ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 651
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
Использование PRF позволяет самим микрооперациям сохранять лишь указатели на операнды, но не сами операнды. С одной стороны, такой подход обеспечивает снижение энергопотребления процессора, поскольку перемещение по конвейеру микроопераций вместе с их опе- рандами требует существенных затрат по энергопотреблению. С дру- гой — применение физического регистрового файла позволяет сэконо- мить размер кристалла, а высвободившееся пространство использовать для увеличения размеров буферов кластера внеочередного выполнения команд.
В микроархитектуре Sandy Bridge физический регистровый файл для целочисленных операндов (Integer Registers) рассчитан на 160 записей, а для операндов с плавающей запятой (AVX Registers) — на 144 записи.
В микроархитектуре Haswell физические регистровые файлы Integer Registers и AVX Registers рассчитаны на 168 записей.
Буферы чтения (Load) и записи (Store), которые используются для доступа к памяти, также увеличились. Например, если в микроархитек- туре Sandy Bridge буферы Load и Store были рассчитаны на 64 и 36 за- писей соответственно, то в микроархитектуре Haswell они рассчитаны соответственно на 72 и 42 записи.
Размер буфера Unified Scheduler, в котором формируются очереди микроопераций к портам функциональных устройств, также изменился в микроархитектуре Haswell. Если в Sandy Bridge он был рассчитан на 54 микрооперации, то в Haswell — на 60.
Итак, если сравнивать архитектуры Haswell и Sandy Bridge, то в блоке внеочередного исполнения команд микроархитектура Haswell имеет не структурные, а лишь качественные изменения, касающиеся увеличения размеров буферов. Но никаких принципиальных изменений
в блоке внеочередного исполнения команд в микроархитектуре Haswell нет.
Что касается исполнительных блоков ядра процессора, то в микро- архитектуре Haswell они претерпели существенные изменения по срав- нению с микроархитектурой Sandy Bridge. Так, в Sandy Bridge насчиты- вается шесть портов функциональных устройств (портов диспетчериза- ции): три вычислительных и три для работы с памятью.
В микроархитектуре Haswell количество портов функциональных устройств увеличено до восьми.
На рис. 3.15 показаны только вычислительные порты.
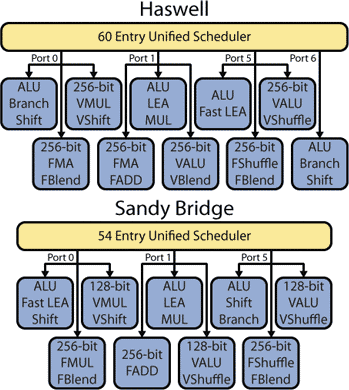
Рис. 3.15. Состав исполнительных утройств, подсоединенных к вычислительным портам
К тому, что было в микроархитектуре Sandy Bridge, добавили еще один порт для записи адреса (Store address) и вычислительный порт для операций с целыми числами и операций сдвига (Integer ALU & Shift). Таким образом, процессоры Haswell могут за один такт выполнять до восьми микроопераций, в то время как в микроархитектуре Sandy Bridge максимальное количество выполняемых за такт микроопераций равно шести.
Кроме того, в микроархитектуре Haswell немного изменены и сами исполнительные устройства. Связано это с тем, что в микроархитектуре Haswell появились дополнительные наборы инструкций: AVX2, FMA3 и BMI.
Одно из наиболее значимых изменений в микроархитектуре Haswell в сравнении с Sandy Bridge было сделано в подсистеме памяти (рис. 3.16). И дело не только в том, что увеличен размер буферов чтения (Load) и записи (Store), которые используются для доступа к памяти (72 и 42 записи соответственно). Главное, был добавлен еще один порт для записи адреса (Store address), кэш данных L1 стал более производитель- ным, а пропускная способность между кэшами L1 и L2 увеличена. Рас- смотрим эти изменения более подробно.
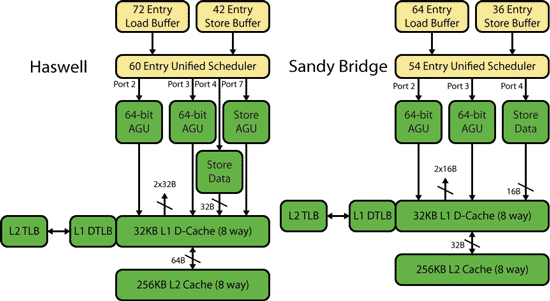
Рис. 3.16 Структура подсистема памяти
Доступ к подсистеме памяти начинается с того, что соответствую-
щие микрооперации поступают в буферы чтения (Load) и записи (Store), которые в совокупности могут накапливать более ста микроопераций. В микроархитектуре Sandy Bridge порты функциональных устройств, ко- торые маркируются на схемах как 2, 3 и 4, отвечали именно за доступ к памяти. Порты 2 и 3 связаны с функциональными устройствами генера- ции адреса (Address Generation Unit, AGU) для записи или чтения дан- ных, а порт 4 связан с функциональным устройством для записи данных из ядра процессора в кэш данных L1 (DL1). Процедура генерации адре- са занимает один или два такта процессора.
В микроархитектуре Haswell к портам 4, 2 и 3 добавлен еще порт 7, который связан с функциональным устройством генерации адреса для записи данных (Store AGU). В результате ядро Haswell может поддер-
живать две операции загрузки данных и одну операцию записи данных за такт.
Выделенное функциональное устройство генерации адреса для за- писи данных немного проще в исполнении в сравнении с функциональ- ными устройствами генерации адреса общего назначения (для записи и загрузки данных). Дело в том, что микрооперация записи данных просто записывает адрес (и, в конечном счете, сами данные) в буфер записи (store buffer). А микрооперация загрузки данных должна записывать в буфер чтения и также отслеживать содержимое буфера записи, для того чтобы исключить возможные конфликты.
Как только сгенерирован нужный виртуальный адрес, начинается просмотр кэша L1 DTLB на предмет соответствия этого виртуального адреса физическому. Сам кэш данных L1 DTLB в микроархитектуре Haswell не претерпел изменений.
При промахе в кэше L1 DTLB начинается просмотр соответствую- щих записей в унифицированном кэше L2 TLB, который имеет ряд улучшений в микроархитектуре Haswell.
Сам кэш данных L1 остался размером 32 Кбайт и 8-канальным (как и в микроархитектуре Sandy Bridge).
Однако в микроархитектуре Haswell кэш данных L1 имеет более высокую пропускную способность. Он поддерживает одновременно две
256-битных операций чтения и одну 256-битную операцию записи, что в совокупности дает агрегированную полосу пропускания в 96 байт за такт. В микроархитектуре Sandy Bridge кэш данных L1 поддерживает одновременно две 128-битных операций чтения и одну 128-битную опе- рацию записи, то есть имеет теоретическую полосу пропускания в два раза ниже. При этом реальная полоса пропускания кэша данных L1 в микроархитектуре Sandy Bridge более чем вдвое ниже полосы пропус- кания в микроархитектуре Haswell по причине того, что в Sandy Bridge только два функциональных блока AGU.
Кроме того, в микроархитектуре Haswell увеличена и пропускная способность между кэшами L1 и L2. Так, если в Sandy Bridge пропуск- ная способность между кэшем L2 и L1 составляла 32 байта за цикл, то в Haswell она повышена до 64 байтов за цикл. И при этом кэш L2 в Haswell имеет ту же латентность, что и в Sandy Bridge. В заключение отметим, что, как и в микроархитектуре Sandy Bridge, в Haswell кэш L2 не эксклюзивен и не инклюзивен по отношению к кэшу L1.
Одно из основных нововведений в микроархитектуре Haswell — это новое графическое ядро c поддержкой DirectX 11.1, OpenCL 1.2 и OpenGL 4.0 (рис. 3 17).
Но самое главное, что графическое ядро в микроархитектуре Haswell масштабируемое. Существуют варианты графического ядра с кодовыми названиями GT3, GT2 и GT1.
Ядро GT1 имеет минимальную производительность, а GT3 — мак- симальную.
В графическом ядре GT3 появился второй вычислительный блок, за счет чего удвоилось количество блоков растеризации, пиксельных кон- вейеров, вычислительных ядер и сэмплеров. Ожидается, что GT3 будет вдвое производительнее GT2.
Ядро GT3 содержит 40 исполнительных блоков, 160 вычислитель- ных ядер и четыре текстурных блока. Для сравнения напомним, что в графическом ядре Intel HD Graphics 4000 процессоров Ivy Bridge содер- жится 16 исполнительных устройств, 64 вычислительных ядра и два текстурных блока. Поэтому, несмотря на приблизительно одинаковые тактовые частоты их работы, графическое ядро Intel GT3 превосходит
В микроархитектуре Sandy Bridge физический регистровый файл для целочисленных операндов (Integer Registers) рассчитан на 160 записей, а для операндов с плавающей запятой (AVX Registers) — на 144 записи.
В микроархитектуре Haswell физические регистровые файлы Integer Registers и AVX Registers рассчитаны на 168 записей.
Буферы чтения (Load) и записи (Store), которые используются для доступа к памяти, также увеличились. Например, если в микроархитек- туре Sandy Bridge буферы Load и Store были рассчитаны на 64 и 36 за- писей соответственно, то в микроархитектуре Haswell они рассчитаны соответственно на 72 и 42 записи.
Размер буфера Unified Scheduler, в котором формируются очереди микроопераций к портам функциональных устройств, также изменился в микроархитектуре Haswell. Если в Sandy Bridge он был рассчитан на 54 микрооперации, то в Haswell — на 60.
Итак, если сравнивать архитектуры Haswell и Sandy Bridge, то в блоке внеочередного исполнения команд микроархитектура Haswell имеет не структурные, а лишь качественные изменения, касающиеся увеличения размеров буферов. Но никаких принципиальных изменений
в блоке внеочередного исполнения команд в микроархитектуре Haswell нет.
Исполнительные блоки ядра процессора
Что касается исполнительных блоков ядра процессора, то в микро- архитектуре Haswell они претерпели существенные изменения по срав- нению с микроархитектурой Sandy Bridge. Так, в Sandy Bridge насчиты- вается шесть портов функциональных устройств (портов диспетчериза- ции): три вычислительных и три для работы с памятью.
В микроархитектуре Haswell количество портов функциональных устройств увеличено до восьми.
На рис. 3.15 показаны только вычислительные порты.
Рис. 3.15. Состав исполнительных утройств, подсоединенных к вычислительным портам
К тому, что было в микроархитектуре Sandy Bridge, добавили еще один порт для записи адреса (Store address) и вычислительный порт для операций с целыми числами и операций сдвига (Integer ALU & Shift). Таким образом, процессоры Haswell могут за один такт выполнять до восьми микроопераций, в то время как в микроархитектуре Sandy Bridge максимальное количество выполняемых за такт микроопераций равно шести.
Кроме того, в микроархитектуре Haswell немного изменены и сами исполнительные устройства. Связано это с тем, что в микроархитектуре Haswell появились дополнительные наборы инструкций: AVX2, FMA3 и BMI.
Подсистема памяти в микроархитектуре Haswell
Одно из наиболее значимых изменений в микроархитектуре Haswell в сравнении с Sandy Bridge было сделано в подсистеме памяти (рис. 3.16). И дело не только в том, что увеличен размер буферов чтения (Load) и записи (Store), которые используются для доступа к памяти (72 и 42 записи соответственно). Главное, был добавлен еще один порт для записи адреса (Store address), кэш данных L1 стал более производитель- ным, а пропускная способность между кэшами L1 и L2 увеличена. Рас- смотрим эти изменения более подробно.
Рис. 3.16 Структура подсистема памяти
Доступ к подсистеме памяти начинается с того, что соответствую-
щие микрооперации поступают в буферы чтения (Load) и записи (Store), которые в совокупности могут накапливать более ста микроопераций. В микроархитектуре Sandy Bridge порты функциональных устройств, ко- торые маркируются на схемах как 2, 3 и 4, отвечали именно за доступ к памяти. Порты 2 и 3 связаны с функциональными устройствами генера- ции адреса (Address Generation Unit, AGU) для записи или чтения дан- ных, а порт 4 связан с функциональным устройством для записи данных из ядра процессора в кэш данных L1 (DL1). Процедура генерации адре- са занимает один или два такта процессора.
В микроархитектуре Haswell к портам 4, 2 и 3 добавлен еще порт 7, который связан с функциональным устройством генерации адреса для записи данных (Store AGU). В результате ядро Haswell может поддер-
живать две операции загрузки данных и одну операцию записи данных за такт.
Выделенное функциональное устройство генерации адреса для за- писи данных немного проще в исполнении в сравнении с функциональ- ными устройствами генерации адреса общего назначения (для записи и загрузки данных). Дело в том, что микрооперация записи данных просто записывает адрес (и, в конечном счете, сами данные) в буфер записи (store buffer). А микрооперация загрузки данных должна записывать в буфер чтения и также отслеживать содержимое буфера записи, для того чтобы исключить возможные конфликты.
Как только сгенерирован нужный виртуальный адрес, начинается просмотр кэша L1 DTLB на предмет соответствия этого виртуального адреса физическому. Сам кэш данных L1 DTLB в микроархитектуре Haswell не претерпел изменений.
При промахе в кэше L1 DTLB начинается просмотр соответствую- щих записей в унифицированном кэше L2 TLB, который имеет ряд улучшений в микроархитектуре Haswell.
Сам кэш данных L1 остался размером 32 Кбайт и 8-канальным (как и в микроархитектуре Sandy Bridge).
Однако в микроархитектуре Haswell кэш данных L1 имеет более высокую пропускную способность. Он поддерживает одновременно две
256-битных операций чтения и одну 256-битную операцию записи, что в совокупности дает агрегированную полосу пропускания в 96 байт за такт. В микроархитектуре Sandy Bridge кэш данных L1 поддерживает одновременно две 128-битных операций чтения и одну 128-битную опе- рацию записи, то есть имеет теоретическую полосу пропускания в два раза ниже. При этом реальная полоса пропускания кэша данных L1 в микроархитектуре Sandy Bridge более чем вдвое ниже полосы пропус- кания в микроархитектуре Haswell по причине того, что в Sandy Bridge только два функциональных блока AGU.
Кроме того, в микроархитектуре Haswell увеличена и пропускная способность между кэшами L1 и L2. Так, если в Sandy Bridge пропуск- ная способность между кэшем L2 и L1 составляла 32 байта за цикл, то в Haswell она повышена до 64 байтов за цикл. И при этом кэш L2 в Haswell имеет ту же латентность, что и в Sandy Bridge. В заключение отметим, что, как и в микроархитектуре Sandy Bridge, в Haswell кэш L2 не эксклюзивен и не инклюзивен по отношению к кэшу L1.
Графическое ядро в микроархитектуре Haswell
Одно из основных нововведений в микроархитектуре Haswell — это новое графическое ядро c поддержкой DirectX 11.1, OpenCL 1.2 и OpenGL 4.0 (рис. 3 17).
Но самое главное, что графическое ядро в микроархитектуре Haswell масштабируемое. Существуют варианты графического ядра с кодовыми названиями GT3, GT2 и GT1.
Ядро GT1 имеет минимальную производительность, а GT3 — мак- симальную.
В графическом ядре GT3 появился второй вычислительный блок, за счет чего удвоилось количество блоков растеризации, пиксельных кон- вейеров, вычислительных ядер и сэмплеров. Ожидается, что GT3 будет вдвое производительнее GT2.
Ядро GT3 содержит 40 исполнительных блоков, 160 вычислитель- ных ядер и четыре текстурных блока. Для сравнения напомним, что в графическом ядре Intel HD Graphics 4000 процессоров Ivy Bridge содер- жится 16 исполнительных устройств, 64 вычислительных ядра и два текстурных блока. Поэтому, несмотря на приблизительно одинаковые тактовые частоты их работы, графическое ядро Intel GT3 превосходит