Добавлен: 25.10.2018
Просмотров: 4934
Скачиваний: 12

26
• создатель (Creator) – правило, позволяющее назначить классу В обязанность создавать эк-
земпляры класса А при выполнении определенных условий;
• контроллер (Controller) – создание специального (служебного) класса–обработчика систем-
ных сообщений.
Кроме перечисленных выше пяти базовых шаблонов, отвечающих за распределение обязан-
ностей между классами, дополнительно используются шаблоны GRASP, предназначенные для обес-
печения универсальности ИС и/или расширяемости ее в будущем:
• полиморфизм (Polymorphism) – порядок распределения обязанностей класса для обеспече-
ния различных вариантов поведения его объектов;
• чистая синтетика (Pure Fabrication) - правила создания служебного класса, обеспечивающе-
го высокое сцепление, низкое связывание и повторное использование;
• перенаправление (Indirection) – правила создания промежуточного (служебного) класса,
предназначенного для обеспечения связи между компонентами или службами системы, свя-
зывание которых напрямую привело бы к нежелательному повышению внешней связности;
• защищенные вариации (Protect Variation) – правила проектирования подсистемы, при вы-
полнении которых изменение ее объектов не оказывает существенного влияния на другие
подсистемы.
Последний из указанных выше паттернов в большей степени отражает проблемы проектиро-
вания интерфейсов системы, решению которых посвящены многие GoF-паттерны (Gang-of-Four –
союз четырех), опубликованные в [62].
Использование паттернов позволяет решить несколько фундаментальных задач проектирова-
ния информационных систем – обеспечить удовлетворение принципов «слабой вешней связанности и
сильного внутреннего сцепления», а также обеспечить возможность повторного использования ком-
понентов. Ниже перечислены ошибки проектирования, затрудняющие повторное использование ком-
понентов, а также наращивание функциональности системы и GoF-паттерны, позволяющие испра-
вить такие ошибки [62]:
• поскольку сильно связанные между собой классы образуют монолитные подсистемы, в кото-
рых нельзя ни изменить, ни удалить класс без модификации других классов. Для снижения
внешней связности используются слои (см. ниже), абстрактные связи, а также следующие
паттерны: абстрактная фабрика (abstract factory), мост (bridge), цепочка обязанностей
(chain of responsibility), команда (command), фасад (facade), посредник (mediator), наблю-
датель (observer). Для повышения независимости отдельных классов подсистемы друг от
друга используются паттерны: адаптер (adapter), декоратор (decorator), посетитель
(visitor).
• использование имени класса при создании объекта привязывает проектировщика к конкрет-
ной реализации, а не к интерфейсу, что может осложнить изменение объектов в будущем.
Решение этой проблемы состоит в косвенном создании объектов с помощью паттернов абст-
рактная фабрика, фабричный метод (factory method), прототип (prototype);
• использование конкретной операции ограничивает выполнение запроса одним единственным
способом. Паттерны цепочка обязанностей и команда позволяют, не включая запросы в код,
изменить способ удовлетворения запроса, как на этапе компиляции, так и на этапе выполне-
ния;
• ограничить зависимость от конкретной платформы (операционной системы с предоставляе-
мой ее API) позволяют паттерны абстрактная фабрика и мост;
• если при построении клиента использовалась информация о том, как тот или иной объект
представлен, храниться или реализован, то при изменении объекта может потребоваться из-
менить клиент. Инкапсуляцию перечисленной информации обеспечивают паттерны абст-
рактная фабрика, мост, хранитель (memento), заместитель (proxy);
• объекты, зависящие от изменяющихся алгоритмов (в случае необходимости расширения, оп-
тимизации и т.д.), приходится перепроектировать. Паттерны мост, итератор (iterator), стра-
тегия (strategy), шаблонный метод (template method) и посетитель позволяют изолировать
алгоритмы с высокой вероятностью изменения;
• композиция объектов и делегирование – гибкие альтернативы наследования для комбиниро-
вания поведения, поскольку в этом случае новая функциональность добавляется в систему
посредством изменения способа композиции объектов, а не за счет определения новых под-
классов через наследование. Однако использование только композиции объектов может су-
27
щественно усложнить структуру проекта. В этой связи используют прием, при котором вна-
чале определяется подкласс, а затем для обеспечения требуемой специализации выполняется
комбинирование его объектов с существующими. Такой прием нашел отражение в следую-
щих паттернах: мост, цепочка обязанностей, компоновщик (composite), декоратор (deco-
rator), наблюдатель, стратегия.
Определив обязанности классов, введя системные класса, а также, рассмотрев интерфейсы
классов в соответствии с паттернами GRASP и GoF, переходят к описанию более высокоуровневых
абстракций – архитектурных слоев ИС.
Архитектура большинства корпоративных приложений включает в свой состав три слоя [98]:
(i) слой представления (presentation) предназначен для обработки событий пользовательского интер-
фейса, отображении данных, поддержки функций командной строки и т.д.; (ii) слой предметной об-
ласти (бизнес-логики или домена) предназначен для описания бизнес-логики – основных функций
приложения, предназначенных для достижения поставленной цели; (iii) слой источника данных (data
source) – отвечает за обращение к БД, обмен сообщениями, управление транзакциями с внешними
приложениями.
Зависимость слоев бизнес-логики и источника данных от слоя представления кате-
горически не допускается – это позволяет упростить адаптацию слоя представления
или замену его альтернативным вариантом с сохранением основы приложения.
4.8.1. Слой предметной области
При решении вопроса физического размещения слоев в первом приближении стараются обес-
печить их функционирование на сервере, что существенно упрощает процедуры исправления ошибок
и обновления версий. Однако в этом случае снижается скорость реагирования и возникает необходи-
мость постоянной поддержки сетевого соединения. Если для проектируемой ИС указанные характе-
ристики являются критическими, то слой представления и слой бизнес-логики вынуждены размещать
на клиентской стороне. Однако, расщепление слоя бизнес-логики между клиентом и сервером стара-
ются избегать.
Наибольшее распространение получили три подхода к организации слоя бизнес-логики:
1. Типовое решение «сценарий транзакции» (transaction script) предполагает использование про-
цедуры, которая получает на вход информацию от слоя представления, обрабатывает ее, проводя
необходимые проверки и вычисления, при необходимости активирует операции других систем.
Затем процедура возвращает результат работы слою представления, нужным образом форматируя
его, и при необходимости передает результат работы слою источника данных. Таким образом, в
этом случае бизнес-логика представляет набор процедур, по одной на каждую операцию (или ва-
риант использования), которые могут храниться в различных подпрограммах.
Существует два способа разнесения кода сценариев транзакции по классам: (i) использование од-
ного класса для реализации нескольких сценариев транзакции; (ii) разработка собственного клас-
са для каждого сценария транзакции. При этом создается родительский класс с базовым методом,
который наследуется классом, реализующим выполнение заданного сценария.
Достоинства типового решения «сценарий транзакций»: простота и наглядность, а также чет-
кие границы транзакции. Недостаток – существенное усложнение структуры приложения и дуб-
лирование кода при усложнении бизнес-логики.
2. Типовое решение «модель предметной области» (domain model) строится на базе объектно-
ориентированного подхода. Вместо использования одной подпрограммы, несущей в себе всю ло-
гику, которая соответствует набору функций, реализуемых системой, каждый объект наделяется
только теми методами, которые отвечают его природе.
В первом приближении модели предметной области делят на два типа: (i) «простые» модели
предметной области. В этом случае структура домена совпадает с ER-моделью базы данных: од-
ному объекту домена соответствует одна таблица БД; (ii) «сложные» модели – структура домена
не совпадает с ER-моделью БД и включает в свой состав иерархии наследования, а также слож-
ные сети мелких взаимосвязанных объектов.
Применение модели предметной области для реализации бизнес-логики ИС сопряжено с до-
полнительными трудностями, связанными с отображением объектов в реляционные структуры
БД. Однако существует несколько способов решения этой задачи, одним из которых является ис-
пользование преобразователя данных (см. далее) в качестве паттерна слоя источника данных.
28
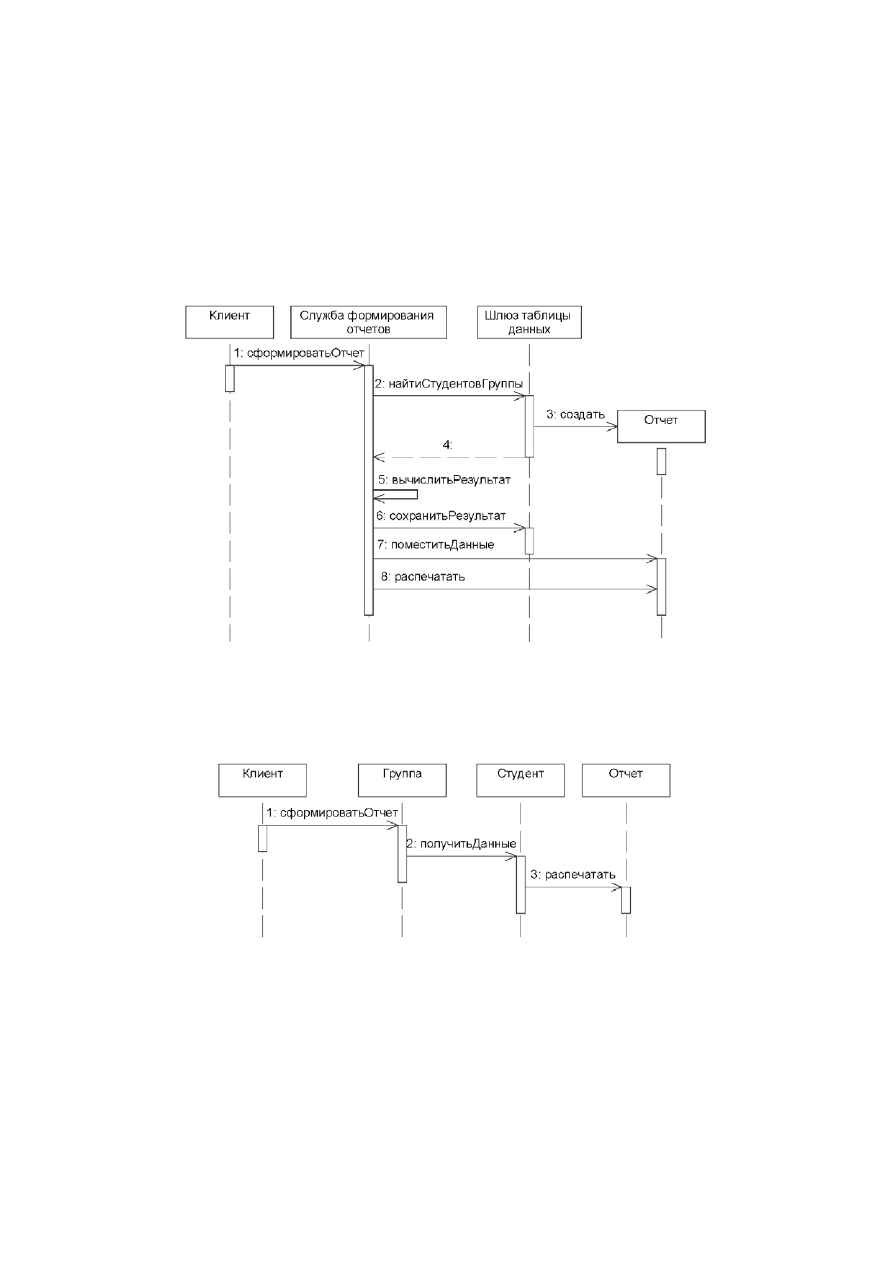
Рассмотрим для примера организацию программной системы, предназначенной для формиро-
вания сводного отчета по успеваемости студентов. Диаграмма последовательностей функциони-
рования системы, построенной на базе паттерна «сценарий транзакций», приведена на рис. 5.
Анализ диаграммы, представленной на рис. 5, показывает, что все обязанности по формиро-
ванию отчета сосредоточены в объекте «Служба формирования отчетов». В том случае, если
метод «вычислитьРезультат» является тривиальным (например, когда необходимо подсчитать
лишь количество студентов первого курса, сдавших сессию на «4» и «5»), то использование сце-
нария транзакций является вполне обоснованным. Однако зачастую бизнес-логика предметной
области, в особенности корпоративных приложений, может включать десятки и даже сотни
сложно-структурированных правил, что существенно затрудняет разработку и последующую мо-
дификацию объектов слоя домена.
Рис. 5. Формирование отчета в системе, построенной на базе паттерна «сценарий транзакций»
При использовании паттерна «модель предметной области» (см. рис. 6) обязанности каждо-
го объекта строго разграничиваются и при необходимости наращивания функциональных воз-
можностей системы изменениям будут подвержены отдельные методы, в то время как структура
домена будет оставаться неизменной.
Рис. 6. Формирование отчета в системе, построенной на базе паттерна «модель предметной области»
3. Типовое решение «модуль таблицы» (table module) является промежуточным вариантом между
сценарием транзакций и моделью предметной области. Модуль таблицы основан на использова-
нии паттерна источника данных «множество записей». Большинство инструментальных плат-
форм (например, Microsoft COM и .NET) позволяют работать с результатами обработки SQL-
запроса, организованными в виде множества записей. При этом имеется возможность выполне-
ния запроса, манипулирования его результатом в контексте модуля таблицы и передачи данных
графическому интерфейсу для отображения.
Типовое решение «модуль таблицы» предусматривает создание по одному классу на каждую
таблицу БД, единственный экземпляр класса содержит всю логику обработки данных таблицы.
29
Основное отличие паттернов «модуль таблицы» и «модель предметной области» состоит в том,
что если, например, приложение обслуживает множество заказов, в соответствии с моделью
предметной области необходимо создать по одному объекту на каждый заказ, а при использова-
нии модуля таблицы понадобится всего один объект, представляющий одновременно все заказы.
В большинстве случаев для решения общей задачи в процессе функционирования системы
создается несколько модулей таблицы, которые могут манипулировать одним и тем же множест-
вом записей.
Вместе с тем, модуль таблицы не позволяет воспользоваться всеми возможностями объектно-
ориентированной методологии для реализации сложной бизнес-логики (в частности, не полно-
ценно функционирует механизм полиморфизма). В этой связи, реализация крупных корпоратив-
ных приложений возможна только с использованием модели предметной области, не имеющей
ограничений.
Нередко при реализации слоя бизнес-логики его расщепляют на два подуровня, выделяя по-
мимо модели предметной области или модуля таблицы, слой служб, который предназначен, напри-
мер, для управления транзакциями или обеспечения безопасности. Кроме того, рассмотренные типо-
вые решения реализации слоя бизнес-логики не являются взаимоисключающими. Например, сцена-
рий транзакций может использоваться для некоторого фрагмента бизнес-логики, а модель предмет-
ной области или модуль таблицы – для оставшейся части.
4.8.2. Слой источника данных
Роль слоя источника данных в основном состоит во взаимодействии с БД в большинстве слу-
чаев реляционной. Получили распространение следующие подходы к реализации слоя источника
данных:
1. Для поддержания хорошей переносимости код SQL стремятся обособлять от бизнес-логики, раз-
мещая его в специальных классах, в которых воспроизводится структура каждой таблицы БД и
формируется шлюз, поддерживающий возможность обращения к таблице. При этом используется
два варианта реализации типового решения «шлюз» (gateway):
a. шлюз записи данных (row data gateway) предполагает использование экземпляра шлюза для
каждой записи, возвращаемой в результате обработки запроса к БД. При такой реализации
шлюз записи данных выступает в роли объекта, полностью повторяющего одну запись, напри-
мер, одну строку таблицы БД (каждому столбцу таблицы соответствует поле записи).
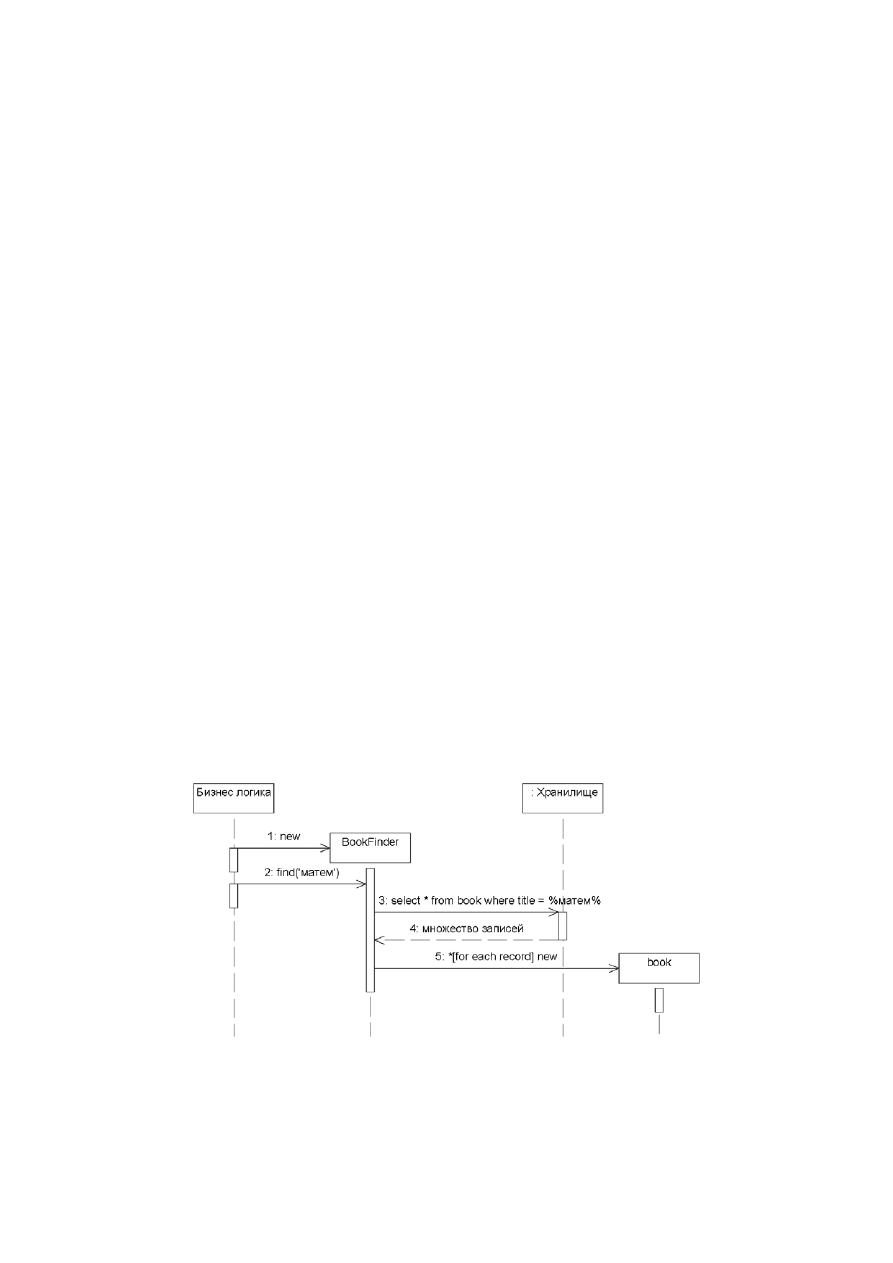
При реализации шлюза записи данных часто возникают трудности в принятии решения о раз-
мещении метода поиска. В том случае, если необходимо взаимодействовать с разными источ-
никами данных рекомендуется для каждой таблицы БД создавать отдельный класс для прове-
дения поиска и отдельный класс для сохранения результатов, как показано на рис. 7.
Рис. 7. Реализация метода поиска в контексте шлюза записи данных
Как правило, шлюз записи данных используется при представлении бизнес-логики в виде сце-
нария транзакций.
b. шлюз таблицы данных (table data gateway) предполагает использование классов, сопостав-
ленных с отдельной таблицей БД, и содержащих методы активации запросов, возвращающие
множество записей. Модель «множества записей» – основополагающая структура данных,

30
имитирующая табличную форму представления содержимого БД. Различными инструмен-
тальными системами (IDE) поддерживаются графические интерфейсные элементы, реализую-
щие паттерн «множества записей». Интерфейс шлюза таблицы данных включает в себя не-
сколько методов поиска, предназначенных для извлечения данных, а также методы обновле-
ния, вставки и удаления. Каждый метод передает аргументы соответствующей команде SQL и
выполняет ее в контексте установленного соединения с БД.
2. При описании бизнес-логики с использованием модели предметной области, относящейся к типу
«простой», для представления слоя источника данных может использоваться типовое решение
«активная запись» (active record). Каждая активная запись отвечает за сохранение и загрузку
информации в БД, а также за логику домена, применяемую к данным. Структура данных актив-
ной записи должна в точности соответствовать структуре таблицы БД: каждое поле объекта
должно соответствовать одному столбцу таблицы. Как правило, активная запись включает в се-
бя методы, предназначенные для выполнения следующих операций: (i) создание экземпляра ак-
тивной записи на основе строки, полученной в результате выполнения SQL-запроса; (ii) создание
нового экземпляра активной записи для последующей вставки в таблицу; (iii) статические методы
поиска, выполняющие стандартные SQL-запросы и возвращающие активные записи; (iv) обнов-
ление БД и вставка в нее данных из активной записи; (v) извлечение и установка значений полей
(get- и set-методы); (vi) реализация фрагментов бизнес-логики. Недостатком активной записи яв-
ляется тесная зависимость структуры ее объектов от структуры БД.
3. При использовании «сложной» модели предметной области для организации слоя бизнес-логики
стремятся полностью изолировать модель предметной области от БД, возложив на слой источни-
ка данных всю ответственность за отображение объектов домена в таблицы БД. В этом случае
слой источника данных обслуживает все операции загрузки и сохранения информации, иниции-
руемые бизнес-логикой и позволяет независимо модифицировать как модель предметной облас-
ти, так и схему БД. Поскольку объекты и реляционные СУБД используют разные механизмы
структурирования данных, то в реляционных БД не отображаются многие характеристики объек-
тов. В этой связи, для обеспечения обмена данными между объектной моделью и реляционной
СУБД используют паттерн «преобразователь данных» (data mapper) – слой ПО, который отде-
ляет объекты, расположенные в оперативной памяти от БД. В функции преобразователя данных
входит: передача данных между объектами и БД и изоляция их друг от друга; обработка классов,
поля которых объединены одной таблицей; обработка классов, соответствующих нескольким
таблицам, классов с наследованием, а также обеспечение связывания загруженных объектов.
Реализация перечисленных выше функций является нетривиальной задачей, в состав преобра-
зователя данных может входить ряд узкоспециализированных паттернов, которые, однако, находят
широкое применение при проектировании слоя источника данных в целом. Из числа «служебных»
типовых решений источника данных наибольшее распространение получили следующие паттерны:
1. единица работы (unit of work) - содержит список объектов, охватываемых бизнес-транзакцией и
предназначен для управления изменениями в БД и решения проблемы параллелизма;
2. коллекция объектов (identity map) – гарантирует, что каждый объект будет загружен из БД
только один раз, сохраняя загруженный объект в специальной коллекции. При получении запроса
коллекция просматривается в поисках нужного объекта;
3. загрузка по требованию (lazy load) – представляет собой объект, который не сдержит всех тре-
бующихся данных в настоящий момент времени, но может их загрузить в случае необходимости;
4. поле идентификации (identity field) – сохраняет идентификатор записи данных для поддержки
соответствия между объектом приложения и строкой БД;
5. отображение внешних ключей (foreign key mapping) – паттерн, предназначенный для отобра-
жения ассоциации между объектами на ссылки внешнего ключа между таблицами БД;
6. отображение с помощью таблицы ассоциации (association table mapping) – сохраняет множе-
ство ассоциаций в виде таблицы, содержащей внешние ключи таблиц, связанных ассоциациями;
7. отображение зависимых объектов (dependent mapping) – передает полномочия некоторому
служебному классу по выполнению отображения для дочернего класса;
8. внедренное значение (embedded value) – отображает объект на несколько полей таблицы, соот-
ветствующей другому объекту;
9. сериализованный крупный объект (serialized large object) – сохраняет граф объектов путем их
сериализации в единый крупный объект и помещает его в поле БД;