Файл: Лабораторная работа 8 Исследование методов классификации данных с помощью нейронной сети Фамилия Григорьев Имя.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 246
Скачиваний: 13
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ,
СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ
УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ. М.А. БОНЧ-БРУЕВИЧА»
(СПбГУТ)
ИНСТИТУТ НЕПРЕРЫВНОГО ОБРАЗОВАНИЯ
Дисциплина: Теория информации, знания, данные
ЛАБОРАТОРНАЯ РАБОТА 8
«Исследование методов классификации данных с помощью нейронной сети»
Фамилия: Григорьев
Имя: Максим
Отчество: Дмитриевич
Группа №: ИБ-16с
№ Зач: 2110871
Проверил:______________
Санкт-Петербург
2023
Описание методики исследования
Цель работы – исследование принципов разработки нейронной сети на примере задачи классификации данных в PyTorch.
Для исследование принципов разработки нейронной сети используем датасет классификации вин - sklearn.datasets.load_wine() (этот датасет будет содержать 178 различных бутылок вин, у каждой бутылки измерено 13 параметров, это вещественные числа) Для того чтобы эксперименты были воспроизводимы (чтобы, взяв один и тот же питоновский файл и выполнив его, мы получили бы тот же самый результат, как и раньше) зафиксируем все случайный генераторы (random в python, numpy.random). Для этого возьмём random seed и поставим его в конкретное значение. Таким образом, мы всегда будем использовать нулевую последовательность при вызове случайного генератора библиотеки random.
Также нам нужно зафиксировать сиды в numpy и в PyTorch, случайные сиды, которые отвечают за обсчет и CPU и на GPU – они разные, соответственно нужно ещё зафиксировать случайный seed подмодуля CUDA.
Выставив все эти параметры, мы можем практически гарантировать то, что у нас эксперименты будут воспроизводимы.
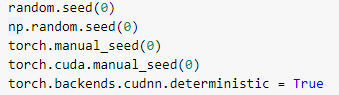
Рис. 1
Разбиваем датасет на две части:
● трейновая (на которой будет проходить обучение)
● тестовая (на которой будут считаться метрики)
Отведем 30 процентов на тест, и перед тем, как этот датасет делить на две части, нужно его перемешать, чтобы удостовериться, что если он был отсортирован, например, по номеру класса, то теперь эта сортировка не работает.
После этого мы все "фолды": X_train, X_test, Y_train и Y_test обернём в torch тензоры: дробные числа, мы обернем в float тензор, если числа не дробные, обернем в long тензор.

Рис.2
Реализуем класс, назовем его WineNet, это будет нейросеть для классификации.
Отнаследуем класс от torch.nn.Module, в функции __init__ (в конструкторе этого класса) будет аргумент – количество скрытых нейронов n_hidden_neurons.
Реализуем здесь два скрытых слоя, нейросеть будет состоять всего из трёх слоёв, и два из них будут скрыты. Первый слой – это fully connected (полносвязный) слой, из двух входов (у нас две колонки для каждой бутылки вина), на выходе N скрытых нейронов, дальше активация: сигмоида, можно поставить любую другую, если хотите. После этого – скрытый слой, который из N нейронов, превращает их тоже в N нейронов. Снова сигмоидная активация. После этого снова fully connected слой, который выдаёт нам три нейрона, каждый нейрон будет отвечать за свой класс.
Таким образом, на выходе этих трёх нейронов будут некоторые числа, которые после этого мы передадим в софтмакс, и получим вероятности классов. Напишем функцию "forward" – она будет реализовывать граф нашей нейронной сети. Передаем трехмерный тензор с двумя колонками в первый fully connected слой, после этого в первую активацию, во второй fully connected слой, во вторую активацию, в третий fully connected слой, у которого три выхода.
Инициализируем нашу нейронную сеть с количеством скрытых нейронов, равным пяти. Нейросеть имеет имя wine_net.
Инициируем функцию потерь – бинарную кросс-энтропию (torch.nn.CrossEntropyLoss), которая использует невыходы после софтмакса, а выходы нейронной сети, не пропущенные ещё через софтмакс.
Далее задается оптимайзер – метод, который будет использоваться для вычисления градиентных шагов. В оптимайзер мы передаем все параметры нейронной сети – ее веса. Это те скрытые значения, которые находятся в нейронах, которые мы хотим подбирать. Learning rate выбираем 0.001 (как правило, стандартное значение по умолчанию).
Чтобы попытаться улучшить результаты классификации изменим количество скрытых слоёв на один. Закомментируем слой.
Увидим, что обучение пошло быстрее, потому что у нас меньше вычислений, меньше слоёв, и довольно быстро нейронная сеть выходит на те же значения.
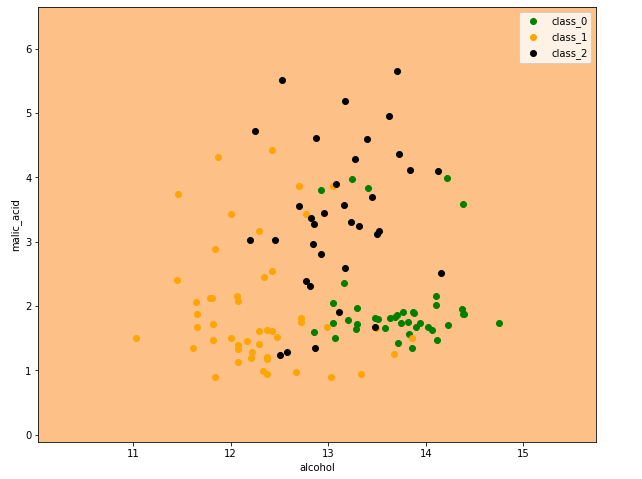
Видим, что картина поменялась. Возможно, эта картина более адекватная. Судя по метрике, она "угадывает на валидации" немножко лучше, отделяет классы друг от друга.
Код программы
import torch
import random
import numpy as np
## Вариант 6
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed(0)
torch.backends.cudnn.deterministic = True
##
import sklearn.datasets
wine = sklearn.datasets.load_wine()
wine.data.shape
##
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
wine.data[:, :2],
wine.target,
test_size=0.3,
shuffle=True)
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
##
class WineNet(torch.nn.Module):
def __init__(self, n_hidden_neurons):
super(WineNet, self).__init__()
self.fc1 = torch.nn.Linear(2, n_hidden_neurons)
self.activ1 = torch.nn.Sigmoid()
self.fc2 = torch.nn.Linear(n_hidden_neurons, n_hidden_neurons)
self.activ2 = torch.nn.Sigmoid()
self.fc3 = torch.nn.Linear(n_hidden_neurons, 3)
self.sm = torch.nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.activ1(x)
x = self.fc2(x)
x = self.activ2(x)
x = self.fc3(x)
return x
def inference(self, x):
x = self.forward(x)
x = self.sm(x)
return x
wine_net = WineNet(20)
##
##
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(wine_net.parameters(), lr=0.01)
##
batch_size = 10
for epoch in range(5000):
order = np.random.permutation(len(X_train))
for start_index in range(0, len(X_train), batch_size):
optimizer.zero_grad()
batch_indexes = order[start_index:start_index+batch_size]
x_batch = X_train[batch_indexes]
y_batch = y_train[batch_indexes]
preds = wine_net.forward(x_batch)
loss_value = loss(preds, y_batch)
loss_value.backward()
optimizer.step()
if epoch % 100 == 0:
test_preds = wine_net.forward(X_test)
test_preds = test_preds.argmax(dim=1)
print((test_preds == y_test).float().mean())
##
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (10, 8)
n_classes = 3
plot_colors = ['g', 'orange', 'black']
plot_step = 0.02
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = torch.meshgrid(torch.arange(x_min, x_max, plot_step),
torch.arange(y_min, y_max, plot_step))
preds = wine_net.inference(
torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1)], dim=1))
preds_class = preds.data.numpy().argmax(axis=1)
preds_class = preds_class.reshape(xx.shape)
plt.contourf(xx, yy, preds_class, cmap='Accent')
for i, color in zip(range(n_classes), plot_colors):
indexes = np.where(y_train == i)
plt.scatter(X_train[indexes, 0],
X_train[indexes, 1],
c=color,
label=wine.target_names[i],
cmap='Accent')
plt.xlabel(wine.feature_names[0])
plt.ylabel(wine.feature_names[1])
plt.legend()
##
Результат выполнения работы программы
Выводы по работе
Выполняя лабораторную работу №8, я научился исследовать принципы разработки нейронной сети на примере задачи классификации данных в PyTorch.
Можно сделать вывод, что для данной задачи два скрытых слоя – это слишком много, это переусложнение, и хватает всего одного скрытого слоя, даже более того, от уменьшения сложности нейронной сети мы выигрываем в качестве.