответствующей онтологии.
Результат обработки текста представляется в виде синтаксического дерева, которое должно соответствовать какому-нибудь фрагменту ис-пользуемой онтологии.
Каждый из агентов наделен специальными знаниями, которые используются для повышения эффективности поиска информации. Агенты способны взаимодействовать друг с другом, обмениваться информацией, контактировать с Web-браузерами, анализаторами естественного языка и онтологическими БД.
Виртуальное предприятие
Создание виртуальных предприятий – одно из современных направлений бизнеса, которое в значительной мере стимулируется быстрым ростом информационных ресурсов и услуг, предоставляемых в сети Интернет. Кроме того, появлению виртуальных предприятий способствует сокращение времени ЖЦ создаваемых изделий и повышение уровня их сложности, так как при этом возникает необходимость оперативного объединения производственных, технологических и интеллектуальных ресурсов. Еще одна немаловажная причина – ужесто-чение конкуренции на товарных рынках, вынуждающая предприятия объединяться с целью выживания.
Виртуальное предприятие можно определить как кооперацию юридически независимых предприятий, организаций и отдельных лиц, которые производят продукцию или услуги в общем бизнес-процессе. Во внешнем мире виртуальное предприятие выступает как единая организация, в которой используются методы управления и администри-рования, основанные на применении информационных и телеком-муникационных технологий. Целью создания виртуального предприя-тия является объединение производственных, технологических, интел-лектуальных и инвестиционных ресурсов для продвижения на рынок новых товаров и услуг.
Поскольку каждое реальное предприятие в рамках виртуального выполняет только часть работ из общей технологической цепочки, то при его создании решаются две главные задачи:
декомпозиция общего бизнес-процесса на компоненты (подпро-цессы);
выбор рационального состава реальных предприятий-партнеров, которые будут осуществлять технологический процесс.
Первая задача решается с применением методов системного анализа, а для решения второй могут использоваться средства мульти-агентных технологий.
Задача оптимального распределения множества работ среди множества предприятий формулируется как задача о назначениях. Ее решение начинается с формирования множеств подпроцессов и по-тенциальных предприятий-участников. Затем строятся возможные ото-бражения из множества участников на множество подпроцессов и делается выбор наиболее приемлемого отображения, которое соответствует кон-кретным назначениям предприятий на бизнес-процессы. Для этого можно использовать механизм аукциона.
Пусть выделены бизнес-процессы А, В, С, Д, Е и участники-предприятия Р1, Р2, Р3, Р4, претендующие на их реализацию. Каждое из предприятий представлено интеллектуальным агентом, при этом Р1 выступает в роли инициатора создания виртуального предприятия (аукционера).
Перед началом аукциона аукционер (менеджер) формирует БД и БЗ об участниках аукциона. Затем он выставляет на продажу отдельные бизнес-процессы, информация о которых представлена стартовой ценой и требованиями по заданному набору показателей. Каждый претендент вы-двигает свои предложения по параметрам, которые он в состоянии обес-печить, и свою цену. Собрав и обработав эти предложения, аукционер с помощью некоторой модели рассуждения упорядочивает потенциальных претендентов с учетом собственной информации о них. После этого он принимает решение о выборе назначений или отвергает их и выдвигает новые предложения.
Задача создания виртуального предприятия относится к задачам структурного синтеза сложных систем, удовлетворяющих заданным требованиям.
Мультиагентные системы учебного назначения
При построении МАС для повышения эффективности деятельности обучаемого (студента) и преподавателя в вузе необходимо организовать взаимодействие различных источников знаний. В процессе обучения циркулируют следующие типы знаний:
предметные знания;
стратегические и методические знания, относящиеся к организации учебного процесса (сценарии обучения, формы проведения занятий);
педагогические знания;
эргономические знания об эффективности организации интерфейса преподавателей и студентов с компьютерными системами;
метазнания о способах компьютерной интеграции знаний.
Реализация программных агентов, оказывающих помощь обучаемым и преподавателю, позволяет создать дружественный, персонифицирован-ный интерфейс пользователя и повысить качество и эффективность учеб-ной деятельности.
Структура МАС учебного назначения включает в себя:
БЗ учебного процесса, предметной области, обучаемого и про-граммных агентов;
интерфейс преподавателя и студента, осуществляющий доступ к знаниям в процессе обучения;
онтологии, которые обеспечивают доступ к информации из БЗ предметной области и играют роль интерфейса между БЗ и другими агентами, обеспечивая доступ к ресурсам онтологии;
координатор взаимодействий, который выполняет роль посредника между агентами МАС.
Мультиагентная система обладает возможностью на основе модели обучаемого генерировать процесс обучения со всеми необходимыми функциями, а также поддерживать активную обратную связь студентов с преподавателем.
Глава 8. Хранилища данных и управление знаниями
8.1. Хранилища данных
Для устранения разрозненности, разнотипности, противоречивости данных используется концепция «хранилище данных» (ХД). Под ХД понимают предметно-ориентированную, интегрированную, некорректи-руемую, зависимую от времени коллекцию данных, предназначенную для поддержки принятия управленческих решений. Хранилище данных должно предложить такую среду накопления данных, которая оптимизирована для выполнения сложных аналитических запросов управленческого персонала. Данные в хранилище не предназначены для модификации. Предметная ориентация означает, что данные объединены и хранятся в соответствии с теми областями, которые они описывают. Интегрированность подразумевает, что данные должны удовлетворять требованиям всего предприятия. Некорректируемость заключается в том, что данные не создаются в ХД, а поступают из внешних источников, не подвергаются изменениям и не удаляются. Данные в ХД должны быть согласованы во времени.
При реализации ХД особое значение приобретают процессы извлечения, преобразования, анализа и представления. При извлечении данные приводятся к единому формату. Источники данных могут быть классифицированы по территориальному, административному признаку, степени достоверности, частоте обновляемости, количеству пользователей, секретности и используемым СУБД. Вся эта информация составляет основу словаря метаданных ХД, который призван обеспечить корректную периодическую актуализацию ХД.
Инструментальные средства (ИС) реализующие аналитические методы обработки данных, классифицируются по способу представления данных. Выделяют ИС, хранящие данные:
в реляционном виде, но имитирующие многоразмерность для пользователя;
в многоразмерных базах;
как в реляционном виде, так и в многоразмерных базах.
Помимо извлечения данных из БД для принятия решений, актуален процесс извлечения знаний для удовлетворения информационных потребностей пользователя. Если в ЭС основное внимание уделяется проблеме извлечения знаний от экспертов, то в данном случае знания извлекаются из БД.
С точки зрения пользователя в процессе извлечения знаний из БД должны решаться задачи преобразования данных (неструктурированных наборов чисел, символов) в информацию (описание обнаруженных закономерностей), информации в знания (значимые для пользователя закономерности), знаний в решения (последовательность действий, на-правленных на удовлетворение информационных потребностей поль-зователя).
Интеллектуальные средства извлечения знаний из БД позволяют выявить закономерности и вывести правила из них. Эти закономерности и правила можно использовать для принятия решений и прогнозирования их последствий. Существует несколько интеллектуальных методов выявления и анализа знаний: ассоциация, последовательность, классификация, кластеризация и прогнозирование. Ассоциация имеет место в том случае, когда несколько событий связаны друг с другом. Если существует цепочка связанных во времени событий, то говорят о последовательности. С по-мощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Кластеризация аналогична классификации, но отличается от нее тем, что сами группы еще
не сформированы. С помощью прогнозирования на основе особен-
ностей поведения данных оцениваются будущие значения непрерывно изменяющихся переменных (см. п. 2.5).
8.2. Управление знаниями
Понятие «управление знаниями» появилось в середине 90-х годов прошлого века в крупных корпорациях, где проблемы обработки информации приобрели особую остроту. Системы управления знаниями (Knowledge Management) получили название КМ-систем. Для их при-менения используются следующие технологии:
электронная почта;
базы и хранилища данных;
системы групповой поддержки;
браузеры и системы поиска;
корпоративные сети и Интернет;
ИИ-системы.
Хранилища данных, которые работают по принципу центрального склада, стали одним из первых инструментариев КМ. Управление знаниями – это совокупность процессов, которые управляют созданием, распространением, обработкой и использованием знаний внутри пред-приятия. Необходимость в разработке КМ-систем возникла в силу нескольких причин:
работники предприятия тратят слишком много времени на поиск необходимой информации;
опыт ведущих специалистов используется только ими самими;
ценная информация «захоронена» в огромном количестве докумен-тов, доступ к которым затруднен;
из-за недостаточной информированности и игнорирования преды-дущего опыта повторяются «дорогостоящие» ошибки.
Одним из новых решений по управлению знаниями является понятие корпоративной памяти, которая фиксирует информацию из различных источников предприятия и делает ее доступной специалистам для решения производственных задач. Корпоративная память не позволяет исчезнуть знаниям выбывающих специалистов. Различают два уровня корпоративной памяти:
-
Уровень материальной или явной информации – данные и знания, которые содержатся в документах организации в виде сообщений, статей, справочников, патентов, ПО.
-
Уровень персональной или скрытой информации – персо-нальные знания, неотрывно связанные с индивидуальным опытом, которые могут быть переданы через процедуры извлечения знаний. Скрытое зна-ние – основа СППР.
При разработке КМ-систем можно выделить следующие этапы:
-
Стихийное и бессистемное накопление информации в орга-низации.
-
Извлечение знаний – наиболее сложный и трудоемкий этап.
-
Структурирование – выделение основных понятий, выработка структуры представления информации.
-
Формализация – представление структурированной информа-ции на языках описания данных и знаний.
-
Обслуживание – корректировка данных и знаний.
Автоматизированные системы КМ OMIS (Organizational Memory Information Systems) предназначены для накопления и управления знаниями предприятия (рис. 8.1).
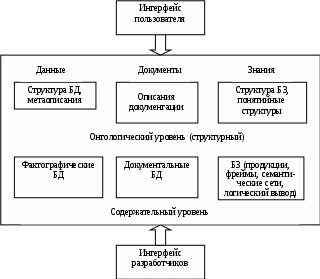
Рис. 8.1. Архитектура OMIS
Основные функции OMIS:
сбор и систематическая организация информации из различных источников в централизованное или структурное ХД;
интеграция с существующими автоматизированными системами;
обеспечение нужной информации по запросу.
В отличие от ЭС первичной целью систем OMIS является не поддержка одной задачи, а лучшая эксплуатация необходимого общего ресурса знаний.
Первые информационные системы на основе гипертекстовых (ГТ) моделей появились в середине 60-х годов ХХ века, но первые ком-мерческие ГТ-системы относятся к 1980-х годам. Под гипертекстом понимают технологию формирования информационных массивов в виде ассоциативных сетей, элементами или узлами которых выступают фраг-менты текста, рисунки, диаграммы. Навигация по таким сетям осу-ществляется по связям между узлами.
Основные функции связей:
переход к новой теме;
присоединение комментария к документу;
соединение ссылки на документ с документом, показ на экране графической информации;
запуск другой программы.
Мультимедиа (ММ) понимается как интегрированная компьютерная среда, позволяющая наряду с традиционными средствами взаимодействия человека и компьютера (дисплей, принтер, клавиатура) использовать новые возможности – звук, мультипликацию, видеоролики. Когда элементы ММ объединены на основе сети гипертекста, можно говорить о гипермедиа (ГМ). Основной сферой применения ГМ являются автома-тизированные обучающие системы или электронные учебники. Глобаль-ный успех в этом направлении получила сеть Интернет.
8.3. Технология создания систем управления знаниями
Проектирование систем управления знаниями (СУЗ) или КМ-систем декомпозируется на этапы, которые свойственны любой другой ИИ-системе. Вместе с тем имеется ряд особенностей:
коллективное использование знаний предполагает объединение и распределение источников знаний по различным субъектам, а следо-вательно, решение организационных вопросов администрирования и оп-тимизации деловых процессов, связывающих пользователей СУЗ;
задача проектирования СУЗ носит непрерывный характер, поскольку постоянно добавляются внешние источники данных;
поскольку СУЗ имеет многоцелевое значение, возникает потребность в интеграции разнообразных источников знаний на основе единого се-мантического описания пространства знаний.
Этапы проектирования СУЗ:
идентификация проблемной области:
определение типов решаемых задач;
отбор источников знаний;
определение категорий пользователей;
концептуализация:
выявление понятий (категорий);
выявление свойств (отношений);
построение правил (ограничений);
формализация:
выбор метода представления знаний;
представление знаний;
реализация:
создание онтологий;
аннотирование и подключение источников знаний;
настройка (создание) приложений;
внедрение:
тестирование;
развитие.
Онтология (от греч. «онтос» – сущее, «логос» – учение) – это точное (явное) описание концептуализации знаний, учение о сущем.
Идентификация проблемной области
В первую очередь определяется состав решаемых задач. Возможно создание узкоспециализированных систем по конкретным функциям управления: маркетинга, менеджмента, финансов. Разработка СУЗ может начинаться с отдельных областей, например с маркетинга, не требуя одновременной разработки всех необходимых онтологий и источников знаний. Для создания БЗ прецедентов требуется определить набор типовых бизнес-процессов, для которых будут отбираться прецеденты (например, разработка проектов, заключение договоров, проведение PR-акций). Центральное место в проектировании СУЗ занимает онтология, которая определяет и интегрирует все источники знаний. Требования разработки онтологий оформляются в виде спецификации требований (таблица).
Предметная
область
Подбор и повышение квалификации персонала компании
Назначение
Онтология служит для обмена знаниями между депар-таментом управления и менеджерами проектов при отборе персонала. Используется для семантического поиска квали-фикационных характеристик для выполнения определенных видов работ
Область значений
Онтология содержит концепты (категории) управления пер-соналом. Концепты используемых квалификаций в техно-логиях рассматриваются детально
Продолжение табл.
Предметная
область
Подбор и повышение квалификации персонала компании
Поддерживающие приложения
Система управления квалификацией персонала в ИНТРАНЕТ-среде
Источники знания
Web-страницы департамента управления персоналом
Руководство о развитии персонала
Спецификация продукции и технологий
Интервью с работниками департамента управления персо-налом и менеджерами проектов
Концептуализация знаний с помощью онтологий
Назначение онтологий – обеспечение возможностей:
повышения интеллектуальности СУЗ на основе того, что остается неявным;
стандартизации на основе описания целевого мира в виде словаря, разделения знаний между различными пользователями и компьютерными системами;
систематизации знаний, позволяющей интегрировать разнородные источники знаний на базе единой многоаспектной таксономии, пред-ставляемой в общем словаре;
снабжения необходимыми понятиями, отношениями и ограниче-ниями, которые используются как строительные блоки для создания конкретной модели решения задач;
постепенного обобщения понятий конкретной проблемной об-
ласти.
Требования к проектированию онтологий знаний:
ясность – четкая передача смысла введенных терминов (кон-
цептов);
согласованность – логическая непротиворечивость определений;
расширяемость – возможность монотонного расширения и специали-зации без необходимости пересмотра уже существующих понятий;
инвариантность к методам представления знаний;
отражение только наиболее существенных предположений о модели-руемом мире.
Онтологическое знание организуется на трех уровнях, в связи с чем выделяют онтологии:
верхнего уровня (метаонтология);
предметной области;
задач.
Метаонтология отражает такие общие понятия, как «сущность», «класс», «свойство», «значение», «типы данных», «типы отношений», «процесс», «событие». Определение общих категорий позволяет системе контролировать синтаксические конструкции понятий предметных и проблемных областей, которые идентифицирутся как наследники общих категорий.
Онтология предметной области определяет набор понятий, ис-пользуемых при решении различных интеллектуальных задач и независимых от применяемого метода. При построении онтологии предметной области выявляются свойства и отношения понятий, строятся логические правила, расширяющие семантику модели предметной области.
Онтология задач имеет дело с понятиями, описывающими методы преобразования объектов предметной области в процессе решения задач. Например, для задач обучения в качестве методов могут использоваться дедуктивный (от общего к частному), индуктивный (от частного к общему) и абдуктивный (от частного к частному). С помощью понятий, свойств и отношений описывается сущность используемых методов, устанавливается последовательность их выполнения. Введение онтологии задач позволяет расширить класс интеллектуальных задач, решаемых с помощью СУЗ, в частности перейти от простых поисковых задач к задаче конфигурации, когда система автоматически разбивает задачу на под-задачи, для каждой подзадачи выбирает метод решения, а для каждого метода – необходимые единицы предметных знаний. Такая СУЗ является не просто интеллектуальной информационно-поисковой системой, но и системой, которая планирует и генерирует решение задачи. В этом аспекте СУЗ должна обладать развитым механизмом вывода и по своей реализации сближается с классом ЭС, но на более развитой семанти-ческой основе.
Формализация онтологического знания
В основу формализации онтологий, с одной стороны, положены общепризнанные методы представления знаний (исчисление предикатов, семантические сети и фреймы), с другой методы описания онто-логических знаний с помощью специальных семантических конструк-
ций. В качестве языков представления онтологического знания исполь-зуются:
языки, основанные на исчислении предикатов;
HTML-подобные языки;
XML-подобные языки.
Языки, основанные на исчислении предикатов, построены на декларативной семантике и обеспечивают выражение произвольных логических предложений. С помощью этих языков хорошо представляется метазнание, что позволяет пользователю представлять знания в явном виде и разрешает пользователю применять новые конструкции представления знаний без изменения самого языка. Одним из таких языков является KIF, разработанный для обмена знаниями между различными программными агентами (ЛИСП-подобный язык).
HTML-подобные языки (Hypertext Markup Language) – инструмент разметки гипертекста. С использованием HTML создано более 60 % ресурсов современного Интернета. Браузер – специальная клиентская программа, предназначенная для просмотра содержимого Web-узлов и отображения документов HTML. В качестве основы для описания онтологий и онтологического аннотирования текстов может выступать язык разметки данных HTML, дополненный специальными тегами (указателями). С помощью тегов происходит выделение семан-тических фрагментов текста, которые унифицированно интерпрети-руются семантическими анализаторами различных ПС. Языки данной группы позволяют описать объекты онтологии (концепты), отношения между ними и определить правила вывода. Основное назначение таких языков состоит в возможности описания онтологии, аннотирования необходимых Web-страниц концептами онтологии и дальнейшем осу-ществлении поиска данных Web-страниц с помощью специальной по-исковой машины.
В качестве основы для XML-подобных языков выступает расширяемый язык разметки. В настоящее время существует около 20 различных языков, основанных на XML. Основным достоинством языка является то, что для работы с документами, подготовленными с помощью него, достаточно обычного интернет-браузера, т.е. не требуется никаких дополнительных средств. XML-документ представляет собой размеченное дерево. Структура XML описания обычного учебного курса приведена на рис. 8.2.
Язык XML не обладает практически никакими возможностями в области представления онтологий. В нем отсутствуют специальные конструкции, позволяющие описать взаимоотношения между концептами онтологии, правила вывода. Он предназначен исключительно для представления данных. Язык RDF, представляющий расширение XML, позволяет описать концепты, отношения между ними, поддерживает иерархию концептов и их наследование, задает некоторые правила вывода. Базовыми строительными блоками в RDF является триплет «объект –атрибут – значение», часто записываемый в виде A (O, V), который
читается как «объект О имеет атрибут А со значением V».
В семантической сети эту связь можно представить как ребро с меткой А, соединяющее два узла – О и V.
Р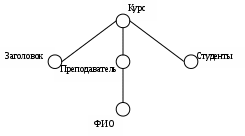
ис. 8.2. Размеченное дерево
Выбор ИС реализации СУЗ во многом определяется требуемой функциональностью использования СУЗ: информационным поиском в источниках знаний, коллективным решением задач, обучением и др. Для узкоспециализированных целей, ориентированных на поиск в интернет-ресурсах, применяются специализированные системы, например SHOE, которая обеспечивает аннотацию документов, сбор знаний в централи-зованную БЗ, выполнение поисковых запросов.
Инструментальные средства должны обеспечивать выполнение двух основных групп функций:
-
Создание и поддержание источников знаний:
создание и поддержание онтологий;
аннотирование источников знаний;
подключение источников знаний;
автоматическую рубрикацию и индексирование источников зна-ний;
-
Доступ к источникам знаний:
реализация запросов;
навигация и просмотр;
коммуникация пользователей;
распространение знаний.
Глава 9. Интеллектуальные информационные системы
в условиях неопределенности и риска
9.1. Понятие риска в системах поддержки принятий решений слабоструктурированных проблем
Экономические решения в зависимости от определенности воз-можных исходов или последствий рассматриваются в рамках трех моделей [16] выбора решения:
в условиях определенности, если относительно каждого действия известно, что оно неизменно приводит к некоторому исходу;
в ситуации риска, если каждое действие приводит к одному из множества возможных частных исходов, причем появление каждого исхода имеет вычисляемую или экспертно оцениваемую вероятность;
при неопределенности, когда то или иное действие имеет своим следствием множество частных исходов, но их вероятности неиз-
вестны.
Вероятностные методы обеспечивают подходящие условия для принятия решения и содержательные гарантии качества выбора. При этом исходят из предположения, что суждения относительно значений, предпочтений и намерений представляют собой ценные абстракции человеческого опыта и их можно обрабатывать для принятия решений.
В то время как суждения относительно правдоподобия событий квалифицируются вероятностями, суждения относительно желательности действий представляются понятиями. Байесовская методология рас-сматривает ожидаемую полезность U(d) как оценку качества решения d.
В соответствии с этим, если мы можем выбрать либо действие d1, либо d2, вычисляем U(d1), U(d2) и выбираем действие, которое соответствует наибольшему значению. Семантика полезности состоит в том, чтобы описать риск.
Под риском принято понимать вероятность (угрозу) утраты лицом или организацией части своих ресурсов, недополучения доходов или появления дополнительных расходов в результате осуществления определенной финансовой политики.
Уровень риска – это объективная или субъективная вероятность возникновения потерь. Под объективной вероятностью понимается ко-личественная мера возможности наступления случайного события, по-лученная с помощью расчетов или опыта, позволяющая оценить веро-ятность выявления данного события. Субъективная вероятность пред-ставляет собой меру уверенности в истинности высказанного суждения и устанавливается экспертным путем.
Уровни риска наиболее легко устанавливаются при помощи атрибутивных оценок типа «высокий», «средний», «небольшой». Разно-видностью атрибутивной оценки рисков является буквенная кодировка. При этом в порядке нарастания риска и падения надежности используются латинские буквы от А до D.
AAA – самая высокая надежность;
AA – очень высокая надежность;
A – высокая надежность;
…
D – максимальный риск.
Оценивать уровень риска можно, используя показатели бухгалтер-ской и статистической отчетности, в первую очередь КТЛ – коэффициент текущей ликвидности, который представляет собой соотношение ликвид-ных средств партнера и его долгов.
В результате анализа ситуации строятся причинно-следственные диаграммы («дерево причин») и диаграммы зависимостей. Причинно-следственная диаграмма является формальным отображением структуры проблемной ситуации в виде иерархически незамкнутого графа, вер-шины которого соответствуют элементам проблемы, отражающим при-чины ее возникновения, а дуги – связям между ними. Связь элементов-подпроблем отображается в виде отношения «причина – следствие» (рис. 9.1).
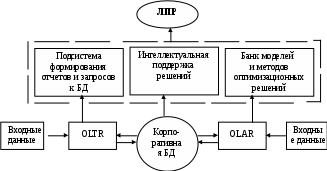
Рис. 9.1. Модель системы поддержки принятия решений:
OLTR – средства складирования данных и оперативной обработки транзакций; OLAR – средства оперативной обработки информации
Корпоративная БД, организованная в виде ХД, заполняется ин-формацией с использованием технологий OLTR и OLAR. Для создания и реализации СППР слабоструктурированных проблем должны быть разработаны и адаптированы к ее условиям следующие методы и средства:
система признаков для регистрации проблемных ситуаций;
методы оценки степени критичности проблемных ситуаций;
причинно-следственные диаграммы для диагностирования причин возникновения проблемных ситуаций;
таблица принятия решений для формирования и выбора вариантов решений;
методы прогнозирования результатов решений;
модели функционирования предприятия и внешней среды.
Наиболее распространенной формой выявления проблем с исполь-зованием технико-экономических показателей является сравнение их фактических величин с нормативными и средними значениями.
Логический анализ проблем-причин, находящихся на нижних уровнях иерархии, показывает, что во многих случаях они позволяют сформировать варианты решения проблем более высокого уровня. Например, возможны следующие варианты решения проблемы снижения объемов производства и сбыта продукции:
варьирование ценами;
варьирование формами оплаты;
снижение численности работающих;
сокращение доли условно-постоянных расходов в себестоимости продукции;
сокращение сроков выполнения заказов;
усиление службы маркетинга.
Когда отсутствуют статистические данные, необходимые для расчета объективной вероятности риска, прибегают к субъективным оценкам, основанным на интуиции и опыте экспертов. Дж. Кейнс
ввел понятие субъективной вероятности. В соответствии с принципом безразличия одинаково правдоподобные события или суждения долж-
ны иметь одинаковую вероятность, что математически записывается
так:
А
В ≡ Р(А) = Р(В),
где
– знак, выражающий отношение безразличия, или толерантности.
8.1. Хранилища данных
Для устранения разрозненности, разнотипности, противоречивости данных используется концепция «хранилище данных» (ХД). Под ХД понимают предметно-ориентированную, интегрированную, некорректи-руемую, зависимую от времени коллекцию данных, предназначенную для поддержки принятия управленческих решений. Хранилище данных должно предложить такую среду накопления данных, которая оптимизирована для выполнения сложных аналитических запросов управленческого персонала. Данные в хранилище не предназначены для модификации. Предметная ориентация означает, что данные объединены и хранятся в соответствии с теми областями, которые они описывают. Интегрированность подразумевает, что данные должны удовлетворять требованиям всего предприятия. Некорректируемость заключается в том, что данные не создаются в ХД, а поступают из внешних источников, не подвергаются изменениям и не удаляются. Данные в ХД должны быть согласованы во времени.
При реализации ХД особое значение приобретают процессы извлечения, преобразования, анализа и представления. При извлечении данные приводятся к единому формату. Источники данных могут быть классифицированы по территориальному, административному признаку, степени достоверности, частоте обновляемости, количеству пользователей, секретности и используемым СУБД. Вся эта информация составляет основу словаря метаданных ХД, который призван обеспечить корректную периодическую актуализацию ХД.
Инструментальные средства (ИС) реализующие аналитические методы обработки данных, классифицируются по способу представления данных. Выделяют ИС, хранящие данные:
в реляционном виде, но имитирующие многоразмерность для пользователя;
в многоразмерных базах;
как в реляционном виде, так и в многоразмерных базах.
Помимо извлечения данных из БД для принятия решений, актуален процесс извлечения знаний для удовлетворения информационных потребностей пользователя. Если в ЭС основное внимание уделяется проблеме извлечения знаний от экспертов, то в данном случае знания извлекаются из БД.
С точки зрения пользователя в процессе извлечения знаний из БД должны решаться задачи преобразования данных (неструктурированных наборов чисел, символов) в информацию (описание обнаруженных закономерностей), информации в знания (значимые для пользователя закономерности), знаний в решения (последовательность действий, на-правленных на удовлетворение информационных потребностей поль-зователя).
Интеллектуальные средства извлечения знаний из БД позволяют выявить закономерности и вывести правила из них. Эти закономерности и правила можно использовать для принятия решений и прогнозирования их последствий. Существует несколько интеллектуальных методов выявления и анализа знаний: ассоциация, последовательность, классификация, кластеризация и прогнозирование. Ассоциация имеет место в том случае, когда несколько событий связаны друг с другом. Если существует цепочка связанных во времени событий, то говорят о последовательности. С по-мощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Кластеризация аналогична классификации, но отличается от нее тем, что сами группы еще
не сформированы. С помощью прогнозирования на основе особен-
ностей поведения данных оцениваются будущие значения непрерывно изменяющихся переменных (см. п. 2.5).
8.2. Управление знаниями
Понятие «управление знаниями» появилось в середине 90-х годов прошлого века в крупных корпорациях, где проблемы обработки информации приобрели особую остроту. Системы управления знаниями (Knowledge Management) получили название КМ-систем. Для их при-менения используются следующие технологии:
электронная почта;
базы и хранилища данных;
системы групповой поддержки;
браузеры и системы поиска;
корпоративные сети и Интернет;
ИИ-системы.
Хранилища данных, которые работают по принципу центрального склада, стали одним из первых инструментариев КМ. Управление знаниями – это совокупность процессов, которые управляют созданием, распространением, обработкой и использованием знаний внутри пред-приятия. Необходимость в разработке КМ-систем возникла в силу нескольких причин:
работники предприятия тратят слишком много времени на поиск необходимой информации;
опыт ведущих специалистов используется только ими самими;
ценная информация «захоронена» в огромном количестве докумен-тов, доступ к которым затруднен;
из-за недостаточной информированности и игнорирования преды-дущего опыта повторяются «дорогостоящие» ошибки.
Одним из новых решений по управлению знаниями является понятие корпоративной памяти, которая фиксирует информацию из различных источников предприятия и делает ее доступной специалистам для решения производственных задач. Корпоративная память не позволяет исчезнуть знаниям выбывающих специалистов. Различают два уровня корпоративной памяти:
-
Уровень материальной или явной информации – данные и знания, которые содержатся в документах организации в виде сообщений, статей, справочников, патентов, ПО. -
Уровень персональной или скрытой информации – персо-нальные знания, неотрывно связанные с индивидуальным опытом, которые могут быть переданы через процедуры извлечения знаний. Скрытое зна-ние – основа СППР.
При разработке КМ-систем можно выделить следующие этапы:
-
Стихийное и бессистемное накопление информации в орга-низации. -
Извлечение знаний – наиболее сложный и трудоемкий этап. -
Структурирование – выделение основных понятий, выработка структуры представления информации. -
Формализация – представление структурированной информа-ции на языках описания данных и знаний. -
Обслуживание – корректировка данных и знаний.
Автоматизированные системы КМ OMIS (Organizational Memory Information Systems) предназначены для накопления и управления знаниями предприятия (рис. 8.1).
Рис. 8.1. Архитектура OMIS
Основные функции OMIS:
сбор и систематическая организация информации из различных источников в централизованное или структурное ХД;
интеграция с существующими автоматизированными системами;
обеспечение нужной информации по запросу.
В отличие от ЭС первичной целью систем OMIS является не поддержка одной задачи, а лучшая эксплуатация необходимого общего ресурса знаний.
Первые информационные системы на основе гипертекстовых (ГТ) моделей появились в середине 60-х годов ХХ века, но первые ком-мерческие ГТ-системы относятся к 1980-х годам. Под гипертекстом понимают технологию формирования информационных массивов в виде ассоциативных сетей, элементами или узлами которых выступают фраг-менты текста, рисунки, диаграммы. Навигация по таким сетям осу-ществляется по связям между узлами.
Основные функции связей:
переход к новой теме;
присоединение комментария к документу;
соединение ссылки на документ с документом, показ на экране графической информации;
запуск другой программы.
Мультимедиа (ММ) понимается как интегрированная компьютерная среда, позволяющая наряду с традиционными средствами взаимодействия человека и компьютера (дисплей, принтер, клавиатура) использовать новые возможности – звук, мультипликацию, видеоролики. Когда элементы ММ объединены на основе сети гипертекста, можно говорить о гипермедиа (ГМ). Основной сферой применения ГМ являются автома-тизированные обучающие системы или электронные учебники. Глобаль-ный успех в этом направлении получила сеть Интернет.
8.3. Технология создания систем управления знаниями
Проектирование систем управления знаниями (СУЗ) или КМ-систем декомпозируется на этапы, которые свойственны любой другой ИИ-системе. Вместе с тем имеется ряд особенностей:
коллективное использование знаний предполагает объединение и распределение источников знаний по различным субъектам, а следо-вательно, решение организационных вопросов администрирования и оп-тимизации деловых процессов, связывающих пользователей СУЗ;
задача проектирования СУЗ носит непрерывный характер, поскольку постоянно добавляются внешние источники данных;
поскольку СУЗ имеет многоцелевое значение, возникает потребность в интеграции разнообразных источников знаний на основе единого се-мантического описания пространства знаний.
Этапы проектирования СУЗ:
идентификация проблемной области:
определение типов решаемых задач;
отбор источников знаний;
определение категорий пользователей;
концептуализация:
выявление понятий (категорий);
выявление свойств (отношений);
построение правил (ограничений);
формализация:
выбор метода представления знаний;
представление знаний;
реализация:
создание онтологий;
аннотирование и подключение источников знаний;
настройка (создание) приложений;
внедрение:
тестирование;
развитие.
Онтология (от греч. «онтос» – сущее, «логос» – учение) – это точное (явное) описание концептуализации знаний, учение о сущем.
Идентификация проблемной области
В первую очередь определяется состав решаемых задач. Возможно создание узкоспециализированных систем по конкретным функциям управления: маркетинга, менеджмента, финансов. Разработка СУЗ может начинаться с отдельных областей, например с маркетинга, не требуя одновременной разработки всех необходимых онтологий и источников знаний. Для создания БЗ прецедентов требуется определить набор типовых бизнес-процессов, для которых будут отбираться прецеденты (например, разработка проектов, заключение договоров, проведение PR-акций). Центральное место в проектировании СУЗ занимает онтология, которая определяет и интегрирует все источники знаний. Требования разработки онтологий оформляются в виде спецификации требований (таблица).
| Предметная область | Подбор и повышение квалификации персонала компании |
| Назначение | Онтология служит для обмена знаниями между депар-таментом управления и менеджерами проектов при отборе персонала. Используется для семантического поиска квали-фикационных характеристик для выполнения определенных видов работ |
| Область значений | Онтология содержит концепты (категории) управления пер-соналом. Концепты используемых квалификаций в техно-логиях рассматриваются детально |
| Продолжение табл. | |
| Предметная область | Подбор и повышение квалификации персонала компании |
| Поддерживающие приложения | Система управления квалификацией персонала в ИНТРАНЕТ-среде |
| Источники знания | Web-страницы департамента управления персоналом Руководство о развитии персонала Спецификация продукции и технологий Интервью с работниками департамента управления персо-налом и менеджерами проектов |
Концептуализация знаний с помощью онтологий
Назначение онтологий – обеспечение возможностей:
повышения интеллектуальности СУЗ на основе того, что остается неявным;
стандартизации на основе описания целевого мира в виде словаря, разделения знаний между различными пользователями и компьютерными системами;
систематизации знаний, позволяющей интегрировать разнородные источники знаний на базе единой многоаспектной таксономии, пред-ставляемой в общем словаре;
снабжения необходимыми понятиями, отношениями и ограниче-ниями, которые используются как строительные блоки для создания конкретной модели решения задач;
постепенного обобщения понятий конкретной проблемной об-
ласти.
Требования к проектированию онтологий знаний:
ясность – четкая передача смысла введенных терминов (кон-
цептов);
согласованность – логическая непротиворечивость определений;
расширяемость – возможность монотонного расширения и специали-зации без необходимости пересмотра уже существующих понятий;
инвариантность к методам представления знаний;
отражение только наиболее существенных предположений о модели-руемом мире.
Онтологическое знание организуется на трех уровнях, в связи с чем выделяют онтологии:
верхнего уровня (метаонтология);
предметной области;
задач.
Метаонтология отражает такие общие понятия, как «сущность», «класс», «свойство», «значение», «типы данных», «типы отношений», «процесс», «событие». Определение общих категорий позволяет системе контролировать синтаксические конструкции понятий предметных и проблемных областей, которые идентифицирутся как наследники общих категорий.
Онтология предметной области определяет набор понятий, ис-пользуемых при решении различных интеллектуальных задач и независимых от применяемого метода. При построении онтологии предметной области выявляются свойства и отношения понятий, строятся логические правила, расширяющие семантику модели предметной области.
Онтология задач имеет дело с понятиями, описывающими методы преобразования объектов предметной области в процессе решения задач. Например, для задач обучения в качестве методов могут использоваться дедуктивный (от общего к частному), индуктивный (от частного к общему) и абдуктивный (от частного к частному). С помощью понятий, свойств и отношений описывается сущность используемых методов, устанавливается последовательность их выполнения. Введение онтологии задач позволяет расширить класс интеллектуальных задач, решаемых с помощью СУЗ, в частности перейти от простых поисковых задач к задаче конфигурации, когда система автоматически разбивает задачу на под-задачи, для каждой подзадачи выбирает метод решения, а для каждого метода – необходимые единицы предметных знаний. Такая СУЗ является не просто интеллектуальной информационно-поисковой системой, но и системой, которая планирует и генерирует решение задачи. В этом аспекте СУЗ должна обладать развитым механизмом вывода и по своей реализации сближается с классом ЭС, но на более развитой семанти-ческой основе.
Формализация онтологического знания
В основу формализации онтологий, с одной стороны, положены общепризнанные методы представления знаний (исчисление предикатов, семантические сети и фреймы), с другой методы описания онто-логических знаний с помощью специальных семантических конструк-
ций. В качестве языков представления онтологического знания исполь-зуются:
языки, основанные на исчислении предикатов;
HTML-подобные языки;
XML-подобные языки.
Языки, основанные на исчислении предикатов, построены на декларативной семантике и обеспечивают выражение произвольных логических предложений. С помощью этих языков хорошо представляется метазнание, что позволяет пользователю представлять знания в явном виде и разрешает пользователю применять новые конструкции представления знаний без изменения самого языка. Одним из таких языков является KIF, разработанный для обмена знаниями между различными программными агентами (ЛИСП-подобный язык).
HTML-подобные языки (Hypertext Markup Language) – инструмент разметки гипертекста. С использованием HTML создано более 60 % ресурсов современного Интернета. Браузер – специальная клиентская программа, предназначенная для просмотра содержимого Web-узлов и отображения документов HTML. В качестве основы для описания онтологий и онтологического аннотирования текстов может выступать язык разметки данных HTML, дополненный специальными тегами (указателями). С помощью тегов происходит выделение семан-тических фрагментов текста, которые унифицированно интерпрети-руются семантическими анализаторами различных ПС. Языки данной группы позволяют описать объекты онтологии (концепты), отношения между ними и определить правила вывода. Основное назначение таких языков состоит в возможности описания онтологии, аннотирования необходимых Web-страниц концептами онтологии и дальнейшем осу-ществлении поиска данных Web-страниц с помощью специальной по-исковой машины.
В качестве основы для XML-подобных языков выступает расширяемый язык разметки. В настоящее время существует около 20 различных языков, основанных на XML. Основным достоинством языка является то, что для работы с документами, подготовленными с помощью него, достаточно обычного интернет-браузера, т.е. не требуется никаких дополнительных средств. XML-документ представляет собой размеченное дерево. Структура XML описания обычного учебного курса приведена на рис. 8.2.
Язык XML не обладает практически никакими возможностями в области представления онтологий. В нем отсутствуют специальные конструкции, позволяющие описать взаимоотношения между концептами онтологии, правила вывода. Он предназначен исключительно для представления данных. Язык RDF, представляющий расширение XML, позволяет описать концепты, отношения между ними, поддерживает иерархию концептов и их наследование, задает некоторые правила вывода. Базовыми строительными блоками в RDF является триплет «объект –атрибут – значение», часто записываемый в виде A (O, V), который
читается как «объект О имеет атрибут А со значением V».
В семантической сети эту связь можно представить как ребро с меткой А, соединяющее два узла – О и V.
Р
ис. 8.2. Размеченное дерево
Выбор ИС реализации СУЗ во многом определяется требуемой функциональностью использования СУЗ: информационным поиском в источниках знаний, коллективным решением задач, обучением и др. Для узкоспециализированных целей, ориентированных на поиск в интернет-ресурсах, применяются специализированные системы, например SHOE, которая обеспечивает аннотацию документов, сбор знаний в централи-зованную БЗ, выполнение поисковых запросов.
Инструментальные средства должны обеспечивать выполнение двух основных групп функций:
-
Создание и поддержание источников знаний:
создание и поддержание онтологий;
аннотирование источников знаний;
подключение источников знаний;
автоматическую рубрикацию и индексирование источников зна-ний;
-
Доступ к источникам знаний:
реализация запросов;
навигация и просмотр;
коммуникация пользователей;
распространение знаний.
Глава 9. Интеллектуальные информационные системы
в условиях неопределенности и риска
9.1. Понятие риска в системах поддержки принятий решений слабоструктурированных проблем
Экономические решения в зависимости от определенности воз-можных исходов или последствий рассматриваются в рамках трех моделей [16] выбора решения:
в условиях определенности, если относительно каждого действия известно, что оно неизменно приводит к некоторому исходу;
в ситуации риска, если каждое действие приводит к одному из множества возможных частных исходов, причем появление каждого исхода имеет вычисляемую или экспертно оцениваемую вероятность;
при неопределенности, когда то или иное действие имеет своим следствием множество частных исходов, но их вероятности неиз-
вестны.
Вероятностные методы обеспечивают подходящие условия для принятия решения и содержательные гарантии качества выбора. При этом исходят из предположения, что суждения относительно значений, предпочтений и намерений представляют собой ценные абстракции человеческого опыта и их можно обрабатывать для принятия решений.
В то время как суждения относительно правдоподобия событий квалифицируются вероятностями, суждения относительно желательности действий представляются понятиями. Байесовская методология рас-сматривает ожидаемую полезность U(d) как оценку качества решения d.
В соответствии с этим, если мы можем выбрать либо действие d1, либо d2, вычисляем U(d1), U(d2) и выбираем действие, которое соответствует наибольшему значению. Семантика полезности состоит в том, чтобы описать риск.
Под риском принято понимать вероятность (угрозу) утраты лицом или организацией части своих ресурсов, недополучения доходов или появления дополнительных расходов в результате осуществления определенной финансовой политики.
Уровень риска – это объективная или субъективная вероятность возникновения потерь. Под объективной вероятностью понимается ко-личественная мера возможности наступления случайного события, по-лученная с помощью расчетов или опыта, позволяющая оценить веро-ятность выявления данного события. Субъективная вероятность пред-ставляет собой меру уверенности в истинности высказанного суждения и устанавливается экспертным путем.
Уровни риска наиболее легко устанавливаются при помощи атрибутивных оценок типа «высокий», «средний», «небольшой». Разно-видностью атрибутивной оценки рисков является буквенная кодировка. При этом в порядке нарастания риска и падения надежности используются латинские буквы от А до D.
AAA – самая высокая надежность;
AA – очень высокая надежность;
A – высокая надежность;
…
D – максимальный риск.
Оценивать уровень риска можно, используя показатели бухгалтер-ской и статистической отчетности, в первую очередь КТЛ – коэффициент текущей ликвидности, который представляет собой соотношение ликвид-ных средств партнера и его долгов.
В результате анализа ситуации строятся причинно-следственные диаграммы («дерево причин») и диаграммы зависимостей. Причинно-следственная диаграмма является формальным отображением структуры проблемной ситуации в виде иерархически незамкнутого графа, вер-шины которого соответствуют элементам проблемы, отражающим при-чины ее возникновения, а дуги – связям между ними. Связь элементов-подпроблем отображается в виде отношения «причина – следствие» (рис. 9.1).
Рис. 9.1. Модель системы поддержки принятия решений:
OLTR – средства складирования данных и оперативной обработки транзакций; OLAR – средства оперативной обработки информации
Корпоративная БД, организованная в виде ХД, заполняется ин-формацией с использованием технологий OLTR и OLAR. Для создания и реализации СППР слабоструктурированных проблем должны быть разработаны и адаптированы к ее условиям следующие методы и средства:
система признаков для регистрации проблемных ситуаций;
методы оценки степени критичности проблемных ситуаций;
причинно-следственные диаграммы для диагностирования причин возникновения проблемных ситуаций;
таблица принятия решений для формирования и выбора вариантов решений;
методы прогнозирования результатов решений;
модели функционирования предприятия и внешней среды.
Наиболее распространенной формой выявления проблем с исполь-зованием технико-экономических показателей является сравнение их фактических величин с нормативными и средними значениями.
Логический анализ проблем-причин, находящихся на нижних уровнях иерархии, показывает, что во многих случаях они позволяют сформировать варианты решения проблем более высокого уровня. Например, возможны следующие варианты решения проблемы снижения объемов производства и сбыта продукции:
варьирование ценами;
варьирование формами оплаты;
снижение численности работающих;
сокращение доли условно-постоянных расходов в себестоимости продукции;
сокращение сроков выполнения заказов;
усиление службы маркетинга.
Когда отсутствуют статистические данные, необходимые для расчета объективной вероятности риска, прибегают к субъективным оценкам, основанным на интуиции и опыте экспертов. Дж. Кейнс
ввел понятие субъективной вероятности. В соответствии с принципом безразличия одинаково правдоподобные события или суждения долж-
ны иметь одинаковую вероятность, что математически записывается
так:
А