Файл: Частное образовательное учреждение высшего образования региональный открытый социальный институт.docx
Добавлен: 26.10.2023
Просмотров: 39
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
В связи с вышеизложенным актуальной является научно-техническая задача многократного повышения скорости выполнения процедур планирования размещения параллельно обрабатываемых задач по процессорам кластерной системы путем реализации названных процедур в специализированном вычислительном устройстве.
Разработанный метод ускорения поиска субоптимального варианта размещения задач по процессорам базового матричного кластерного блока основан на следующем подходе.
Пакет взаимодействующих программ (задач), запланированных к обработке в базовом блоке, аописывается графом взаимодействия задач
G=
 а - аа (1)
а - аа (1)множество вершин графа G, вершины
Матричный базовый блок кластерной системы представляется топологической моделью в виде графа H=
, где
 а - множество идентификаторова процессорных модулей базового блока, организованных в матрицу |P|n?n, где
а - множество идентификаторова процессорных модулей базового блока, организованных в матрицу |P|n?n, где Размещение пакета программ (задач), описываемых графом G (1), в параллельной системе (ПС) может быть аналитически описано отображением
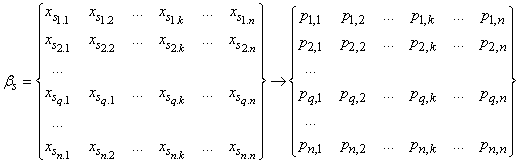 , ,где | (2) |
Здесь
Задачу планирования размещения, можно сформулировать как поиск такого отображения b*IY, что
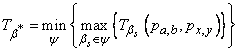 , (3)
, (3)где а
где
а
Присутствующий в (4) сомножитель С не учитывается в выражениях (3,5) и последующем анализе, так как он обратно пропорционален постоянной скорости передачи данных и поэтому не влияет на результаты минимизации по (3).
Поиск наилучшего варианта размещения b* по критерию (3) является сложной переборной задачей. Одним из путей его ускорения может быть применение целенаправленных перестановок строк и столбцов матрицы МОИ с выбором в ней aк-го места перестановки ее элемента
где
Новизна подхода состоит в том, что общее число требуемых перестановок можно дополнительно уменьшить, если отбросить явно нецелесообразные из них, разрешая очередную перестановку по следующим дополнительным критериям:
Многократное ускорение поиска возможно за счет допустимого снижения выигрыша на снижение величины коммуникационной задержки, например, не более, чем на 20-30%, по сравнению с лучшими результатами, достигаемыми при больших затратах времени на поиск. Для этого необходимо в ходе поиска контролировать степень уменьшения величины образующейся коммуникационной задержки (3) и принимать решение о целесообразности продолжения поисковых перестановок строк и столбцов матрицы МОИ. Процедура принятия решения основана на вычислении недостижимой минимальной оценки размещения Tinf (гипотетического минимума коммуникационной задержки) при допущении, что топологии графов G и H тождественны. При вычислении нижней оценки будем назначать дуги графа G с наибольшим весом
-
Переписать элементы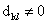 аматрицы D в вектор-строку
аматрицы D в вектор-строку 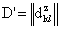 атак, что
атак, что 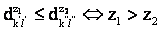 , где z1 и z2 - порядковые номера элементов в D'.
, где z1 и z2 - порядковые номера элементов в D'. -
Переписать элементы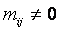 аматрицы M в вектор-строку
аматрицы M в вектор-строку 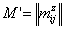 атак, что
атак, что 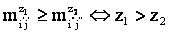 , где z1 и z2 - порядковые номера элементов в M'.
, где z1 и z2 - порядковые номера элементов в M'. -
Положить
гдеа
Для многократного ускорения поиска разработана следующая методика ускоренного выполнения процедур планирования размещения задач.
1. Составляются две матрицы: обмена информацией между задачами (МОИ) и кратчайших маршрутов (ММР) между процессорами в коммуникационной среде базового блока.
2. Вычисляются гипотетический минимум коммуникационной задержки Tinf и коэффициент эффективности исходного произвольного размещения задач
3. По порогу эффективности
4. Выполняются шаги целенаправленных перестановок столбцов и строк матрицы обмена информацией. Находится максимальное значение коммуникационной задержки (5) по предыдущему варианту перестановок задач.
5. Находится минимум (3) из максимумов задержек по всем вариантам перестановок и вычисляется коэффициент эффективности
6. Если
Величина порога эффективности
На основании разработанных в данной главе метода ускорения поиска и методики ускорения выполнения процедур планирования размещения составлен следующий алгоритм, программноЦаппаратно реализованный в двухуровневом микропроцессорном акселераторе.
-
Ввести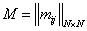 ,
, 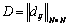 ,
, 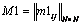 ,
, 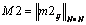 ,
, 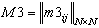 ,
, 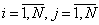 а"mij=0, "m1ij=0, "m2ij=0, "m3ij=0.
а"mij=0, "m1ij=0, "m2ij=0, "m3ij=0.
2. Переписать "mij в
3. Переписать "dij в
Положить
5. Найти
6. Вычислить
7. Принять Т0=Тн.
8. Выполнить
9. Принять k=1.
10. Выбрать
11. Найти
12. Если
13. Принять i=1.
14. Если
15. Если
16. Для
17. Вычислить
18. Вычислить
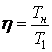 . Если
. Если 19. Принять
20. Принять Т0=Т1.
21. Принять
22. Для
23. Принять
24. Принять k=k+1 и перейти к п.26.
25.
26. Если
В третьей главе описаны программная модель разработанного алгоритма планирования размещения задач и результаты статистических исследований его эффективности.
Для моделирования и тестирования разработанного метода планирования размещения задач в кластерных системах была разработана на языке Си++ программная система, котораяа позволяет программно реализовать алгоритм размещения, строить графики изменения показателей эффективности
Целью исследования было определение величины выигрыша