ВУЗ: Томский государственный университет систем управления и радиоэлектроники
Категория: Учебное пособие
Дисциплина: Проектирование информационных систем
Добавлен: 21.10.2018
Просмотров: 10761
Скачиваний: 8

61
declare
1 X,
2 Y FIXED BINARY,
2 Z BIT(12);
Объявляется
структура
с
именем
Х,
состоящая
из
двоич-
ной
переменной
с
фиксированной
точкой
с
именем
X.Y
и
стро-
ки
длиной
12
бит
с
именем
X.Z.
Структуры
могут
использоваться
для
создания
перемен-
ных
нового
типа.
4.3.1.3 Списки
Списком
называют
упорядоченный
набор
переменных
од-
ного
типа.
Список
отличается
от
массива
тем,
что
его
размер
обычно
является
переменной
величиной,
т.е.
элементы
могут
добавляться
в
список
и
изыматься
из
него.
Список
может
быть
объявлен
как:
declare
1 LIST(N),
2 DATA_ENTRIES TYPE (
некоторый тип данных),
SIZE; /*
текущий размер списка */
Элементами
списка
являются
DATA_ENTRIES(1)
,
DATA_ENTRIES(2)
,...
, DATA_ENTRIES(SIZE).
Если
список
может
расти
неограниченно,
то
такой
способ
описания
не
годится,
поскольку
SIZE
может
стать
больше,
чем
N
.
Другой
способ
состоит
в
реализации
совокупности
базиро-
ванных
переменных.
declare
1 LIST BASED,
2 DATA_ENTRIES TYPE (
некоторый тип данных);
2 FPTR POINTER /*
указатель следующей записи
в списке */
LIST_HEAD POINTER; /*
указатель первого
элемента в списке */
В
первом
случае
элементами
списка
являются
LIST.DATA_ENTRIES(1),
LIST.DATA_ENTRIES(2),
LIST.DATA_ENTRIES(3),
...
62
LIST.DATA_ENTRIES(SIZE),
а
во
втором
LIST_HEAD
→ DATA_ENTRIES
(LIST_HEAD
→ FPTR) → DATA_ENTRIES
((LIST_HEAD
→ FPTR) → FPTR) → DATA_ENTRIES
...
Для
работы
со
списками
обычно
используются
следую-
щие
операторы
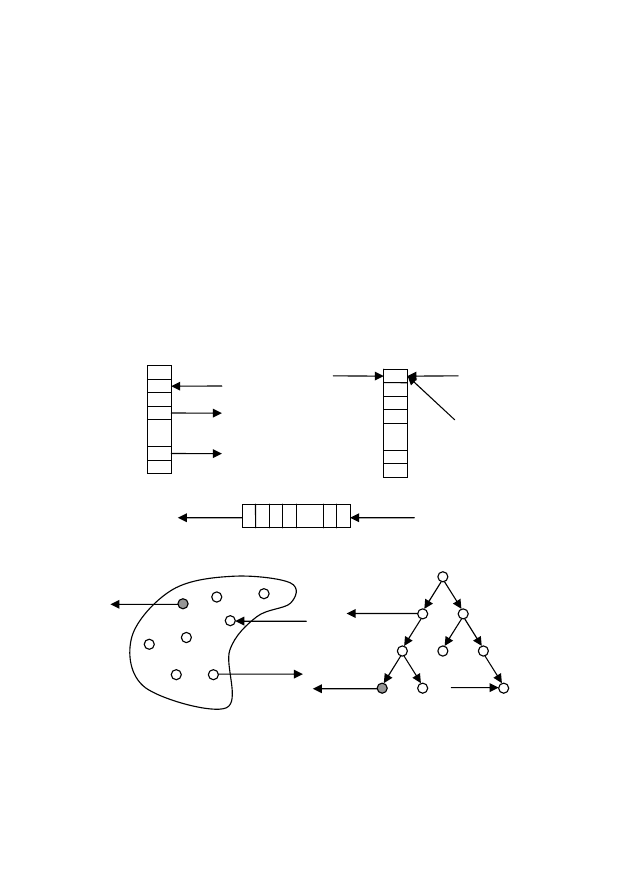
(рис.
4.9, а):
1)
ADD
—
поместить
новый
элемент
в
список;
2)
DELETE
—
удалить
элемент
из
списка;
3)
SEARCH
—
проверить
наличие
элемента
в
списке.
Рис.
4.9
—
Агрегативные
структуры
и
соответствующие
им
операторы
а)
Список
…
add
search
delete
в)
Стек
…
pus
empty
pop
…
б)
Очередь
delete insert
г)
Множество
delete
insert
member
д)
Дерево
delete
add
search

63
4.3.1.4 Очереди
Очередь
—
это
упорядоченный
список,
в
один
конец
ко-
торого
элементы
добавляются,
а
из
другого
изымаются
(рис.
4.9, б).
Очередь
называют
списком
FIFO
—
Fist
In,
Fist
Out
(поступивший
первым
обслуживается
первым).
Очередь
может
быть
организована
любым
из
рассмотренных
выше
способов,
однако
второй
способ
(использование
указателей)
более
эффек-
тивен.
Для
обслуживания
очереди
необходимы
две
операции:
1)
INSERT
—
добавить
элемент
в
очередь;
2)
DELETE
—
удалить
элемент
из
очереди.
4.3.1.5 Стеки
Стек
—
это
упорядоченный
список,
в
один
конец
которо-
го
элементы
добавляются
и
изымаются
из
этого
же
конца.
Стек
называют
списком
LIFO
—
Last
In,
Fist
Out
(поступивший
по-
следним
обслуживается
первым).
Аналогично
очереди,
стек
может
быть
организован
любым
из
рассмотренных
выше
спосо-
бов,
однако
использование
массивов
более
эффективно.
Для
рабо-
ты
со
стеком
обычно
используются
три
операции
(рис.
4.9, в).
1)
PUSH
—
поместить
элемент
в
стек;
2)
POP
—
извлечь
элемент
из
стека;
3)
EMPTY
—
функция,
принимающая
значение
ИСТИННО,
если
стек
не
заполнен.
4.3.1.6 Множества
Множества
—
это
совокупность
переменных
одного
ти-
па.
Множество
аналогично
списку,
за
исключением
того,
что
порядок
расположения
элементов
не
имеет
значения.
Множест-
ва
обычно
организуются
как
списки
с
помощью
любого
из
двух
способов.
Множества
обрабатываются
с
использованием
следую-
щих
операторов
(рис.
4.9, г):
1)
INSERT
—
добавить
новый
элемент
во
множество;
2)
DELETE
—
удалить
элемент
из
множества;

64
3)
MEMBER
—
функция,
которая
принимает
значение
ИСТИННО,
если
данная
переменная
находится
во
множестве.
4.3.1.7 Графы
Направленный
граф
—
это
структура,
состоящая
из
узлов
и
дуг,
причем
каждая
дуга
направлена
от
одного
узла
к
другому.
Графы
обычно
организовываются
с
помощью
базированных
переменных,
где
дуги
являются
переменными
типа
указатель.
Если
из
каждого
узла
выходит
несколько
дуг,
то
граф
можно
описать
следующим
образом:
declare
1 GRAPH BASED,
2 DATA_ENTPIES TYPE (
некоторый тип данных),
2 EDGES(N) POINTER;
Для
ненаправленных
графов
дугам
соответствуют
два
на-
правления
—
вперед
и
назад:
declare
1 GRAPH BASED,
2 DATA_ENTPIES TYPE (
некоторый тип данных),
2 FORWARD_EDGES(N) POINTER,
2 BACKWARD_EDGES(N) POINTER;
Операторы
для
работы
с
графами
представлены
на
рис.
4.9, д.
4.3.1.8 Деревья
Дерево
—
это
направленный
граф,
обладающий
следую-
щими
свойствами:
1)
только
один
узел
не
имеет
дуг,
входящих
в
него
(кор-
невой
узел);
2)
в
каждый
узел
входит
не
более
одной
дуги;
3)
в
каждый
узел
можно
попасть
из
корневого
узла
за
не-
сколько
шагов.

65
4.3.2 Абстрактные конструкции
В
современных
языках
программирования
основное
вни-
мание
уделяется
структурам
данных.
Управляющие
операторы
остались
почти
такими
же,
какими
они
были
в
первых
версиях
языка
ALGOL.
Кроме
использования
оператора
case
и
замены
оператора
goto
,
обработка
операторов
if
,
for
и
процедур
вы-
зова
претерпела
незначительные
изменения.
Однако
структуры
данных
за
это
время
изменились
в
зна-
чительной
степени.
Ранее
назначение
данных
состояло
в
пред-
ставлении
чисел
в
системе
исчисления,
ориентированной
на
ЭВМ.
Поэтому
в
первых
языках
программирования
использова-
лись
целочисленные
и
действительные
типы
данных,
к
которым
применялась
арифметика
с
фиксированной
и
плавающей
точ-
кой.
В
более
развитых
языках,
кроме
числовых
данных,
вклю-
чались
данные,
состоящие
из
строк
символов.
Кроме
того,
под
одним
именем
группировались
иерархически
составленные
структуры,
состоящие
из
различных
типов
данных.
Программи-
сту
представлялась
возможность
составлять
структуры
данных
произвольной
сложности.
Поскольку
структуры
данных
становятся
все
более
слож-
ными,
это
сильно
затрудняет
процесс
тестирования
и
сопрово-
ждение
тех
систем,
в
которых
используются
такие
данные.
Не-
большие
изменения
одной
структуры
данных
могут
вызвать
разлад
в
работе
всей
системы
и
превратить
процесс
сопровож-
дения
в
сложную
и
дорогостоящую
задачу.
Кроме
того,
агрегативные
структуры
становятся
все
более
машинно-
ориентированными.
Поэтому
программисту
приходится
мыс-
лить
категориями
(целочисленные,
действительные,
строки),
а
не
рассматриваемой
прикладной
задачей.
Для
того
чтобы
избежать
таких
затруднений,
в
настоящее
время
при
проектировании
больших
программных
систем
ис-
пользуется
принцип
информационной
локализованности.
Этот
принцип
заключается
в
том,
что
вся
информация
о
структуре
данных
сосредотачивается
в
одном
модуле.
Доступ
к
данным
осуществляется
из
этого
модуля.
Таким
образом,
внесение
из-
менения
в
структуру
данных
не
сопряжено
с
особыми
затруд-