ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 663
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
ростными категориями памяти нового стандарта DDR3 являются разно- видности DDR3-800, DDR3-1066, DDR3-1333, DDR3-1600, DDR3-1866.
Очередное увеличение теоретической пропускной способности компо- нентов памяти в 2 раза вновь связано со снижением их внутренней ча- стоты функционирования во столько же раз. Поэтому для достижения темпа передачи данных со скоростью 1 бит/такт по каждой линии внешней шины данных с «эффективной» частотой в 1600 МГц (как в примере, рассмотренном на рис. 4.8, г) используемые микросхемы (с частотой 200 МГц) должны передавать по 8 бит данных за каждый
«свой» такт, т.е. ширина внутренней шины данных микросхем памяти окажется уже в 8 раз больше по сравнению с шириной их внешней ши- ны. Такая схема передачи данных с рассмотренным преобразованием типа «8–1» называется схемой «8n-предвыборки» (8n-prefetch).
Частота ядра –
a 200 МГц
Частота буфера ввода/ вывода – 200 МГц
Частота внешней шины данных – 200 МГц





 б Частота ядра – 200 МГц
б Частота ядра – 200 МГц
в Частота ядра – 200 МГц
Частота буфера ввода/
вывода – 200 МГц

Частота буфера ввода/ вывода – 400 МГц
«Эффективная» частота внешней шины – 400 МГц


«Эффективная» частота внешней шины – 800 МГц



 DDR2-800 SDRAM
DDR2-800 SDRAM
Внешняя шина данных
г Частота ядра –
Частота буфера ввода/
«Эффективная» частота
 200 МГц
200 МГц
вывода – 800 МГцвнешнейшины – 1600 МГц

 DDR3-1600 SDRAM
DDR3-1600 SDRAM
Внешняя шина данных
Рис. 4.8. Схематическое представление передачи данных в микросхеме памяти: а – SDRAM-200; б– DDR-400; в– DDR2-800; г– DDR3-1600
Преимущества при переходе от DDR2 к DDR3 те же, что и при со- стоявшемся ранее переходе от DDR к DDR2: с одной стороны, это сни- жение энергопотребления компонентов в условиях равенства их пико- вой пропускной способности (DDR3-800 против DDR2-800), с другой сто- роны – возможность дальнейшего наращивания тактовой частоты и тео- ретической пропускной способности при сохранении прежнего уровня
«внутренней» частоты компонентов (DDR3-1600 против DDR2-800). Теми же являются и недостатки: дальнейший разрыв между «внутрен- ней» и «внешней» частотами шин компонентов памяти приводит к ещё большим задержкам.
Дальнейшее развитие технологии реализации памяти DDR SDRAM
– это переход к новому стандарту DDR4. По сравнению с DDR3 эта па- мять работает на более высоких частотах (DDR4 – 3200, DDR4 – 3000, DDR4 – 2800, DDR4 – 2666), благодаря чему она может обеспечить го-
раздо лучшую пропускную способность, однако при этом её латент- ность заметно выше.
Чтобы проиллюстрировать вышесказанное приведем (рис. 4.9) с помощью бенчмарков из пакета SiSoftware Sandra 21.42 практические характеристики подсистемы памяти Skylake-S, укомплектованной мо- дулями DDR4 SDRAM с различной скоростью. Для сравнения рядом приводятся результаты, полученные в аналогичной системе с процессо- ром Haswell и привычной памятью типа DDR3 SDRAM.
Как нетрудно заметить, DDR4 SDRAM действительно обеспечива- ет более высокую пропускную способность. Она продолжает масштаби- роваться синхронно с частотой, то есть модули DDR4 с более высокой задекларированной скоростью всегда смогут обеспечить лучшую поло- су пропускания по сравнению с DDR3. И это – несомненное преимуще- ство новой технологии. Однако латентность серьёзно повысилась. Как видно из диаграмм, такие же, как у DDR3-1866, задержки можно полу- чить лишь при установке в систему модулей класса DDR4-3000, кото- рые относятся к числу премиальных оверклокерских предложений. Иными словами, переход с DDR3 на DDR4 пока не несёт очевидных плюсов. В каких-то аспектах быстродействия системы нового поколе- ния от использования иной технологии памяти выиграют, но в каких-то и проиграют.
Правда, не стоит упускать из виду, что с выходом Skylake внедре- ние DDR4 в массовых системах должно заметно ускорить продвижение этой технологии. Так что недорогие и скоростные модули DDR4 SDRAM, которые будут превосходить память предшествующего стан-
дарта во всех аспектах, могут приобрести широкое распространение уже в самом ближайшем будущем.
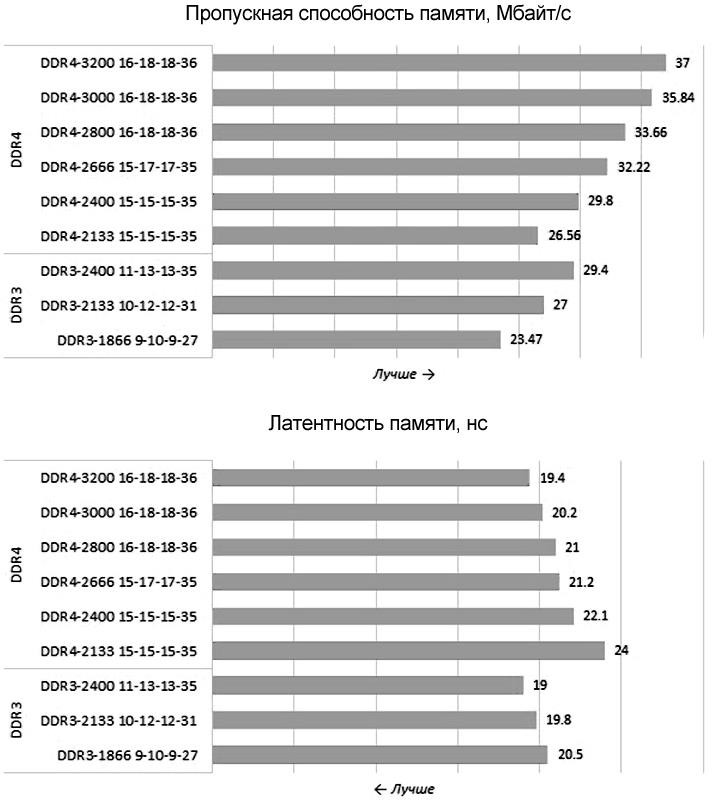
Рис. 4.9. Характеристики памяти на DDR4 в сравнении с DDR3
Прямой способ сокращения числа обращений к ОП состоит в орга- низации выборки широким словом. Этот способ основывается на свойстве локальности данных и программ. При выборке широким сло- вом за одно обращение к ОП производится одновременная запись или считывание нескольких команд или слов данных из «широкой» ячейки. Широкое слово заносится в буферную память (кэш-память) или регистр, где оно расформировывается на отдельные команды или слова данных, которые могут последовательно использоваться процессором без до- полнительных обращений к ОП.
В системах с кэш-памятью первого уровня ширина шин данных ОП часто соответствует ширине шин данных кэш-памяти, которая во мно- гих случаях имеет физическую ширину шин данных, соответствующую количеству разрядов в слове. Удвоение и учетверение ширины шин кэш-памяти и ОП удваивает или учетверяет соответственно полосу про- пускания системы памяти.
Реализация выборки широким словом вызывает необходимость мультиплексирования данных между кэш-памятью и процессором, по- скольку основной единицей обработки данных в процессоре все еще остается слово. Эти мультиплексоры оказываются на критическом пути поступления информации в процессор. Кэш-память второго уровня не- сколько смягчает эту проблему, в этом случае мультиплексоры могут располагаться между двумя уровнями кэш-памяти, т.е. вносимая ими задержка не столь критична. Другая проблема, связанная с увеличением разрядности памяти, заключается в необходимости определения мини- мального объема (инкремента) памяти для поэтапного её расширения, которое часто выполняется самими пользователями во время эксплуата- ции системы. Удвоение или учетверение ширины памяти приводит к удвоению или учетверению этого минимального инкремента. Кроме того, имеются проблемы и с организацией коррекции ошибок в систе-
мах с широкой памятью.
Другой способ повышения пропускной способности ОП связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются по- следовательные обращения к различным физическим модулям. Обра- щения к различным модулям могут перекрываться, и таким образом об-
разуется своеобразный конвейер. Эта процедура носит название рас- слоения памяти. Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Известно несколько вариантов организации расслое- ния. Наиболее часто используется способ расслоения обращений за счет расслоения адресов. Этот способ основывается на свойстве локально- сти программ и данных, предполагающем, что адрес следующей коман- ды программы на единицу больше адреса предыдущей (линейность про- грамм нарушается только командами перехода). Аналогичная последо- вательность адресов генерируется процессором при чтении и записи слов данных. Таким образом, типичным случаем распределения адресов обращений к памяти является последовательность вида а, а + 1, а + 2, … Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а + 1, а + 2, … будут размещаться в блоках 0, 1, 2, … Та- кое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида
1 m
,
где В– k-разрядный адрес модуля (младшая часть адреса) и С– n-разрядный адрес
Очередное увеличение теоретической пропускной способности компо- нентов памяти в 2 раза вновь связано со снижением их внутренней ча- стоты функционирования во столько же раз. Поэтому для достижения темпа передачи данных со скоростью 1 бит/такт по каждой линии внешней шины данных с «эффективной» частотой в 1600 МГц (как в примере, рассмотренном на рис. 4.8, г) используемые микросхемы (с частотой 200 МГц) должны передавать по 8 бит данных за каждый
«свой» такт, т.е. ширина внутренней шины данных микросхем памяти окажется уже в 8 раз больше по сравнению с шириной их внешней ши- ны. Такая схема передачи данных с рассмотренным преобразованием типа «8–1» называется схемой «8n-предвыборки» (8n-prefetch).
Частота ядра –
a 200 МГц
Частота буфера ввода/ вывода – 200 МГц
Частота внешней шины данных – 200 МГц
б Частота ядра – 200 МГцв Частота ядра – 200 МГц
Частота буфера ввода/
вывода – 200 МГц
Частота буфера ввода/ вывода – 400 МГц
«Эффективная» частота внешней шины – 400 МГц
«Эффективная» частота внешней шины – 800 МГц
DDR2-800 SDRAMВнешняя шина данных
г Частота ядра –
Частота буфера ввода/
«Эффективная» частота
200 МГцвывода – 800 МГцвнешнейшины – 1600 МГц
DDR3-1600 SDRAMВнешняя шина данных
Рис. 4.8. Схематическое представление передачи данных в микросхеме памяти: а – SDRAM-200; б– DDR-400; в– DDR2-800; г– DDR3-1600
Преимущества при переходе от DDR2 к DDR3 те же, что и при со- стоявшемся ранее переходе от DDR к DDR2: с одной стороны, это сни- жение энергопотребления компонентов в условиях равенства их пико- вой пропускной способности (DDR3-800 против DDR2-800), с другой сто- роны – возможность дальнейшего наращивания тактовой частоты и тео- ретической пропускной способности при сохранении прежнего уровня
«внутренней» частоты компонентов (DDR3-1600 против DDR2-800). Теми же являются и недостатки: дальнейший разрыв между «внутрен- ней» и «внешней» частотами шин компонентов памяти приводит к ещё большим задержкам.
Дальнейшее развитие технологии реализации памяти DDR SDRAM
– это переход к новому стандарту DDR4. По сравнению с DDR3 эта па- мять работает на более высоких частотах (DDR4 – 3200, DDR4 – 3000, DDR4 – 2800, DDR4 – 2666), благодаря чему она может обеспечить го-
раздо лучшую пропускную способность, однако при этом её латент- ность заметно выше.
Чтобы проиллюстрировать вышесказанное приведем (рис. 4.9) с помощью бенчмарков из пакета SiSoftware Sandra 21.42 практические характеристики подсистемы памяти Skylake-S, укомплектованной мо- дулями DDR4 SDRAM с различной скоростью. Для сравнения рядом приводятся результаты, полученные в аналогичной системе с процессо- ром Haswell и привычной памятью типа DDR3 SDRAM.
Как нетрудно заметить, DDR4 SDRAM действительно обеспечива- ет более высокую пропускную способность. Она продолжает масштаби- роваться синхронно с частотой, то есть модули DDR4 с более высокой задекларированной скоростью всегда смогут обеспечить лучшую поло- су пропускания по сравнению с DDR3. И это – несомненное преимуще- ство новой технологии. Однако латентность серьёзно повысилась. Как видно из диаграмм, такие же, как у DDR3-1866, задержки можно полу- чить лишь при установке в систему модулей класса DDR4-3000, кото- рые относятся к числу премиальных оверклокерских предложений. Иными словами, переход с DDR3 на DDR4 пока не несёт очевидных плюсов. В каких-то аспектах быстродействия системы нового поколе- ния от использования иной технологии памяти выиграют, но в каких-то и проиграют.
Правда, не стоит упускать из виду, что с выходом Skylake внедре- ние DDR4 в массовых системах должно заметно ускорить продвижение этой технологии. Так что недорогие и скоростные модули DDR4 SDRAM, которые будут превосходить память предшествующего стан-
дарта во всех аспектах, могут приобрести широкое распространение уже в самом ближайшем будущем.
Рис. 4.9. Характеристики памяти на DDR4 в сравнении с DDR3
Выборка широким словом
Прямой способ сокращения числа обращений к ОП состоит в орга- низации выборки широким словом. Этот способ основывается на свойстве локальности данных и программ. При выборке широким сло- вом за одно обращение к ОП производится одновременная запись или считывание нескольких команд или слов данных из «широкой» ячейки. Широкое слово заносится в буферную память (кэш-память) или регистр, где оно расформировывается на отдельные команды или слова данных, которые могут последовательно использоваться процессором без до- полнительных обращений к ОП.
В системах с кэш-памятью первого уровня ширина шин данных ОП часто соответствует ширине шин данных кэш-памяти, которая во мно- гих случаях имеет физическую ширину шин данных, соответствующую количеству разрядов в слове. Удвоение и учетверение ширины шин кэш-памяти и ОП удваивает или учетверяет соответственно полосу про- пускания системы памяти.
Реализация выборки широким словом вызывает необходимость мультиплексирования данных между кэш-памятью и процессором, по- скольку основной единицей обработки данных в процессоре все еще остается слово. Эти мультиплексоры оказываются на критическом пути поступления информации в процессор. Кэш-память второго уровня не- сколько смягчает эту проблему, в этом случае мультиплексоры могут располагаться между двумя уровнями кэш-памяти, т.е. вносимая ими задержка не столь критична. Другая проблема, связанная с увеличением разрядности памяти, заключается в необходимости определения мини- мального объема (инкремента) памяти для поэтапного её расширения, которое часто выполняется самими пользователями во время эксплуата- ции системы. Удвоение или учетверение ширины памяти приводит к удвоению или учетверению этого минимального инкремента. Кроме того, имеются проблемы и с организацией коррекции ошибок в систе-
мах с широкой памятью.
Расслоение обращений
Другой способ повышения пропускной способности ОП связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются по- следовательные обращения к различным физическим модулям. Обра- щения к различным модулям могут перекрываться, и таким образом об-
разуется своеобразный конвейер. Эта процедура носит название рас- слоения памяти. Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Известно несколько вариантов организации расслое- ния. Наиболее часто используется способ расслоения обращений за счет расслоения адресов. Этот способ основывается на свойстве локально- сти программ и данных, предполагающем, что адрес следующей коман- ды программы на единицу больше адреса предыдущей (линейность про- грамм нарушается только командами перехода). Аналогичная последо- вательность адресов генерируется процессором при чтении и записи слов данных. Таким образом, типичным случаем распределения адресов обращений к памяти является последовательность вида а, а + 1, а + 2, … Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а + 1, а + 2, … будут размещаться в блоках 0, 1, 2, … Та- кое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида
| 1 | С | n | 1 | В | k |
1 m
,
где В– k-разрядный адрес модуля (младшая часть адреса) и С– n-разрядный адрес