Добавлен: 29.10.2018
Просмотров: 48210
Скачиваний: 190
546
Глава 7. Виртуализация и облако
разовать гостевой виртуальный адрес в гостевой физический адрес, точно так же, как
он делал бы это без виртуализации. Разница в том, что он также обходит расширенные
(или вложенные) таблицы страниц, чтобы найти основной физический адрес без вме-
шательства программного обеспечения, и ему нужно делать это при каждом обращении
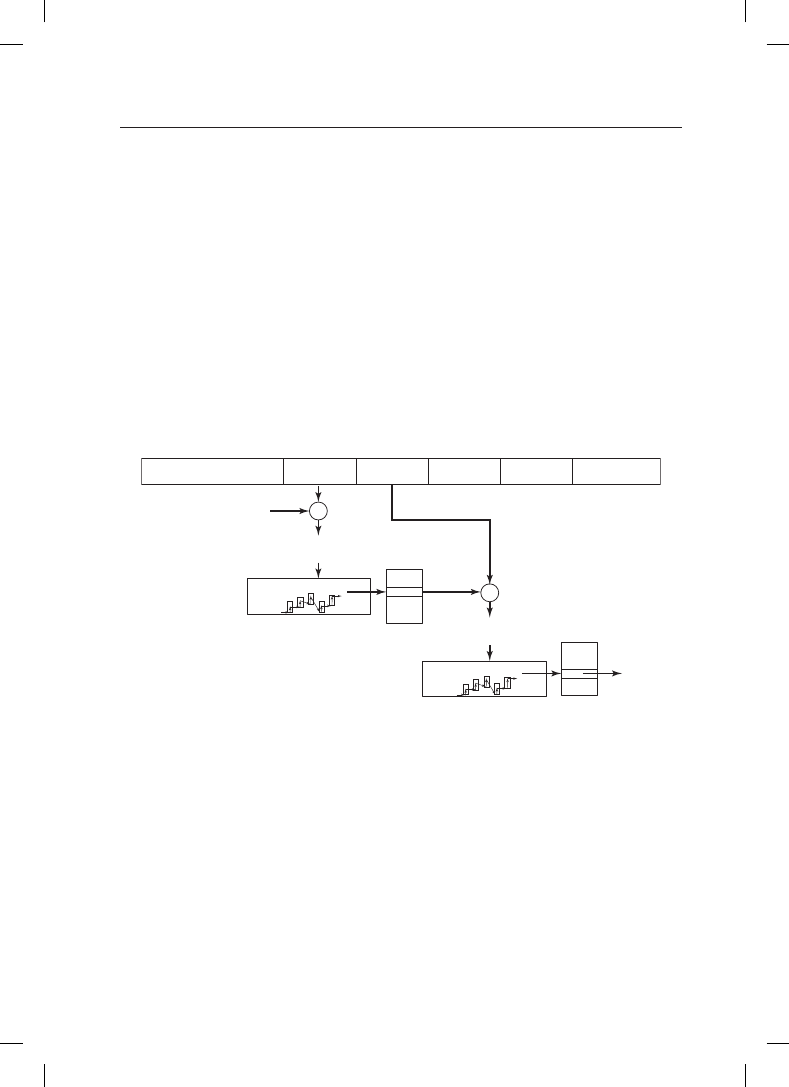
к гостевому физическому адресу. Преобразование показано на рис. 7.6.
К сожалению, оборудованию может понадобиться более частый обход вложенных
таблиц страниц, чем вы можете себе представить. Давайте предположим, что гостевой
виртуальный адрес не был кэширован и требует полного поиска в таблицах страниц.
Каждый уровень в страничной иерархии подвергается поиску во вложенных таблицах
страниц. Иными словами, количество ссылок на память возрастает в соответствии
с глубиной иерархии в квадратичной зависимости. Но даже при этом EPT существенно
сокращает количество VM-выходов. Гипервизорам больше не нужно помечать госте-
вую таблицу страниц предназначенной только для чтения, и они могут устраниться от
обработки теневых таблиц страниц. Что еще лучше, при переключении виртуальных
машин гипервизор просто изменяет это отображение точно так же, как операционная
система изменяет отображение при переключении процессов.
Ñìåùåíèå
1-ãî óðîâíÿ
63
48 47
39 38
30 29
0
+
+
è ò. ä.
Ãîñòåâîé óêàçàòåëü
íà çàïèñü â òàáëèöå
ñòðàíèö 1-ãî óðîâíÿ
Ãîñòåâîé óêàçàòåëü íà òàáëèöó
ñòðàíèö 1-ãî óðîâíÿ
Ïîèñê âî âëîæåííûõ
òàáëèöàõ ñòðàíèö
Ñìåùåíèå
ñòðàíèöû
Ñìåùåíèå
2-ãî óðîâíÿ
Ñìåùåíèå
3-ãî óðîâíÿ
Ñìåùåíèå
4-ãî óðîâíÿ
21 20
12 11
Ãîñòåâîé óêàçàòåëü íà òàáëèöó
ñòðàíèö 2-ãî óðîâíÿ
Ïîèñê âî âëîæåííûõ
òàáëèöàõ ñòðàíèö
Рис. 7.6. Расширенные (вложенные) таблицы страниц, включая обращение к каждому уровню
гостевых таблиц страниц, подвергаются обходу при каждом обращении к гостевой
физической странице
7.6.2. Возвращение памяти
Когда все эти виртуальные машины находятся на одном и том же физическом обо-
рудовании, у всех есть собственные страницы памяти и все они считают себя царями
горы, все превосходно, но до тех пор, пока не понадобится вернуть память назад. Осо-
бую важность это приобретает в случае перерасхода (overcommitment) памяти, когда
гипервизор симулирует, что общий объем памяти для всех виртуальных машин в целом
превышает общий объем физической памяти, имеющийся в системе. В общем, это не-
плохая затея, поскольку она позволяет гипервизору одновременно разрешать запуск все
большего и большего количества полноценных виртуальных машин. Например, на ма-
шине с 32 Гбайт памяти можно запустить три виртуальные машины, каждая из которых

7.7. Виртуализация ввода-вывода
547
будет полагать, что у нее 16 Гбайт памяти. Разумеется, столько машин с такой памятью
там не поместится. Но, возможно, трем машинам в действительности одновременно не
понадобится максимальный объем физической памяти. Или, возможно, они будут со-
вместно использовать страницы, имеющие одно и то же содержимое (например, ядро
Linux) в различных виртуальных машинах и при этом будет проводиться оптимизация,
известная как дедупликация (deduplication). В таком случае три виртуальные машины
используют в общем объем памяти, в три раза меньший 16 Гбайт. Дедупликация будет
рассмотрена чуть позже, а сейчас главное заключается в том, что кажущееся на данный
момент хорошее распределение при изменении рабочей нагрузки может оказаться пло-
хим. Вполне возможно, виртуальной машине 1 понадобится больше памяти, в то время
как виртуальная машина 2 могла бы работать с меньшим количеством страниц. В таком
случае было бы хорошо, чтобы гипервизор смог передать ресурсы от одной виртуальной
машины к другой и принести пользу всей системе. Вопрос в том, как можно безопасно
забрать страницы памяти, если эта память уже отдана виртуальной машине?
В принципе, можно воспользоваться еще одним уровнем страничной организации. В слу-
чае нехватки памяти гипервизор выгрузит несколько страниц виртуальных машин точно
так же, как операционная система может выгрузить несколько страниц приложения.
Недостаток такого подхода заключается в том, что это должен сделать гипервизор, но
он не имеет понятия о том, какие из страниц представляют для гостевой операционной
системы наибольшую ценность. Это очень похоже на выгрузку неподходящих страниц.
Если для выгрузки будут выбраны верные страницы (то есть те, которые также были бы
выбраны гостевой операционной системой), то впереди будет ждать еще немало проблем.
Предположим, к примеру, что гипервизор выгрузил страницу P. Чуть позже гостевая
операционная система также решает выгрузить эту страницу на диск. К сожалению,
у гипервизора и у гостевой операционной системы разные пространства свопинга. Ины-
ми словами, гипервизор должен сначала вернуть содержимое первой страницы обратно
в память только для того, чтобы посмотреть, как гостевая операционная система тут же
снова запишет ее на диск. Получается не очень-то эффективно.
Обычное решение заключается в использовании приема, известного как раздувание
(ballooning), при котором небольшой раздуваемый модуль загружается в каждую
виртуальную машину в качестве псевдодрайвера устройства, общающегося с гиперви-
зором. Раздуваемый модуль может вздуваться по запросу гипервизора путем выделе-
ния все большего и большего количества невыгружаемых страниц и сдуваться путем
освобождения этих страниц. При вздутии такого модуля дефицит памяти в гостевой
операционной системе растет, и она будет реагировать выгрузкой тех страниц, кото-
рые считает наименее ценными, что, собственно, нам и было нужно. И наоборот, как
только такой модуль сдувается, у гостевой системы появляется больше памяти для
распределения. Иными словами, гипервизор наводит операционную систему на при-
нятие трудных для нее решений. В политике такой прием называется перекладыванием
ответственности.
7.7. Виртуализация ввода-вывода
После рассмотрения виртуализации и памяти настал черед рассмотрения виртуали-
зации ввода-вывода. Обычно гостевая операционная система при запуске начинает
исследовать оборудование с целью определения типов подключенных устройств
ввода-вывода. Эти исследования будут вызывать системные прерывания с передачей

548
Глава 7. Виртуализация и облако
управления гипервизору. А что должен сделать гипервизор? Он может послать в ответ
отчет о тех дисках, принтерах и т. д., которые действительно входят в состав оборудо-
вания. Затем гостевая операционная система загружает драйверы для этих устройств
и пытается ими воспользоваться. Когда драйверы устройств пытаются осуществить
настоящий ввод-вывод, они считываются в аппаратные регистры устройства и ведут
в них запись. Инструкции для выполнения этих действий являются служебными и при-
водят к передаче управления гипервизору, который затем может по мере надобности
копировать необходимые значения в аппаратные регистры и обратно.
Но здесь у нас также имеется проблема. Каждая гостевая система может полагать, что она
владеет целым разделом диска, и виртуальных машин может быть намного больше (не-
сколько сотен), чем существующих разделов диска. Обычное решение для гипервизора
заключается в создании файла или области на реальном диске для каждого физического
диска виртуальной машины. Поскольку гостевая операционная система пытается управ-
лять диском, имеющимся у реального оборудования (и понятным гипервизору), гиперви-
зор может преобразовать номер блока, к которому идет обращение, в смещение в файле
или в области диска, используемого в качестве накопителя, и выполнить ввод-вывод.
Возможно также, что диск, используемый гостевой операционной системой, будет
отличаться от реального диска. Например, если реальный диск относится к дискам
нового, высокопроизводительного типа (или является RAID-массивом) с новым
интерфейсом, гипервизор может информировать гостевую операционную систему,
что у него имеется обычный старый IDE-диск, и позволить гостевой операционной
системе установить драйвер IDE-диска. Когда этот драйвер выдает команды управ-
ления IDE-диском, гипервизор преобразует их в команды управления новым диском.
Эта стратегия может использоваться для обновления оборудования без изменения
программного обеспечения. Фактически такая способность виртуальных машин пере-
назначать аппаратные устройства была одной из причин приобретения популярности
VM/370: компании хотели покупать новое и более быстродействующее оборудование,
но не хотели вносить изменения в свое программное обеспечение. Технология вирту-
альных машин предоставляет такую возможность.
Еще одна интересная тенденция, связанная с вводом-выводом, заключается в том, что
гипервизор может сыграть роль виртуального коммутатора. В этом случае у каждой
виртуальной машины имеется MAC-адрес и гипервизор переключает фреймы от одной
виртуальной машины к другой точно так же, как это делал бы Ethernet-коммутатор.
Виртуальные коммутаторы имеют ряд преимуществ. Например, их очень просто пере-
конфигурировать. Также можно расширить коммутатор, придав ему дополнительные
функциональные возможности, например, для обеспечения дополнительной безопас-
ности.
7.7.1. Блоки управления памятью при вводе-выводе
Еще одной проблемой, которая так или иначе должна быть решена, является при-
менение прямого доступа к памяти, DMA, который использует абсолютные адреса
памяти. Наверное, для вас не будет неожиданностью, что гипервизор должен здесь
вмешаться и переназначить адреса до запуска DMA. Но на оборудовании уже есть блок
управления памятью при вводе-выводе
(I/O MMU), который виртуализирует ввод-
вывод таким же образом, как MMU виртуализирует память. I/O MMU существует
в различных видах и формах для множества архитектур процессоров. Даже если мы

7.7. Виртуализация ввода-вывода
549
ограничимся семейством x86, то у Intel и у AMD есть немного отличающиеся друг от
друга технологии. Но замысел при этом используется один и тот же. Это оборудование
устраняет проблему DMA.
Как и обычные MMU-блоки, I/O MMU использует таблицы страниц для отображения
адреса памяти, которым желает воспользоваться устройство (адрес устройства), на
физический адрес. В виртуальной среде гипервизор может настроить таблицы страниц
таким образом, что устройство, выполняющее DMA, не станет забираться в память, не
принадлежащую виртуальной машине, от имени которой оно работает.
I/O MMU-блоки при работе с устройством в виртуализированном мире предлагают
различные преимущества. Прямая передача устройства (device pass through) позволяет
физическому устройству быть напрямую назначенным конкретной виртуальной маши-
не. В общем, было бы идеально, если бы адресное пространство устройства совпадало
с гостевым физическим адресным пространством. Но это вряд ли может произойти, пока
у вас не будет I/O MMU. Блок управления памятью позволяет адресам пройти явное
переназначение, и тогда как устройство, так и виртуальная машина будут пребывать
в абсолютном неведении о производимом в аппаратных недрах преобразовании адресов.
Изоляция устройств
(device isolation) гарантирует, что устройство, назначенное вир-
туальной машине, может напрямую обращаться к этой виртуальной машине, не под-
вергая опасности неприкосновенность других гостевых операционных систем. Иными
словами, I/O MMU предотвращает неконтролируемый DMA-трафик точно так же, как
обычный MMU предотвращает неконтролируемое обращение к памяти из процессов.
В обоих случаях обращение к неотображенным страницам влечет за собой сбой.
Но, к сожалению, на DMA и адресах история ввода-вывода не заканчивается. Для
полноты картины нам нужно также виртуализировать прерывания, чтобы прерывания,
выданные устройством, попадали на нужную виртуальную машину, имея правильный
номер. В связи с этим современные блоки I/O MMU поддерживают переназначение
прерываний
(interrupt remapping). Предположим, устройство отправило сообщение,
оповещающее о прерывании с номером 1. Сначала это сообщение попадает в I/O MMU,
чтобы преобразоваться в новое сообщение, предназначенное для центрального процес-
сора, на котором в данный момент работает виртуальная машина, да еще и с номером
вектора, ожидаемого этой виртуальной машиной (например, 66), будет использована
таблица переназначения прерываний.
И наконец, наличие I/O MMU также помогает 32-разрядным устройствам иметь до-
ступ к памяти, превышающей порог в 4 Гбайт. Обычно такие устройства (например,
DMA) не могут обращаться к адресам за пределами 4 Гбайт, но I/O MMU может легко
переназначить нижние адреса устройства на любые адреса в физическом более обшир-
ном адресном пространстве.
7.7.2. Домены устройств
Еще один подход к обработке ввода-вывода заключается в выделении одной из вир-
туальных машин для запуска стандартной операционной системы и воспроизведении
на ней всех вызовов ввода-вывода других виртуальных машин. Этот подход проявляет
свои лучшие качества при использовании паравиртуализации, при этом команда, вы-
даваемая гипервизору, фактически сообщает о том, что нужно гостевой операционной
системе (например, считать с диска 1 блок 1403), и заменяет собой серию команд, за-
писываемых в регистры устройства, которая заставляет гипервизор выступать в роли

550
Глава 7. Виртуализация и облако
Шерлока Холмса и выяснять, попытка какого именно действия предпринимается. Xen
использует этот подход для ввода-вывода с использованием осуществляющей этот
ввод-вывод виртуальной машины, которая получает имя нулевого домена (domain 0).
Виртуализация ввода-вывода относится к области, в которой гипервизоры второго
типа получают практическое преимущество над гипервизорами первого типа: основная
операционная система содержит драйверы устройств для всего разнообразия устройств
ввода-вывода, подключенных к компьютеру. Когда прикладная программа пытается
обратиться к неизвестному устройству ввода-вывода, оттранслированный код, чтобы
выполнить свою работу, может вызвать существующий драйвер устройства. При нали-
чии гипервизора первого типа он должен либо содержать сам драйвер, либо вызывать
драйвер в нулевом домене, что похоже на действия основной операционной системы.
По мере становления технологии виртуальных машин оборудование, скорее всего, по-
зволит прикладным программам обращаться к оборудованию напрямую безопасным
образом, а это будет означать, что драйверы устройств смогут быть непосредственно
связаны с кодом приложения или помещены в отдельные серверы, работающие в поль-
зовательском режиме (как в MINIX3), устраняя, таким образом, проблему.
7.7.3. Виртуализация ввода-вывода в отдельно взятом
физическом устройстве
Непосредственное назначение устройства виртуальной машине плохо масштабируется.
Этим способом с четырьмя физическими сетями можно поддерживать не более четырех
виртуальных машин. Для восьми виртуальных машин нужны восемь сетевых карт,
а при запуске 128 виртуальных машин ваш компьютер в сплетении всех эти сетевых
кабелей вряд ли отыщется.
Организовать программным способом совместное использование устройств несколькими
гипервизорами возможно, но зачастую не оптимально, потому что уровень эмуляции
(или домен устройства) вклинивается между оборудованием, драйверами и гостевыми
операционными системами. Эмулируемое устройство зачастую не реализует все расши-
ренные функции, поддерживаемые оборудованием. В идеале технология виртуализации
должна была бы предложить эквивалент устройства, переходя без каких-либо издержек
от отдельно взятого устройства к нескольким гипервизорам. Виртуализация отдельно
взятого устройства, вводящая каждую виртуальную машину в заблуждение, что у нее
имеется исключительный доступ к его собственному устройству, существенно облегча-
ется, если оборудование проделает эту виртуализацию за вас. На PCIe такое действие
называется виртуализацией ввода-вывода в отдельно взятом физическом устройстве.
Виртуализация ввода-вывода в отдельно взятом физическом устройстве
(Single root
I/O virtualization (SR-IOV)) позволяет обойти привлечение гипервизора к обмену
данными между драйвером и устройством. Устройства, поддерживающие SR-IOV,
предоставляют независимое пространство памяти, прерывания и DMA-потоки каждой
использующей их виртуальной машине (Intel, 2011). Устройства показываются как
несколько отдельных устройств, каждое из которых может быть сконфигурировано
отдельной виртуальной машиной. Например, у каждого устройства будут отдельный
регистр базового адреса и отдельное адресное пространство. Виртуальная машина ото-
бражает одну из этих областей памяти (используемую, к примеру, для конфигурации
устройства) на свое адресное пространство.
SR-IOV предоставляет доступ к устройству в двух разновидностях: физических функ-
циях
(Physical Functions (PF)) и виртуальных функциях (Virtual Functions (VF)). Фи-