ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 634
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ

Архивная память
Внешняя память
Оперативный Внешний Архивный
Рис. 4.1. Иерархическая структура памяти
Сравнительно небольшая емкость оперативной памяти компенси- руется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства работают намного медленнее, чем оперативная память. Время обращения за данными для магнитных дис- ков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет несколько десятков наносекунд. Исходя из этого, вычислительный процесс должен протекать с возмож- но меньшим числом обращений к внешней памяти. Память современ- ных компьютеров реализуется на микросхемах статических и динами- ческих запоминающих устройств с произвольной выборкой. Микросхе- мы статических ЗУ (SRAM) имеют меньшее время доступа и не требу- ют циклов регенерации (восстановления) информации. Микросхемы динамических ЗУ (DRAM) характеризуются большей емкостью и меньшей стоимостью, но требуют схем регенерации и имеют значи- тельно большее время доступа. У статических ЗУ время доступа совпа- дает с длительностью цикла.
По этим причинам в основной памяти практически любого компь- ютера, проданного после 1975 г., использовались полупроводниковые микросхемы DRAM (SDRAM, DDR SDRAM, RDRAM). Для построения кэш-памяти применяются SRAM.
Непрерывный рост производительности ЭВМ проявляется в первую очередь в повышении скорости работы процессора. Быстродей- ствие ОП также растет, но все время отстает от быстродействия аппа- ратных средств процессора в значительной степени потому, что одно- временно происходит опережающий рост её емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП часто оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Это проявляется в несоответствии пропускных
способностей процессора и ОП. Возникающая проблема выравнивания их пропускных способностей решается путем использо- вания сверхоперативной буферной памяти небольшой емкости и повы- шенного быстродействия, хранящей команды и данные, относящиеся к обрабатываемому участку программы.
При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память (СБП). Последующие обращения производятся к копии блока данных, находящейся в СБП. Поскольку время выборки из сверхоперативной буферной памяти tСБУ (несколько наносекунд) много меньше времени выборки из оперативной памяти tОП, введение в структуру памяти СБП
приводит к уменьшению эквивалентного времени обращения tЭ по сравнению с tОП:
tЭ =tСБП + tОП ,
где = (1 – q) и q – вероятность нахождения блока в СБП в момент об- ращения к нему, т.е. вероятность «попадания». Очевидно, что при высо- кой вероятности попадания эквивалентное время обращения приближа- ется к времени обращения к СБП.
В основе такой организации взаимодействия ОП и СБП лежит принцип локальности обращений, согласно которому при выполнении какой-либо программы (практически для всех классов задач) большая часть обращений в пределах некоторого интервала времени приходится на ограниченную область адресного пространства ОП, причем обраще- ния к командам и элементам данных этой области производятся много- кратно. Это позволяет копии наиболее часто используемых участков программ и некоторых данных загрузить в СБП и таким образом обес-
печить высокую вероятность попадания q. Высокая эффективность применения СБП достигается при q 0,9.
Буферная память не является программно доступной. Это значит, что она влияет только на производительность ЭВМ, но не должна ока- зывать влияния на программирование прикладных задач. Поэтому она получила название кэш-памяти (в переводе с английского – тайник). В современных компьютерах применяют многоуровневую кэш-память (до трех уровней), которая еще больше способствует производительно- сти ЭВМ. Как правило, на первом уровне используются раздельные кэш-памяти для команд и данных, а на других уровнях данные и коман- ды хранятся в одних и тех же кэш-памятях.
- 1 ... 55 56 57 58 59 60 61 62 ... 76
Организация стека регистров
Регистровая структура процессора была рассмотрена в разд. 3.
Стек регистров, реализующий безадресное задание операндов, яв- ляется эффективным элементом архитектуры ЭВМ. Стек представляет собой группу последовательно пронумерованных регистров, снабжён- ных указателем стека, в котором автоматически при записи устанавли- вается номер первого свободного регистра стека (вершина стека). Су- ществует два основных способа организации стека регистров:
LIFO (Last-in First-Out) – последний пришёл – первый ушёл; FIFO (First-in First-Out) – первый пришёл – первый ушёл.
Механизм стековой адресации для первого способа поясняется на рис. 5.2. Для реализации адресации по способу LIFO используется счёт- чик адреса СЧА, который перед началом работы устанавливается в со- стояние ноль, и память (стек) считается пустой. Состояние СЧА опреде- ляет адрес первой свободной ячейки. Слово загружается в стек с вход- ной шины Хв момент поступления сигнала записи ЗП.
По сигналу ЗП слово Х записывается в регистр P[СЧА], номер ко- торого определяется текущим состоянием счётчика адреса, после чего с задержкой D, достаточной для выполнения микрооперации записи P[СЧА]:=Х, состояние счетчика увеличивается на единицу. Таким обра- зом, при последовательной загрузке слова А, В и С размещаются в реги- страх с адресами P[S], P[S + 1] и P[S + 2], где S – состояние счётчика на момент начала загрузки. Операция чтения слова из ЗУ инициируется сиг- налом ЧТ, при поступлении которого состояние счётчика уменьшается на единицу, после чего на выходную шину Yпоступает слово, записанное
в стек последним. Если слова загружались в стек в порядке А, В, С, то они могут быть прочитаны только в обратном порядке: С, В, А.
| 1 | P[0] | n |
| 1 | P[1] | n |
| … | ||
| 1 | P[M] | n |
В современных архитектурах процессоров стек и стековая адреса- ция широко используются при организации переходов к подпрограммам и возврата из них, а также в системах прерывания.
+1
-1


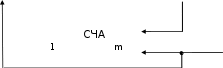 ЗП
ЗП ЧТ
СЧА:=0
Рис. 4.2. Механизм стековой адресации по способу LIFO
- 1 ... 56 57 58 59 60 61 62 63 ... 76