ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 655
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
для версий чипов с различным количеством ядер и других компонентов. По словам пред- ставителей компании, в перспективе к кольцевой шине может быть "подключено" до 20 процессорных ядер на кристалл, и подобный реди- зайн, как вы понимаете, может производиться очень быстро, в виде гиб- кой и оперативной реакции на текущие потребности рынка. Кроме того, физически кольцевая шина располагается непосредственно над блоками кеш-памяти L3 в верхнем уровне металлизации, что упрощает разводку дизайна и позволяет сделать чип более компактным.
Вычислительное ядро Haswell не претерпело кардинальных изме- нений в сравнении с вычислительным ядром Sandy Bridge — были улучшены лишь отдельные блоки ядра процессора. А потому уместным будет рассмотреть в общих чертах микроархитектуру Sandy Bridge и остановиться на внесенных в нее изменениях в Haswell.
Традиционно описание микроархитектуры ядра процессора начи- нается с блока предпроцессора (front-end), который отвечает за выборку инструкций x86 из кэша инструкций и их декодирование. В микроархи- тектуре Haswell блок предпроцессора претерпел минимальные измене- ния (рис. 3.13).
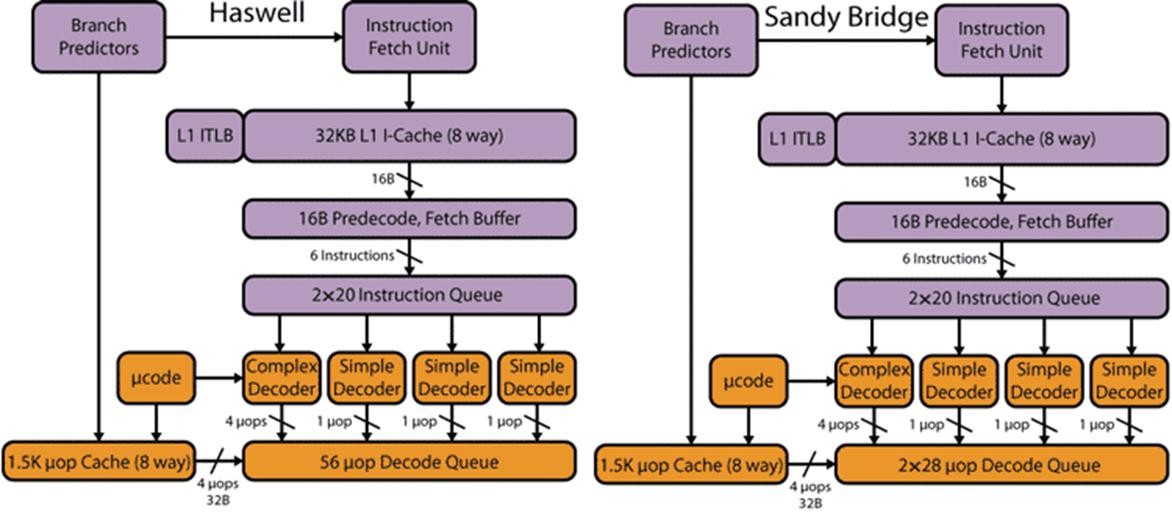
Рис. 3.13. Структура предпроцессора
Инструкции x86 выбираются из кэша инструкций L1I (Instruction Сache), который не изменился в микроархитектуре Haswell. Он имеет размер 32 Кбайт, является 8-канальным и динамически разделяем меж- ду двумя потоками инструкций (поддержка технологии Hyper- Threading).
Из кэша L1I команды загружаются 16-байтными блоками в 16- байтный буфер предекодирования (Fetch Buffer).
Поскольку инструкции x86 имеют переменную длину (от 1 до 16 байт), а длина блоков, которыми команды загружаются из кэша, фикси- рованная, при декодировании команд определяются границы между от-
дельными командами (информация о размерах команд хранится в кэше
инструкций L1I в специальных полях). Процедура выделения команд из выбранного блока называется предварительным декодированием (PreDecode).
После операции выборки команды организуются в очередь (Instruction Queue). В микроархитектуре Sandy Bridge и Haswell буфер очереди команд рассчитан на 20 команд в каждом из двух потоков, при- чем из буфера предекодирования за каждый такт в буфер очереди ко- манд могут загружаться до шести выделенных команд.
После этого выделенные команды (x86-инструкции) передаются в декодер, где они преобразуются в машинные микрокоманды (обознача- ются как micro-ops или uOps).
Декодер ядра процессора Haswell остался без изменений. Он по- прежнему является четырехканальным и может декодировать в каждом такте до четырех инструкций x86.
Четырехканальный декодер состоит из трех простых декодеров, де- кодирующих простые инструкции в одну микрокоманду, и одного сложного, который способен декодировать одну инструкцию не более чем в четыре микрокоманды (декодер типа 4-1-1-1). Для еще более сложных инструкций, декодирующихся более чем в четыре микроко- манды, сложный декодер соединен с блоком uCode Sequenser, который и применяется для декодирования подобных инструкций.
При декодировании инструкций используются технологии Macro- Fusion и Micro-Fusion.
Кроме того, в микроархитектуре Haswell и Sandy Bridge применя- ется кэш декодированных микрокоманд (Uop Cache), в который посту- пают все декодированные микрокоманды. Этот кэш рассчитан прибли- зительно на 1500 микрокоманд средней длины.
Концепция кэша декодированных микрокоманд заключается в том, чтобы сохранять в нем уже декодированные последовательности мик- рокоманд. В результате, если нужно выполнить некую x86-инструкцию повторно, а соответствующая ей последовательность декодированных
микрокоманд все еще находится в кэше декодированных микрокоманд, не требуется вторично выбирать эту инструкцию из кэша L1 и декоди- ровать ее — из кэша на дальнейшую обработку поступают уже декоди- рованные микрокоманды.
После процесса декодирования x86-инструкций они, по четыре штуки за такт, поступают в буфер очереди декодированных инструкций (Decode Queue). В микроархитектуре Sandy Bridge этот буфер очереди декодированных инструкций был рассчитан на два потока команд по 28 микрокоманд на каждый поток. В микроархитектурах Ivy Bridge и
Haswell он не делится на два потока команд и рассчитан на 56 микроко- манд. Такой подход оказывается более предпочтительным при выпол- нении однопоточного приложения (с одним потоком команд). В этом случае одному потоку команд доступен буфер емкостью на 56 микро- команд, а в микроархитектуре Sandy Bridge — только на 28 микроко- манд.
Предпроцессоры ядер Haswell и Sandy Bridge различаются лишь структурой буфера очереди декодированных инструкций.
Тем не менее, как заявляет компания Intel, некоторые улучшения в предпроцессор Haswell все же были внесены и касались усовершенство- вания блока предсказания ветвлений (Branch Predictors). Однако, какие именно улучшения были реализованы, компания Intel не раскрывает.
Заканчивая описание предпроцессора в микроархитектуре Haswell, нужно также упомянуть и о TLB-буфере.
Буфер TLB (Translation Look-aside Buffers) — это специальный кэш процессора, в котором сохраняются адреса декодированных инструкций и данных, что позволяет значительно сократить время доступа к ним. Этот кэш предназначен для сокращения времени преобразования вирту- ального адреса данных или инструкций в физический. Дело в том, что процессор использует виртуальную адресацию, а для доступа к данным в кэше или оперативной памяти нужны реальные физические адреса. Преобразование виртуального адреса в физический занимает приблизи- тельно три такта процессора. TLB-кэш хранит результаты предыдущих преобразований, благодаря чему преобразование адреса возможно осу-
ществлять за один такт.
В процессорах c микроархитектурой Haswell и Sandy Bridge (как и в процессорах Intel на базе других микроархитектур) используется двухуровневый кэш TLB, причем если кэш L2 TLB является унифици- рованным, то L1 TLB-кэш разделен на буфер данных (DTLB) и буфер инструкций (ITLB).
После процесса декодирования x86-инструкций начинается этап их внеочередного исполнения (Out-of-Order).
На первом этапе происходит переименование и распределение до- полнительных регистров процессора, которые не определены архитек- турой набора команд. Поэтому из буфера очереди декодированных ин- струкций (Decode Queue) микрооперации по четыре штуки за такт по- ступают в буфер переупорядочения (ReOrder Buffer), где происходит
переупорядочение микроопераций не в порядке их поступления (Out-of- Order).
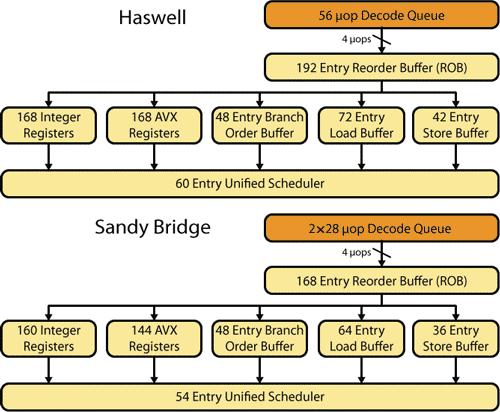 В микроархитектуре Sandy Bridge размер буфера переупорядочения рассчитан на 168 микроопераций, а в микроархитектуре Haswell — на 192 микрооперации (рис. 3.14).
В микроархитектуре Sandy Bridge размер буфера переупорядочения рассчитан на 168 микроопераций, а в микроархитектуре Haswell — на 192 микрооперации (рис. 3.14).
Рис. 3.14. Структура блока внеочередного исполнения команд Далее происходит распределение микрокоманд по исполнительным
блокам. В блоке процессора Unified Scheduler формируются очереди микрокоманд, в результате чего микрокоманды попадают на один из портов функциональных устройств (Dispatch ports). Этот процесс назы- вается диспетчеризацией (Dispatch), а сами порты выполняют функцию шлюза к функциональным устройствам.
В микроархитектурах Sandy Bridge и Haswell кластеры внеочеред- ного выполнения команд (Out-of-Order Cluster) используют так называ- емые физические регистровые файлы (Physical Register File, PRF), в ко- торых хранятся операнды микроопераций.
Напомним, что, когда в ядрах процессоров не применялись физиче- ские регистровые файлы (например, в микроархитектуре Nehalem), каждая микрооперация имела копию необходимого ей операнда (или операндов). Фактически это означало, что блоки кластера внеочередно- го выполнения команд должны были обладать достаточно большим
размером, чтобы иметь возможность вмещать микрооперации вместе с требуемыми им операндами.
-
Микроархитектура Intel Haswell
Вычислительное ядро Haswell не претерпело кардинальных изме- нений в сравнении с вычислительным ядром Sandy Bridge — были улучшены лишь отдельные блоки ядра процессора. А потому уместным будет рассмотреть в общих чертах микроархитектуру Sandy Bridge и остановиться на внесенных в нее изменениях в Haswell.
Традиционно описание микроархитектуры ядра процессора начи- нается с блока предпроцессора (front-end), который отвечает за выборку инструкций x86 из кэша инструкций и их декодирование. В микроархи- тектуре Haswell блок предпроцессора претерпел минимальные измене- ния (рис. 3.13).
Рис. 3.13. Структура предпроцессора
Инструкции x86 выбираются из кэша инструкций L1I (Instruction Сache), который не изменился в микроархитектуре Haswell. Он имеет размер 32 Кбайт, является 8-канальным и динамически разделяем меж- ду двумя потоками инструкций (поддержка технологии Hyper- Threading).
Из кэша L1I команды загружаются 16-байтными блоками в 16- байтный буфер предекодирования (Fetch Buffer).
Поскольку инструкции x86 имеют переменную длину (от 1 до 16 байт), а длина блоков, которыми команды загружаются из кэша, фикси- рованная, при декодировании команд определяются границы между от-
дельными командами (информация о размерах команд хранится в кэше
инструкций L1I в специальных полях). Процедура выделения команд из выбранного блока называется предварительным декодированием (PreDecode).
После операции выборки команды организуются в очередь (Instruction Queue). В микроархитектуре Sandy Bridge и Haswell буфер очереди команд рассчитан на 20 команд в каждом из двух потоков, при- чем из буфера предекодирования за каждый такт в буфер очереди ко- манд могут загружаться до шести выделенных команд.
После этого выделенные команды (x86-инструкции) передаются в декодер, где они преобразуются в машинные микрокоманды (обознача- ются как micro-ops или uOps).
Декодер ядра процессора Haswell остался без изменений. Он по- прежнему является четырехканальным и может декодировать в каждом такте до четырех инструкций x86.
Четырехканальный декодер состоит из трех простых декодеров, де- кодирующих простые инструкции в одну микрокоманду, и одного сложного, который способен декодировать одну инструкцию не более чем в четыре микрокоманды (декодер типа 4-1-1-1). Для еще более сложных инструкций, декодирующихся более чем в четыре микроко- манды, сложный декодер соединен с блоком uCode Sequenser, который и применяется для декодирования подобных инструкций.
При декодировании инструкций используются технологии Macro- Fusion и Micro-Fusion.
Кроме того, в микроархитектуре Haswell и Sandy Bridge применя- ется кэш декодированных микрокоманд (Uop Cache), в который посту- пают все декодированные микрокоманды. Этот кэш рассчитан прибли- зительно на 1500 микрокоманд средней длины.
Концепция кэша декодированных микрокоманд заключается в том, чтобы сохранять в нем уже декодированные последовательности мик- рокоманд. В результате, если нужно выполнить некую x86-инструкцию повторно, а соответствующая ей последовательность декодированных
микрокоманд все еще находится в кэше декодированных микрокоманд, не требуется вторично выбирать эту инструкцию из кэша L1 и декоди- ровать ее — из кэша на дальнейшую обработку поступают уже декоди- рованные микрокоманды.
После процесса декодирования x86-инструкций они, по четыре штуки за такт, поступают в буфер очереди декодированных инструкций (Decode Queue). В микроархитектуре Sandy Bridge этот буфер очереди декодированных инструкций был рассчитан на два потока команд по 28 микрокоманд на каждый поток. В микроархитектурах Ivy Bridge и
Haswell он не делится на два потока команд и рассчитан на 56 микроко- манд. Такой подход оказывается более предпочтительным при выпол- нении однопоточного приложения (с одним потоком команд). В этом случае одному потоку команд доступен буфер емкостью на 56 микро- команд, а в микроархитектуре Sandy Bridge — только на 28 микроко- манд.
Предпроцессоры ядер Haswell и Sandy Bridge различаются лишь структурой буфера очереди декодированных инструкций.
Тем не менее, как заявляет компания Intel, некоторые улучшения в предпроцессор Haswell все же были внесены и касались усовершенство- вания блока предсказания ветвлений (Branch Predictors). Однако, какие именно улучшения были реализованы, компания Intel не раскрывает.
Заканчивая описание предпроцессора в микроархитектуре Haswell, нужно также упомянуть и о TLB-буфере.
Буфер TLB (Translation Look-aside Buffers) — это специальный кэш процессора, в котором сохраняются адреса декодированных инструкций и данных, что позволяет значительно сократить время доступа к ним. Этот кэш предназначен для сокращения времени преобразования вирту- ального адреса данных или инструкций в физический. Дело в том, что процессор использует виртуальную адресацию, а для доступа к данным в кэше или оперативной памяти нужны реальные физические адреса. Преобразование виртуального адреса в физический занимает приблизи- тельно три такта процессора. TLB-кэш хранит результаты предыдущих преобразований, благодаря чему преобразование адреса возможно осу-
ществлять за один такт.
В процессорах c микроархитектурой Haswell и Sandy Bridge (как и в процессорах Intel на базе других микроархитектур) используется двухуровневый кэш TLB, причем если кэш L2 TLB является унифици- рованным, то L1 TLB-кэш разделен на буфер данных (DTLB) и буфер инструкций (ITLB).
Блок внеочередного исполнения команд
После процесса декодирования x86-инструкций начинается этап их внеочередного исполнения (Out-of-Order).
На первом этапе происходит переименование и распределение до- полнительных регистров процессора, которые не определены архитек- турой набора команд. Поэтому из буфера очереди декодированных ин- струкций (Decode Queue) микрооперации по четыре штуки за такт по- ступают в буфер переупорядочения (ReOrder Buffer), где происходит
переупорядочение микроопераций не в порядке их поступления (Out-of- Order).
В микроархитектуре Sandy Bridge размер буфера переупорядочения рассчитан на 168 микроопераций, а в микроархитектуре Haswell — на 192 микрооперации (рис. 3.14).Рис. 3.14. Структура блока внеочередного исполнения команд Далее происходит распределение микрокоманд по исполнительным
блокам. В блоке процессора Unified Scheduler формируются очереди микрокоманд, в результате чего микрокоманды попадают на один из портов функциональных устройств (Dispatch ports). Этот процесс назы- вается диспетчеризацией (Dispatch), а сами порты выполняют функцию шлюза к функциональным устройствам.
В микроархитектурах Sandy Bridge и Haswell кластеры внеочеред- ного выполнения команд (Out-of-Order Cluster) используют так называ- емые физические регистровые файлы (Physical Register File, PRF), в ко- торых хранятся операнды микроопераций.
Напомним, что, когда в ядрах процессоров не применялись физиче- ские регистровые файлы (например, в микроархитектуре Nehalem), каждая микрооперация имела копию необходимого ей операнда (или операндов). Фактически это означало, что блоки кластера внеочередно- го выполнения команд должны были обладать достаточно большим
размером, чтобы иметь возможность вмещать микрооперации вместе с требуемыми им операндами.