ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 652
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
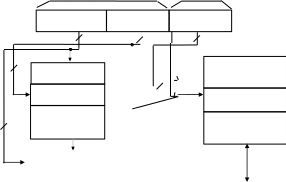
са строки, и на его место помещается строка, считанная из основной памяти. Осуществляется также обновление соответствующего тега в те- говой памяти.
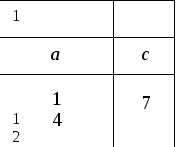
Способ прямого распределения реализовать довольно просто, од- нако из-за того, что место хранения строки в кэш-памяти однозначно определяется по адресу строки, вероятность сосредоточения областей хранения строк в некоторой части кэш-памяти высока, т.е. замены строк будут происходить довольно часто. В такой ситуации эффективность кэш-памяти заметно снижается.
 Тег
Тег
Индекс
Адрес внутри
Адрес строки
строки
a
7
7 1 7
b а
7 128
b
7
Теговая память
(b, c) 4
7
с
4
1
128
Адрес основной памяти
Память данных
 v
v

 Действительный/ недействительный
Действительный/ недействительный

 Данные считывания/записи
Данные считывания/записи
Рис. 4.4. Структура кэш-памяти с прямым распределением
При полностью ассоциативном распределении (fully associative) допускается размещение каждой строки основной памяти на месте лю- бой строки кэш-памяти. Структура кэш-памяти с полностью ассоциа- тивным распределением представлена на рис. 4.5.
Адрес основной памяти состоит из 14-разрядного адреса строки (тега) и 4-разрядного адреса внутри строки.
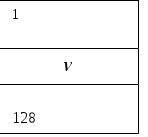
При полностью ассоциативном распределении механизм преобра- зования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память была реализована, как ассоциативная память. Входной информацией для ас- социативной памяти тегов (ключ поиска) является тег – 14-разрядный
адрес строки, а выходной информацией – адрес строки внутри кэш- памяти (памяти данных). Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса строки памяти данных кэша.
Ключ поиска параллельно сравнивается со всеми тегами ассоциа- тивной памяти. При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных.
Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной строке). При выполнении операции чтения по этому адресу считывается и передается в процессор выбранная строка, а при записи – по этому же адресу в па- мять данных записывается новая строка
данных. При несовпадении ключа ни с одним из тегов теговой памяти (кэш-промах) осуществляет- ся обращение к основной памяти и чтение необходимой строки.
Адрес строки (тег)
Адрес внутри

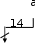
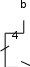 строки
строки


Память тегов
Память данных
 Адрес основной памяти
Адрес основной памяти
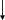

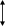
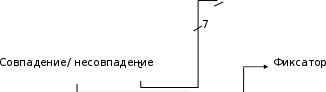 Действительный/недействительный
Действительный/недействительный
Данные считывания/записи
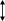 Рис. 4.5. Структура кэш-памяти с полностью ассоциативным распределением
Рис. 4.5. Структура кэш-памяти с полностью ассоциативным распределением
По этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти.
Если некоторая строка основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется ча- стично ассоциативным или множественно ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа строк, расположенных в различных банках (блоках) данных. Если группа (множество) состоит из n строк (банков, блоков), то такое размещение называется частично (множественно) ассоциатив- ным с n каналами (n– way).
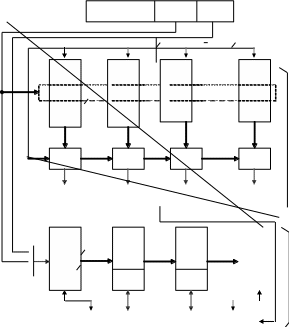
В качестве примера рассмотрим структуру четырёхканальной частич- но ассоциативной кэш-памяти (рис. 4.6). В этом случае 4 соседних строки из 128 строк кэш-памяти образуют структуру, называемую группой.
Адрес строки основной памяти (14 бит) разделяется на две части: b – тег (старшие 9 бит) и е – адрес группы (младшие 5 бит). Адрес стро- ки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бита).
Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адре- сами. Каждый банк массива тегов имеет длину слова 9 бит для помеще- ния значения тега, а число групп тегов в банке равно 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженным на число групп в кэш-памяти.
Для помещения в кэш-память строки, хранимой в
ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырёх строк в группе может быть выбрана. Для выбора груп- пы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по i-му адресу к кэш-памяти с целью чтения или записи, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (a, b, c, d), каждый из которых сравнивается со старшими 9 битами (b) адреса стро- ки. На выходе четырёх схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразряд- ный позиционный код, служащий адресом для выбора банка данных (01). При операции чтения (записи) одновременно осуществляется об- ращение к массиву данных по адресу e.f(9 бит) и считывание (запись) из банка (в банк) V2 требуемой строки или слова.
При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырёх строк соответствующего набора (группы).


Тег Адрес группы
Адрес строки Адрес внутри строки

 b e f
b e f
9 5 4
Адрес основной памяти
Способ прямого распределения реализовать довольно просто, од- нако из-за того, что место хранения строки в кэш-памяти однозначно определяется по адресу строки, вероятность сосредоточения областей хранения строк в некоторой части кэш-памяти высока, т.е. замены строк будут происходить довольно часто. В такой ситуации эффективность кэш-памяти заметно снижается.
Тег Индекс
Адрес внутри
Адрес строки
строки
a7
7 1 7
b а
7 128
b
7
Теговая память
(b, c) 4
7
с
4
1
128
Адрес основной памяти
Память данных
v Действительный/ недействительный Данные считывания/записиРис. 4.4. Структура кэш-памяти с прямым распределением
Полностью ассоциативное распределение
При полностью ассоциативном распределении (fully associative) допускается размещение каждой строки основной памяти на месте лю- бой строки кэш-памяти. Структура кэш-памяти с полностью ассоциа- тивным распределением представлена на рис. 4.5.
Адрес основной памяти состоит из 14-разрядного адреса строки (тега) и 4-разрядного адреса внутри строки.
При полностью ассоциативном распределении механизм преобра- зования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память была реализована, как ассоциативная память. Входной информацией для ас- социативной памяти тегов (ключ поиска) является тег – 14-разрядный
адрес строки, а выходной информацией – адрес строки внутри кэш- памяти (памяти данных). Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса строки памяти данных кэша.
Ключ поиска параллельно сравнивается со всеми тегами ассоциа- тивной памяти. При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных.
Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной строке). При выполнении операции чтения по этому адресу считывается и передается в процессор выбранная строка, а при записи – по этому же адресу в па- мять данных записывается новая строка
данных. При несовпадении ключа ни с одним из тегов теговой памяти (кэш-промах) осуществляет- ся обращение к основной памяти и чтение необходимой строки.
Адрес строки (тег)
Адрес внутри
строки Память тегов
Память данных
Адрес основной памяти Действительный/недействительныйДанные считывания/записи
Рис. 4.5. Структура кэш-памяти с полностью ассоциативным распределениемПо этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти.
Частично ассоциативное распределение
Если некоторая строка основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется ча- стично ассоциативным или множественно ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа строк, расположенных в различных банках (блоках) данных. Если группа (множество) состоит из n строк (банков, блоков), то такое размещение называется частично (множественно) ассоциатив- ным с n каналами (n– way).
В качестве примера рассмотрим структуру четырёхканальной частич- но ассоциативной кэш-памяти (рис. 4.6). В этом случае 4 соседних строки из 128 строк кэш-памяти образуют структуру, называемую группой.
Адрес строки основной памяти (14 бит) разделяется на две части: b – тег (старшие 9 бит) и е – адрес группы (младшие 5 бит). Адрес стро- ки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бита).
Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адре- сами. Каждый банк массива тегов имеет длину слова 9 бит для помеще- ния значения тега, а число групп тегов в банке равно 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженным на число групп в кэш-памяти.
Для помещения в кэш-память строки, хранимой в
ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырёх строк в группе может быть выбрана. Для выбора груп- пы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по i-му адресу к кэш-памяти с целью чтения или записи, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (a, b, c, d), каждый из которых сравнивается со старшими 9 битами (b) адреса стро- ки. На выходе четырёх схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразряд- ный позиционный код, служащий адресом для выбора банка данных (01). При операции чтения (записи) одновременно осуществляется об- ращение к массиву данных по адресу e.f(9 бит) и считывание (запись) из банка (в банк) V2 требуемой строки или слова.
При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырёх строк соответствующего набора (группы).
Тег Адрес группы
Адрес строки Адрес внутри строки
b e f9 5 4
Адрес основной памяти