-
Этапы развития систем управления
базами данных. Сравнение и особенности.
Трехуровневая архитектура систем
управления базами данных. Ее особенности
и реализация принципов логической
и физической независимости с ее
использованием в MS Access и MS SQL Server.
В
истории развития СУБД и БД можно
выделить 4 основных этапа.
Первый
этап развития
СУБД связан с организацией баз
данных на больших машинах типа IBM
360/370, ЕС-ЭВМ и мини-ЭВМ типа
PDP11 (фирмы Digital Equipment Corporation —
DEC), разных моделях HP (фирмы Hewlett
Packard).
Короче,
есть большая пребольшая центральная
ЭВМ, у которой подключена внешняя
память. В самой ЭВМ на тот момент была
только оперативка, где данные храниться
не могут. К ней подключалось некое
количество терминалов. Они выч ресурсов
не имели, с помощью них можно было
только вводить и выводить инфу, т.е.
процессоров и внешней памяти как у
центральной ЭВМ у них не было.
Особенности
этого этапа развития выражаются
в следующем:
-
Все
СУБД базируются на мощных
мультипрограммных операционных
системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому
в основном поддерживается работа
с централизованной базой данных
в режиме распределенного доступа.(то,
что на схеме)
-
Функции
управления распределением ресурсов
в основном осуществляются
операционной системой (ОС). (см схему,
то бишь все операции на центр машине)
-
Поддерживаются
языки низкого уровня манипулирования
данными, ориентированные на навигационные
методы доступа к данным.
-
Значительная
роль отводится администрированию
данных.
-
Проводятся
серьезные работы по обоснованию
и формализации реляционной модели
данных, и создается первая система
(System R), реализующая идеологию
реляционной модели данных.
-
Проводятся
теоретические работы по оптимизации
запросов и управлению распределенным
доступом к централизованной
БД, введено понятие транзакции( у
них явно были проблемы с одновременным
доступом, потому и исследовали).
-
Результаты
научных исследований открыто
обсуждаются в печати, идет мощный
поток общедоступных публикаций,
касающихся всех аспектов теории
и практики баз данных, и результаты
теоретических исследований активно
внедряются в коммерческие СУБД.
-
Появляются
первые языки высокого уровня для
работы с реляционной моделью
данных. Однако отсутствуют стандарты
для этих первых языков.
Потом
появились персональные
компьютеры. Все стали ими пользоваться.
Появилась туча самописных СУБД,
настольных СУБД, все разного формата.
Разрабатывались
все новые и новые СУБД , и главная
проблема заключалась в переносе
данных с одной на другую.
Одна база – один комп. Инета нет.
Серваков с базами нет.
Концептуальная
схемка(СУБД на компе):

Особенности
этого этапа состоят в следующем:
-
Все
СУБД были рассчитаны на создание
БД в основном с монопольным
доступом. И это понятно: компьютер
персональный, он не был подсоединен
к сети, и база данных на нем
создавалась для работы одного
пользователя. В редких случаях
предполагалась последовательная
работа нескольких пользователей,
например сначала оператора, который
вводил бухгалтерские документы,
а потом главбуха, который определял
проводки, соответствующие первичным
документам.
-
Большинство
СУБД имели развитый и удобный
пользовательский интерфейс. В основном
существовал интерактивный режим
работы с БД как в рамках
описания БД, так и в рамках
проектирования запросов. Кроме того,
большинство СУБД предлагали развитый
и удобный инструментарий для
разработки готовых приложений без
программирования. Инструментальная
среда состояла из готовых элементов
приложения в виде шаблонов экранных
форм, отчетов, этикеток (Labels), графических
конструкторов запросов, которые
достаточно просто могли быть собраны
в единый комплекс.
-
Во всех
настольных СУБД поддерживался только
внешний уровень представления
реляционной модели, т. е. только
внешний табличный вид структур
данных.
-
При
наличии высокоуровневых языков
манипулирования данными, вроде
реляционной алгебры и SQL, в настольных
СУБД поддерживались низкоуровневые
языки манипулирования данными
на уровне отдельных строк таблиц.
-
В настольных
СУБД отсутствовали средства поддержки
ссылочной и структурной целостности
базы данных. Эти функции должны были
выполнять приложения, однако скудость
средств разработки приложений иногда
не позволяла это сделать, и эти
функции должны были выполняться
пользователем, требуя от него
дополнительного контроля при вводе
и изменении информации, хранящейся
в БД.
-
Наличие
монопольного режима работы фактически
привело к вырождению функций
администрирования БД и в связи
с этим — к отсутствию
инструментальных средств
администрирования БД.
-
И, наконец,
последняя и в настоящий момент
весьма положительная особенность —
это сравнительно скромные требования
к аппаратному обеспечению со стороны
настольных СУБД. Вполне работоспособные
приложения, разработанные, например,
на Clipper, работали на PC 286.
В
принципе, их даже трудно назвать
полноценными СУБД. Яркие представители
этого семейства — очень широко
использовавшиеся до недавнего
времени СУБД Dbase (DbaseIII+, DbaseIV), FoxPro,
Clipper, Paradox (рис. 1.2).
Потом
появились локальные сети,
в которых инфа обрабатывалась между
несколькими пользователями. Встала
задача
согласованности данных, хранящихся
и обрабатывающихся в разных
местах, но логически друг с другом
связанных.
Как
следствие – появились распределенные
базы данных.
Особенности
данного этапа состоят в следующем.
-
Практически
все современные СУБД обеспечивают
поддержку полной реляционной модели,
а именно:
-
структурной
целостности — допустимыми являются
только данные, представленные в виде
отношений реляционной модели;
-
языковой
целостности, т. е. языков
манипулирования данными высокого
уровня (в основном SQL);
-
ссылочной
целостности, контроля за соблюдением
ссылочной целостности в течение
всего времени функционирования
системы, и гарантий невозможности
со стороны СУБД нарушить эти
ограничения.
-
Большинство
современных СУБД рассчитаны
на многоплатформенную архитектуру,
т. е. они могут работать
на компьютерах с разной
архитектурой и под разными
операционными системами, при этом
для пользователей доступ к данным,
управляемым СУБД на разных
платформах, практически неразличим.
-
Необходимость
поддержки многопользовательской
работы с базой данных и возможность
децентрализованного хранения данных
потребовали развития средств
администрирования БД с реализацией
общей концепции средств защиты
данных.
-
Потребность
в новых реализациях вызвала
создание серьезных теоретических
трудов по оптимизации реализаций
распределенных БД и работе
с распределенными транзакциями
и запросами с внедрением
полученных результатов в коммерческие
СУБД.
-
Для
того чтобы не потерять клиентов,
которые ранее работали на настольных
СУБД, практически все современные
СУБД имеют средства подключения
клиентских приложений, разработанные
с использованием настольных СУБД,
и средства экспорта данных
из форматов настольных СУБД второго
этапа развития.
-
Именно
к этому этапу можно отнести
разработку ряда стандартов в рамках
языков описания и манипулирования
данными начиная с SQL89, SQL92, SQL99
и технологий по обмену данными
между различными СУБД, к которым
можно отнести и протокол ODBC (Open
DataBase Connectivity), предложенный фирмой
Microsoft.
-
Именно
к этому этапу можно отнести начало
работ, связанных с концепцией
объектно-ориентированных БД (ООБД).
Представителями СУБД, относящимися
ко второму этапу, можно считать
MS Access 97 и все современные
серверы баз данных Oracle7.3,Oracle 8.4, Oracle
10, MS SQL Server 6.5, MS SQL Server 7.0, MS SQL
Server 2000, System 10, System 11, Informix, DB2, SQL
Base и другие современные серверы
баз данных, которых в настоящий
момент насчитывается несколько
десятков (рис. 1.3).
Следующий
этап
характеризуется появлением новой
технологии доступа к данным —
Интранет. Основное отличие этого
подхода от технологии «клиент-сервер»
состоит в том, что отпадает
необходимость использования
специализированного клиентского
программного обеспечения.
Нужна только программа-обозреватель(браузер),
которая шлет запросы и получает ответы
от сервера. Архитектура «клиент-сервер».
Трехуровневая
архитектура
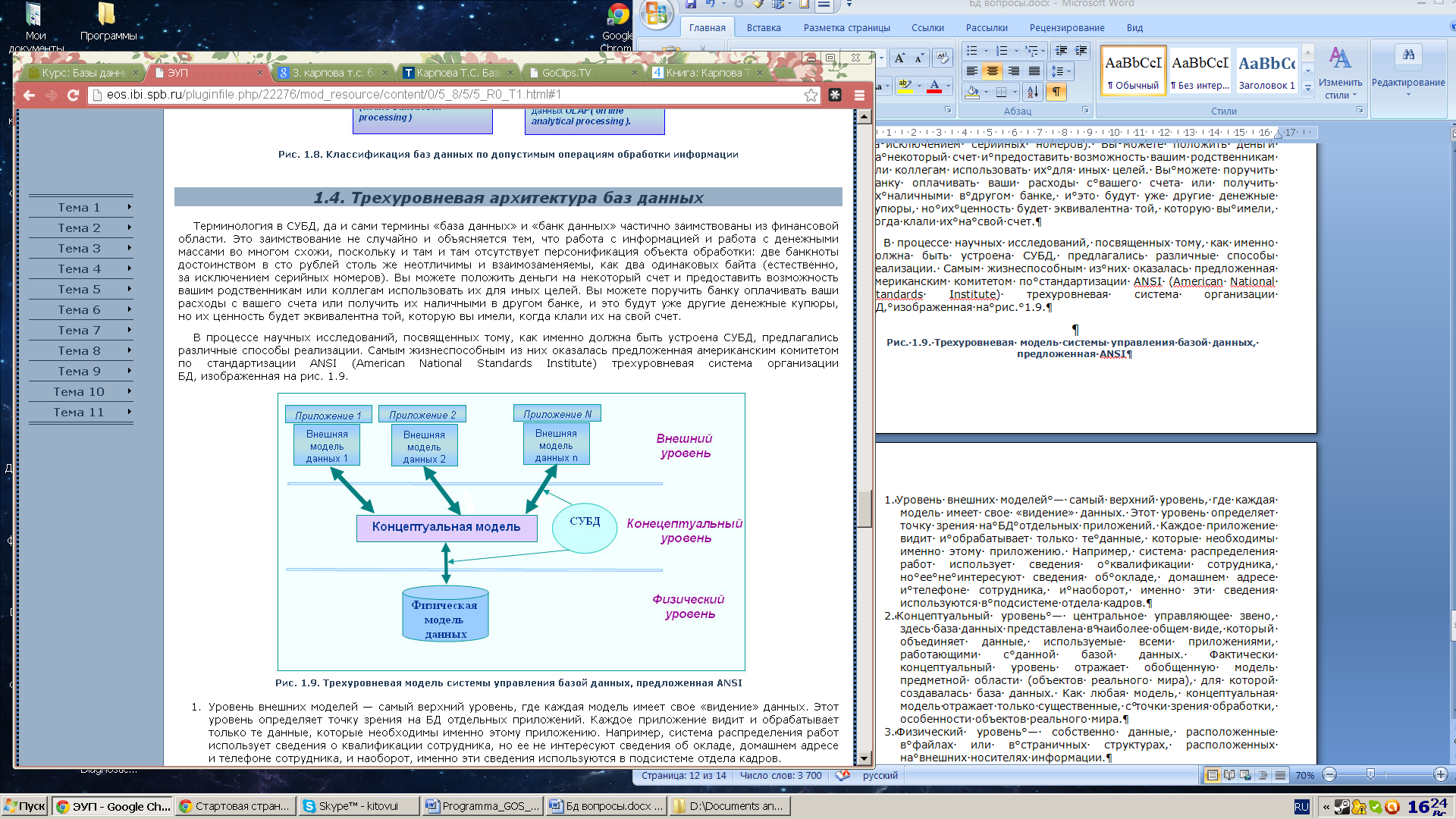
-
Уровень
внешних моделей — самый верхний
уровень, где каждая модель имеет свое
«видение» данных. Этот уровень
определяет точку зрения на БД отдельных
приложений. Каждое приложение видит
и обрабатывает только те данные,
которые необходимы именно этому
приложению. Например, система
распределения работ использует
сведения о квалификации сотрудника,
но ее не интересуют сведения
об окладе, домашнем адресе и телефоне
сотрудника, и наоборот, именно эти
сведения используются в подсистеме
отдела кадров.
-
Концептуальный
уровень — центральное управляющее
звено, здесь база данных представлена
в наиболее общем виде, который
объединяет данные, используемые
всеми приложениями, работающими
с данной базой данных. Фактически
концептуальный уровень отражает
обобщенную модель предметной области
(объектов реального мира), для которой
создавалась база данных. Как любая
модель, концептуальная модель отражает
только существенные, с точки зрения
обработки, особенности объектов
реального мира.
-
Физический
уровень — собственно данные,
расположенные в файлах или
в страничных структурах, расположенных
на внешних носителях информации.
Эта
архитектура позволяет обеспечить
логическую (между уровнями 1 и 2) и
физическую (между уровнями 2 и 3) независимость
при работе с данными. Логическая
независимость предполагает возможность
изменения одного приложения без
корректировки других приложений,
работающих с этой же базой
данных. Физическая независимость
предполагает возможность переноса
хранимой информации с одних
носителей на другие при сохранении
работоспособности всех приложений,
работающих с данной базой данных.
Это именно то, чего не хватало
при использовании файловых систем.
-
Методология SADT (IDEF0). Синтаксис IDEF0.
Правила построения IDEF0-диаграмм.
Стадии создания IDEF0-модели (РД IDEF0 -
2000)
Интерфейсная
стрелка,
интерфейсная дуга или поток (Arrow).
Интерфейсная стрелка отображает
элемент системы, который обрабатывается
функциональным блоком или оказывает
влияние на функцию, отображенную
данным функциональным блоком. С дугами
связаны надписи (или метки) на
естественном языке, описывающие
данные, которые они представляют.
ОПР.:
Взаимодействие между функциями
(блоками) в IDEF0 представляется в виде
дуги, которая отображает поток данных
или материалов, поступающий с выхода
одной функции на вход другой.
Выходы
одной функции могут быть Входами,
Управлением или Механизмами для
другой. В зависимости от того, с какой
стороной блока связан поток, его
называют соответственно “входным”,
“выходным”, “управляющим”.
-
Интерфейсная
стрелка «вход»
(Input) -
это
материалы, предметы или информация,
которые трансформируются в процессе
выполнения функции с целью получения
результата. Стрелки входа соединяются
с левой стороной блока. Некоторые
блоки могут не иметь стрелок входа,
поскольку не каждая функция преобразует
или изменяет что-либо.
-
Интерфейсная
стрелка «управление»
(Control)
определяет как, когда и в каком случае
выполняется функция, и какой результат
от нее ожидается. Каждая функция
(IDEF0-блока) должна иметь как минимум
один вход управления. Управление
часто представляется в виде правил,
норм, процедур, стандартов. Они
оказывают влияние на выполнение
функции, не изменяясь при этом сами.
Управление – это особый тип входных
данных функции. Часто даже возникает
вопрос, какого типа должна быть
стрелка: вход или управление.
-
Интерфейсная
стрелка «ресурс»
или «механизм» (Mechanism)
обозначает те ресурсы, при помощи
которых выполняется функция. В
качестве механизма выступают люди,
машины, оборудование, которые
обеспечивают все необходимое для
реализации функции. IDEF0-блок может
не содержать стрелок механизма. Это
объясняется тем, что знание механизма,
осуществляющего функцию, зачастую
не является целью моделирования
системы.
-
Интерфейсная
стрелка «выход»
(Output) –
это материалы, предметы, информация,
производимые функцией, это результат
выполнения функции. Каждый блок
обязательно имеет хотя бы одну стрелку
выхода. При моделировании
непроизводственных процессов, выходом
функции часто являются данные, которые
были обработаны или переработаны по
алгоритму , определяемому функцией.
-
Интерфейсные
стрелки ссылки
(Call Arrow)
используются для указания на другие
модели или диаграммы внутри модели,
которые помогают лучше понять модель.
Интерфейсная стрелка ссылки может
ссылаться на другую диаграмму внутри
самой модели или на специфическое
дочернее действие другой модели.
Данный вид стрелок в дипломной работе
не использовался.
Одним
из главных отличий стандарта IDEF0 от
других методологий классов DFD (Data Flow
Diagram) и WFD (Work Flow Diagram) является обязательное
наличие управляющих интерфейсных
стрелок.
Дуги
позволяют отражать взаимосвязи между
блоками. По типу этой связи выделяют
5 видов взаимодействия (Error: Reference source not found).
Примеры данных взаимодействий и их
отражения на модели показаны на схемах
Модель
в IDEF0
Модель
в IDEF0 представляет собой совокупность
иерархически упорядоченных и
взаимосвязанных диаграмм. Каждая
диаграмма располагается на отдельном
листе (Error: Reference source not found).
Модель
IDEF0 всегда начинается с представления
системы как единого целого – одного
функционального блока с интерфейсными
стрелками, простирающимися за пределы
рассматриваемой области. Такая
диаграмма с одним функциональным
блоком называется контекстной
диаграммой, и обозначается идентификатором
А-0.
Ни
одна модель не может быть создана без
конкретного объекта или цели.
Формулировка цели должна ответить
на следующие вопросы: почему был
смоделирован данный процесс; что
модель собирается показать; что с ней
могут сделать читающие. Формулировка
цели позволяет команде экспертов
придерживаться ее в течение всего
моделирования. Без формулировки цели
моделирование может зайти в тупик.
Модели
создаются для получения ответа на
ряд вопросов. Данные вопросы должны
подготавливаться заранее и будут
служить основой для создания цели
модели. Примерные вопросы могут
звучать следующим образом: каковы
основные задачи сотрудника; кто
отвечает за произведенную продукцию;
кто управляет начальной стадией
производства; какой требуется
инструмент для каждого этапа.
Точка
зрения (Viewpoint).
Особенно важно включать в процесс
разработки модели представителей
различных мнений, однако сама модель
должна базироваться на единой точке
зрения. Чаще всего разнообразные
точки зрения кратко фиксируют на
диаграмме ФЕО (FEO – For Exposition Only – только
для комментариев). Эти диаграммы
используются только в качестве
материалов для презентаций.
Точка
зрения должна формулироваться исходя
из цели построение диаграммы. При
построении модели важно придерживаться
одной точки зрения, которая должна
содержать наименование должности,
структурного подразделения или
описание должностных обязанностей
работника. Модели могут содержать
разнообразные точки зрения с целью
детальной фиксации всех действий
(функций).
В
комментариях к контекстной диаграмме
должна быть указана цель (Purpose)
построения диаграммы в виде краткого
описания и зафиксирована точка зрения
(Viewpoint).
Определение
и формализация цели разработки и
точки зрения IDEF0 – модели является
крайне важным моментом. Фактически
цель определяет соответствующие
области в исследуемой системе, на
которых необходимо обратить внимание
в первую очередь. Точка зрения
определяет основное направление
развития модели и уровень необходимой
детализации. Четкое фиксирование
точки зрения позволяет разгрузить
модель, отказавшись от детализации
и исследования отдельных элементов,
не являющихся необходимыми, исходя
из выбранной точки зрения на систему.
Диаграммы
IDEF0 второго уровня называются дочерней
(Child diagram) по отношению к первому (каждый
из функциональных блоков, принадлежащих
дочерней диаграмме соответственно
называется дочерним блоком – Child
Box). В свою очередь, функциональный
блок – предок называется родительским
блоком по отношению к дочерней
диаграмме (Parent Box), а диаграмма, к
которой он принадлежит – родительской
диаграммой (Parent Diagram).
При
декомпозиции функционального блока
все стрелки, входящие в данный блок,
или исходящие из него фиксируются на
дочерней диаграмме. Этим достигается
структурная целостность IDEF0-модели.
Каждый блок имеет свой уникальный
порядковый номер на диаграмме (цифра
в правом нижнем углу), а обозначение
под правым углом указывает на номер
дочерней для этого блока диаграммы.
Отсутствие этого обозначения говорит
о том, что декомпозиции для данного
блока не существует.
Туннели
(Tunnels).
Связывание интерфейсных стрелок
используется в моделях для определения
уровня детализации. Когда интерфейсная
стрелка не возникает на базовой
диаграмме, но не связана с другими
стрелками, туннель используется для
указания того, что интерфейсная
стрелка входит или выходит из системы.
Туннель используется, чтобы не
загромождать базовую диаграмму. В
других случаях туннель может быть
использован в интерфейсной стрелке,
ведущей к базовому действию. Это
указывает, что взаимоотношения
интерфейсной стрелки с дочерними
действиями не определены.
Глоссарий
(Glossary). Для
каждого из элементов IDEF0 (диаграмм,
функциональных блоков, интерфейсных
стрелок) существующий стандарт
подразумевает создание и поддержание
набора соответствующих определений,
ключевых слов, повествовательных
изложений и т.д., которые характеризуют
объект, отображенный данным элементом.
Этот набор называется глоссарием и
является описанием сущности данного
элемента. Он дополняет наглядный
графический язык, снабжая диаграммы
необходимой дополнительной информацией.
Принципы IDEF0
Принцип
функциональной декомпозиции.
Принцип
декомпозиции или, как его еще называют
принцип «разделяй и властвуй»
применяется при разбиении сложного
процесса на составляющие его функции.
Декомпозиция позволяет представить
модель системы в виде иерархической
структуры отдельных диаграмм, что
делает ее менее перегруженной и легко
усваиваемой.
Суть
принципа функциональной декомпозиции
очень прост (Error: Reference source not found):
-
Функциональный
блок, который представляет систему
в качестве единого модуля, детализируется
на другой диаграмме с помощью
нескольких блоков, соединенных между
собой дугами.
-
Эти
блоки представляют основные подфункции
(подмодули) единого исходного модуля.
-
Данная
декомпозиция выявляет полный набор
подмодулей, каждый из которых
представлен как блок, границы которого
определены дугами.
-
Каждый
из этих подмодулей может быть
декомпозирован подобным же образом
для более детального представления.
Принцип
ограничения сложности
При
работе с IDEF0 диаграммами существенным
является условие их разборчивости и
удобочитаемости, поэтому количество
блоков на диаграмме должно быть не
менее двух и не более шести. Такой
диапазон вызван учетом особенностей
психологии человеческого восприятия.
Практика показывает, что соблюдение
этого принципа приводит к тому, что
функциональные процессы, представленные
в виде IDEF0 модели, хорошо структурированы,
понятны и легко поддаются анализу.
Принцип
контекста (целеполагания)
Как
было указано выше любая модель должна
отвечать на вопросы о системе («М есть
модель системы S, если М может быть
использована для получения ответов
на вопросы относительно S с точностью
А»). Это означает, что не может быть
модели вообще. Любая модель – это
лишь инструмент и чтобы правильно ее
создать надо иметь однозначное
представление о цели моделирования
(Purpose), точке зрения (Viewpoint) и границах
моделирования (Scope). Принцип целеполагания
как раз и означает, что любая модель
в SADT
– должна быть определена прежде всего
по перечисленным трем позициям.
Правила построения
IDEF0 диаграмм
Выполнение
вышеперечисленных принципов требует
введения ряда ограничений, которые
должен выполнять любой автор IDEF0
модели. Как было указано ранее, эти
требования сведены в документе РД
IDEF0-2000.
Основные из этих правил приведем ниже
с необходимыми комментариями.
Правило
контекста
В
составе модели должна присутствовать
контекстная диаграмма number
prefix-0
(например, А-0), которая содержит только
один блок. Номер единственного блока
на контекстной диаграмме А-0 должен
быть 0 (Error: Reference source not found).
Это правило обеспечивает выполнение
принципа контекста.
Правило
«доминирования»
Блоки
на диаграмме должны располагаться
по диагонали - от левого верхнего угла
диаграммы до правого нижнего в порядке
присвоенных номеров (Error: Reference source not found).
Блоки на диаграмме, расположенные
вверху слева «доминируют» над блоками,
расположенными внизу справа.
«Доминирование» понимается как
влияние, которое блок оказывает на
другие блоки диаграммы.
Правило
ограничения сложности
Это
правило дополняет одноименный принцип.
Неконтекстные диаграммы должны
содержать не более шести блоков. Это
ограничение поддерживают сложность
диаграмм на уровне, доступном для
чтения, понимания и использования.
Диаграммы
с количеством блоков более шести
сложны для восприятия читателями и
вызывают у автора трудности при
внесении в нее всех необходимых
графических объектов и меток.
Однако,
несмотря на существование этого
правила в реальной практике моделирования
из него иногда допускаются исключения.
Более подробно об этих исключениях
будет рассказано ниже.
Правило
выбора управления
Часто
возникает проблема, когда автор модели
не может однозначно определить, к
какому из типов дуг отнести ту или
иную интерфейсную стрелку. Прежде
всего такая ситуация возникает, когда
речь идет об отображении на диаграмме
информационных потоков. Для преодоления
этой проблемы и существует правило
выбора управления. В соответствии с
этим правилом если одни и те же данные
служат и для управления, и для входа,
вычерчивается только стрелка
управления. Этим подчеркивается
управляющий характер данных и
уменьшается сложность диаграммы (Error: Reference source not found).
Правила
нумерации и именования диаграмм,
блоков и дуг
Правило
нумерации блоков
Каждый
блок диаграммы декомпозиции получает
номер, помещаемый в правом нижнем
углу (Error: Reference source not found);
порядок нумерации - от верхнего левого
к нижнему правому блоку (в
соответствии с доминированием блоков).
Правило
нумерации диаграмм
Каждая
диаграмма имеет свой уникальный код,
который формируется следующим образом
(Error: Reference source not found):
Правило
именования
Имена
блоков (выполняемых функций) и метки
дуг должны быть уникальными (Error: Reference source not found).
Если метки интерфейсных стрелок
совпадают, это значит, что стрелки
отображают тождественные данные.
Правила
компоновки объектов диаграмм
Правило
компоновки блоков
Следует
обеспечить максимальное расстояние
между блоками и поворотами стрелок,
а также между блоками и пересечениями
стрелок для облегчения чтения
диаграммы. Одновременно уменьшается
вероятность перепутать две разные
стрелки.
Правило
рисования стрелок
Надо
пытаться максимально увеличивать
расстояние между параллельными
стрелками (Error: Reference source not found),
что облегчает размещение меток, их
чтение и позволяет проследить пути
стрелок.
Правило
минимизации пересечений
При
соединении большого числа блоков
необходимо избегать необязательных
пересечений стрелок. Следует
минимизировать число петель и поворотов
каждой стрелки (Error: Reference source not found
Правило
связывания дуг
Дуги
связываются (сливаются), если они
представляют сходные данные и их
источник не указан на диаграмме.
Дуги
объединяются, если они имеют общий
источник или приемник, или они
представляют связанные данные. Общее
название лучше описывает суть данных.
Следует минимизировать число дуг,
касающихся каждой стороны блока,
если, конечно, природа данных не
слишком разнородна (Error: Reference source not found).
Правило
присоединения дуг к блокам
Если
возможно, дуги присоединяются к блокам
в одной и той же позиции. Тогда
соединение дуг конкретного типа с
блоками будет согласованным и чтение
диаграммы упростится (Error: Reference source not found).
Процесс
моделирования
В
одной из лучших книг по SADT-моделированию
дается следующая характеристика этой
методологии: «В значительной мере
успех методологии SADT объясняется ее
графическим языком, хотя не менее
ценным является сам процесс
моделирования. Процесс моделирования
в SADT включает сбор информации об
исследуемой области, документирование
полученной информации и представление
ее в виде модели и уточнение модели
посредством итеративного рецензирования.
Кроме того, этот процесс подсказывает
вполне определенный путь выполнения
согласованной и достоверной структурной
декомпозиции, что является ключевым
моментом в квалифицированном анализе
системы. SADT уникальна в своей способности
обеспечить как графический язык, так
и процесс создания непротиворечивой
и полезной системы описаний». Если
процесс моделирования описанный в
РД IDEF0-2000
представить в нотации IDEF0,
то получится следующее видение (Error: Reference source not found
Именно
то, что SADT
представляет собой не просто нотацию,
но, прежде всего системный подход к
анализу и синтезу сложных систем
делает SADT
полноценной методологией, которая
нашла широкое распространение не
только в сфере создания ИС, но и в
областях связанных с оптимизацией
организационно-экономических и
производственно-технических систем.
3. Выполнить ручную
настройку сетевого интерфейса рабочей
станции по заданным исходным данным
и включить ее в указанный домен.
Зайти
в свойства сетевого окружения и
посмотреть какой там ip
и т.д.
Затем
в рабочей станции в dns
прописать ip сервера.
На
рабочей станции включить компьютер
в домен. В свойства компьютера это
делается.
Зайти
в свойства компьютера на вкладку имя
компьютера. И написать ivanov.local
когда спросит пользователя и ввести
администратор 123456.
Зайти
в актив директории в пользователи и
компьютеры и проверить что среди
компьютеров появился компьютер.
И
на рабочей станции попробовать зайти
каким либо пользователем домена.
Например, указываем администратор
123456. И внизу выбираем не этот компьютер
а домен. И проверить что в DNS
есть компьютер (на сервере
администрирование- dns)
|