ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 628
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС
ОРГАНИЗАЦИЯ СИСТЕМНОГО ИНТЕРФЕЙСА И ВВОДА/ВЫВОДА ИНФОРМАЦИИ
МНОГОПРОЦЕССОРНЫЕ И МНОГОМАШИННЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
возможность пользователю самому подобрать необходимую конфигурацию. Шина ввода/вывода компьютера рассматривается как шина расширения, обес- печивающая постепенное наращивание устройств ввода/вывода. Поэто- му стандарты играют огромную роль, позволяя разработчикам компью- теров и устройств ввода/вывода работать независимо.
В подсистеме ввода/вывода ЭВМ используются три основных спо- соба организации передачи данных между памятью и ПУ: программно- управляемая передача, передача по запросу прерывания от ПУ и прямой доступ к памяти (ПДП).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора, который при этом выполняет специальную подпрограмму ввода/вывода. Операция ввода/вывода инициируется центральным процессором, т.е. текущей командой программы. Данный способ является простым в реализации, но при обработке команды ввода/вывода ЦП бесполезно тратит время, ожи- дая готовности ПУ. Это значительно снижает производительность ЭВМ.
Второй способ передачи данных по запросу прерывания от ПУ реализуется под управлением контроллера прерываний (КПР) и позво- ляет организовывать более гибкое взаимодействие между ЦП и ПУ. Предположим, что в качестве ПУ используется клавиатура, предназна- ченная для ввода в ЭВМ команд, инструкций и данных. Каждый раз, ко- гда пользователь (оператор) нажимает клавишу, ПУ выдает в КПР за- прос на прерывание, который, в свою очередь, вырабатывает для ЦП сигнал прерывания. ЦП по этому сигналу приостанавливает работу те- кущей программы и передает управление подпрограмме ввода/вывода. Подпрограмма обрабатывает запрос и по её завершении ЦП возвраща- ется к работе по текущей программе. Выполнение текущей программы
продолжается до следующего нажатия клавиши, и далее процесс повто- ряется. В этом случае преимущество от использования прерывания оче- видно (принципы работы системы прерывания программ описаны в разд. 2.6).
При программно-управляемой передаче данных ЦП на всё время этой передачи отвлекается от выполнения основной программы. Опера- ция пересылки данных логически слишком проста, чтобы эффективно загружать логически сложную быстродействующую аппаратуру про- цессора. Вместе с тем при пересылке блока данных ЦП приходится для каждой единицы передаваемых данных (байт, слово) выполнять до- вольно много инструкций, чтобы обеспечить буферизацию данных, преобразование форматов, подсчёт количества переданных данных, формирование адресов в памяти и т.п. В результате скорость передачи данных при пересылке блока данных под управлением процессора ока- зывается недостаточной. Поэтому для быстрого ввода/вывода блоков данных и разгрузки ЦП от управления операциями ввода/вывода ис- пользуют прямой доступ к памяти.
Прямой доступ к памяти (DMA – Direct Memory Access) – это та- кой способ обмена данными, который обеспечивает автономно от ЦП установление связи и передачу данных между ОП и ПУ. Прямой доступ к памяти освобождает процессор от управления операциями вво- да/вывода, позволяет осуществлять параллельно во времени выполне- ние процессором программы с обменом данными между ОП и ПУ, про- изводить этот обмен со скоростью, ограничиваемой только пропускной способностью ОП или ПУ.
Таким образом, ПДП, разгружая процессор от обслуживания ввода/ вывода, способствует возрастанию общей производительности ЭВМ. Повышение предельной скорости ввода/вывода информации делает ма- шину более приспособленной для работы в системах реального време- ни. Прямым доступом к памяти управляет
контроллер ПДП (DMA) (рис. 5.2), который выполняет следующие функции:



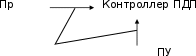 Инициирование ПДП
Инициирование ПДП
Рис. 5.2. Прямой доступ к памяти
ПДП обеспечивает высокую скорость обмена данными за счёт того, что управление обменом производится не программным путем, а аппа- ратурными средствами.
Контроллер ПДП обычно имеет более высокий приоритет в заня- тии цикла памяти по сравнению с процессором. Управление памятью переходит к контроллеру ПДП, как только завершится цикл ее работы, выполняемый для текущей команды процессора.
В современных ЭВМ используются все перечисленные способы передачи данных.
Поскольку основным производителем процессоров для настольных компьютеров является корпорация Intel, то существуют семейства чип- сетов под эти процессоры. В последнее время корпорации Intel удалось организовать практически полную монополию разработанных ею чип- сетов для собственных процессоров. Бывшим лидерам рынка чипсетов, таким как VIA Technologies, SIS, NVIDIA, пришлось переориентиро- ваться на разработку системной логики для других процессоров, напри- мер: AMD, VIA.
После перехода от микроархитектуры Net Burst к архитектуре Intel
Core семейство чипсетов от Intel претерпело существенные изменения. Место на новых материнских платах заняла серия под кодовым именем Broadwater, которая в 2006 г. состояла из четырёх моделей: Intel Q965, Q963, G965 и Р965. Эти чипсеты полностью поддерживали процессоры Core 2 Duo и работали на частоте системной шины FSB 1066 МГц.
Появившееся позже семейство чипсетов Bearlake (Intel X38, P35, G35, G33, Q35, Q33) пришло на смену предыдущего поколения микро- схем и предназначалось для высокопроизводительных систем с процес- сорами, произведёнными по 45 нм техпроцессу.
Семейство чипсетов (Intel Х58, Р55, Н55, Н57) предназначалось для системной организации компьютеров на базе процессоров с микроархи- тектурой Nehalem.
С тех пор, как контроллер памяти и контроллер графической шины PCI Express переместились внутрь процессора, дизайн наборов вистем- ной логики сущестенно упростился. Чипсеты, состоящие ранее из пары микросхем – северного и южного мостов, переродились (начиная с Intel P55) в единый чип – концентратор, отвечающий за реализацию интер- фейсов ввода-ввывода. И теперь их обновление не оказывает суще- ственного влияния на производительность и возможности платформы, а сказывается лишь на конструкции материнских плат, комплектуемых тем или иным набором дополнительных контроллеров. Поэтому ожи- дать, что выход очередного поколения наборов логики может как-то существенно повлиять на потребительские характеристики систем, явно не следует.
Чипсеты шестой (P67, H67, Q67, Z68) и седьмой (Z77, Z75, H77) серий мало отличались друг от друга и использовались для процессоров Sandy Bridge и Ivy Bridge. Они поддерживали разъем LGA 1155.
Чипсеты 8-й и 9-й серий по разводке, питанию, функциональным возможностям отличаются незначительно. Они используют для настольных систем один и тот же сокет LGA 1150.
Семейство чипсетов 8-й серии (Q87, Q85, B85, Z85, H87, H81) под-
держивают процессоры Intel Core четвертого поколения с микроархи- тектурой Haswell и Haswell Refresh. К Haswell Refresh относятся про- цессоры Haswell, у которых увеличены на 100 МГц базовая и турбо ча- стоты.
Чипсеты 9-й серии (Z97, H97) кроме процессоров четвертого поко- ления, упомянутых выше, поддерживают процессоры Intel Core пятого поколения (процессоры Broadwell с техпроцессом 14 нм).
Перечисленные чипсеты можно распределить по трем категориям. Для корпоративного сегмента используются чипсеты Q87, Q85. Для сегмента малого и среднего бизнеса – B85. На потребительском уровне
производительные (флагманские) чипсеты: Z87, Z97 PCH. Варианты чипсетов для массового рынка: H87, H97. Для компьютеров начального уровня используется чипсет H81.
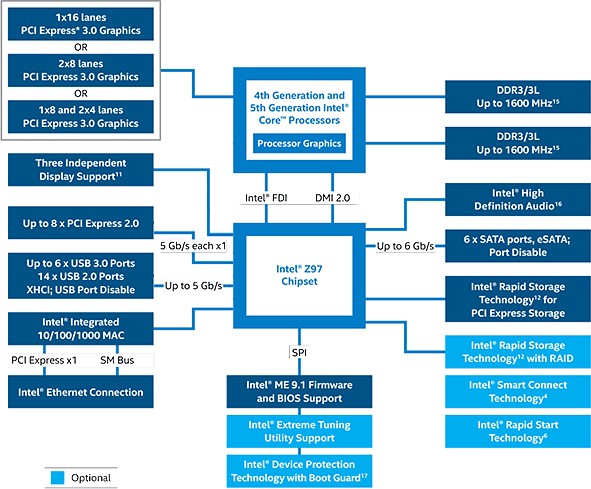 В качестве примера более подробно рассмотрим (рис.5.3) систем- ную организацию процессоров Intel 4-го и 5-го поколений на базе чип- сета Z97.
В качестве примера более подробно рассмотрим (рис.5.3) систем- ную организацию процессоров Intel 4-го и 5-го поколений на базе чип- сета Z97.
Рис. 5.3 Системная организация компьютера на базе чипсета Intel Z97
Процессоры имеют несколько портов PEG (суммарно 16 линий PCI Express 3.0 Graphics), и в зависимости от примененного на плате чипсе- та эти порты могут комбинироваться по-разному для реализации раз- личных вариантов слотов PCIe. Например, чипсет Intel Z97 (как и его аналог Intel Z87) позволяет использовать порты PEG в следующих ком- бинациях: x16, х8/х8 или x8/x4/x4. Таким образом, на платах с чипсетом Intel Z97 может быть реализован один слот PCIe x16, два слота PCIe x8 или один слот PCIe x8 и два слота PCIe x4. Чипсет Intel H97 допускает
только одну возможную комбинацию: x16 (то есть на платах с чипсетом Intel H97 может быть реализован только один слот PCIe x16).
Для связи процессора с чипсетом Intel 9-й серии используется все та же полнодуплексная шина DMI 2.0 (Direct Media Interface) с пропуск- ной способностью
-
Способы организации передачи данных
В подсистеме ввода/вывода ЭВМ используются три основных спо- соба организации передачи данных между памятью и ПУ: программно- управляемая передача, передача по запросу прерывания от ПУ и прямой доступ к памяти (ПДП).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора, который при этом выполняет специальную подпрограмму ввода/вывода. Операция ввода/вывода инициируется центральным процессором, т.е. текущей командой программы. Данный способ является простым в реализации, но при обработке команды ввода/вывода ЦП бесполезно тратит время, ожи- дая готовности ПУ. Это значительно снижает производительность ЭВМ.
Второй способ передачи данных по запросу прерывания от ПУ реализуется под управлением контроллера прерываний (КПР) и позво- ляет организовывать более гибкое взаимодействие между ЦП и ПУ. Предположим, что в качестве ПУ используется клавиатура, предназна- ченная для ввода в ЭВМ команд, инструкций и данных. Каждый раз, ко- гда пользователь (оператор) нажимает клавишу, ПУ выдает в КПР за- прос на прерывание, который, в свою очередь, вырабатывает для ЦП сигнал прерывания. ЦП по этому сигналу приостанавливает работу те- кущей программы и передает управление подпрограмме ввода/вывода. Подпрограмма обрабатывает запрос и по её завершении ЦП возвраща- ется к работе по текущей программе. Выполнение текущей программы
продолжается до следующего нажатия клавиши, и далее процесс повто- ряется. В этом случае преимущество от использования прерывания оче- видно (принципы работы системы прерывания программ описаны в разд. 2.6).
При программно-управляемой передаче данных ЦП на всё время этой передачи отвлекается от выполнения основной программы. Опера- ция пересылки данных логически слишком проста, чтобы эффективно загружать логически сложную быстродействующую аппаратуру про- цессора. Вместе с тем при пересылке блока данных ЦП приходится для каждой единицы передаваемых данных (байт, слово) выполнять до- вольно много инструкций, чтобы обеспечить буферизацию данных, преобразование форматов, подсчёт количества переданных данных, формирование адресов в памяти и т.п. В результате скорость передачи данных при пересылке блока данных под управлением процессора ока- зывается недостаточной. Поэтому для быстрого ввода/вывода блоков данных и разгрузки ЦП от управления операциями ввода/вывода ис- пользуют прямой доступ к памяти.
Прямой доступ к памяти
Прямой доступ к памяти (DMA – Direct Memory Access) – это та- кой способ обмена данными, который обеспечивает автономно от ЦП установление связи и передачу данных между ОП и ПУ. Прямой доступ к памяти освобождает процессор от управления операциями вво- да/вывода, позволяет осуществлять параллельно во времени выполне- ние процессором программы с обменом данными между ОП и ПУ, про- изводить этот обмен со скоростью, ограничиваемой только пропускной способностью ОП или ПУ.
Таким образом, ПДП, разгружая процессор от обслуживания ввода/ вывода, способствует возрастанию общей производительности ЭВМ. Повышение предельной скорости ввода/вывода информации делает ма- шину более приспособленной для работы в системах реального време- ни. Прямым доступом к памяти управляет
контроллер ПДП (DMA) (рис. 5.2), который выполняет следующие функции:
-
Управление инициируемой процессором или ПУ передачей дан- ных между ОП и ПУ. -
Задание размера блока данных, который подлежит передаче, и области памяти, используемой при передаче. -
Формирование адресов ячеек ОП, участвующих в передаче. -
Подсчёт числа единиц данных (байт, слов), передаваемых от ПУ в ОП или обратно, и определение момента завершения заданной опера- ции ввода/вывода.
Инициирование ПДПРис. 5.2. Прямой доступ к памяти
ПДП обеспечивает высокую скорость обмена данными за счёт того, что управление обменом производится не программным путем, а аппа- ратурными средствами.
Контроллер ПДП обычно имеет более высокий приоритет в заня- тии цикла памяти по сравнению с процессором. Управление памятью переходит к контроллеру ПДП, как только завершится цикл ее работы, выполняемый для текущей команды процессора.
В современных ЭВМ используются все перечисленные способы передачи данных.
-
Системная организация настольных компьютеров на базе современных чипсетов компании Intel
Поскольку основным производителем процессоров для настольных компьютеров является корпорация Intel, то существуют семейства чип- сетов под эти процессоры. В последнее время корпорации Intel удалось организовать практически полную монополию разработанных ею чип- сетов для собственных процессоров. Бывшим лидерам рынка чипсетов, таким как VIA Technologies, SIS, NVIDIA, пришлось переориентиро- ваться на разработку системной логики для других процессоров, напри- мер: AMD, VIA.
После перехода от микроархитектуры Net Burst к архитектуре Intel
Core семейство чипсетов от Intel претерпело существенные изменения. Место на новых материнских платах заняла серия под кодовым именем Broadwater, которая в 2006 г. состояла из четырёх моделей: Intel Q965, Q963, G965 и Р965. Эти чипсеты полностью поддерживали процессоры Core 2 Duo и работали на частоте системной шины FSB 1066 МГц.
Появившееся позже семейство чипсетов Bearlake (Intel X38, P35, G35, G33, Q35, Q33) пришло на смену предыдущего поколения микро- схем и предназначалось для высокопроизводительных систем с процес- сорами, произведёнными по 45 нм техпроцессу.
Семейство чипсетов (Intel Х58, Р55, Н55, Н57) предназначалось для системной организации компьютеров на базе процессоров с микроархи- тектурой Nehalem.
С тех пор, как контроллер памяти и контроллер графической шины PCI Express переместились внутрь процессора, дизайн наборов вистем- ной логики сущестенно упростился. Чипсеты, состоящие ранее из пары микросхем – северного и южного мостов, переродились (начиная с Intel P55) в единый чип – концентратор, отвечающий за реализацию интер- фейсов ввода-ввывода. И теперь их обновление не оказывает суще- ственного влияния на производительность и возможности платформы, а сказывается лишь на конструкции материнских плат, комплектуемых тем или иным набором дополнительных контроллеров. Поэтому ожи- дать, что выход очередного поколения наборов логики может как-то существенно повлиять на потребительские характеристики систем, явно не следует.
Чипсеты шестой (P67, H67, Q67, Z68) и седьмой (Z77, Z75, H77) серий мало отличались друг от друга и использовались для процессоров Sandy Bridge и Ivy Bridge. Они поддерживали разъем LGA 1155.
-
Системная организация компьютеров на базе чипсетов Intel 8-й и 9-й серий
Чипсеты 8-й и 9-й серий по разводке, питанию, функциональным возможностям отличаются незначительно. Они используют для настольных систем один и тот же сокет LGA 1150.
Семейство чипсетов 8-й серии (Q87, Q85, B85, Z85, H87, H81) под-
держивают процессоры Intel Core четвертого поколения с микроархи- тектурой Haswell и Haswell Refresh. К Haswell Refresh относятся про- цессоры Haswell, у которых увеличены на 100 МГц базовая и турбо ча- стоты.
Чипсеты 9-й серии (Z97, H97) кроме процессоров четвертого поко- ления, упомянутых выше, поддерживают процессоры Intel Core пятого поколения (процессоры Broadwell с техпроцессом 14 нм).
Перечисленные чипсеты можно распределить по трем категориям. Для корпоративного сегмента используются чипсеты Q87, Q85. Для сегмента малого и среднего бизнеса – B85. На потребительском уровне
производительные (флагманские) чипсеты: Z87, Z97 PCH. Варианты чипсетов для массового рынка: H87, H97. Для компьютеров начального уровня используется чипсет H81.
В качестве примера более подробно рассмотрим (рис.5.3) систем- ную организацию процессоров Intel 4-го и 5-го поколений на базе чип- сета Z97.Рис. 5.3 Системная организация компьютера на базе чипсета Intel Z97
Поддержка функций процессора
Процессоры имеют несколько портов PEG (суммарно 16 линий PCI Express 3.0 Graphics), и в зависимости от примененного на плате чипсе- та эти порты могут комбинироваться по-разному для реализации раз- личных вариантов слотов PCIe. Например, чипсет Intel Z97 (как и его аналог Intel Z87) позволяет использовать порты PEG в следующих ком- бинациях: x16, х8/х8 или x8/x4/x4. Таким образом, на платах с чипсетом Intel Z97 может быть реализован один слот PCIe x16, два слота PCIe x8 или один слот PCIe x8 и два слота PCIe x4. Чипсет Intel H97 допускает
только одну возможную комбинацию: x16 (то есть на платах с чипсетом Intel H97 может быть реализован только один слот PCIe x16).
Шины DMI и FDI
Для связи процессора с чипсетом Intel 9-й серии используется все та же полнодуплексная шина DMI 2.0 (Direct Media Interface) с пропуск- ной способностью