Файл: Методические указания по выполнению лабораторных работ по дисциплине (модулю) Лингвистическое и программное обеспечение автоматизированных систем.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 588
Скачиваний: 3
СОДЕРЖАНИЕ
2.Общие положения (теоретические сведения)
2.1. Принцип рекурсии в правилах грамматики
2.2. Запись правил грамматик с использованием метасимволов
2.3. Запись правил грамматик в графическом виде
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2.Общие положения (теоретические сведения)
2.1. Разработка лексического анализатора
2.2. Разработка синтаксического анализатора
2.3. Пример построения простого синтаксического анализатора
2.4. Анализаторы для сложных рекурсивных грамматик
2. Общие положения (теоретические сведения)
2.5. Логическая структура XML-документа
2.8. Описание структуры XML-документов
2.9. Язык XML Sсhema Definition (XSD)
2.10. Программная обработка XML-документов
2.11. Обработка XML-данных с использованием модели DOM
2.14. Сопоставление объектной иерархии с XML-данными
2.16. Считывание XML-документа в DOM
2.17. Директивы таблицы стилей, встроенные в документ
2.18. Загрузка данных из модуля чтения
2.19. Доступ к атрибутам в модели DOM
2.20. Получение всех атрибутов в виде коллекции
2.21. Получение единичного узла атрибута
2.22. Считывание объявлений сущностей и ссылок на сущности в DOM
2.23. Сохраняемые ссылки на сущности
2.24. Разворачиваемые и не сохраняемые ссылки на сущности
2.25. Создание новых узлов в модели DOM
2.26. Создание новых атрибутов для элементов в модели DOM
2.29. Проверка имен XML-элементов и атрибутов при создании новых узлов
2.30. Создание новых ссылок на сущности
2.32. Копирование существующих узлов
2.33. Копирование существующих узлов из одного документа в другой
2.34. Копирование фрагментов документа
2.35. Удаление узлов, содержимого и значений из XML-документа
2.36. Изменение узлов, содержимого и значений в XML-документе
2.37. Проверка XML-документа в DOM
2.38. Проверка XML-документа в DOM
2.39. Обработка ошибок проверки и предупреждений
2.40. Сохранение и запись документа
2.42. Запись содержимого документа с помощью свойства OuterXml
3.Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3.5. Эскизы в документах Деталей
3.6. Взаимодействие с пользователем
3 Задание на работу (рабочее задание)
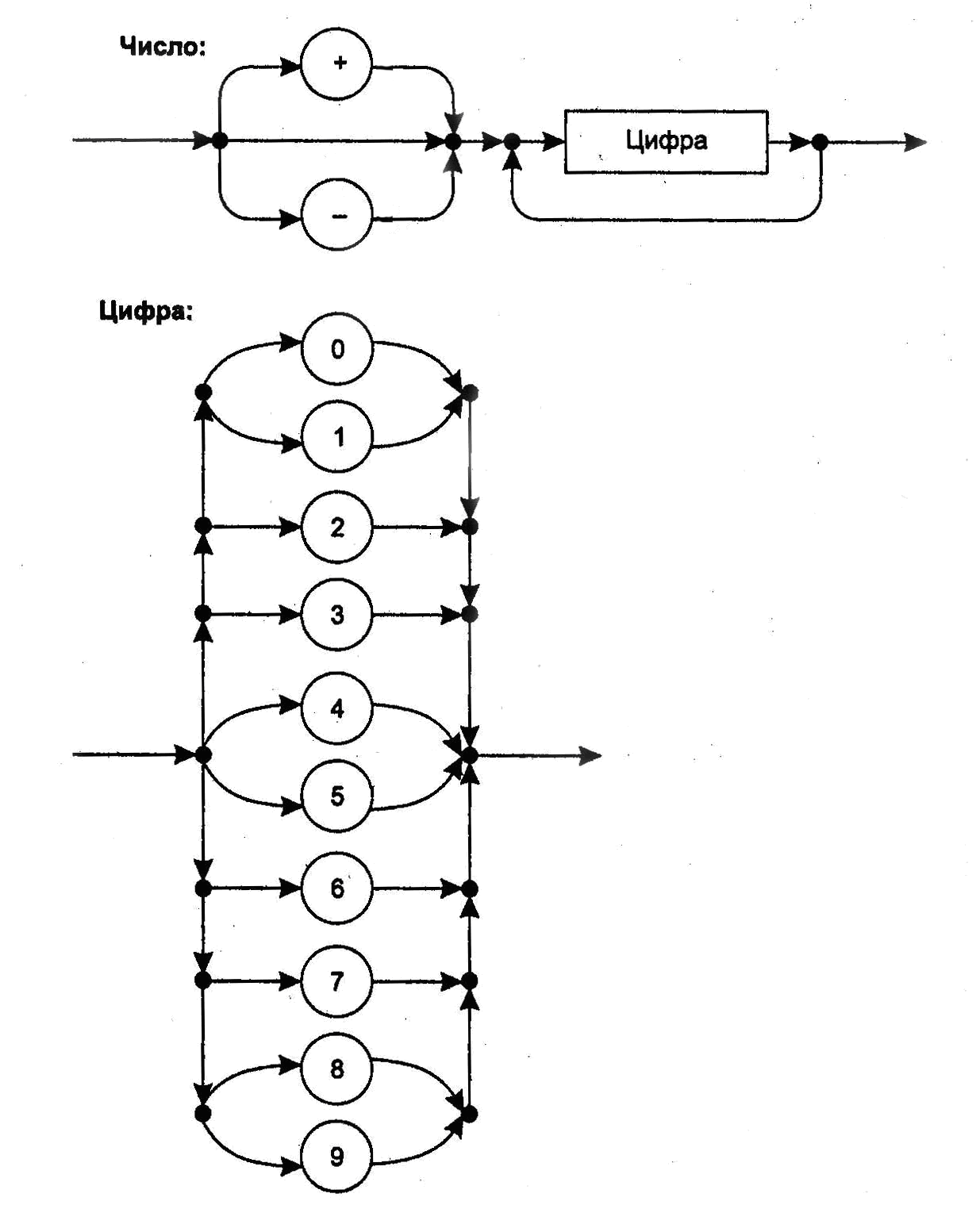
Рис. 2.2 - Графическое представление грамматики
целых десятичных чисел со знаком
3. Задание на лабораторную работу
-
Описать язык арифметических выражений с одноместными операциями языка программирования Си (++, --, =, +=, -=, *=, /=, %=), с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений в префиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления со скобками, с операндами в форме идентификаторов и элементов массива. -
Описать язык выражений с побитовыми операциями логики языка Си, без скобок, с операндами в форме идентификаторов и целыми константами ( в двоичной, восьмеричной, десятичной и шестнадцатеричной формах). -
Описать язык функциональных выражений с произвольным количеством аргументов и неограниченной вложенностью. Аргументы – идентификаторы: f(g(x,e(y,z))). -
Описать язык арифметических выражений в постфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и целых констант. -
Описать язык выражений с операциями логики языка Си, без скобок, с операндами в форме идентификаторов, операциями отношений. Операции отношений включают в себя двухоперандные арифметические выражения с идентификаторами и целыми константами. -
Описать язык выражений в синтаксисе Си, включающий присваивание, префиксный и постфиксный инкремент и декремент, сложение, вычитание, умножение, деление, с операндами в форме идентификаторов и констант. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и целых констант. -
Описать язык арифметических выражений с операциями языка Си ( +, -, *, /, + +, - -, %), без скобок, с операндами в форме идентификаторов и констант (целых, с фиксированной и плавающей запятой). -
Описать язык функциональных выражений. Каждая функция имеет один аргумент. Аргументами являются идентификаторы, элементы массива и константы. -
Описать язык адресных выражений языка Си с операциями ссылок ( *, &, ®), со скобками, с операндами в форме идентификаторов. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и целых констант и функциональных выражений с несколькими аргументами. Аргумент функционального выражения – вышеописанное выражение. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и целых констант и функциональных выражений с несколькими аргументами. Аргумент функционального выражения – идентификатор. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления со скобками, с операндами в форме идентификаторов и целых констант. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений в постфиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и элементов массива. -
Описать язык выражений с побитовыми операциями логики языка Си, со скобками, с операндами в форме идентификаторов и целыми константами ( в двоичной форме). -
Описать язык адресных выражений языка Си с операциями ссылок ( &, *), без скобок, с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений в инфиксной форме с операциями сложения, вычитания, умножения, деления со скобками, с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений с операциями языка Си ( +, -, *, /, + +, - -, %), со скобками, с операндами в форме идентификаторов и констант (целых). -
Описать язык выражений в синтаксисе Си, включающий присваивание, префиксный и постфиксный инкремент и декремент, сложение, вычитание, умножение, деление, с операндами в форме идентификаторов и функциональных вызовов. Допустимы вызовы функций с произвольным количеством аргументов в форме идентификаторов. -
Описать язык выражений в синтаксисе Си, включающий присваивание, префиксный и постфиксный инкремент и декремент, сложение, вычитание, умножение, деление, с операндами в форме идентификаторов и функциональных вызовов. Допустимы вызовы функций с произвольным количеством аргументов в форме идентификаторов. -
Описать язык выражений с операциями логики языка Си, со скобками, с операндами в форме идентификаторов, логическими константами, операциями отношений. -
Описать язык логических выражений с операциями .NOT. , .OR. , .AND. , без скобок, с операндами в форме идентификаторов, константами .TRUE. , .FALSE. и операциями отношений в синтаксисе ФОРТРАНа (.GE. , .LE. , .NE. , .EQ. , .GT. , .LT.). -
Описать язык арифметических выражений в префиксной форме с операциями сложения, вычитания, умножения, деления без скобок, с операндами в форме идентификаторов и целых констант. -
Описать язык арифметических выражений с одноместными операциями языка программирования Си (++, --, =, +=, -=, *=, /=, %=), с операндами в форме идентификаторов и элементов массива. -
Описать язык арифметических выражений с одноместными операциями языка программирования Си (++, --, =, +=, -=, *=, /=, %=), с операндами в форме идентификаторов и элементов массива. -
Описать язык выражений в синтаксисе Си, включающий присваивание, префиксный и постфиксный инкремент и декремент, сложение, вычитание, умножение, деление, с операндами в форме идентификаторов и функциональных вызовов. Допустимы вызовы функций с произвольным количеством аргументов в форме идентификаторов. -
Описать язык арифметических выражений с операциями языка Си ( +, -, *, /, + +, - -, %), со скобками, с операндами в форме идентификаторов и констант (целых).
4. Ход работы (порядок выполнения работы)
1) Ознакомится теоретической справкой.
2) Описать грамматики тремя различными способами.
3) Оформить отчет.
4) Защитить работу преподавателю.
5. Содержание отчета
1) Титульный лист
2) Задание
3) Примеры допустимых и недопустимых выражений в описываемой грамматике.
4) Описание грамматики в форме Бэкуса-Наура.
5) Описание грамматики в расширенной форме Бэкуса-Наура.
6) Описание грамматики в графической форме.
7) Выводы по работе
8) Список используемой литературы
Лабораторная работа № 2
Разработка лексического и синтаксического анализаторов
1.Цель и задачи работы
Целью работы являются выработать у студентов навык построения лексических и синтаксических анализаторов.
Задачами работы являются
-
Изучение методов разработки лексических и синтаксических анализаторов. -
Разработка лексического анализатора грамматики в соответствии с индивидуальным заданием. -
Разработка синтаксического анализатора грамматики в соответствии с индивидуальным заданием.
2.Общие положения (теоретические сведения)
2.1. Разработка лексического анализатора
При лексическом анализе текст выражения на языке L разделяется на отдельные лексемы. Лексема – это один терминальный или нетерминальный символ. В рассматриваемой грамматике лексический анализатор (ЛА) должен выделять лексемы следующих типов: идентификатор; число; "+"; "-", т.е. лексемы, непосредственно входящие в описание грамматики языка L. Результатом работы является динамический массив лексем.
Константа FINISH соответствует концу анализируемого выражения и указывает на то, что за ней других лексем нет.
Такая грамматика имеет вид:
<цифра> ( 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 )
<число> <цифра>{<цифра>}
<идентификатор>
<слагаемое> (<идентификатор>|<число>)
<операция> ( + | - )
Опишем тип Tresult элемента выходного динамического массива:
public struct Tresult
{
public string lexeme;
public long value;
public string name;
public ushort position; // целое число от 0 до 65535
}
Здесь в поле value хранится численное значение лексемы типа NUMBER, в поле name – имя лексемы-идентификатора типа ID, в поле position – позиция лексемы во входной строке (для индикации).
Создадим теперь класс "Лексический анализатор":
public partial class TLexicalAnalyzer
{
public static string[] TLexemeType = { "NUMBER", "ID", "PLUS", "MINUS", "FINISH" };
private string Ferr;
private Tresult[] Flex;
public TLexicalAnalyzer() //Конструктор
{ Ferr = ""; Flex = new Tresult[0]; }
public String Error { get { return Ferr; } }
public Tresult[] Lexem { get { return Flex; } }
string s = "";
ushort i;
Здесь введено свойство Error (только для чтения) для хранения в нём сообщений об ошибках, которые могут быть обнаружены в процессе анализа. В свойстве Lexem хранится собственно формируемый список лексем. Основным методом данного класса является функция Run, которая получает на вход выражение на языке L, а возвращает массив лексем.
А теперь самое интересное.… Для упрощения кода основная процедура Run разбита на несколько отдельных процедур - AddLex, добавляющая лексему в результирующий массив. Процедуры ReadID и ReadNumber считывают идентификаторы и числа соответственно. Для преобразования текса в число в процедуре ReadNumber применена стандартная функция Convert.ToString().
public void AddLex(byte LexemeType, long v, string n)
{
Array.Resize(ref Flex, Flex.Length + 1);
Flex[Flex.Length - 1].lexeme = TLexemeType[LexemeType - 1];
Flex[Flex.Length - 1].value = v;
Flex[Flex.Length - 1].name = n;
Flex[Flex.Length - 1].position = i;
}
public void ReadID()
{
string N = "";
do
{
N += s[i];
i++;
}
while ((i < s.Length) && (char.IsLetterOrDigit(s, i) || (s[i] == '_')));
AddLex(2, 0, N);
i--;
}
public void ReadNumber()
{
string N = "";
do
{
N += s[i];
i++;
}
while ((i < s.Length) && (char.IsDigit(s, i)));
AddLex(1, Convert.ToInt64(N), N);
i--;
}
public void Run(string Data)
{
s = Data;
Array.Resize(ref Flex, 0);
Ferr = "";
for (i = 0; i <= s.Length – 1; i++)
{
if (s[i] == '+') AddLex(3, 0, "+");
else
if (s[i] == '-') AddLex(4, 0, "-");
else
if ((char.IsLetter(s, i)) || (s[i] == '_')) ReadID();
else
if (char.IsDigit(s, i)) ReadNumber();
else
{
Ferr = "Недопустимый символ в коде!";
break;
}
}
AddLex(5, 0, "");
}
2.2. Разработка синтаксического анализатора
После получения списка лексем необходимо ответить на вопрос: в правильном ли порядке они идут? Из грамматики языка очевидно, что, к примеру, последовательность лексем ID – PLUS – NUMBER является верной, а последовательность ID – ID – MINUS – неверной. Программа-распознаватель должна ответить на вопрос, допустима ли предлагаемая последовательность лексем в рамках грамматики того или иного языка.
Существуют различные методы построения анализаторов. Один из основных – метод нисходящего разбора, при котором диаграмма Вирта фактически является блок-схемой процедур распознавания. Основная программа будет состоять из оператора чтения первой лексемы, за которым следует оператор активации основной цели грамматического разбора. Отдельные процедуры, соответствующие целям грамматического разбора или графам, получаются по следующим правилам.
Правила преобразования графа в программу:
1. Свести систему графов к как можно меньшему числу отдельных графов с помощью соответствующих подстановок.
2. Преобразовать каждый граф в описание процедуры в соответствии с приведенными ниже правилами З-7.
3. Последовательность элементов

S1
S2
Sn
… переводится в составной оператор
T(S1); T(S2); ...; T(Sn)
4. Выбор элементов
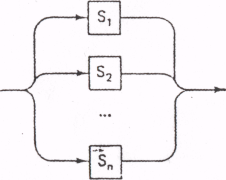 переводится в выбирающий или условный оператор:
переводится в выбирающий или условный оператор:switch (ch)
{
case L1: T(S1);
break;
case L2:
T(S2);
break;
…………
case Ln: T(Sn);
break;
default:
error;
}
if (ch == L1) T(S1);
else
if (ch == L2) T(S2);
else ……………
if (ch == Ln) T(Sn);
else
error;
где Li означает множество начальных символов нетерминального символа Si. Если Li состоит из одного символа a, то, разумеется, вместо ch in Li нужно писать ch == а.