Добавлен: 21.10.2018
Просмотров: 1613
Скачиваний: 11
Цель курсового проектирования – применение на практике знаний, полученных в процессе изучения курса "Базы данных", и получение практических навыков создания автоматизированных информационных систем (АИС), основанных на базах данных.
Проектирование базы данных (БД) – одна из наиболее сложных и ответственных задач, связанных с созданием информационной системы (ИС). В результате её решения должны быть определены содержание БД, эффективный для всех её будущих пользователей способ организации данных и инструментальные средства управления данными.
Основная цель процесса проектирования БД состоит в получении такого проекта, который удовлетворяет следующим требованиям:
-
Корректность схемы БД, т.е. база данных должна быть как можно более полным и адекватным образом моделируемой предметной области (ПрО), где каждому объекту предметной области соответствуют данные в памяти ЭВМ, а каждому процессу – адекватные процедуры обработки данных.
-
Обеспечение ограничений (на объёмы внешней и оперативной памяти и другие ресурсы вычислительной системы).
-
Эффективность функционирования (соблюдение ограничений на время реакции системы на запрос и обновление данных).
-
Защита данных (от аппаратных и программных сбоев и несанкционированного доступа).
-
Простота и удобство эксплуатации.
-
Гибкость, т.е. возможность развития и адаптации к изменениям предметной области и/или требований пользователей.
Удовлетворение требований 1–4 обязательно для принятия проекта.
1.2. Этапы проектирования базы данных
Процесс проектирования включает в себя следующие этапы:
-
Инфологическое проектирование.
-
Обоснование выбора системы управления базой данных (СУБД)
-
Даталогическое проектирование БД.
-
Физическое проектирование БД.
Инфологический подход не предоставляет формальных способов моделирования реальности, но он закладывает основы методологии проектирования баз данных.
1.2.1. Инфологическое проектирование
Основными задачами инфологического проектирования являются определение предметной области системы и формирование взгляда на ПрО с позиций сообщества будущих пользователей БД, т.е. инфологической модели ПрО.
Инфологическая модель ПрО представляет собой описание структуры и динамики ПрО, характера информационных потребностей пользователей в терминах, понятных пользователю и не зависимых от реализации БД. Это описание выражается в терминах не отдельных объектов ПрО и связей между ними, а их типов, связанных с ними ограничений целостности и тех процессов, которые приводят к переходу предметной области из одного состояния в другое. На первом этапе инфологического проектирования происходит выбор подхода к проектированию БД и анализ предметной области в соответствии с индивидуальным заданием.
Рассмотрим основные подходы к созданию инфологической модели предметной области.
Функциональный подход к проектированию БД
Этот метод реализует принцип "от задач" и применяется тогда, когда известны функции некоторой группы лиц и/или комплекса задач, для обслуживания информационных потребностей которых создаётся рассматриваемая БД.
Предметный подход к проектированию БД
Предметный подход к проектированию БД применяется в тех случаях, когда у разработчиков есть чёткое представление о самой ПрО и о том, какую именно информацию они хотели бы хранить в БД, а структура запросов не определена или определена не полностью. Тогда основное внимание уделяется исследованию ПрО и наиболее адекватному её отображению в БД с учётом самого широкого спектра информационных запросов к ней.
Проектирование с использованием метода "сущность-связь"
Метод "сущность–связь" (entity–relation, ER–method) является комбинацией двух предыдущих и обладает достоинствами обоих. Этап инфологического проектирования начинается с моделирования ПрО. Проектировщик разбивает её на ряд локальных областей, каждая из которых (в идеале) включает в себя информацию, достаточную для обеспечения запросов отдельной группы будущих пользователей или решения отдельной задачи (подзадачи). Каждое локальное представление моделируется отдельно, затем они объединяются.
Выбор локального представления зависит от масштабов ПрО. Обычно она разбивается на локальные области таким образом, чтобы каждая из них соответствовала отдельному внешнему приложению и содержала 6-7 сущностей.
Сущность – это объект, о котором в системе будет накапливаться информация. Сущности бывают как физически существующие (например, СОТРУДНИК или АВТОМОБИЛЬ), так и абстрактные (например, ЭКЗАМЕН или ДИАГНОЗ).
Для сущностей различают тип сущности и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр – конкретными значениями свойств.
Типы сущностей можно классифицировать как сильные и слабые. Сильные сущности существуют сами по себе, а существование слабых сущностей зависит от существования сильных. Например, читатель библиотеки – сильная сущность, а абонемент этого читателя – слабая, которая зависит от наличия соответствующего читателя. Слабые сущности называют подчинёнными (дочерними), а сильные – базовыми (основными, родительскими).
Для каждой сущности выбираются свойства (атрибуты). Различают:
-
Идентифицирующие и описательные атрибуты. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ (ПК). В качестве ПК обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. Кроме того, ПК должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными и заключают в себе интересующие свойства сущности.
-
Составные и простые атрибуты. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно, принадлежащих разным типам данных (например, ФИО или адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от характера его обработки и формата пользовательского представления этого атрибута.
-
Однозначные и многозначные атрибуты (могут иметь соответственно одно или много значений для каждого экземпляра сущности).
-
Основные и производные атрибуты. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст студента вычисляется на основе даты его рождения и текущей даты).
Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности – множества значений (или домена), которые может принимать данный атрибут.
Далее осуществляется спецификация связей внутри локального представления. Связи могут иметь различный содержательный смысл (семантику). Различают связи типа "сущность-сущность", "сущность-атрибут" и "атрибут-атрибут" для отношений между атрибутами, которые характеризуют одну и ту же сущность или одну и ту же связь типа "сущность-сущность".
Каждая связь характеризуется именем, обязательностью, типом и степенью. Различают факультативные и обязательные связи. Если вновь порождённый объект одного типа оказывается по необходимости связанным с объектом другого типа, то между этими типами объектов существует обязательная связь (обозначается двойной линией). Иначе связь является факультативной.
По типу различают множественные связи "один к одному" (1:1), "один ко многим" (1:n) и "многие ко многим" (m:n). ER–диаграмма, содержащая различные типы связей, приведена на рис. 1. Обратите внимание, что обязательные связи на рис. 1 выделены двойной линией.
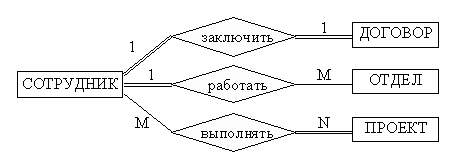
Рис.1. ER–диаграмма с примерами типов множественных связей
Степень связи определяется количеством сущностей, которые охвачены данной связью. Пример бинарной связи – связь между отделом и сотрудниками, которые в нём работают. Примером тернарной связи является связь типа экзамен между сущностями ДИСЦИПЛИНА, СТУДЕНТ, ПРЕПОДАВАТЕЛЬ. Из последнего примера видно, что связь также может иметь атрибуты (в данном случае это Дата проведения и Оценка). Пример ER–диаграммы с указанием сущностей, их атрибутов и связей приведен на рис. 2.
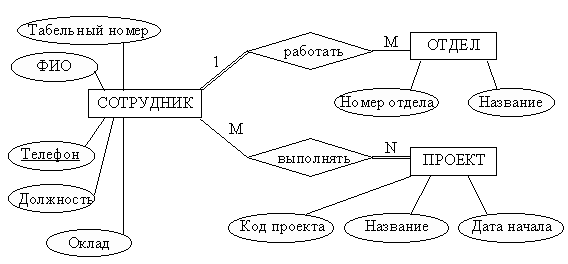
Рис.2. Пример ER–диаграммы с однозначными и многозначными атрибутами
После того, как созданы локальные представления, выполняется их объединение. При небольшом количестве локальных областей (не более пяти) они объединяются за один шаг. В противном случае обычно выполняют бинарное объединение в несколько этапов.
При объединении проектировщик может формировать конструкции, производные по отношению к тем, которые были использованы в локальных представлениях. Такой подход может преследовать следующие цели:
-
объединение в единое целое фрагментарных представлений о различных свойствах одного и того же объекта;
-
введение абстрактных понятий, удобных для решения задач системы, установление их связи с конкретными понятиями, использованными в модели;
-
образование классов и подклассов подобных объектов (например, класс "изделие" и подклассы типов изделий, производимых на предприятии).
На этапе объединения необходимо выявить и устранить все противоречия. Например, одинаковые названия семантически различных объектов или связей или несогласованные ограничения целостности на одни и те же атрибуты в разных приложениях. Устранение противоречий вызывает необходимость возврата к этапу моделирования локальных представлений с целью внесения в них соответствующих изменений.
По завершении объединения результаты проектирования являют собой концептуальную инфологическую модель предметной области. Модели локальных представлений – это внешние инфологические модели.
1.2.2. Обоснование выбора СУБД и других программных средств
Выбор СУБД является одним из важнейших моментов в разработке проекта БД, так как он принципиальным образом влияет на весь процесс проектирования БД и реализацию информационной системы. Теоретически при выборе СУБД нужно принимать во внимание десятки факторов. Но практически разработчики руководствуются лишь собственной интуицией и несколькими наиболее важными критериями, к которым, в частности, относятся:
-
тип модели данных, которую поддерживает данная СУБД, её адекватность потребностям рассматриваемой предметной области;
-
характеристики производительности системы;
-
запас функциональных возможностей для дальнейшего развития ИС;
-
степень оснащённости системы инструментарием для персонала администрирования данными;
-
удобство и надежность СУБД в эксплуатации;
-
стоимость СУБД и дополнительного программного обеспечения.
Таким образом, в разделе нужно не выбрать СУБД из множества возможных, а, опираясь на критерии, приведенные выше, обосновать свой выбор СУБД для реализации проектируемой БД.
1.2.3. Определение требований к операционной обстановке
На этом этапе производится оценка требований к вычислительным ресурсам, необходимым для функционирования системы, определение типа и конфигурации конкретной ЭВМ, выбор типа и версии операционной системы. Объём вычислительных ресурсов зависит от предполагаемого объёма проектируемой базы данных и от интенсивности их использования. Если БД будет работать в многопользовательском режиме, то требуется подключение её к сети и наличие соответствующей многозадачной операционной системы.
1.2.4. Даталогическое проектирование БД
На этом этапе разрабатывается логическая структура БД, соответствующая логической модели ПО. Решение этой задачи существенно зависит от модели данных, поддерживаемой выбранной СУБД.
Результатом выполнения этого этапа являются схемы БД концептуального и внешнего уровней архитектуры, составленные на языках определения данных (DDL, Data Definition Language), поддерживаемых данной СУБД.
1.2.5. Физическое проектирование БД
Этап физического проектирования заключается в увязке логической структуры БД и физической среды хранения с целью наиболее эффективного размещения данных, т.е. отображении логической структуры БД в структуру хранения. Решается вопрос размещения хранимых данных в пространстве памяти, выбора эффективных методов доступа к различным компонентам "физической" БД. Результаты этого этапа документируются в форме схемы хранения на языке определения данных (DDL). Принятые на этом этапе решения оказывают определяющее влияние на производительность системы.
Одной из важнейших составляющих проекта базы данных является разработка средств защиты БД. Защита данных имеет два аспекта: защита от сбоев и защита от несанкционированного доступа. Для защиты от сбоев разрабатывается стратегия резервного копирования. Для защиты от несанкционированного доступа каждому пользователю доступ к данным предоставляется только в соответствии с его правами доступа.
1.3. Особенности проектирования реляционной базы данных
Проектирование реляционной базы данных проходит в том же порядке, что и проектирование БД других моделей данных, но имеет свои особенности.
Проектирование схемы БД должно решать задачи минимизации дублирования данных и упрощения процедур их обработки и обновления. При неправильно спроектированной схеме БД могут возникнуть аномалии модификации данных. Они обусловлены отсутствием средств явного представления типов множественных связей между объектами ПО и неразвитостью средств описания ограничений целостности на уровне модели данных.
Для решения подобных проблем проводится нормализация отношений.
В рамках реляционной модели данных Э.Ф. Коддом (E.F. Codd) был разработан аппарат нормализации отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей нормальной форме.
Нормализация схемы отношения выполняется путём декомпозиции схемы. Декомпозицией схемы отношения R называется замена её совокупностью схем отношений Аi таких, что
![]() ,
,
и не требуется, чтобы отношения Аi были непересекающимися.
Введём понятие простого и сложного атрибута. Простой атрибут – это атрибут, значения которого атомарны (т.е. неделимы). Сложный атрибут может иметь значение, представляющее собой конкатенацию нескольких значений одного или разных доменов. Аналогом сложного атрибута может быть агрегат или повторяющийся агрегат данных.
Первая нормальная форма (1НФ).
Отношение приведено к 1НФ, если все его атрибуты простые.
Для того чтобы привести к 1НФ отношение, содержащее повторяющиеся атрибуты (агрегаты), нужно построить декартово произведение всех повторяющихся агрегатов с кортежами, к которым они относятся. Для идентификации кортежа в этом случае понадобится составной ключ, включающий первичный ключ исходного отношения и идентифицирующие атрибуты агрегатов.
Введём понятие функциональной зависимости. Пусть X и Y – атрибуты некоторого отношения. Если в любой момент времени каждому значению X соответствует единственное значение Y, что Y функционально зависит от X (XY). Атрибут (группа атрибутов) Х называется детерминантом.
В нормализованном отношении все неключевые атрибуты функционально зависят от ключа отношения. Говорят, что неключевой атрибут функционально полно зависит от составного ключа, если он функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.