Добавлен: 20.10.2018
Просмотров: 1038
Скачиваний: 10
представляющих объект из E
1
, и повторяющейся группы полей, в которой
каждый экземпляр группы представляет объект типа E
2
. Число повторений
группы - переменное.
Таблица № 4. Сравнение способов организации файлов.
Организация Время выполнения
Достоинства и
недостатки
Хеширование >=3
Самый быстрый
Нет сортировки
Разреженный
Индекс
2+logn – двоичн. поиск
2+loglogn – вычисл. адреса
Быстрый
Сортировка
B – дерево
2+log
d
(m/e)
Быстрый
Сортировка
Плотный
Индекс
<=2+ время плотн. индекса
Медленный
Сортировка
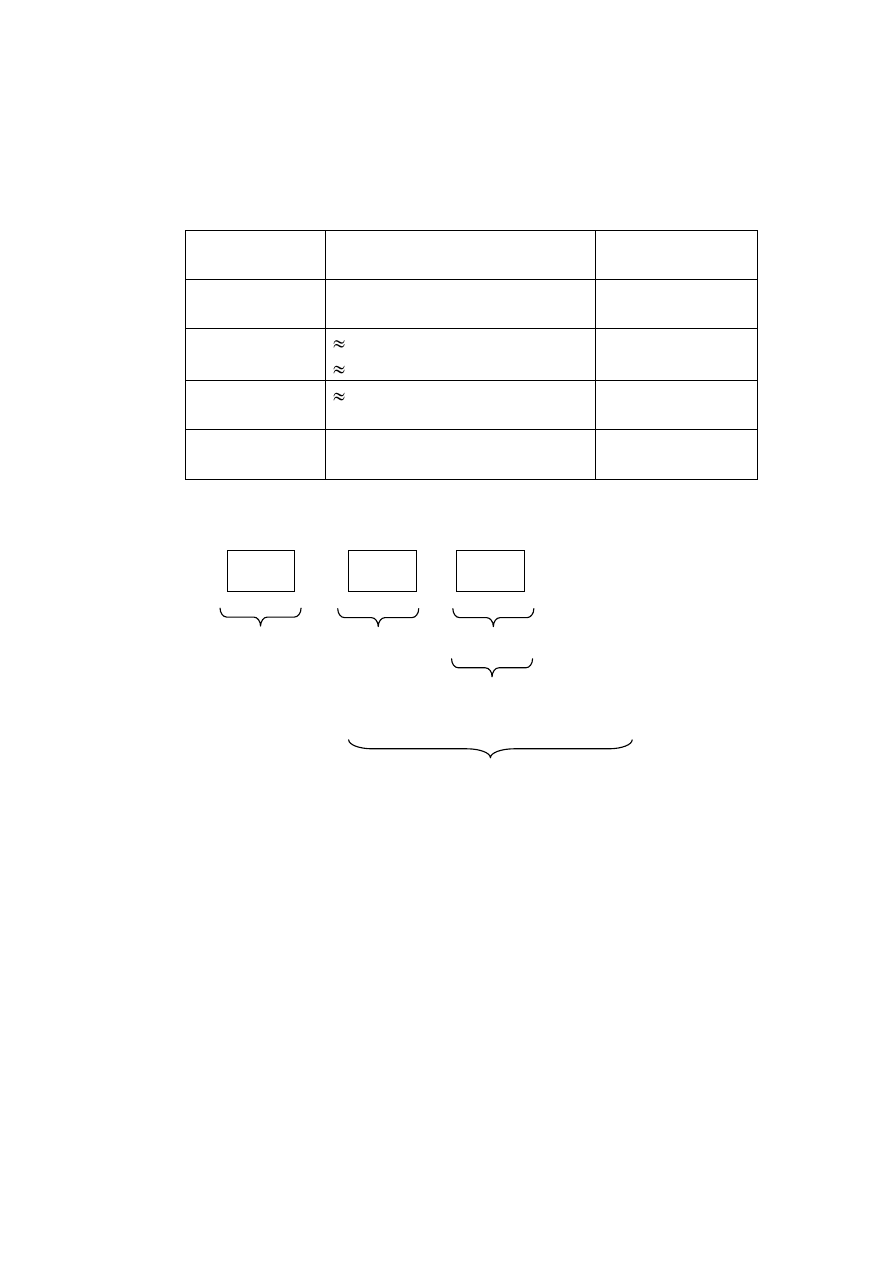
Формат записи (группы) – это список ее полей. Формат повторяющейся
группы записывается так: формат_группы*. Экземпляр записи, группы,
повторяющейся группы – совокупность значений полей заданного формата.
Обычно записи переменной длины хранятся в одной или нескольких
записях фиксированной длины. Используются три метода хранения.
A|B|C
E|F|G
E|F|G
…
e
1
e
2
e
2
экземпляр
группы
экземпляр
повторяющейся
группы
Рис. 29.4. Запись переменной длины.

Метод зарезервированного пространства. Повторяющаяся группа
представляется фиксированным числом записей постоянной длины, способной
вместить максимальное число экземпляров группы.
Метод указателей. Повторяющуюся группу можно реализовать в виде
цепочки блоков, ссылка на которую помещается в запись, содержащую
повторяющуюся группу.
Комбинированный метод.
Поиск по неключевым полям
Пусть требуется найти запись со значением v
1
в поле F
1
, v
2
в поле F
2
, …
v
k
в поле F
k
. Если S
i
- множество записей со значением v
i
в поле F
i
(i = 1..k), то
требуемое множество S=S
1
S
2
… S
k
. Существуют два метода решения этой
задачи: использование множественных вторичных индексов, использование
функций раздельного хеширования.
Вторичные индексы
Пусть записи файла содержат поле F, не обязательно являющееся ключом
и принимающее значения из множества D. Вторичный индекс по полю F есть
связь между доменом D и множеством записей файла. Файл с вторичным
индексом по полю F называется инвертированным по полю F. Вторичный
индекс имеет формат ЗНАЧЕНИЕ ЗАПИСЬ
*
, где ЗАПИСЬ – ключ записи с
требуемым значением в поле F.
В процессе поиска по неключевым полям находится пересечение
множеств S
i
, поддерживаемых вторичными индексами. В найденном
пересечении просматриваются все записи. Для ускорения поиска следует
начинать с наименьшего множества S
i
. Для этого выбираются поля с
наибольшим множеством различных значений.
Функции раздельного хеширования
Пусть каждое поле записи имеет свою функцию хеширования. Полный
номер участка в этом случае функционально зависит от хеш-значений всех
полей записи. Такая организация адресации позволяет вычислять частично
определенные номера участков (часть битов определена, часть - нет).

Пусть число участков 2
B
. Логический адрес участка в этом случае есть
последовательность B битов. Разделим биты адреса на группы – по одной
группе для каждого поля. Некоторым полям может быть назначено по 0 бит.
Если имеются поля F
1
,…F
k
и для поля F
i
назначено b
i
бит, то адрес записи
(v
1
,v
2
,…v
k
) определяется путем вычисления h
i
(v
i
) (i = 1..k). В качестве адреса
участка принимается последовательность B бит h
1
(v
1
) h
2
(v
2
)… h
k
(v
k
). Так как
все хеш-функции полей вычисляются независимо от значения других полей,
знание значения F
i
сокращает число просматриваемых участков в 2
bi
раз.
Бесфайловая физическая организация данных
Использование файловых структур для хранения данных освобождает
СУБД от функций управления внешней памятью, которые берет на себя ОС.
Это в известной мере ограничивает возможности СУБД, т.к. требования к
управлению у СУБД и ОС различаются. По этой причине некоторые СУБД
взяли на себя непосредственное управление памятью.
Рассмотрим некоторые принципы бесфайловой физической организации
данных.
Имеются две классификации объектов физической модели: физическая
(строки, страницы, чанки, экстенты, страницы Blob-объектов) и логическая
(область базы данных, область таблиц, область Blob-объектов).
Чанк – часть диска, ассоциированная одному процессу.
Экстент – непрерывная область дисковой памяти. Совокупность
экстентов представляет логическую единицу.
Экстенты состоят из четырех типов страниц: страницы данных, страницы
индексов, битовые страницы и страницы Blob–объектов (неструктурированные
данные). Основная единица операций обмена – страница.
Структура страницы имеет вид:
Слоты характеризуют размещение
строк
данных
на
странице. Каждая строка имеет однозначный идентификатор вида (номер
экстента/ номер страницы/ номер строки). Страницы индексов организованы в
Заголовок
Содержание
Слоты

виде B-деревьев. Страницы Blob-объектов хранят слабоструктурированную
информацию, содержащую тексты большого объема, графику, двоичные коды.
В страницах данных делаются ссылки на эти объекты. Битовые страницы
служат для трассировки других типов страниц.
СУБД организует специальные структуры в оперативной памяти
(разделяемая память) и журналы транзакций во внешней памяти. Разделяемая
память (рис. 29.5) служит для кэширования данных и для поддержки
параллельной обработки данных. Она содержит буферы страниц данных,
журнала транзакций, системного каталога.
Кэш буферов
данных
Управляющая
информация
Кэш буферов
журналов
Кэш
системного
каталога
Область SQL
Разделяемая память
Рис. 29.5. Разделяемая память.
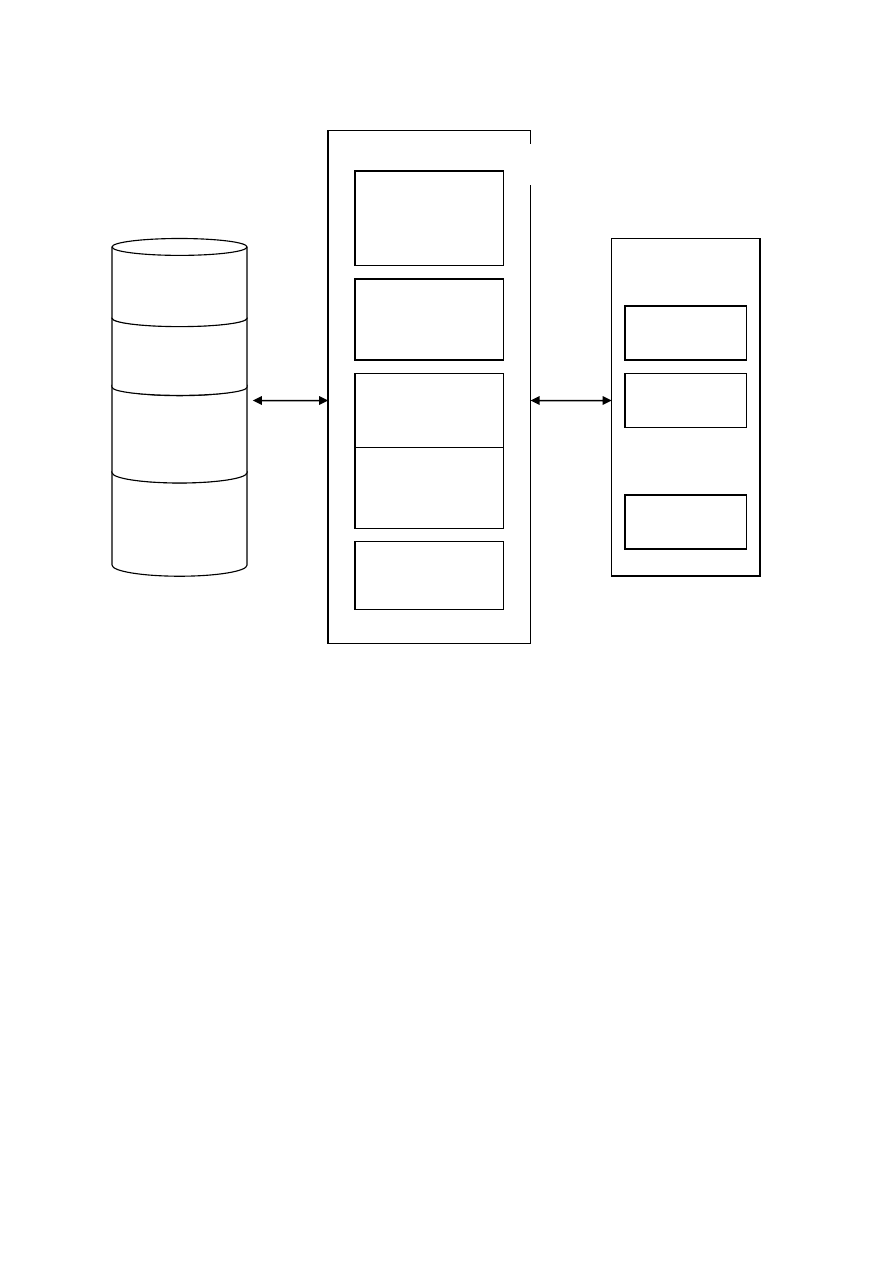
Обобщенная архитектура СУБД.
Архитектуру СУБД условно можно представить в виде рисунка 29.6.
Внешняя память содержит файлы данных, журналов, системного каталога
и др.
Ядро СУБД управляет данными во внешней памяти, буферами
оперативной памяти, транзакциями, журналами, содержит транслятор SQL.
В оперативной памяти СУБД размещаются буферы данных, журналов,
управляющая информация, кэш словаря данных, область SQL.
Системный каталог является совокупностью специальных таблиц с
ограниченным доступом. Таблицы каталога содержат информацию о
структурных элементах БД. В SQL 2 определены следующие системные
таблицы: USERS, SCHEMA, DATA_TYPE_DESCRIPTION, TABLES, VIEWS,
TABLE CONSTRAINS, TABLE_PRIVILEGES и др.
Журналы
Данные
Системный
каталог
Другие
файлы
Ядро СУБД
Модуль
управления
внешней
памятью
Модуль
управления
буферами
Модуль
управления
транзакциями
Модуль
управления
журналами
Транслятор
SQL-запросов
Оперативная
память
Разделяемая
память
Память
процесса 1
Память
процесса N
…
Рис. 29.6. Архитектура СУБД.