Добавлен: 20.10.2018
Просмотров: 828
Скачиваний: 8
Тема 29. Физическая организация данных
На физическом уровне БД реализуется в виде совокупности файлов.
Будем считать, что каждый файл состоит из записей одного формата. Связи
представляются с помощью указателей на записи. Если на некоторую запись в
БД есть указатель, то эта запись считается закрепленной на месте. В противном
случае запись не закреплена. Над файлом могут быть выполнены операции
включения, удаления, модификации записи и поиска записи с указанными
значениями полей.
Распространенными
способами
организации
файлов
являются
хеширование, индексирование и представление в виде сбалансированных
деревьев.
Хешированные файлы
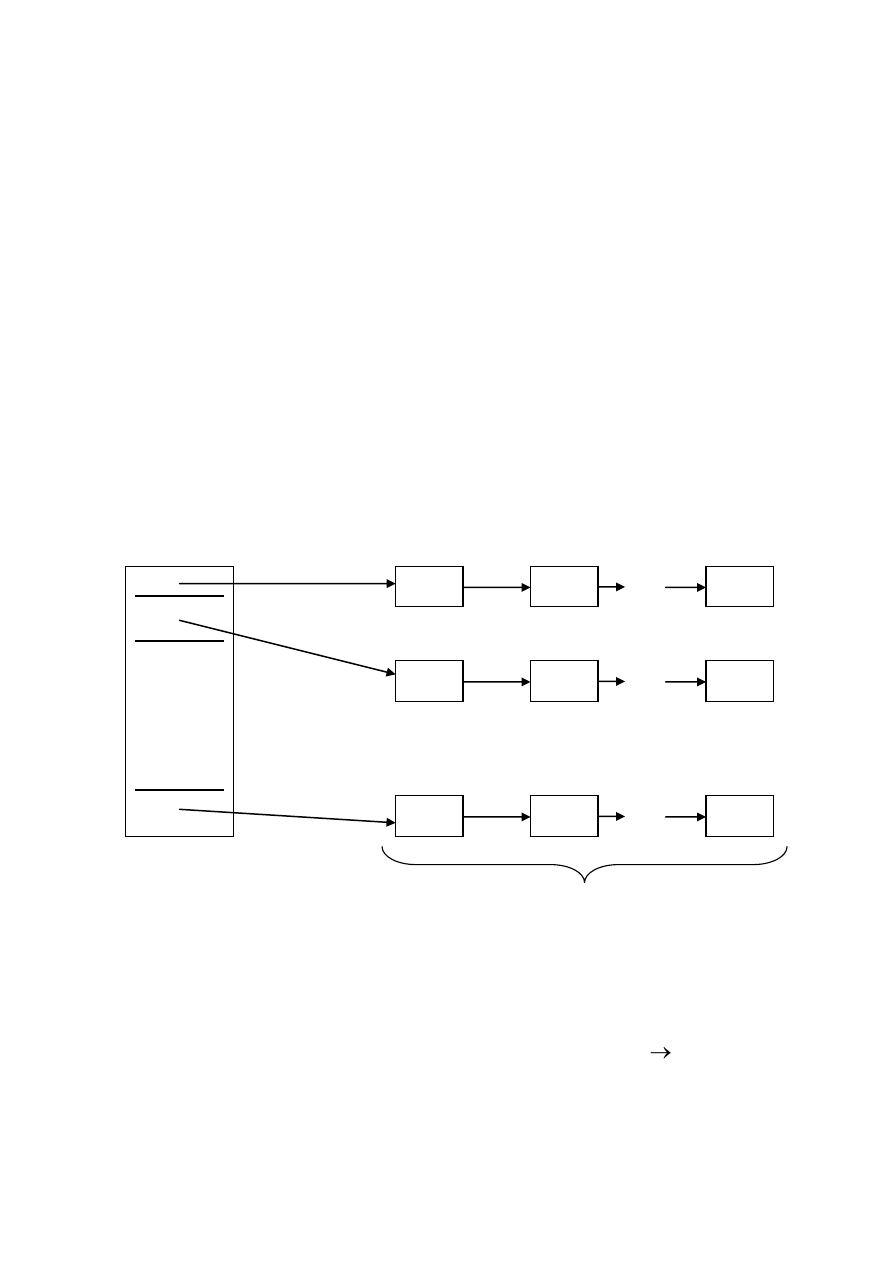
Хешированный файл (рис. 29.1) состоит из справочника и набора
участков, участок состоит из одного или более блоков. Записи файла
распределяются по участкам с помощью хеш-функции h:V N (V – домен
значений ключа, N – домен номеров участков). Для значения v ключа величина
h(v) есть номер участка, в котором находится запись с данным значением
B
01
B
02
B
0m
…
B
11
B
12
B
1m
…
B
n1
B
n2
B
nm
…
…………
0
1
…
n
Справочник
участков
Участок
Рис. 29.1. Хешированный файл.
ключа. Желательно, чтобы функция h хешировала ключ V, т.е. равномерно
отображала значения ключа в номера участков.
Один из простейших алгоритмов хеширования:
1. Ключ рассматривается как последовательность битов.
2. Биты ключа делятся на группы фиксированной длины.
3. Группы складываются как целые числа.
4. Номер участка вычисляется как остаток от деления полученной
суммы на число участков.
Для поиска записи с заданным значением v ключа вычисляется h(v)
(номер участка), из справочника извлекается ссылка на первый блок участка,
последовательно просматриваются блоки участка.
Индексированные файлы
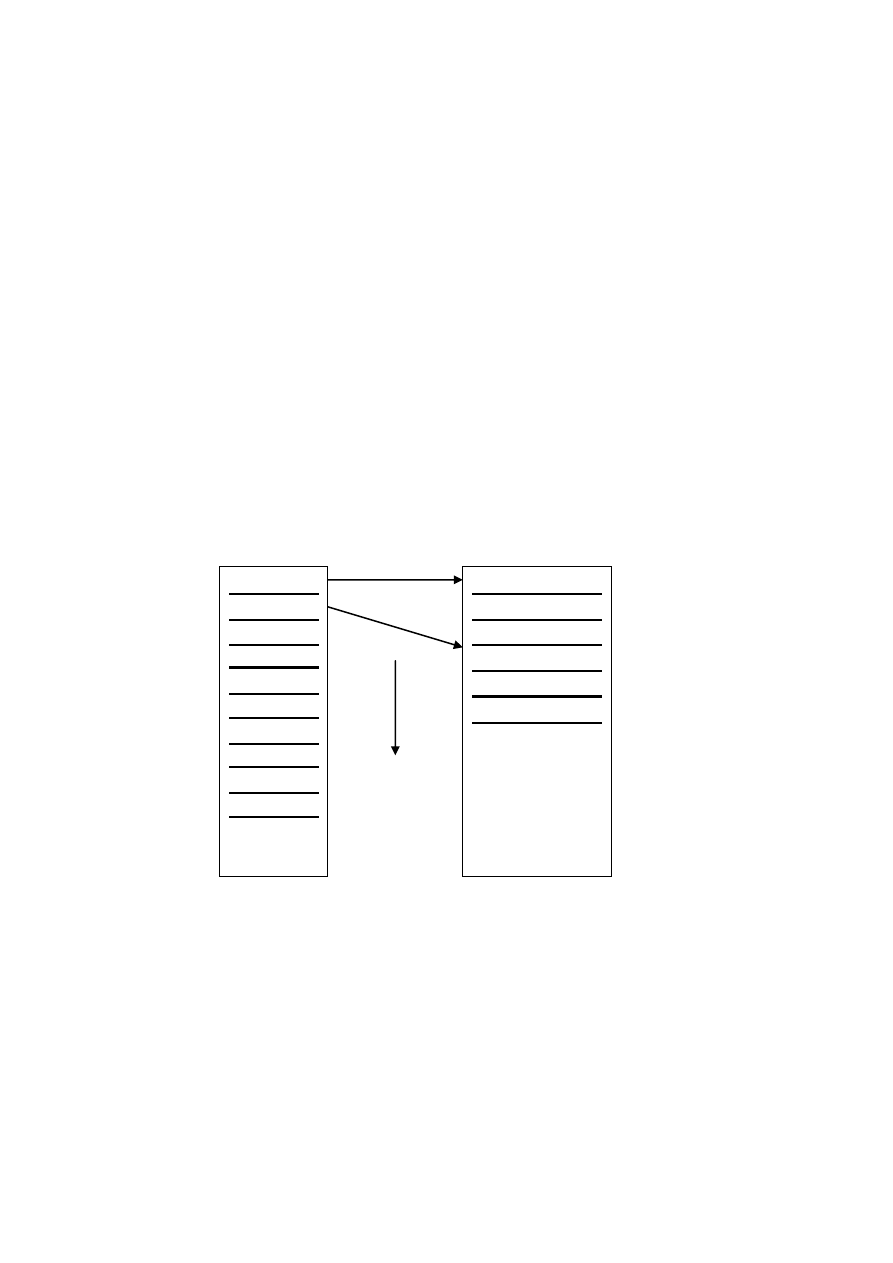
Индексированный файл (рис.29.2) состоит из главного файла,
содержащего записи БД, и файла индекса, записи которого хранят пары (ключ
записи, указатель блока). Оба файла упорядочены по возрастанию ключа.
Упорядочен-
ность ключа
v
1
| b
1
v
2
| b
2
…
v
m
| b
m
v
m+1
| b
m+1
…
…
v
n
| b
n
v
n+1
| b
n+1
…
…
Блок 1
Блок 2
Блок k
Запись v
1
Запись v
11
…
Запись v
2
Запись v
21
…
…
Блок b
1
Блок b
2
Файл
индекса
Главный
файл
Рис. 29.2. Индексированный файл.


Индексная запись (v,b) состоит из указателя блока главного файла и ключа
первой записи блока (разреженный индекс).
Над файлом индекса выполняются те же операции, что и над главным
файлом. Дополнительно выполняется следующая операция: для заданного
значения ключа v
1
найти в индексе такую запись (v
2
,b), что v
1
>=v
2
и либо (v
2
,b)
– последняя запись в индексе, либо следующая запись (v
3
,b) такова, что v
1
<v
3
. В
этом случае говорят, что значение v
2
покрывает v
1
. Таким способом находят
блок главного файла, содержащий запись со значением ключа v
1
.
Поиск в индексе
Индекс хранится в известной совокупности блоков. Требуется найти
индексную запись (v
2
,b), покрывающую заданное значение v
1
ключа.
Простейший вид поиска – линейный поиск.
Двоичный поиск. Если задано значение v
1
ключа и индекс, включающий
блоки B
1
, …B
n
, то рассматривается средний блок B
n/2
и v
1
сравнивается со
значением v
2
ключа в первой записи этого блока ( x - округление до
ближайшего целого сверху). При v
1
<v
2
процесс повторяется над блоками B
1
, …
B
n/2 -1
. Если v
1
>=v
2
, то процесс повторяется над блоками B
n/2
, …B
n
. В конце
концов, останется единственный блок, который просматривается линейно.
Двоичный поиск требует примерно log
2
n чтений блоков индекса.
Интерполяция. Метод основан на знании распределения значений
ключа.
Пусть v
2
<=v
1
<=v
3
и имеется функция f(v
1
,v
2
,v
3
)=0 1, которая указывает
ожидаемое положение v
1
на пути от v
2
к v
3
. Пусть индекс размещается в блоках
B
1
, … B
n
и v
2
- первый ключ в B
1
, а v
3
- последний в B
n
. Рассмотрим блок B
i
, где
I = nf(v
1
,v
2
,v
3
) , и сравним его первый ключ с v
1
. Далее как и в двоичном
поиске, повторяем процесс либо над B
1
, … B
i-1
, либо над B
i
, … B
n
в
зависимости от результатов сравнения и т.д.
Можно показать, что при знании распределения значений ключа
потребуется около 1+log
2
log
2
n доступов к блокам индекса.
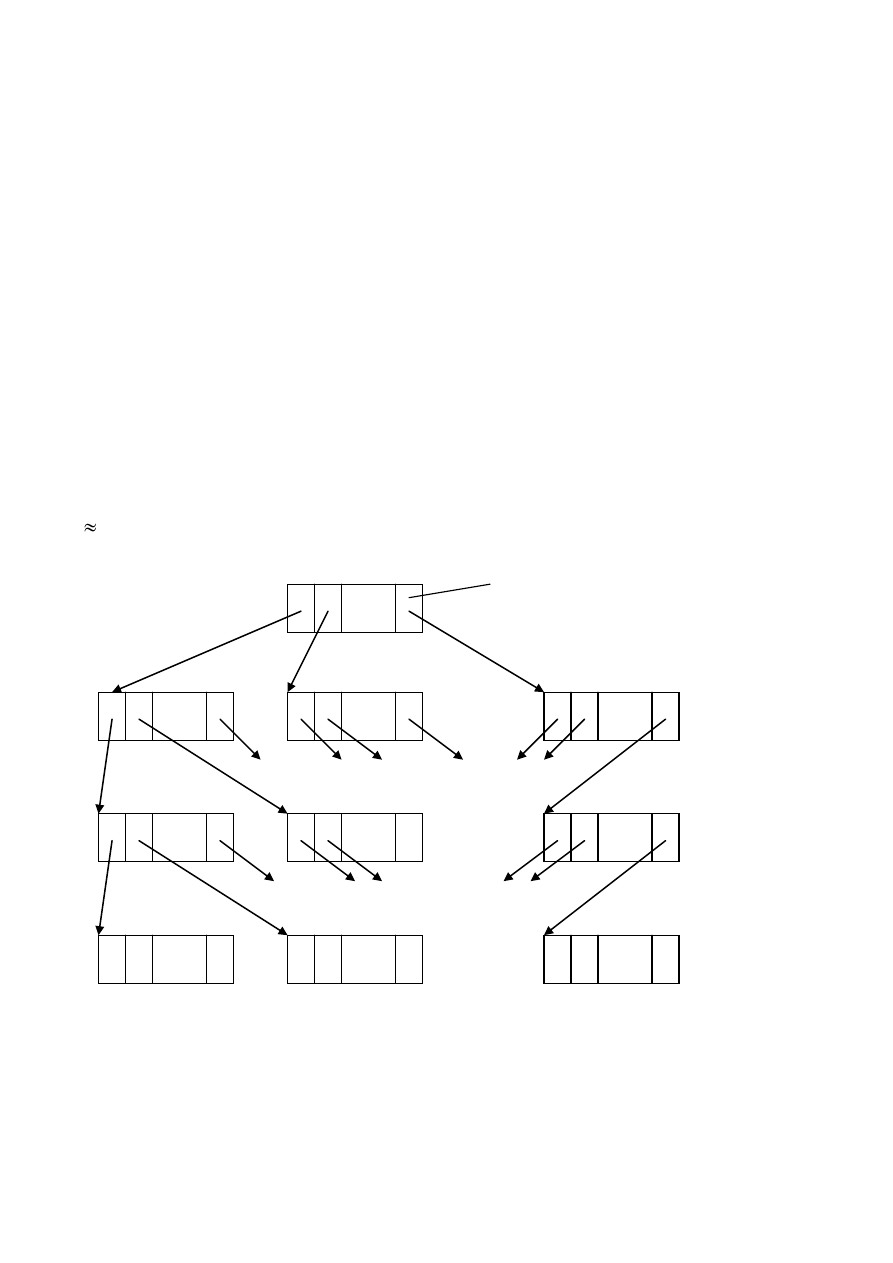
Сбалансированные деревья (B – деревья)
B-дерево (рис.29.3) является многоуровневым индексом, в котором
каждый путь от корня (индекса первого уровня) до листа (блока главного
файла) имеет одну и ту же длину. Число уровней не фиксировано.
Пусть блок главного файла содержит 2e-1 записей, а блок индекса 2d-1
записей. Всего записей m.
Поиск. Ищется путь от корня к листу с требуемой записью. Пусть в
некоторый момент достигнут узел B. Пусть B – лист, тогда проверяем, имеется
ли в этом блоке запись со значением ключа v. Если B не лист, тогда он – блок
индекса. Определяем, какое значение ключа в блоке покрывает v. В индексной
записи с покрывающим значением находим указатель на блок нижнего уровня.
С найденным блоком повторяются все рассмотренные шаги. Число обменов
2+log
d
(m/e).
Модификация. Выполняется как удаление старой записи и включение
новой.
Блок главного
файла
Индексный
блок
…
…
…
…
…
…
…
…
…
…
… …
… …
… …
Индекс 1-го
уровня
Индекс 2-го
уровня
Главный
файл
(v,b)
Рис. 29.3. Сбалансированное дерево.

Включение. Находим нужный блок главного файла. Если в блоке менее
2e-1 записей, то запись включается в блок. Если в блоке уже имеется 2e-1
записей, то создается новый блок B
1
, и данные из B частично переписываются в
B
1
. Пусть P – родитель B (P – индексный блок). Применим процедуру
включения рекурсивно, чтобы включить в блок P индекса запись для блока B
1
.
Процесс включения может затронуть несколько уровней.
Удаление. Находим блок B главного файла с удаляемой записью. Если
после удаления в B осталось e или более записей, операция завершена. Если
после удаления осталось e-1 записей, то возможна пересылка части записей из
соседних блоков в B или слияние двух блоков в один. В последнем случае
происходит удаление блока, которое реализуется рекурсивным применением
процедуры удаления.
Файлы с плотным индексом
Пусть главный файл не сортирован. Для поиска записи по ключу в
несортированном файле используется плотный индекс. Плотный индекс
состоит из пар (v,p) для каждого значения ключа v в главном файле (p –
указатель записи главного файла).
Чтобы найти, модифицировать или удалить некоторую запись главного
файла, нужно найти в плотном индексе запись с таким же значением ключа и
затем прочитать блок главного файла с требуемой записью. Далее выполняется
требуемое действие. При включении запись помещается в конец главного
файла, а указатель на нее - в файл плотного индекса.
Показатели разных способов организации файлов приведены в табл. 4.
Файлы с записями переменной длины
Записи переменной длины содержат в своем составе повторяющиеся
однотипные группы значений. С помощью таких записей можно хранить
отображения «многие ко многим». Например, для хранения связей объектов
набора E
1
с объектами набора E
2
(рис. 29.4) можно использовать файл записей
переменной длины, в котором каждая запись состоит из группы полей,