Добавлен: 29.10.2018
Просмотров: 48078
Скачиваний: 190

836
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
страниц с одинаковой защитой и страничной организацией. Текстовый сегмент и ото-
браженные файлы являются примерами таких областей (см. рис. 10.8). Между обла-
стями виртуального адресного пространства могут быть дыры. Любая ссылка на дыру
приводит к фатальной страничной ошибке. Размер страницы фиксирован: например,
для Pentium он равен 4 Кбайт, а для Alpha — 8 Кбайт. Начиная с Pentium была добав-
лена поддержка страничных блоков размером 4 Мбайт. На последних 64-разрядных
архитектурах Linux умеет поддерживать большие страницы (huge pages) размером по
2 Мбайт или 1 Гбайт каждая. Кроме того, в режиме расширения физических адресов
(Physical Address Extension (PAE)), который используется на некоторых 32-битных
архитектурах для увеличения адресного пространства процессов сверх 4 Гбайт, под-
держивается также размер страниц 2 Мбайт.
Каждая область описывается в ядре элементом vm_area_struct. Все эти элементы (для
одного процесса) связываются вместе в список, отсортированный по виртуальным
адресам (чтобы все страницы можно было найти). Когда список становится слишком
длинным (более 32 элементов), для ускорения поиска по нему создается дерево. В эле-
менте vm_area_struct перечислены свойства области. Эти свойства включают режим
защиты (например, «только для чтения» или «чтение/запись»), информацию о том,
закреплен ли он в памяти (не подкачивается) и в каком направлении растет (для сег-
ментов данных — вверх, для стеков — вниз).
В структуре vm_area_struct также записано, является область приватной для процесса
или используется совместно с одним или несколькими другими процессами. После вы-
полнения вызова fork система Linux делает копию списка областей для дочернего про-
цесса, но настраивает указатели в родительском и дочернем процессах на одни и те же
таблицы страниц. Области помечаются как «чтение/запись», но страницы помечаются
как «только для чтения». Если какой-то процесс пытается сделать запись в страницу,
то происходит ошибка защиты и ядро видит, что область логически доступна для за-
писи, а страница — нет. Тогда ядро дает процессу копию страницы и помечает ее как
«чтение/запись». С помощью этого механизма реализовано копирование при записи.
В структуре vm_area_struct также записано, имеет ли область резервное хранение на
диске, и если имеет, то где. Текстовые сегменты используют в качестве резервного
хранения исполняемый двоичный файл, а отображаемые на память файлы — дисковый
файл. Другие области (такие, как стек) не имеют резервного хранения (до момента
вытеснения в файл подкачки).
Дескриптор памяти верхнего уровня mm_struct собирает информацию обо всех об-
ластях виртуальной памяти (принадлежащих адресному пространству), о различных
сегментах (текста, данных, стека), пользователях (совместно использующих это адрес-
ное пространство) и т. д. Ко всем элементам адресного пространства в mm_struct можно
обращаться через их дескриптор памяти (двумя способами). Во-первых, они организо-
ваны в связанные списки, упорядоченные по адресам виртуальной памяти. Этот способ
полезен тогда, когда нужно обращаться ко всем областям виртуальной памяти или
когда ядро ищет для выделения область виртуальной памяти определенного размера.
Кроме того, элементы структуры vm_area_struct организованы в бинарное дерево (это
оптимизированная для быстрого поиска структура). Этот метод используется, когда
нужно обратиться к определенной виртуальной памяти. Обеспечивая доступ к эле-
ментам адресного пространства процессов этими двумя способами, Linux использует
больше памяти на процесс, но позволяет различным операциям ядра использовать тот
метод доступа, который более эффективен для текущей задачи.

10.4. Управление памятью в Linux
837
10.4.4. Подкачка в Linux
В ранних системах UNIX использовался процесс подкачки (swapper process), который
перемещал процессы целиком между памятью и диском (когда все активные процессы
не помещались в физической памяти). Linux (подобно другим современным версиям
UNIX) больше не перемещает процессы целиком. Единицей управления памятью яв-
ляется страница, и почти все компоненты управления памятью работают с точностью
до страниц. Подсистема подкачки также работает с точностью до страниц и тесно свя-
зана с алгоритмом Page Frame Reclaiming Algorithm, описанным далее в этом разделе.
Основная идея подкачки в Linux проста: процессу не обязательно находиться цели-
ком в памяти для того, чтобы выполняться. Все, что нужно, — это пользовательская
структура и таблицы страниц. Если они подкачаны в память, то процесс считается
находящимся в памяти и может планироваться для выполнения. Страницы сегментов
текста, данных и стека подкачиваются динамически (по одной) по мере появления
ссылок на них. Если пользовательская структура и таблица страниц не находятся
в памяти, то процесс не может выполняться до тех пор, пока процесс подкачки не до-
ставит их в память.
Подкачка реализована частично ядром, а частично новым процессом, называемым
демоном
страниц (page daemon). Демон страниц — это процесс 2 (процесс 0 — это про-
цесс idle, традиционно называемый своппером, а процесс 1 — это init (см. рис. 10.5)).
Как и все демоны, демон страниц работает периодически. После пробуждения он ос-
матривается, есть ли для него работа. Если он видит, что количество страниц в списке
свободных слишком мало, то он начинает освобождать страницы.
Операционная система Linux является системой с подкачкой страниц по требованию
(без упреждающей подкачки) и без концепции рабочего набора (хотя в ней есть систем-
ный вызов для указания пользователем страницы, которая ему может скоро понадо-
биться). Текстовые сегменты и отображаемые на адресное пространство памяти файлы
подгружаются из соответствующих им файлов на диске. Все остальное выгружается
либо в раздел подкачки (если он присутствует), либо в один из файлов подкачки (фик-
сированной длины), которые называются областью подкачки (swap area). Файлы под-
качки могут динамически добавляться и удаляться, и у каждого есть свой приоритет.
Подкачка страниц из отдельного раздела диска, доступ к которому осуществляется как
к отдельному устройству, не содержащему файловой системы, более эффективна, чем
подкачка из файла, по нескольким причинам. Во-первых, не требуется отображение
блоков файла в блоки диска. Во-вторых, физическая запись может иметь любой размер,
а не только размер блока файла. В-третьих, страница всегда пишется на диск в виде
единого непрерывного участка, а при записи в файл подкачки это может быть и не так.
Страницы на устройстве подкачки или разделе подкачки не выделяются до тех пор,
пока они не потребуются. Каждое устройство или файл подкачки начинается с битового
массива, в котором сообщается, какие страницы свободны. Когда страница, у которой
нет резервного хранения на диске, должна быть удалена из памяти, то из разделов
(или файлов) подкачки, в которых еще есть свободное место, выбирается раздел (или
файл) с наивысшим приоритетом и в нем выделяется страница. Как правило, раздел
подкачки (если таковой имеется) имеет более высокий приоритет, чем любой файл
подкачки. Таблица страниц обновляется, чтобы отразить тот факт, что страница больше
не присутствует в памяти (то есть устанавливается бит «страница отсутствует»), и ее
местоположение на диске записывается в элемент таблицы страниц.

838
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Алгоритм замещения страниц
Алгоритм замещения страниц работает следующим образом. Система Linux пытается
поддерживать некоторые страницы свободными, чтобы при необходимости их можно
было предоставить. Конечно, этот пул страниц должен постоянно пополняться. Это
делается при помощи алгоритма PFRA (Page Frame Reclaiming Algorithm).
Linux различает четыре разных типа страниц: неиспользуемые (unreclaimable), подкачи-
ваемые (swappable), синхронизируемые (syncable) и отбрасываемые (discardable). Не-
используемые страницы (которые включают зарезервированные или заблокированные
страницы, стеки режима ядра и т. п.) не могут вытесняться в подкачку. Подкачиваемые
страницы должны быть записаны обратно в область подкачки (или в раздел подкач-
ки) перед тем, как их можно будет вновь использовать. Синхронизируемые страницы
должны быть записаны на диск в том случае, если они были помечены как «грязные».
И наконец, отбрасываемые страницы могут быть использованы немедленно.
Во время загрузки процесс init запускает страничные демоны kswapd (по одному на
каждый узел памяти) и настраивает их на периодическое срабатывание. При каждом
пробуждении kswapd проверяет, есть ли достаточное количество свободных страниц,
для этого он сравнивает нижний и верхний пределы с текущим уровнем использова-
ния памяти в каждой области памяти. Если памяти достаточно, то он отправляется
обратно спать, хотя может быть разбужен и раньше, если внезапно понадобятся до-
полнительные страницы. Если доступной памяти в одной из зон становится меньше
нижнего предела, то kswapd инициирует алгоритм востребования страниц PFRA.
Во время каждого прохода востребуется только определенное заданное количество
страниц (обычно это 32 страницы). Это число ограничено, чтобы сдерживать объем
ввода-вывода (количество операций записи на диск, порожденных при работе PFRA).
И количество востребуемых страниц, и суммарное количество просмотренных стра-
ниц — это настраиваемые параметры.
При каждом выполнении PFRA сначала пытается востребовать легкодоступные страни-
цы, после чего переходит к труднодоступным. Многие ведь стремятся сначала сорвать те
плоды, что висят ниже. Отбрасываемые страницы и страницы, на которые нет ссылок,
могут быть востребованы немедленно, для этого их необходимо перенести в список
свободных страниц зоны. Затем он ищет такие страницы с резервным хранением, на
которые не было ссылок в последнее время (при помощи временного алгоритма). За-
тем следуют совместно используемые страницы, которые не используются активно
пользователями. Проблема с совместно используемыми страницами состоит в том, что
если элемент страницы востребуется, то таблицы страниц всех адресных пространств
(совместно использующих эту страницу) должны быть синхронно обновлены. Linux
поддерживает эффективные древоподобные структуры данных для того, чтобы облегчить
поиск всех пользователей совместно используемой страницы. Затем просматриваются
обычные пользовательские страницы, и если принимается решение об их вытеснении,
то они ставятся в очередь на запись в область подкачки. «Подкачиваемость» (swappines)
системы, то есть отношение количества страниц с резервным хранением к количеству
страниц, нуждающихся в вытеснении с использованием PFRA, — это настраиваемый па-
раметр алгоритма. И наконец, если страница недействительна, отсутствует в памяти, ис-
пользуется совместно, заблокирована или используется для DMA, то она пропускается.
PFRA при выборе (в данной категории) старых страниц для вытеснения использует
алгоритм, подобный алгоритму часов. В основе этого алгоритма лежит цикл, который
10.4. Управление памятью в Linux
839
сканирует список активных и неактивных страниц каждой зоны, пытаясь востребовать
страницы различных типов (с разной срочностью). Значение срочности передается как
параметр, который сообщает процедуре о том, сколько усилий нужно потратить для
востребования страниц. Обычно он указывает, сколько страниц нужно обследовать до
того, как прекратить работу.
Во время работы PFRA страницы переносятся между списками активных и неактивных
описанным на рис. 10.11 способом. Для реализации некоторых эвристик и поиска стра-
ниц, на которые не было ссылок и которые вряд ли понадобятся в ближайшем будущем,
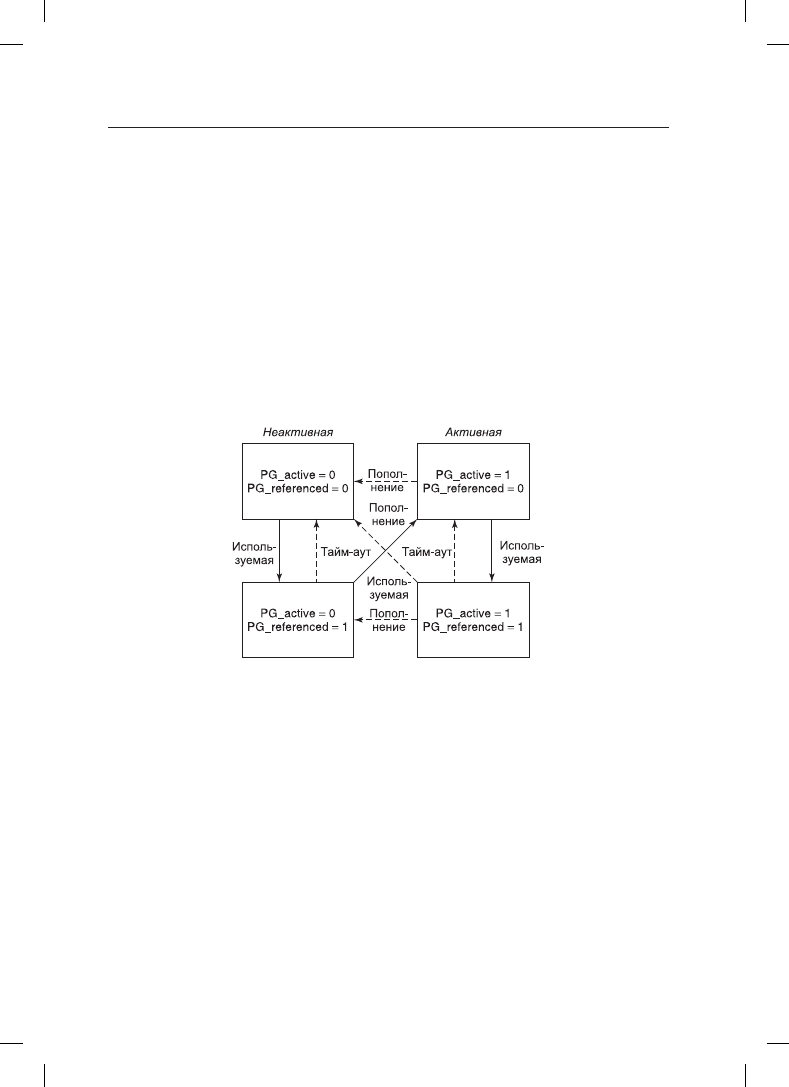
алгоритм PFRA поддерживает два флага для каждой страницы: активная/неактивная
и ссылки есть/нет. Этими двумя флагами можно обозначить четыре состояния (см.
рис. 10.11). Во время первого сканирования набора страниц PFRA сначала сбрасывает
их биты ссылок. Если во время второго прохода по странице обнаруживается, что на
нее была ссылка, то она переводится в другое состояние, из которого вряд ли будет
востребована. В противном случае страница переводится в такое состояние, в котором
она будет вытеснена с большей вероятностью.
Рис. 10.11. Состояния страниц, которые рассматривает алгоритм замещения страниц PFRA
Страницы из списка неактивных (на которые не было ссылок с момента последнего
обследования) являются наилучшими кандидатами на вытеснение. Это те страницы,
у которых оба бита, PG_active и PG_referenced, установлены в нуль (см. рис. 10.11).
Однако при необходимости страницы могут быть востребованы (даже если они на-
ходятся в одном из других состояний). Этот факт изображен на рисунке стрелками
«пополнение».
PFRA содержит страницы в списке неактивных (хотя на них могут быть ссылки) для
того, чтобы предотвратить ситуации наподобие следующей: рассмотрим процесс, кото-
рый делает периодические обращения к разным страницам (с периодичностью в один
час). Страница, к которой в последний раз выполнялось обращение, будет иметь уста-
новленный флаг доступа. Однако поскольку она не понадобится в течение следующего
часа, можно не считать ее кандидатом на востребование.
До сих пор мы не упоминали второй демон системы управления памятью — pdflush,
который, фактически является набором фоновых потоков демона. Либо потоки pdflush
пробуждаются периодически (обычно каждые 500 мс) для записи на диск очень ста-

840
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
рых «грязных» страниц, либо их явным образом будит ядро (когда уровень доступной
памяти падает ниже определенного порога) для записи «грязных» страниц из кэша
страниц на диск. В режиме ноутбука (для сохранения энергии батареи) «грязные»
страницы пишутся на диск при пробуждении потоков pdflush. «Грязные» страницы
могут также записываться на диск по явным запросам синхронизации (при помощи
таких системных вызовов, как sync, orfsync и fdatasync). В более старых версиях Linux
использовались два отдельных демона: kupdate (для записи старых страниц) и bdflush
(для записи страниц в условиях недостатка памяти). В ядре 2.4 эта функциональность
была интегрирована в потоки pdflush. Выбор в пользу нескольких потоков был сделан
для маскировки большой латентности дисков.
10.5. Ввод-вывод в системе Linux
Система ввода-вывода в Linux довольно проста и не отличается от присущих другим
UNIX-системам. Как правило, все устройства ввода-вывода выглядят как файлы и до-
ступ к ним осуществляется с помощью тех же системных вызовов read и write, которые
используются для доступа ко всем обычным файлам. В некоторых случаях должны
быть заданы параметры устройства — это делается при помощи специального систем-
ного вызова. В следующих разделах мы рассмотрим эти вопросы.
10.5.1. Фундаментальные концепции
Как и у всех компьютеров, у работающих под управлением операционной системы
Linux машин есть подключенные к ним устройства ввода-вывода (такие, как диски,
принтеры и сети). Требуется некий способ предоставления программам доступа к этим
устройствам. Хотя возможны различные варианты решения данного вопроса, при-
меняемый в операционной системе Linux подход заключается в интегрировании всех
устройств в файловую систему в виде так называемых специальных файлов (special
files) . Каждому устройству ввода-вывода назначается маршрут (обычно в каталоге
/dev
). Например, диск может иметь маршрут
/dev/hd1
, у принтера может быть маршрут
/dev/lp
, а у сети —
/dev/net
.
Доступ к этим специальным файлам осуществляется так же, как и к любым другим
файлам. Для этого не требуется никаких специальных команд или системных вызовов.
Вполне подойдут обычные системные вызовы read и write. Например, команда
cp file /dev/lp
скопирует файл
file
на принтер, в результате чего этот файл будет распечатан (при
условии, что у пользователя есть разрешение на доступ к
/dev/lp
). Программы могут
открывать и читать специальные файлы, а также писать в них (тем же способом, что
и в обычные файлы). На самом деле программа cp в приведенном выше примере даже
не знает, что она делает вывод на печать. Таким образом, для выполнения ввода-вывода
не требуется специального механизма.
Специальные файлы подразделяются на две категории: блочные и символьные. Блоч-
ный специальный файл
(block special file) состоит из последовательности пронумеро-
ванных блоков. Основное свойство блочного специального файла заключается в том,
что к каждому его блоку можно адресоваться и получить доступ отдельно. Иначе
говоря, программа может открыть блочный специальный файл и прочитать, скажем,