Файл: Features of the application and development prospects of Data Fabric Аннотация.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.12.2023
Просмотров: 52
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
УДК 004.6
Л.Ю. Азаренко, группа №6932, «Санкт-Петербургский государственный технологический институт (технический университет)» (СПбГТИ(ТУ)), г. Санкт-Петербург
L.U. Azarenko, group №6932, St. Petersburg State Institute of Technology (Technical University)», (SPbSTI(TU)), Saint-Petersburg
Email: gogibyrus@gmail.com
А. Г. Хайдаров, доцент кафедры бизнес-информатики, кандидат технических наук «Санкт-Петербургский государственный технологический институт (технический университет)» (СПбГТИ(ТУ)), г. Санкт-Петербург
A.G. Khaidarov, Associate professor of the department of business informatics, candidate in technical sciences St. Petersburg State Institute of Technology (Technical University)» (SPbSTI(TU)), Saint-Petersburg
Email: andreyhaydarov@gmail.com
Особенности применения и перспективы развития Data Fabric
Features of the application and development prospects of Data Fabric
Аннотация. В научной статье рассмотрена технология Data Fabric на примере Публичного акционерного общества "Сбербанк России" и публичного акционерного общества "Газпром нефть". Изучены и сопоставлены технологии Data Fabric, Data Lake и Data Mesh, а также изучено направление Hyperledger Fabric.
Annotation. The scientific article considers the Data Fabric technology on the example of the Public Joint Stock Company "Sberbank of Russia" and the Public Joint Stock Company "Gazprom Neft". Data Fabric, Data Lake and Data Mesh technologies have been studied and compared, and the Hyperledger Fabric direction has been explored.
Ключевые слова: Фабрика данных, Озеро данных, сетка данных, Hyperledger Fabric
Keywords: Data Fabric, Data Lake, Data Mesh, Hyperledger Fabric
Data Fabric (Фабрика данных) представляет собой цельную концептуальную архитектуру управления информацией с полным и гибким доступом для работы с ней. Главная особенность современных Data Fabric заключается в интенсивном использовании подходов и инструментария Big Data и AI (искусственного интеллекта), а также Machine Learning (машинного обучения) для организации оптимальных алгоритмов управления данными. Под Data Fabric обычно понимают замкнутую (автономную) экосистему, которая используется для максимально эффективного доступа к корпоративным данным, а не определенную площадку от конкретного производителя программного обеспечения (ПО).
Главным преимуществом Фабрики данных является возможность работы с данными из разрозненных источников без необходимости их предварительной очистки, трансформации, преобразования к единой модели и складирования в классические хранилища данных, то есть создание своего рода виртуальной структуры данных, которая позволяет обращаться к данным без какой-либо преднастроенной обработки.
Актуальность данной технологии подтверждается тем, что крупные IT-компании используют их для своей работы. Например, Сбербанк в 2019 году запустил в работу новую техническую платформу, разработка которой началась в 2017 году. Её структура показана на рисунке 1. Председатель правления Сбербанка Герман Греф подчеркнул важность этой платформы для бизнеса Сбербанка и то, что она является ключевым элементом превращения банка в технологическую компанию, так как позволяет гораздо быстрее выводить на рынок новые сервисы.
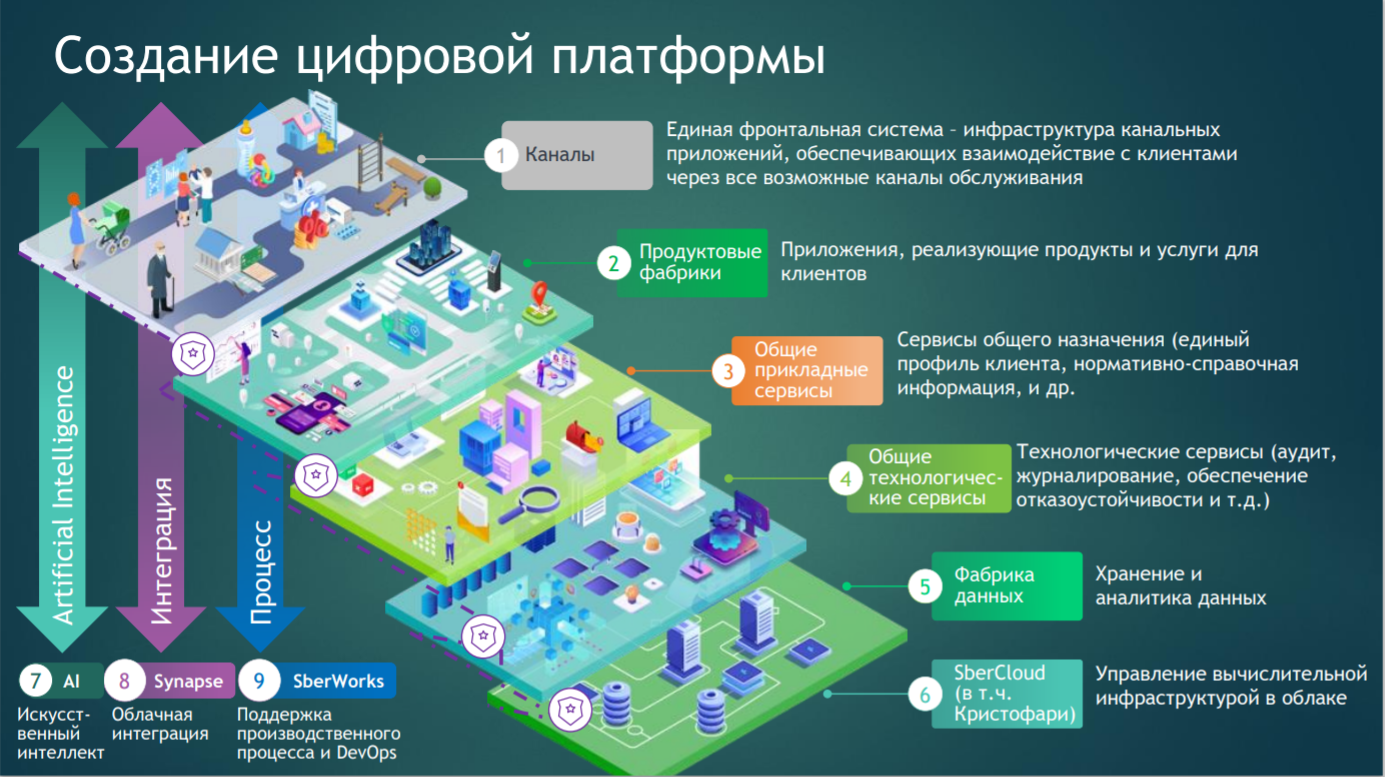
Рисунок 1 – Структура цифровой платформы
Ядром технологической платформы стало программное обеспечение GridGain In-memory Computing Platform компании GridGain, которая выиграла тендер у таких крупных компаний, как Oracle и IBM. Важной составляющей новой экосистемы является Фабрика данных (Data Fabric). Для её реализации был выбран продукт той же компании - GridGain In-Memory Data Fabric. Позже в статье мы рассмотрим его подробнее. «Без такого рода платформы невозможно построить экосистему. И в случае Сбербанка, я думаю, у нас хорошая, продвинутая платформа. Мы – единственная компания в стране, у кого таковая есть», - заявил Герман Греф. Глава Сбербанка, правда, добавил, что тут можно было бы говорить и о «Яндексе», но, по его мнению, у платформы «Яндекса» намного меньше элементов, чем у Сбербанка: «их платформа специфическая и локальная, она не такая всеобъемлющая и универсальная». Также технологии Фабрики данных использует «Газпром нефть». Они совместно с Yandex Data Factory начали сотрудничество по применению технологии машинного обучения и искусственного интеллекта в бурении, а также оптимизации производственных процессов. Yandex Data Factory — международное B2B подразделение компании, которое оказывает услуги по анализу больших данных. Фабрика адаптирует свои технологии для компаний из разных областей — от добычи полезных ископаемых до пищепрома. Константин Кравченко, начальник департамента информационных технологий, автоматизации и телекоммуникаций «Газпром нефти» отметил: «Газпром нефть» сегодня — один из лидеров в области ИТ-инноваций на российском рынке. И дальнейшее движение в этом направлении мы видим в кооперации всех сторон, заинтересованных в создании и внедрении прорывных решений для нефтегазовой индустрии. Поэтому мы очень рады, что компания Yandex Data Factory, специализирующаяся на анализе больших данных и применении технологий машинного обучения в промышленности, поддержала нас в стремлении консолидировать усилия разработчиков и потребителей инновационных продуктов в обмене знаниями и опытом в тех направлениях, которые являются важной частью формирования стратегии цифровой трансформации бизнеса нефтяных компаний.
Существуют и другие технологии хранения и обработки данных. Чтобы выбрать подходящую для решения поставленных задач, проведём их сравнительный анализ.
Сравнение технологий Data Fabric, Data Lake и Data Mesh
Проговорим ещё раз основные концепции технологии Data Fabric: децентрализованная, использование технологий Big Data, искусственного интеллекта, машинного обучения, микро-сервисной архитектуры, а также семантических слоёв. Разберём основные отличия других технологий: Data Lake (Озеро данных) является централизованной системой, а Data Mesh (Сетка данных) отличается осуществлением доступа к API. API (программный интерфейс приложения) — это набор способов и правил, по которым различные программы общаются между собой и обмениваются данными. Data Fabric стремится создать единый виртуальный уровень управления поверх распределенных данных, а Data Mesh поддерживает управление данными распределёнными группами так, как они считают нужным, хотя и с некоторыми общими положениями об управлении.
| | Преимущества | Недостатки |
| Data Fabric |
|
|
| Data Lake |
|
|
| Data Mesh |
|
|
Рассмотрим структуры архитектуры обсуждаемых технологий на рисунках 2,3,4.
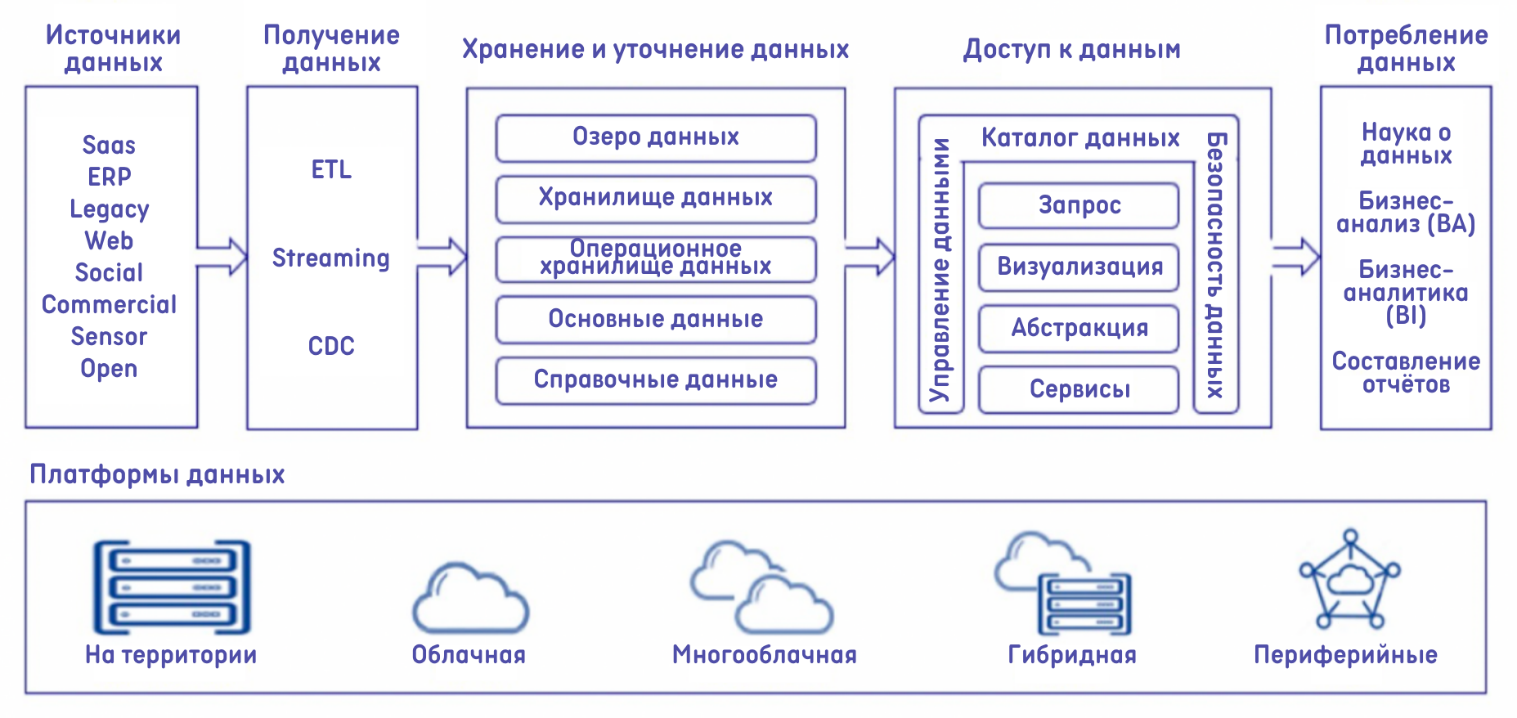
Рисунок 2 - Структура архитектуры Data Fabric
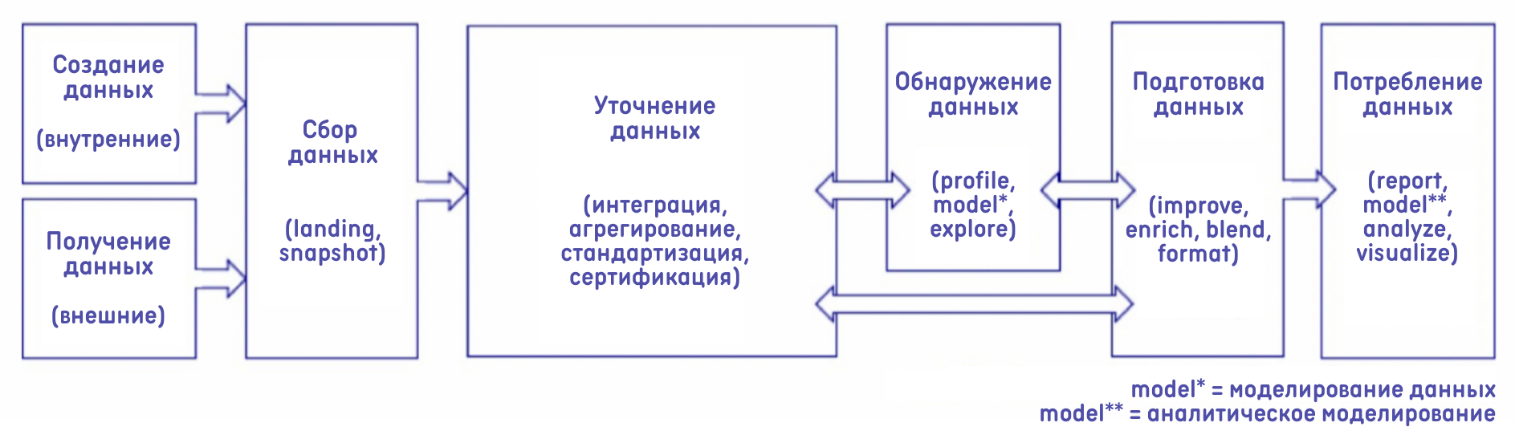
Рисунок 3 - Структура архитектуры Data Lake
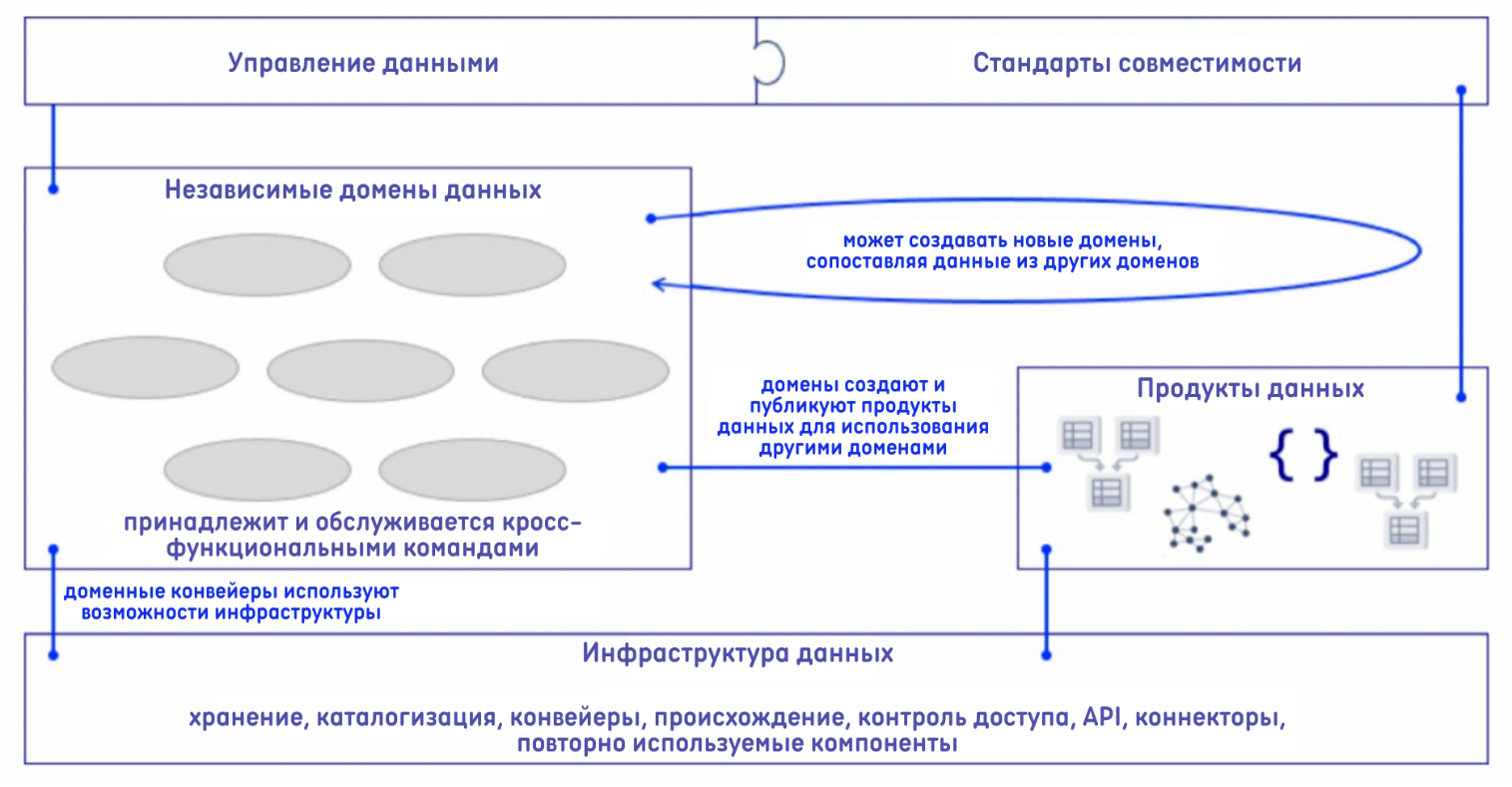
Рисунок 4 - Структура архитектуры Data Mesh
Подводя итоги сравнения, можно сделать вывод, что если вас интересует оперативная обработка данных в режиме реального времени, то стоит сделать выбор в пользу Data Fabric. Однако эти технологии не являются взаимоисключающими, на самом деле Фабрика данных может готовить надёжные данные для Озера данных, в то время как Озеро данных может предоставлять оперативную информацию
Обзор инструментов Data Fabric
GridGain In-Memory Data Fabric
GridGain System представила продукт GridGain In-Memory Data Fabric на облачной платформе Microsoft Azure. Функционал системы позволит финансовым компаниям и банкам использовать преимущества интегрированных облачных служб Microsoft чтобы развернуть распределенное, массово-параллельное решение GridGain для переноса вычислений в оперативную память компьютера.
Программное обеспечение GridGain In-Memory Data Fabric на основе Apache Ignite обеспечивает масштабирование приложений с высоким объемом обработки данных и ускорение транзакций в 1 тыс. раз без замены существующих баз данных, по сравнению с обработкой на диске.
Yandex Data Factory
В декабре 2014 года «Яндекс» объявил об открытии направления по работе с так называемыми большими данными (Big Data) — Yandex Data Factory. Его услуги рассчитаны на компании, которые имеют дело с большими массивами информации: например, показаниями датчиков, аудио- и видеозаписями, сведениями о заказах и т. д. Газпром Нефть, Сбербанк, Магнитогорский металлургический комбинат (ММК) являются клиентами Yandex Data Factory.
Oracle Coherence Data Fabric
В 2002 году компания Oracle изобрела концепцию сетки данных с внедрённой службой управления разделёнными данными. С того момента сочетание виртуализации данных, прозрачной и распределённой интеграции EIS, доступности запросов и единообразной доступности Forrester Research именовала Information Fabric
Azure Data Fabric
Azure Data Fabric – полностью управляемая бессерверная служба интеграции данных. Она позволяет интегрировать источники данных, контролируя процесс, с помощью более 90 встроенных соединителей, которые не требуют обслуживания и дополнительных расходов, легко создавать процессы ETL и ELT без написания кода в интуитивно понятной среде либо с использованием собственного кода. Затем данные передаются в Azure Synapse Analytics для проведения бизнес-аналитики. Компании Adobe и Concentra являются клиентами Azure Data Fabric.
Hyperledger Fabric
Hyperledger Fabric — это готовая для промышленного использования платформа с технологией распределенного реестра (distributed ledger technology - DLT), permissioned-сетями и открытым исходным кодом, спроектированная для промышленных ситуаций, которая обладает ключевыми возможностями, отличающими ее от остальных блокчейн- и DLT-платформ.
Fabric имеет крайне модульную и конфигурабельную архитектуру, предоставляя пространство для инноваций и оптимизаций для большого набора юзкейсов, в том числе для банкинга, финансов, страхования, здравоохранения, HR, логистики и даже цифровой доставки музыки.
Hyperledger Fabric Blockchain: безопасное и эффективное решение для электронных медицинских записей
Разберём применение данной технологии на примере системы здравоохранения. Системы электронных медицинских записей (EHR) используются в качестве эффективного и действенного метода обмена медицинскими записями пациентов между различными больницами и другими ключевыми заинтересованными сторонами отрасли здравоохранения для улучшения диагностики и лечения пациентов во всем мире. Однако существующие одноранговые системы в основном не могут обеспечить надлежащую безопасность, контроль доступа и решение проблем конфиденциальности и секретности, а также проблем, связанных с существующей больничной инфраструктурой. Индустрия здравоохранения стала серьезной мишенью атак, связанных с киберпреступностью, когда информация о пациентах, такая как имена, номера социального страхования и адреса, крадется и изменяется, что приводит к нарушению целостности данных и проблемам, связанным с конфиденциальностью, в существующих системах EHR.
В последнее время распространена кража EHR из-за слабых мер безопасности, систем и применения политики, поскольку записи хранятся в стандартных базах данных, контролируемых и поддерживаемых поставщиками услуг. Система управления EHR с поддержкой блокчейна обеспечивает прозрачность, совместимость, безопасность и создает доверие среди заинтересованных сторон в области здравоохранения, заменяя сторонних поставщиков услуг. Это позволяет нам отслеживать все действия и события, связанные с пациентом, путем предоставления отдельных сведений о транзакциях, связанных с пациентом (например, история болезни, анализы, диагностика, лекарства и послемедицинская помощь) и сохраняет их в неизменяемый и общий реестр.