Добавлен: 25.10.2018
Просмотров: 961
Скачиваний: 8
11
select
c
.
ClientName
,
p
.
ProductName
,
s
.*,
p
.
Price
,
p
.
Price
*
s
.
Counts
as
Summa
from
Client
c
,
Sale
s
,
Product
p
where
c
.
ClientNo
=
s
.
ClientNo
and
s
.
ProductNo
=
p
.
ProductNo
order
by
c
.
ClientName
,
p
.
ProductName
,
s
.
Dates
desc
.
select
c
.
ClientName
,
p
.
ProductName
,
s
.*,
p
.
Price
,
p
.
Price
*
s
.
Counts
as
Summa
from
Client
c
inner
join
Sale
s
on
s
.
ClientNo
=
c
.
ClientNo
join
Product
p
on
p
.
ProductNo
=
s
.
ProductNo
order
by
c
.
ClientName
,
p
.
ProductName
,
s
.
Dates
desc
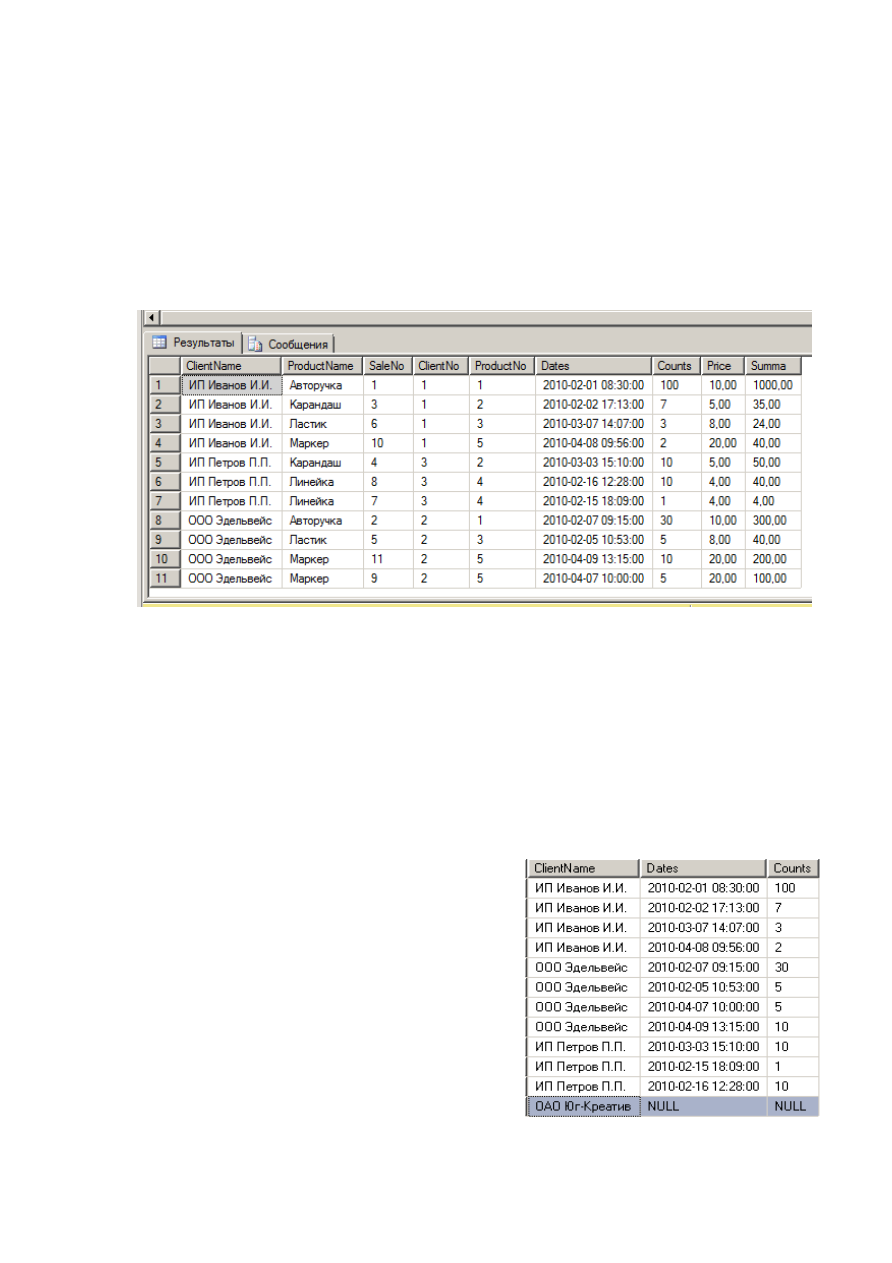
Рис. 13. – Извлечение подробной информации о продажах
Отметим, что описанные формы запросов позволяют организовать внутреннее соединение,
предполагающее вывод информации только для тех клиентов, которые сделали заказ и только о тех
продуктах, которые хотя бы один раз были проданы. Если посмотреть на рис. 3, что видно, что на
рис. 13 отсутствует организация ОАО Юг-Креатив и продукт Треугольник, т.к. они не участвовали
в продажах.
Часто возникают задачи, при которых необходимо вывести информацию о клиентах и
продажах, даже в том случае, когда клиент не совершал покупок. Так в следующем запросе (рис. 14)
выводится информация о всех клиентах и датах сделанных ими покупок.
select c.ClientName, s.Dates, s.Counts
from Client c
left join Sale s on s.ClientNo=c.ClientNo
Рис. 14. – Выборка информации о всех клиентах и датах продаж
12
Для выполнения поставленной задачи использовалось левое внешнее соединение,
реализуемое с помощью оператора left outer join (слово outer необязательное). Такое соединение
подразумевает выборку всех строк, расположенных слева от оператора left join (в нашем случае из
таблицы Client) и выборку только тех строк справа, которые соответствуют строкам слева (в нашем
случае из таблицы Sale). Из рис. 3 видно, что компания ОАО Юг-Креатив не совершала покупок,
поэтому в результирующей выборке (рис. 14) заполнены только поля, соответствующие таблицы
Client
(т.е. ClientName), все остальные поля, соответствующие другим таблицам (в нашем случае
поля Dates и Counts таблицы Sale) будут иметь null-значения. Аналогичным образом для реализации
поставленных задач можно использовать правое внешнее соединение (right join).
Модифицирована версия запроса, представленная на рис. 15, позволяет вывести
информацию только о тех клиентах, которые ничего не приобретали.
select c.ClientName
from Client c
left join Sale s on
s.ClientNo=c.ClientNo
where s.Dates is null
Рис. 15. – Выборка информации о клиентах, не сделавших ни единого заказа
Так как все поля заказа содержат null-значение, то для решения задачи достаточно проверить
любое поле из таблицы с помощью операции is null. Т.к. null имеет особый смысл в теории БД, то
для проверки наличия этого значения в поле таблицы используется отдельная операция. При этом
нельзя использовать стандартную операция сравнения на равенство (=) в данном случае, т.к.
null-
значение не равно никакому другому, в том числе и null.
Все рассмотренные до текущего момента запросы выборки данных позволяли просмотреть
детальную информацию, сформированную на основе строк, хранящихся в таблице. Одна часто
возникает задача посчитать агрегированные (статистические) значения (сумму, среднее значение,
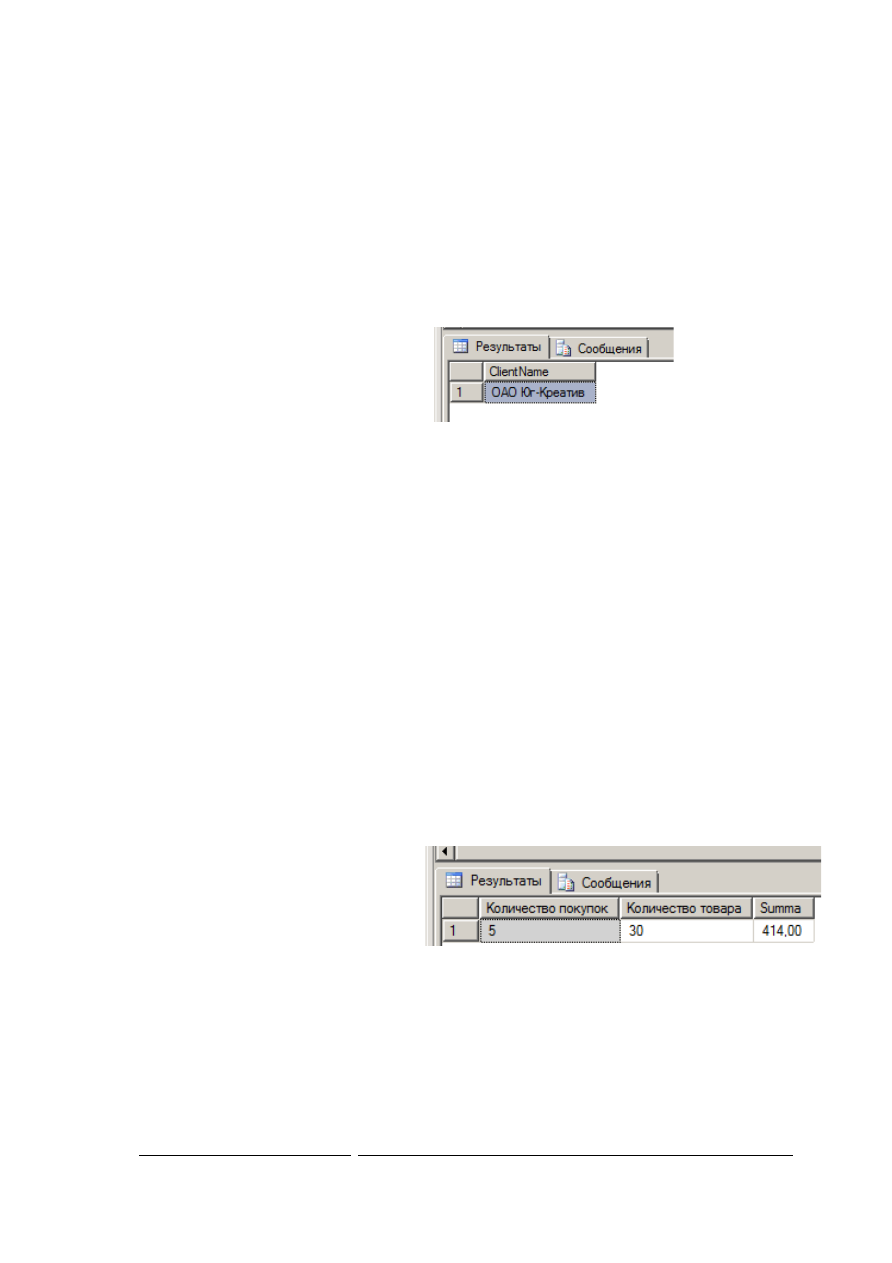
минимальное значение и др) для всей выборки. На рис. 16 представлен пример запроса, который
выводит количество покупок, количество проданного товара и сумму всех продаж, сделанных
начиная с 01.03.2010 9:00.
select
count
(*)
as
'
Количество покупок'
,
sum
(
s
.
Counts
)
as
'
Количество товара'
,
sum
(
p
.
Price
*
s
.
Counts
)
as
Summa
from
Sale
s
inner
join
Product
p
on
s
.
ProductNo
=
p
.
ProductNo
where
s
.
Dates
>=
'2010-03-01T09:00:00'
Рис. 16. – Расчет агрегированных значений
Отметим, что если выражению не присвоить псевдоним (для первого поля на рис. 16 слева),
то в результирующем наборе оно не будет иметь имени. Представленный запрос имеет следующие
особенности: в операторе select присутствуют только агрегирующие функции; условие, записанное
в where применяется к каждой строке.
В таблице 2 представлено подробное описание всех агрегирующих функций, имеющихся в
СУБД Microsoft SQL Server 2008 [1].
Табл. 1. – Агрегирующие (статистические) функции СУБД Microsoft SQL Server 2008

13
Функция/Описание
Аргументы функции
AVG( [ALL|DISTINCT] expression)
Возвращает среднее арифметическое
группы значений. Значения NULL не
учитываются.
ALL
Применяет статистическую функцию ко всем значениям. По
умолчанию задается параметр all.
DISTINCT
CHECKSUM_AGG (
[ALL|DISTINCT] expression)
Возвращает контрольную сумму
значений в группе. Значения NULL
не учитываются.
COUNT( {[[ ALL|DISTINCT]
expression] | * })
Возвращает количество элементов в
группе в виде результата типа int.
Аргументы ALL, DISTINCT и expression используются также как и
для предыдущих функций.
*
Указывается, что при возврате общего числа строк в таблице
COUNT_BIG( {[[ ALL|DISTINCT]
expression] | * })
Возвращает количество элементов в
группе в виде результата типа bigint.
MAX( [ALL|DISTINCT] expression)
Возвращает максимальное значение в
выражении.
Аргументы ALL, DISTINCT и expression используются также как и
для предыдущих функций. Однако параметр distinct не имеет
смысла при использовании функции и доступен только для
MIN( [ALL|DISTINCT] expression)
Возвращает минимальное значение в
выражении.
SUM( [ALL|DISTINCT] expression)
Возвращает сумму значений в
выражении.
Аргументы ALL, DISTINCT и expression используются также как и
для предыдущих функций.
STDEV( [ALL|DISTINCT]
expression)
Возвращает статистическое
стандартное отклонение значений в
выражении.
STDEVP( [ALL|DISTINCT]
expression)
Возвращает статистическое
среднеквадратичное отклонение
совокупности значений в
выражении.
VAR( [ALL|DISTINCT] expression)
Возвращает статистическую
дисперсию значений в выражении
VARP( [ALL|DISTINCT] expression)
Возвращает статистическую
дисперсию для заполнения значений в
выражении.
14
Часто статистические функции используются для расчёта значений не всей выборки в
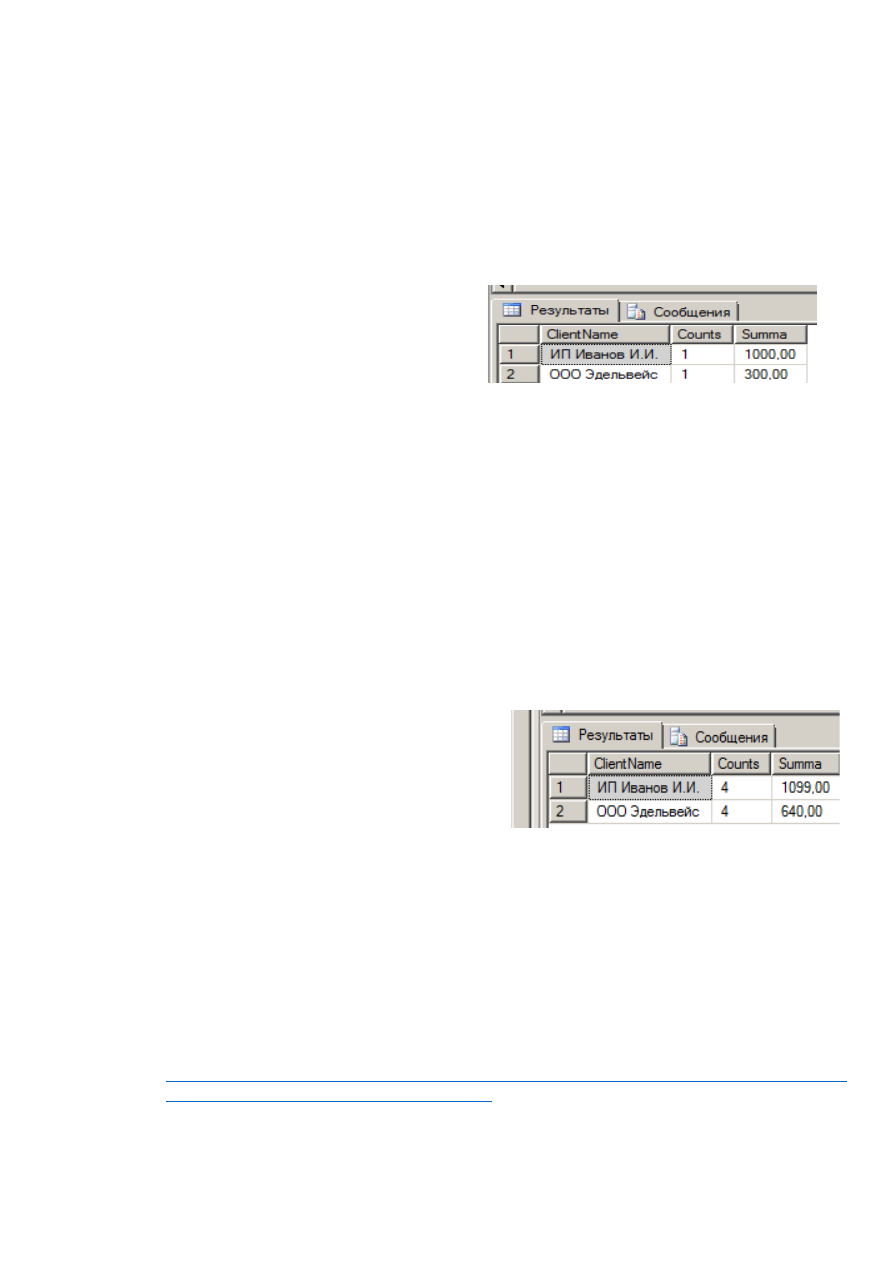
целом, а отдельных групп, сформированных по некоторым критериям. Так в запросе из рис. 17
извлекаются все продажи, в которых куплено более 10 единиц товара. Затем результирующий
набор группируется по клиентам и для каждого клиента выводится его название, количество
продаж и общая сумма всех покупок. Выборка сортируется по названию организации.
select
c
.
ClientName
,
count
(*)
as
Counts
,
sum
(
p
.
Price
*
s
.
Counts
)
as
Summa
from
Product
p
join
Sale
s
on
p
.
ProductNo
=
s
.
ProductNo
join
Client
c
on
c
.
ClientNo
=
s
.
ClientNo
where
s
.
Counts
>
10
group
by
c
.
ClientName
order
by
c
.
ClientName
Рис. 17. – Вывод агрегированных значений для покупателей
При группировке данных, выполняемой оператором group by в операторе select, могут
присутствовать только столбцы, по которым выполняется группировка (c.ClientName) и
агрегирующие функции, а также их комбинация.
Условие оператора where налагает ограничения на каждую строку выборки. Для наложения
ограничений на значения, полученные после расчета статистических функций, используется фраза
having.
На рис. 18 для тех клиентов, которые совершили более трёх покупок на общую сумму более
100 рублей выводится количество продаж и общая сумма.
select
c
.
ClientName
,
count
(*)
as
Counts
,
sum
(
p
.
Price
*
s
.
Counts
)
as
Summa
from
Product
p
join
Sale
s
on
p
.
ProductNo
=
s
.
ProductNo
join
Client
c
on
c
.
ClientNo
=
s
.
ClientNo
group
by
c
.
ClientName
having
sum
(
p
.
Price
*
s
.
Counts
)>
100
and
count
(*)>
3
order
by
c
.
ClientName
Рис. 18. – Определение условий фильтрации для агрегированных значений
Выводы
В ходе выполнения лабораторной работы были изучены основные синтаксические
конструкции, применяемые для манипулирования данными тестовой БД, реализованные в языке
Transact-SQL.
Литература
1.
Электронная документация по Microsoft SQL Server 2008 (Июль 2009г.),