Файл: 14. Управление внешней памятью. Основные операции с файлами.pdf
Добавлен: 20.10.2018
Просмотров: 749
Скачиваний: 9

14. Управление внешней памятью. Основные операции с файлами
Файловая система распределяет дисковое пространство между файлами на
уровне блоков/кластеров. Короткие файлы (например, до 1 Кб) будут
целиком помещаться в блок, и поэтому для них достаточно запомнить номер
выделенного файлу блока. Проблема возникает для достаточно длинных
файлов, требующих нескольких, возможно сотен, блоков. Для решения этой
проблемы существуют разные подходы, некоторые из которых
рассматриваются ниже.
Наиболее простой подход – выделять новому файлу непрерывный набор
блоков. Тогда для однозначного определения положения файла на диске
достаточно двух чисел – номера первого блока и количества выделенных
блоков. Огромное преимущество данного метода – высокая скорость
операций чтения с минимальными затратами на поиск файла. Однако
использование данного способа в общем случае приводит к ряду серьезных
неприятностей, прежде всего – при удалении файлов. Между занятыми
блоками возникают свободные области заранее неизвестного размера, что
приводит к сильной фрагментации диска. Поэтому наиболее разумная
область использования простейшего непрерывного распределения блоков –
это носители с возможностью выполнения только операций чтения данных.
Для дисков общего назначения необходимы другие способы,
реализующие следующую общую идею: отдельные фрагменты файла могут
размещаться в ЛЮБЫХ свободных блоках, но файловая система должна
уметь связывать эти блоки в единую логическую цепочку. Такой подход
похож на организацию линейных динамических списков в основной памяти с
помощью адресных указателей. Однако прямой перенос этой техники на
дисковое пространство дает не очень хороший результат, прежде всего
потому, что для поиска данных где-то в середине или конце файла придется
последовательно просмотреть все предшествующие блоки. По этой причине
были придуманы более хитрые механизмы, основными из которых в
настоящее время являются следующие два.
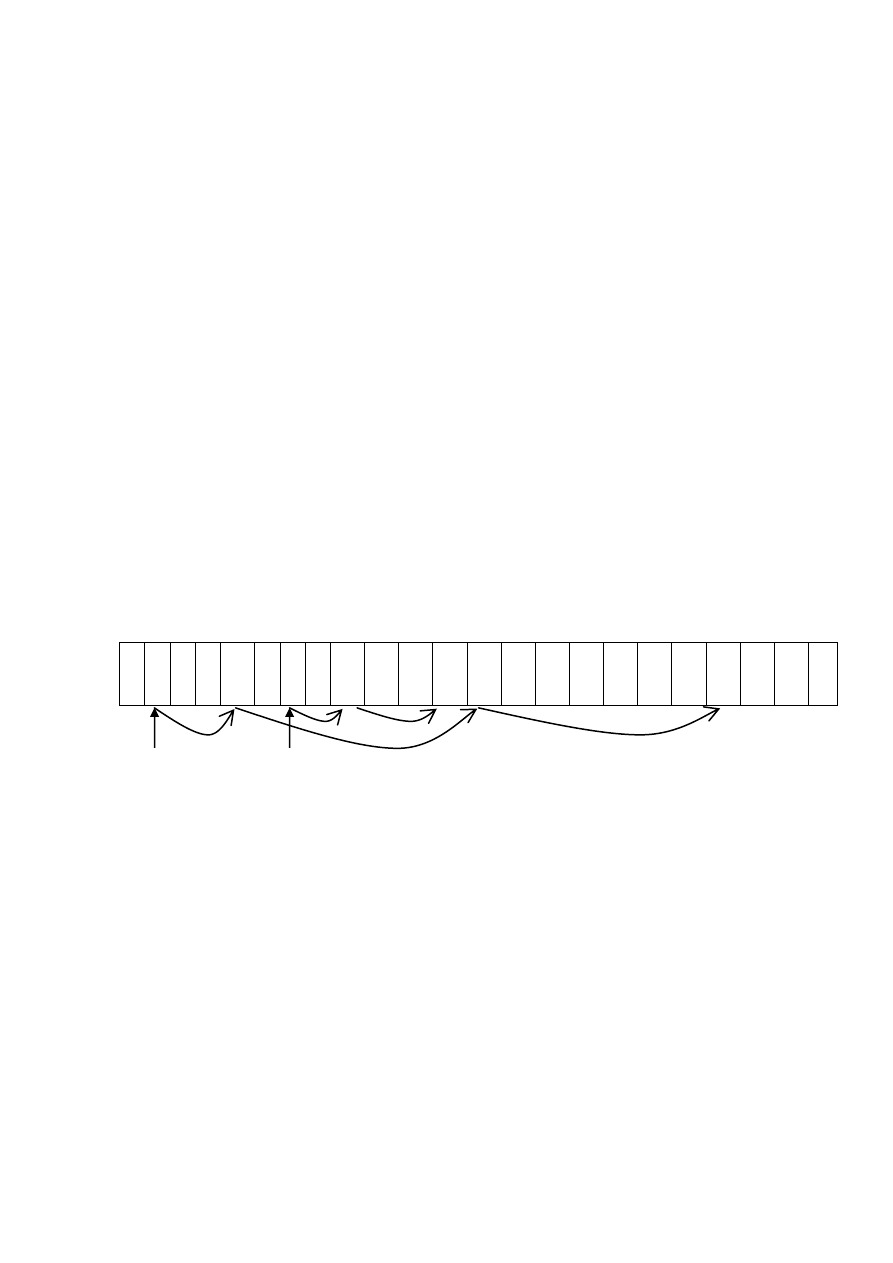
Первый способ – табличный. Файловая система создает и поддерживает
специальную таблицу распределения файлов (File Allocation Table, FAT).
Эта таблица является основой одноименных файловых систем FAT16 (MS
DOS) и FAT32 (Windows 98/ME/XP). Таблица FAT – это массив целых чисел-
номеров дисковых блоков. Число j в ячейке i говорит, что за блоком i должен
идти блок j, и тем самым для задания цепочки блоков некоторого файла
достаточно как-то определить номер первого блока (например, сохранив его
в каталоге вместе с остальными параметрами файла) и установить факт
окончания цепочки в последнем блоке (например, с помощью фиктивного
номера -1). В этом случае легко восстанавливается вся цепочка выделенных
файлу блоков без необходимости просмотра самих блоков.
Предположим, файлу А выделены блоки 2, 5, 13 и 20, а файлу В – блоки 7,
9 и 12. Тогда фрагмент таблицы FAT будет содержать следующие данные:
1 2 3 4
5
6 7 8
9
1
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
2
0
2
1
… N
5
1
3
9
1
2
-1
2
0
-1
В данном способе большое значение имеет разрядность чисел, хранимых
в FAT-таблице. Если все числа 16-разрядные (как это было в системе FAT16),
то потенциально можно адресовать 2
16
, т.е. 65536 (64 Кб) блоков. При
размере блока в 2 Кб это дает общий объем адресуемой дисковой памяти,
равный 128 Мб, что для современных дисков конечно же является мизерной
величиной. Поэтому в системе FAT16 приходилось идти на увеличение
размера блока вплоть до 32 Кб, что позволяло работать с разделами объемом
в 2 Гб. Но с другой стороны, использование таких крупных блоков
увеличивает потери памяти при хранении небольших файлов.
начало
файла А
начало
файла В

Поэтому при появлении дисков с большими объемами вместо FAT16
стала применяться система FAT32, в которой (как видно из названия)
используются 4-байтовые номера блоков. Это позволяет потенциально
работать с дисками объемом до 2 терабайт, используя при этом небольшие
блоки/кластеры размером в 4 Кб. К сожалению, обратной стороной медали
является резкое увеличение самой FAT-таблицы. Например, для диска
объемом 40 Гб при использовании блоков размером 4 Кб необходимо
поддерживать 10 млн. блоков, что при 4
−
х байтовых адресах блоков требует
для таблицы 40 Мб памяти. При этом надо учесть, что для ускорения поиска
адресов блоков FAT-таблица обычно постоянно хранится в оперативной
памяти, отбирая ее существенную часть у приложений.
Другой способ используется в файловых системах различных версий ОС
Unix и в файловой системе NTFS. Он основан на использовании так
называемых индексных узлов – специальной структуры, которая
связывается с каждым файлом. Вместо одной большой FAT-таблицы,
одновременно содержащей информацию о распределении блоков по ВСЕМ
файлам, создается и поддерживается множество небольших таблиц отдельно
для каждого файла. Все эти таблицы хранятся на диске и загружаются в
память только при обращении к файлу, т.е. при его открытии.
Индексный узел – это небольшая структура, содержащая все основные
атрибуты файла и 10-15 адресов начальных блоков файла. Это позволяет
легко адресовать небольшие (10 – 30 Кб) файлы, число которых всегда
достаточно велико. Проблемы начинаются тогда, когда файл слишком
большой, чтобы уложиться в небольшое число блоков. В этом случае один из
последних блоков в индексном узле используется не для хранения данных
файла, а для хранения еще одного, уже вторичного, набора адресов блоков
для второй части большого файла. При среднем размере блока 2 Кб и
4
−
хбайтовом адресе блока один блок может хранить адреса еще 512 блоков
файла, что дает в среднем 1 Мб дисковой памяти. Это приводит к
двухуровневой схеме определения блока.
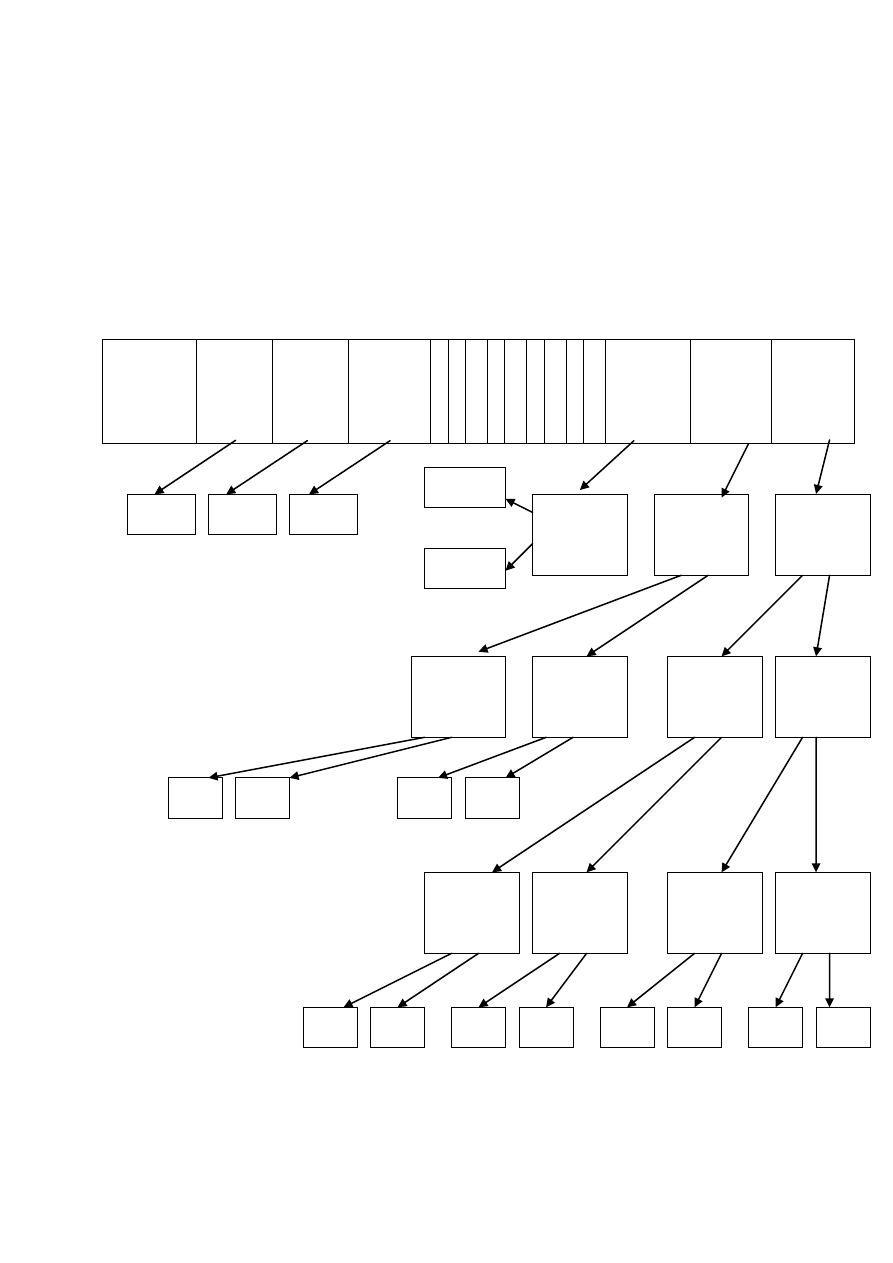
Если файл еще больше, можно включить трехуровневую схему:
индексный узел указывает на блок, содержащий адреса блоков, каждый из
которых, наконец, содержит адреса блоков с данными файла.
Ну, а для сверхбольших файлов включается четырехуровневая схема
адресации.
Атрибуты
файла
Адрес
первого
блока
данных
Адрес
второго
блока
данных
Адрес
третьего
блока
данных
Адрес
первого
дополн.
блока
адресов
Адрес
второго
дополн.
блока
адресов
Адрес
третьего
дополн.
блока
адресов
Все индексные узлы перенумерованы 3-байтовыми числами, что
потенциально дает возможность поддерживать 2
24
, т.е. более 16 млн. файлов.
Индексный узел файла
Блок
адресов
1 уровня
Блок
адресов
1 уровня
БД 1
БД 3
БД 2
Блок
адресов
1 уровня
БД 1.1
БД 1.2
Блок
адресов
2 уровня
Блок
адресов
2 уровня
Блок
адресов
2 уровня
Блок
адресов
2 уровня
Блок
адресов
3 уровня
Блок
адресов
3 уровня
Блок
адресов
3 уровня
Блок
адресов
3 уровня
БД
БД
БД
БД
БД
БД
БД
БД
БД
БД
БД
БД
При создании нового файла ему выделяется свободный индексный узел,
номер которого заносится в каталог и связывается с именем созданного
файла. При уничтожении файла номер его индексного узла становится
свободным. Отсюда следует, что файловая система должна вести учет
свободных и занятых индексных узлов. Большим достоинством данного
способа является простота прямого доступа к любому фрагменту файла без
необходимости просмотра всех предыдущих фрагментов. Недостаток –
некоторое замедление доступа к фрагментам больших файлов за счет
использования косвенной адресации.
Задача учета свободного и занятого дискового пространства аналогична
учету свободных/занятых страниц оперативной памяти и решается похожими
методами. Два основных метода – это список свободных блоков и битовый
массив блоков.
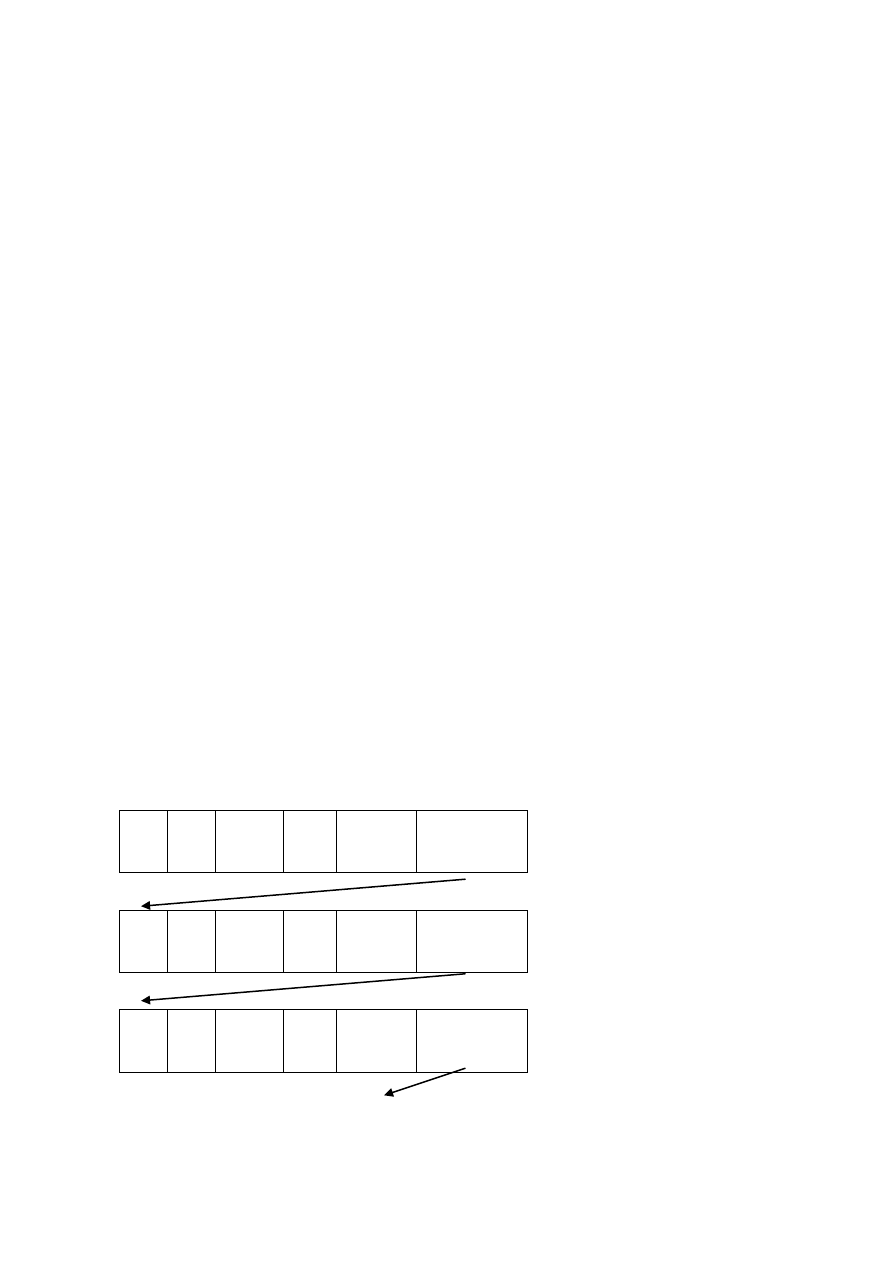
Первый способ – это просто последовательность номеров свободных
блоков. Если диск содержит 10 млн. блоков по 4 Кб, то для пустого диска
список будет занимать около 40 Мб, поэтому разумно разбить его на блоки и
хранить их в дисковой памяти. Один блок средних размеров (4 Кб) может
хранить около 1000 номеров, т.е. всего максимально для хранения данных о
свободных блоках требуется 10 тыс. блоков (0,1% объема диска).
33
15
1099
. . .
12345
номер
следующего
блока
895
111
112
. . .
654
номер
следующего
блока
655
100
101
. . .
201
номер
следующего
блока
В основной памяти достаточно иметь лишь один блок, т.е. часть списка
свободных блоков. При создании файла или его расширении новые блоки
Первый блок с фрагментом
списка свободных блоков
Второй блок с фрагментом
списка свободных блоков
Третий блок с фрагментом
списка свободных блоков