Файл: Технология построения распределенных информационных систем (Преимущества и недостатки использования распределённых информационных систем).pdf
Добавлен: 19.06.2023
Просмотров: 127
Скачиваний: 3
СОДЕРЖАНИЕ
1 Распределенные информационные системы и технологии
1.1 История создания и использования распределенных информационных систем
1.2 Преимущества и недостатки использования распределённых информационных систем
2. Классификация существующих подходов к построению распределённой информационной системы
2.2.1. Двухзвенная архитектура.
2.2.2. Трёхзвенная архитектура
2.3 По нахождению необходимой функциональности
2.3.1. Статическая функциональность
2.3.2. Динамическая функциональность (рассылка функциональности)
ВВЕДЕНИЕ
Одним из основных результатов созидательной, социальной и интеллектуальной человеческой деятельности является создание и накопление информационных ресурсов с целью их дальнейшего использования и сохранения опыта предыдущих поколений. Не будет преувеличением сказать, что уровень развития технологий сохранения информации и эффективности использования накопленной ранее информации на протяжении всей истории человечества значительно влиял на развитие производительных сил. Утеря информации приводила к отбрасыванию цивилизации на века назад. Однако, чтобы эффективно пользоваться накопленной ранее информацией, необходимы специальные инструменты и технологии, при помощи которых могут быть реализованы специальные приемы работы с информацией. Стремительное развитие глобальных информационных и вычислительных сетей ведет к изменению фундаментальных парадигм обработки данных, которые можно охарактеризовать как переход к поддержке и развитию распределенных информационных ресурсов. Поэтому важнейшей задачей, связанной с технологией работы с информацией, является исследование способов интеграции распределенных источников данных и создание научного задела в области распределенных информационных систем и баз данных в целях разработки технологии, поддерживающей создание и функционирование широкомасштабных информационных инфраструктур на основе виртуальной интеграции. Такая технология позволит создавать глобальные инфраструктуры из десятков и сотен гетерогенных баз данных и решать стратегические задачи в области автоматизации различных форм распределенной деятельности. Более узкой целью является разработка принципов и программных средств виртуальной интеграции распределенных источников данных на основе международных стандартов и рекомендаций для создания масштабных информационных инфраструктур, предназначенных для виртуализации доступа к данным различных СУБД с использованием единых правил и политик. На самом деле идея создания универсальной системы доступа к информационным ресурсам, распределенным в мировом пространстве, далеко ненова. По всей видимости, впервые ее четко осознал известный бельгийский ученый Поль Отле1 в конце XIX в., предложив совершенно новый метод, названным им “Документацией”: “Цели Документации состоят в том, чтобы суметь предложить документированные ответы на запросы по любому предмету в любой области знания: 1) универсальные по содержанию; 2) точные и истинные; 3) полные; 4) оперативные; 5) отражающие последние данные; 6) доступные; 7) заранее собранные и готовые к передаче; 8) предоставленные как можно большему числу людей”. “... человеческое знание позволит создать оборудование, действующее на расстоянии, в котором соединятся радио, рентгеновские лучи, кинематограф и микроскопическая фотография. Все предметы Вселенной, все предметы, созданные Человеком, будут регистрироваться на расстоянии с момента их создания. Тем самым будет создан движущийся образ мира — его память, его подлинная копия. Любой человек сможет прочесть отрывок, спроецированный на его личный экран”. Под интеграцией информационных ресурсов понимают их объединение с целью использования (с помощью удобных и унифицированных пользовательских интерфейсов) разнородной информации с сохранением ее свойств, особенностей представления и возможностей манипулирования с ней. При этом объединение ресурсов не обязательно должно осуществляться физически, оно может быть виртуальным, главное — оно должно обеспечивать пользователю восприятие доступной информации как единого информационного пространства. В частности, такие системы позволяют работать с гетерогенными наборами и базами данных или системами баз данных, обеспечивая эффективность информационных поисков независимо от особенностей конкретных систем хранения ресурсов, к которым осуществляется доступ.
1 Распределенные информационные системы и технологии
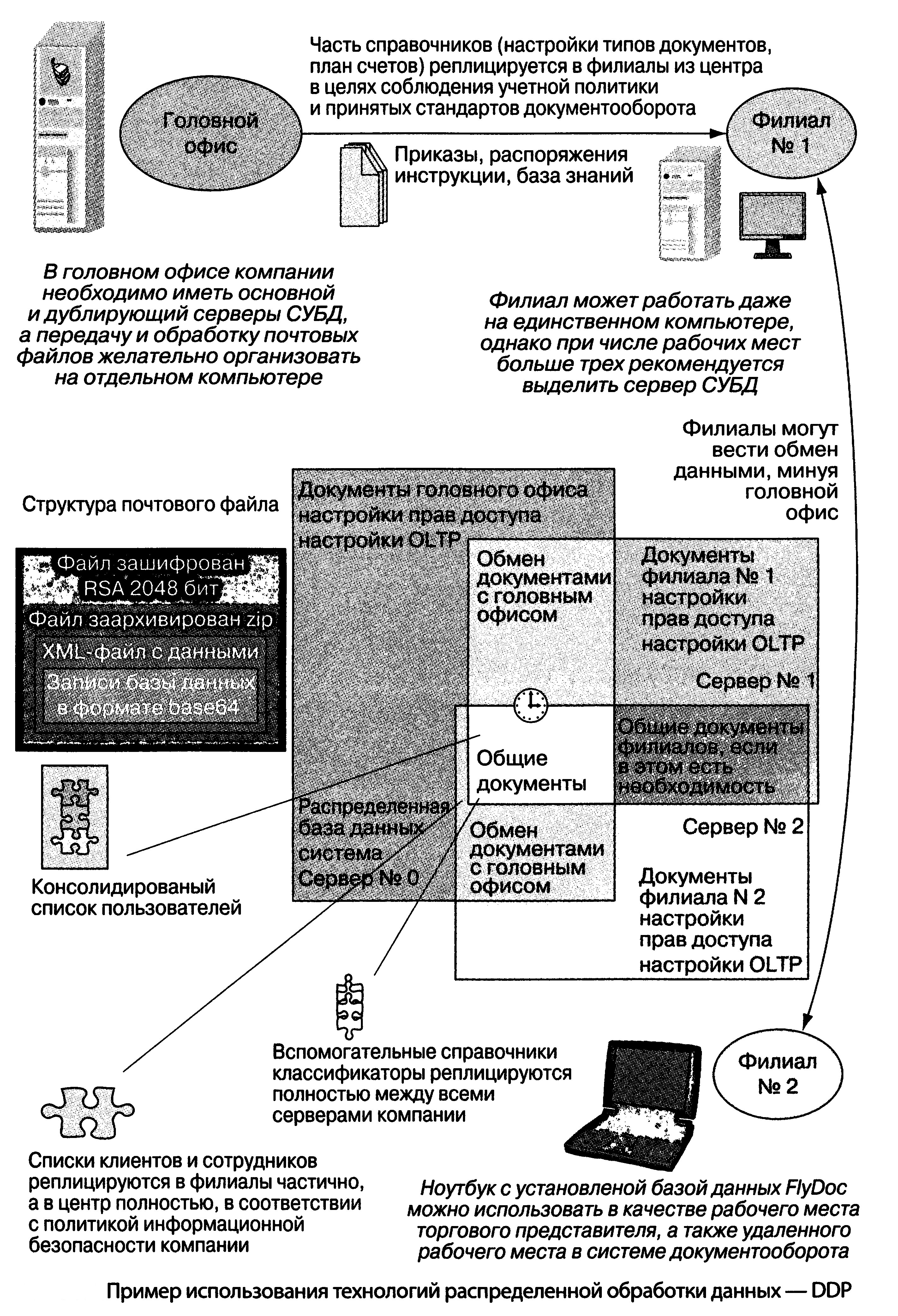
Вопрос об использовании распределенных систем обработки данных стал актуален с появлением мощных вычислительных систем с распределенными ресурсами в пределах одного компьютера, локальных корпоративных и внешних (региональных и глобальных) сетей, технологий поиска и многомерного анализа данных, развитием Web-технологий. Использование технологий распределенной обработки данных (Distributed Data Processing — DDP) стало особенно актуально для высокотехнологичных географически распределенных компаний, деятельность которых поддерживается и сопровождается современными ИТ и системами (рис. 1).
 |
|
Рисунок 1 |
Суть распределенной обработки данных заключается в том, что пользователь получает возможность работать с базами и хранилищами данных, прикладными процессами программами и сервисами, расположенными в нескольких взаимосвязанных оконечных системах. При этом возможны следующие виды работ:
• удаленный запрос, например, посылка команды пользователя
на выполнение задания, связанного с обработкой данных;
• удаленное действие (Transaction), осуществляющее направление группы запросов прикладному процессу; это может быть, например, часть вычислительного процесса, использующего удаленную базу данных;
• распределенная трансакция, дающая возможность использования нескольких серверов и прикладных процессов, выполняемых в группе оконечных систем;
• обработка в системе «клиент-сервер».
Существует несколько технологий распределенной обработки, которые могут использовать как промежуточный слой программного обеспечения, ориентированного на запросы и сообщения, так и распределенную интегрированную среду обработки данных. Первая технология является самой простой, но возможности ее ограничены взаимодействием с одним из выбранных серверов приложений. Технологии второго типа предусматривают совместную работу клиентов с одним или с группой серверов. При этом некоторые серверы могут выступать в роли клиентов для других серверов. Для распределенной обработки осуществляется тематическая сегментация прикладных программ. Для работы в реальном времени используется протокол резервирования ресурсов и предоставляется специализированное инструментальное программное обеспечение распределенной среды обработки данных. Способы конкретной организации процессов обработки и технические решения чрезвычайно разнообразны, однако архитектура таких систем является, как правило, двух- или трехзвенной архитектурой «клиент-сервер» (Client-Server Architecture — CSA).
1.1 История создания и использования распределенных информационных систем
До конца 90-х годов прошлого века основным вектором развития распределенных вычислительных систем (РВС) являлась парадигма создания сосредоточенных систем. Типичным примером данного подхода явилось создание вычислительных кластеров научных организаций. Под термином вычислительный кластер обычно понимают систему, состоящую из вычислительных узлов, объединенных коммутационной сетью. Среди реализованных проектов можно выделить кластеры таких научных организаций, как ИРЭ РАН и ВЦ РАН. Данные системы были созданы для решения трудоемких задач, во многих областях науки, таких, например, как меторологические исследования, исследования задач динамики и ряда др. Использование РВС для решения подобных задач является необходимым условием для качествен-ного решения, так как многие задачи не могут быть решены на одном вычислительном узле за полиноминальное время. Особого внимания заслуживает разработки отечественных ученых по построению распре-деленных вычислительных систем с программи-руемой структурой. Исследования в данном на-правлении активно поддерживаются Сибирским отделением РАН. Под вычислительной системой с программируемой структурой стоит пони-мать совокупность элементарных машин (ЭМ), действие которой основано на модели коллек-тива вычислителей [4]. Основной задачей дан-ных систем является распределенная обработка информации. Первыми опытными разработками по созданию ВС с программируемой архитектурой начались в 60-х годах прошлого века. Сре-ди реализованных проектов ВС можно выделить такие системы как МИНИМАКС, СУММА, МИКРОС-1, МИКРОС-2, МИКРОС-T. Идеология объединения географически распределенных кластеров развилась в начале 90-х годов прошлого века. Основная сложность для развития данного подхода была заключена в объединениии гетерогенных компонентов вы-числительных узлов. Частично, данная пробле-ма была решена благодаря новому подходу к построению ПО, за счет его разделение на два слоя: • слой распределенного приложения• связующий слой программного обеспечения (англ. middleware) Первыми экспериментами по объединению территориально-разрозненных вычислительных компьютерных центров стали американский проект CASA и отечественный Астра. Именно в то время и возник термин метакомпьютинг. Первыми экспериментальными системами по объединению территориально-распределенных стали такие проекты, как FAFNER и I-WAY [17]. Хотя, конечно же, проекты FAFNER и I-WAY были созданы для различных целей (FAFNER предполагал объединение в единую сеть простых рабочих станций, а проект I-WAY предполагал объединение ресурсов суперкомпью-терных центров), но все же они имели немало общих черт. Основной задачей для данных проектов являлось создание распределенных систем с эффективным обменом данными, управлением ресурсами и обработкой данных. Проект FAFNER (англ. Factoring via Network enabled recursion) был создан для умножения простых чисел криптографических задач, путем разделения задачи на небольшие фрагменты и их дальнейшего распределения на узлы системы. Целью создания проект I-WAY являлось объединение ресурсов вычислительных центров в единое целое. Отличительной особенностью данного проекта являлось использование для управлением потоками задач брокера ресурсов. Идеи, заложенные в проекты FAFNER и I-WAY, оказали сильное влияние на развитие таких проектов, как ГЛОБУС (Globus) [18] и Legion [19]. Первым отечественным опытом по созданию территориально-распределенной вычисли-тельной системой стал проект Астра, инициро-ванный ИМ СО АН СССР и Новосибирским электротехническим институтом MB и ССО РСФСР. Проект предполагал построение территориально-распределенных систем на базе ЭВМ «Минск-32» и телефонных каналов связи. Пер-вая рабочая конфигурация системы была введена в эксплуатацию в 1972 г. Система предполагала неограниченные возможности по наращиванию вычислительных мощностей, но каждая ЭВМ, входящая в состав системы, могла соединяться только лишь с двумя соседними ЭВМ. На рис. 2 представлена схема распределенной системы Астра [4]. В дальнейшем, работа по модернизации системы продолжилась. Весь опыт по по-строению системы Астра, в дальнейшем лег в основу системы АРАККС (Асинхронная Распре-деленная вычислительная система с Комбиниро-ванными Каналами Связи).
 |
|
Рисунок 2 |
Существенный прорыв в области построения пространственно-распределенных систем обра-зовался благодаря развитию концепции GRID (Global Resource Information Distribution). Кон-цепция Grid Computing (распределенные сети, или "решетки" вычислительных ресурсов) на сегодняшний день представляет собой ведущую технологию создания распределенных вычисли-тельных систем (РВС). В 1998 году Фостер и Кельман опублико-вали статью [20], в которой предложили кон-цептуально новый подход к организации гло-бально-распределенных систем. Как следует из статьи, грид-системы являются «программно-аппаратными структурами, обеспечивающими надежный и недорогой доступ к высокопроиз-водительным вычислительным возможностям». По своей сути, идеология компьютерных грид-системы является моделированием электрических сетей. Грид – архитектура позволяет соединять между собой географически рас средоточенные вычислительные узлы посред-ством сети Интернет в некоторую абстрактную решетку (англ. GRID – решетка), в которой каждый узел предоставляет ресурсы для со-вместного использования в конкретной задаче. Данная вычислительная модель системы позво-ляет объединять не только сосредоточенные кластеры, но и ПК обычных пользователей сети Интернет в некий единый виртуальный суперкомпьютер. Возможность использования данного подхода к организации территориально-распределенных систем стало возможным, благодаря развитию общей индустрии инфор-мационных технологий, а именно:• развитию высокоскоростных сетей переда-чи данных;• увеличению производительности ПК;•созданию стандартизированных протоколов передачи данных. На рис.3 представлена одна из возможных структур Grid Computing.
 |
|
Рисунок 3 |
Среди значимых систем второго поколения можно выделить такие проекты как Globus, gLite, Legion, Unicore. Проект Globus с раз-работанным инструментарием Globus Toolkit, позволяет объединить множество территори-ально распределенных гетерогенных ресурсов в единую виртуальную систему. Инструментарий Globus Toolkit имеет открытый исходный код. Стоит понимать, что данный инструментарий не является готовым техническим решением для организации распределенных вычислений, а представляет собой лишь набор стандартов и инструментов. Широкое применение инструментария обуславливается, прежде всего, отсутствием жесткой модели программирования, в результате чего разработчик может использовать широкий набор инструментов в соответствии с потребностью. Проект Globus был поддержан многими производителями программного обеспечения, такими как IBM, Sun, HP, Intel. Проект Legion был разработан в университете Вирджиния и предоставляет собой программную среду для организации географически распределенной системы, в состав которой могут входить рабочие станции, векторные супер-компьютеры и параллельные суперкомпьютеры [19]. Основное отличие от подобного рода систем является поддержка объектно-ориентиро-ванного модели, в которой грид представлялся в виде легиона и все компоненты являются компонентами. Однако многих исследователей отталкивала объектно-ориентированная модель, вследствие чего их внимание смещалось в сторону Globus, а проект был закрыт.Концепция гридсистем активно развивается и отечественными учеными. К примеру, исследователями Лаборатории вычислительных си-стем Института физики полупроводников им. А.В. Ржанова СО РАН и Центром параллельных вычислительных технологий Сибирского государственного университета телекоммуни-каций и информатики (СибГУТИ) создана мас-штабируемая GRID-модель – пространственнораспределенная мультикластерная ВС. В состав системы входят вычислительные кластеры данных организаций. Операционная систе-ма системы построена на ядре Linux. Так же в состав системы входит инструментарий раз-работчика для разработки программных продуктов, включаещий такие средства как GCC, ряд библиотек для организации параллельных вычислений(MPI, OpenMP). Дальнейшим развитием в области построения пространственно-распределенных систем явилась разработка третьего поколения GRID. Основная задача построения данных систем на-правлена не на стандартизации интерфейсов, а на решение вопросов самоорганизации и автоматизации процессов, происходящих в GRID [20]. Стоит понимать, что исследования в области стандартизации интерфейсов не остановились, а продолжают развиваться в таких концепциях, как SOA и SOC, что привело к созданию новых коммуникационных протоколов, в частности SOAP (Simple Object Access Protocol). Ярким примером демонстрирующий вектор развития систем является концепция, выдвинутая фирмой IBM в 2001 году, которая полу-чила название «автономные вычисления». Для реализации концепции автономных вычислений необходимо, чтобы система удовлетворяла ряду требований:
• Самовосстановление. Система должна вос-станавливаться в рабочее состояние в случае возникновения сбоя
• Самоконфигурирования. Система должна самостоятельно конфигурировать свое ПО в случае обновления.
• Самозащита. Система должна обеспечивать сохранность данных при возможных попытках вторжения в систему. Развитием создания грид-систем с идеоло-гией «автономных вычислений» явились такой проект как IBM OptimalGrid. В дальнейшем идеология автономных грид-систем была подхвачена многими проектами в области распре-деленной обработки данных и существующие системы в той или иной степени поддерживают идеологию автономных вычислений.
1.2 Преимущества и недостатки использования распределённых информационных систем
В настоящее время практически все большие программные системы являются распределенными. Распределенная система - система, в которой обработка информации сосредоточена не на одной вычислительной машине, а распределена между несколькими компьютерами. При проектировании распределенных систем, которое имеет много общего с проектированием ПО в общем, все же следует учитывать некоторые специфические особенности.
Существует шесть основных достоинств распределенных систем:
•Совместное использование ресурсов. Распределенные системы допускают совместное использование как аппаратных (жестких дисков, принтеров), так и программных (файлов, компиляторов) ресурсов.
•Открытость. Это возможность расширения системы путем добавления новых ресурсов.
•Параллельность. В распределенных системах несколько процессов могут одновременно выполнятся на разных компьютерах в сети. Эти процессы могут взаимодействовать во время их выполнения.
•Масштабируемость. Под масштабируемостью понимается возможность добавления новых свойств и методов.
•Отказоустойчивость. Наличие нескольких компьютеров позволяет дублирование информации и устойчивость к некоторым аппаратным и программным ошибкам. Распределенные системы в случае ошибки могут поддерживать частичную функциональность. Полный сбой в работе системы происходит только при сетевых ошибках.
•Прозрачность. Пользователям предоставляется полный доступ к ресурсам в системе, в то же время от них скрыта информация о распределении ресурсов по системе.