Файл: Обнаружение поддельных новостей с помощью машинного обучения.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 22
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Обнаружение поддельных новостей с помощью машинного обучения
-
https://www.geeksforgeeks.org/fake-news-detection-using-machine-learning/?ref=rp -
-
Последнее обновление : 26 октября 2022 г.
Читать
Обсудить
Курсы
Практика
Видео
Поддельные новости на разных платформах широко распространяются и вызывают серьезную озабоченность, поскольку вызывают социальные войны и постоянный разрыв связей, установленных между людьми. Уже проводится много исследований, посвященных классификации поддельных новостей.
Здесь мы попытаемся решить эту проблему с помощью машинного обучения на Python.
Перед запуском кода загрузите набор данных, нажав на ссылку.
Шаги, которые необходимо выполнить
-
Импорт библиотек и наборов данных -
Предварительная обработка данных -
Предварительная обработка и анализ новостной колонки -
Преобразование текста в векторы -
Обучение, оценка и прогнозирование моделей
Импорт библиотек и наборов данных
Используемые библиотеки :
-
Pandas: Для импорта набора данных. -
Seaborn / Matplotlib: для визуализации данных.
-
Python3
| import pandas as pd import seaborn as sns import matplotlib.pyplot as plt |
Давайте импортируем загруженный набор данных.
-
Python3
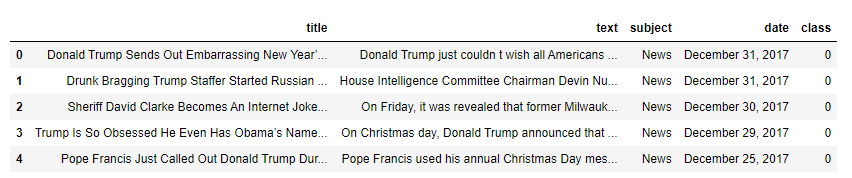
| data = pd.read_csv('News.csv',index_col=0) data.head() |
Вывод :
Предварительная обработка данных
Форму набора данных можно найти по приведенному ниже коду.
-
Python3
| data.shape |
Вывод:
(44919, 5)
Поскольку заголовок, тема и столбец даты не будут полезны для идентификации новостей. Итак, мы можем отбросить эти столбцы.
-
Python3
| data = data.drop(["title", "subject","date"], axis = 1) |
Теперь нам нужно проверить, есть ли какое-либо нулевое значение (мы удалим эти строки)
-
Python3
| data.isnull().sum() |
Вывод:
текст 0
класс 0
Таким образом, нулевого значения нет.
Теперь нам нужно перетасовать набор данных, чтобы предотвратить смещение модели. После этого мы сбросим индекс, а затем удалим его. Потому что столбец индекса нам не полезен.
-
Python3
| # Shuffling data = data.sample(frac=1) data.reset_index(inplace=True) data.drop(["index"], axis=1, inplace=True) |
Теперь давайте рассмотрим уникальные значения в каждой категории, используя приведенный ниже код.
-
Python3
| sns.countplot(data=data, x='class', order=data['class'].value_counts().index) |
Вывод:

Предварительная обработка и анализ новостной колонки
Во-первых, мы удалим из текста все стоп-слова, знаки препинания и любые неуместные пробелы. Для этого требуется библиотека NLTK, и некоторые из ее модулей необходимо загрузить. Итак, для этого выполните приведенный ниже код.
-
Python3
| from tqdm import tqdm import re import nltk nltk.download('punkt') nltk.download('stopwords') from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from nltk.stem.porter import PorterStemmer from wordcloud import WordCloud |
Как только у нас будут все необходимые модули, мы сможем создать текст предварительной обработки имени функции. Эта функция будет предварительно обрабатывать все данные, предоставленные в качестве входных данных.
-
Python3
| def preprocess_text(text_data): preprocessed_text = [] for sentence in tqdm(text_data): sentence = re.sub(r'[^\w\s]', '', sentence) preprocessed_text.append(' '.join(token.lower() for token in str(sentence).split() if token not in stopwords.words('english'))) return preprocessed_text |
Чтобы реализовать эту функцию во всех новостях в текстовом столбце, выполните приведенную ниже команду.
-
Python3
| preprocessed_review = preprocess_text(data['text'].values) data['text'] = preprocessed_review |
Эта команда займет некоторое время (поскольку взятый набор данных очень большой).
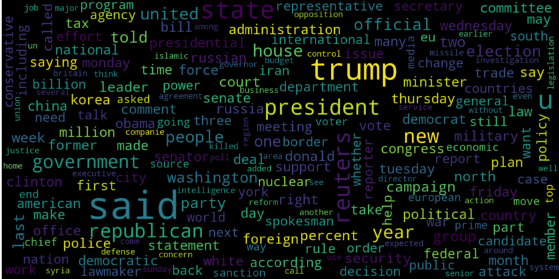
Давайте представим WordCloud для поддельных и реальных новостей отдельно.
-
Python3
| # Real consolidated = ' '.join( word for word in data['text'][data['class'] == 1].astype(str)) wordCloud = WordCloud(width=1600, height=800, random_state=21, max_font_size=110, collocations=False) plt.figure(figsize=(15, 10)) plt.imshow(wordCloud.generate(consolidated), interpolation='bilinear') plt.axis('off') plt.show() |
Вывод :
-
Python3
| # Fake consolidated = ' '.join( word for word in data['text'][data['class'] == 0].astype(str)) wordCloud = WordCloud(width=1600, height=800, random_state=21, max_font_size=110, collocations=False) plt.figure(figsize=(15, 10)) plt.imshow(wordCloud.generate(consolidated), interpolation='bilinear') plt.axis('off') plt.show() |
Вывод :

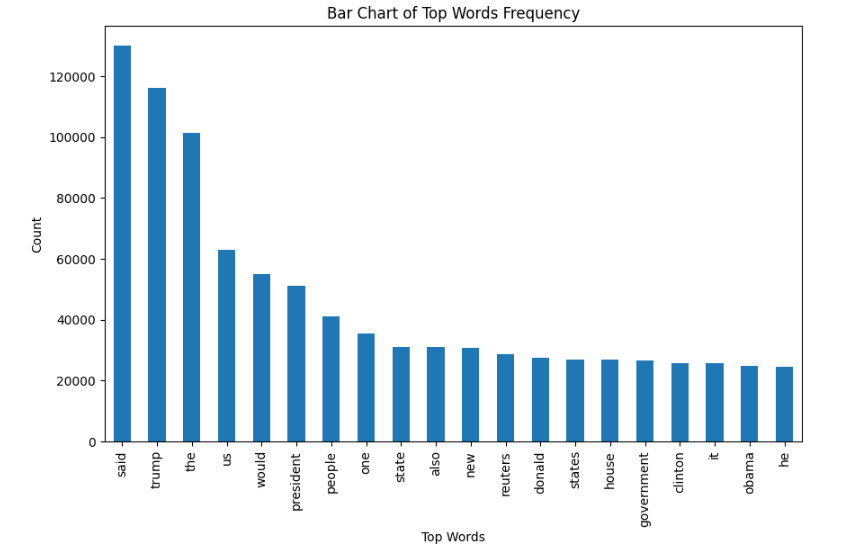
Теперь давайте построим гистограмму 20 самых часто встречающихся слов.
-
Python3
| from sklearn.feature_extraction.text import CountVectorizer def get_top_n_words(corpus, n=None): vec = CountVectorizer().fit(corpus) bag_of_words = vec.transform(corpus) sum_words = bag_of_words.sum(axis=0) words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()] words_freq = sorted(words_freq, key=lambda x: x[1], reverse=True) return words_freq[:n] common_words = get_top_n_words(data['text'], 20) df1 = pd.DataFrame(common_words, columns=['Review', 'count']) df1.groupby('Review').sum()['count'].sort_values(ascending=False).plot( kind='bar', figsize=(10, 6), xlabel="Top Words", ylabel="Count", title="Bar Chart of Top Words Frequency" ) |
Вывод :
Преобразование текста в векторы
Перед преобразованием данных в векторы разделите их на обучающие и тестовые.
-
Python3
| from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression x_train, x_test, y_train, y_test = train_test_split(data['text'], data['class'], test_size=0.25) |
Теперь мы можем преобразовать обучающие данные в векторы с помощью TfidfVectorizer.
-
Python3
| from sklearn.feature_extraction.text import TfidfVectorizer vectorization = TfidfVectorizer() x_train = vectorization.fit_transform(x_train) x_test = vectorization.transform(x_test) |
Обучение, оценка и прогнозирование моделей
Теперь набор данных готов к обучению модели.
Для обучения мы будем использовать логистическую регрессию и оценивать точность прогнозирования с помощью accuracy_score.
-
Python3
| from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(x_train, y_train) # testing the model print(accuracy_score(y_train, model.predict(x_train))) print(accuracy_score(y_test, model.predict(x_test))) |
Вывод :
0.993766511324171
0.9893143365983972
Давайте потренируемся с классификатором дерева решений.
-
Python3
| from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.fit(x_train, y_train) # testing the model print(accuracy_score(y_train, model.predict(x_train))) print(accuracy_score(y_test, model.predict(x_test))) |
Вывод :
0.9999703167205913
0.9951914514692787
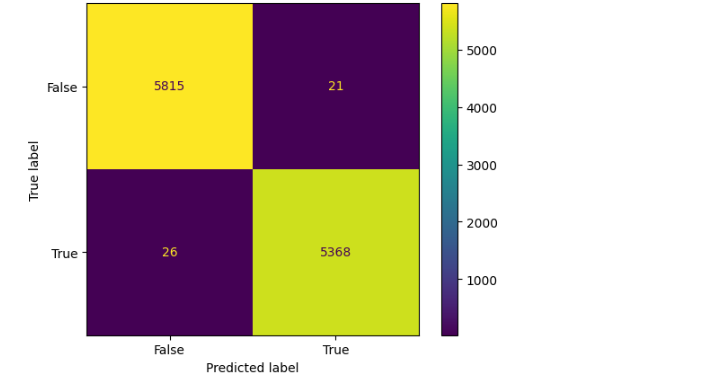
Матрица путаницы для классификатора дерева решений может быть реализована с помощью приведенного ниже кода.
-
Python3
| # Confusion matrix of Results from Decision Tree classification from sklearn import metrics cm = metrics.confusion_matrix(y_test, model.predict(x_test)) cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[False, True]) cm_display.plot() plt.show() |
Вывод :
Заключение
Классификатор дерева решений и логистическая регрессия работают хорошо.