Добавлен: 29.10.2018
Просмотров: 48073
Скачиваний: 190

10.6. Файловая система UNIX
861
количеством байтов). На рисунке это поле обозначено стрелкой. Затем располагается
поле типа файл, каталог и т. д. Последнее поле фиксированной длины содержит длину
имени файла в байтах (8, 10 и 6 для данного примера). Наконец, идет само имя файла,
заканчивающееся нулевым байтом и дополненное до 32-битной границы. За ним могут
следовать дополнительные байты-заполнители.
На рис. 10.18, б показан тот же самый каталог после того, как элемент для
voluminous
был удален. Все, что при этом делается в каталоге, — увеличивается число в поле разме-
ра записи предыдущего файла
colossal
, а байты записи каталога для удаленного файла
voluminous
превращаются в заполнители первой записи. Впоследствии эти байты могут
использоваться для записи при создании нового файла.
Поскольку поиск в каталогах производится линейно, то поиск записи, которая на-
ходится в конце большого каталога, может занять много времени. Поэтому система
поддерживает кэш каталогов, к которым недавно производился доступ. Поиск в кэше
производится по имени файла, и если оно найдено, то дорогой линейный поиск уже не
нужен. Объект dentry вводится в кэш элементов каталога для каждого из компонентов
пути, и (через его i-узел) выполняется поиск в каталоге последующих элементов пути
(до тех пор, пока не будет найден фактический i-узел файла).
Например, чтобы найти файл, указанный абсолютным путем (таким, как
/usr/ast/file
),
необходимо выполнить следующие шаги. Прежде всего система находит корневой ката-
лог, который обычно использует i-узел с номером 2 (особенно когда i-узел с номером 1
зарезервирован для работы с плохими блоками). Она помещает в кэш элементов ката-
лога соответствующий элемент (для будущих поисков корневого каталога). Затем она
ищет в корневом каталоге строку «usr», чтобы получить номер i-узла для каталога
/usr
(который также вносится в кэш элементов каталога). Этот i-узел затем читается, и из
него извлекаются дисковые блоки, так что можно читать каталог
/usr
и искать в нем
строку «ast». После того как соответствующий элемент найден, из него можно опреде-
лить номер i-узла для каталога
/usr/ast
. Имея этот номер i-узла, его можно прочитать
и найти блоки каталога. И наконец, мы ищем «file» и находим номер его i-узла. Таким
образом, использование относительного пути не только более удобно для пользователя,
но и сокращает количество работы для системы.
Если файл имеется в наличии, то система извлекает номер i-узла и использует его как
индекс таблицы i-узлов (на диске) для поиска соответствующего i-узла и считывания
его в память. Этот i-узел помещается в таблицу i-узлов (i-node table) — структуру
данных ядра, которая содержит все i-узлы для открытых в данный момент файлов
и каталогов. Формат элементов i-узлов должен содержать (как минимум) все поля, ко-
торые возвращает системный вызов stat, чтобы вызов stat мог работать (см. табл. 10.10).
В табл. 10.13 показаны некоторые из полей структуры i-узла, поддерживаемой в фай-
ловой системе Linux. Реальная структура i-узла содержит гораздо больше полей,
поскольку эта же структура используется для представления каталогов, устройств
и прочих специальных файлов. Структура i-узла содержит также зарезервированные
для будущего использования поля. История показала, что неиспользованные биты
недолго остаются без дела.
Теперь давайте посмотрим, как система читает файл. Вы помните, что типичный вызов
библиотечной процедуры для запуска системного вызова read выглядит следующим
образом:
n = read(fd, buffer, nbytes);

862
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Таблица 10.13. Структура i-узла в Linux
Поле
Размер, байт
Описание
Mode
2
Тип файла, биты защиты, биты setuid и setgid
Nlinks
2
Количество элементов каталога, указывающих на этот i-узел
Uid
2
UID владельца файла
Gid
2
GID владельца файла
Size
4
Размер файла в байтах
Addr
60
Адрес первых 12 дисковых блоков файла и 3 косвенных блоков
Gen
1
Номер «поколения» (увеличивается на единицу при каждом по-
вторном использовании i-узла)
Atime
4
Время последнего доступа к файлу
Mtime
4
Время последней модификации файла
Ctime
4
Время последнего изменения i-узла (не считая других раз)
Когда ядро получает управление, то все, с чего оно может начать, — эти три параметра
и информация в его внутренних таблицах (относящаяся к пользователю). Один из эле-
ментов этих внутренних таблиц — массив файловых дескрипторов. Он индексирован
по файловым дескрипторам и содержит по одному элементу на каждый открытый файл
(до некоторого максимального количества, по умолчанию это обычно 32).
Идея состоит в том, чтобы начать с этого дескриптора файла и закончить соответ-
ствующим i-узлом. Давайте рассмотрим одну вполне возможную схему: поместим
указатель на i-узел в таблицу дескрипторов файлов. Несмотря на простоту, данный
метод (к сожалению) не работает. Проблема заключается в следующем. С каждым
дескриптором файла должен быть связан указатель в файле, определяющий тот байт
в файле, с которого начнется следующая операция чтения или записи. Где следует
хранить этот указатель? Один вариант состоит в размещении его в таблице i-узлов.
Однако такой подход не сможет работать, если несколько не связанных друг с другом
процессов одновременно откроют один и тот же файл, поскольку у каждого процесса
должен быть собственный указатель.
Второй вариант решения заключается в размещении указателя в таблице дескрипторов
файлов. При этом каждый открывающий файл процесс имеет собственную позицию
в файле. К сожалению, такая схема также не работает, но причина неудачи в данном
случае не столь очевидна и имеет отношение к природе совместного использования
файлов в системе Linux. Рассмотрим сценарий оболочки s, состоящий из двух ко-
манд (p1 и p2), которые должны выполняться по очереди. Если сценарий вызывается
командной строкой
s >x
то ожидается, что команда p1 будет писать свои выходные данные в файл
x
, а затем
команда p2 также будет писать свои выходные данные в файл
x
, начиная с того места,
на котором остановилась команда p1.
Когда оболочка запустит процесс p1, файл
x
будет сначала пустым, поэтому команда p1
просто начнет запись в файл в позиции 0. Однако когда p1 закончит свою работу, по-
требуется некий механизм, который гарантирует, что процесс p2 увидит в качестве
10.6. Файловая система UNIX
863
начальной позиции не 0 (а именно так и произойдет, если позицию в файле хранить
в таблице дескрипторов файлов), а то значение, на котором остановился p1.
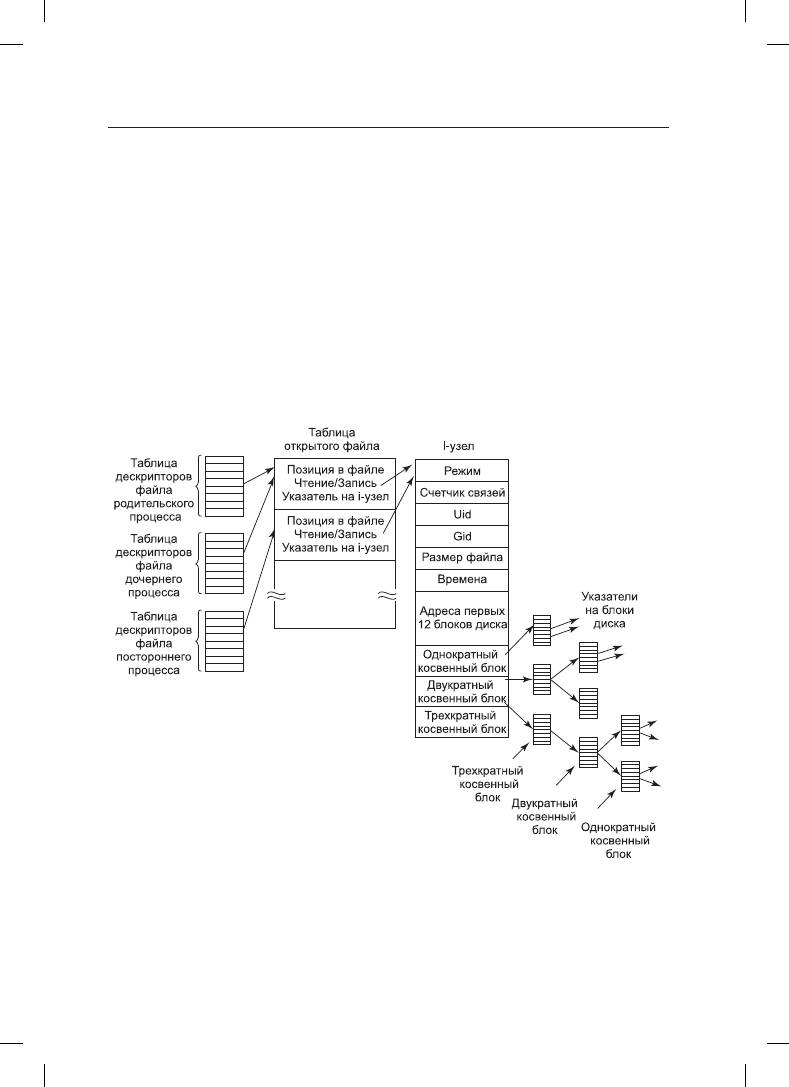
То, как это делается, показано на рис. 10.19. Фокус состоит в том, чтобы ввести новую
таблицу — таблицу описания открытых файлов (open file description table) — между
таблицей дескрипторов файлов и таблицей i-узлов и хранить в ней указатель в файле
(а также бит чтения/записи). На рисунке родительским процессом является оболочка,
а дочерним сначала является процесс p1, а затем процесс p2. Когда оболочка создает
процесс p1, то его пользовательская структура (включая таблицу дескрипторов фай-
лов) представляет собой точную копию такой же структуры оболочки, поэтому обе
они содержат указатели на одну и ту же таблицу описания открытых файлов. Когда
процесс p1 завершает свою работу, дескриптор файла оболочки продолжает указывать
на таблицу описания открытых файлов, в которой содержится позиция процесса p1
в файле. Когда теперь оболочка создает процесс p2, то новый дочерний процесс авто-
матически наследует позицию в файле, при этом ни новый процесс, ни оболочка не
обязаны знать текущее значение этой позиции.
Рис. 10.19. Связь между таблицей дескрипторов файлов, таблицей описания открытых файлов
и таблицей i-узлов
Если какой-нибудь посторонний процесс откроет файл, то он получит собственную
запись в таблице описания открытых файлов со своей позицией в файле, а именно
это и нужно. Таким образом, задача таблицы описания открытых файлов заключается

864
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
в том, чтобы позволить родительскому и дочернему процессам совместно использо-
вать один указатель в файле, но для посторонних процессов выделять персональные
указатели.
Итак (возвращаясь к проблеме выполнения чтения read), мы показали, как опреде-
ляются позиция в файле и i-узел. I-узел содержит дисковые адреса первых 12 блоков
файла. Если позиция в файле попадает в его первые 12 блоков, то считывается нужный
блок файла и данные копируются пользователю. Для файлов, длина которых превы-
шает 12 блоков, в i-узле содержится дисковый адрес одинарного косвенного блока
(single indirect block) (рис. 10.19). Этот блок содержит дисковые адреса дополнитель-
ных дисковых блоков. Например, если размер блока составляет 1 Кбайт, а дисковый
адрес занимает 4 байта, то одинарный косвенный блок может хранить до 256 дисковых
адресов. Такая схема позволяет поддержать файлы размером до 268 Кбайт.
Для более крупных размеров используется двойной косвенный блок (double indirect
block) . Он содержит адреса 256 одинарных косвенных блоков, каждый из которых
содержит адреса 256 блоков данных. Такая схема позволяет поддерживать файлы раз-
мером до 10 + 216 блоков (67 119 104 байт). Если и этого оказывается недостаточно, то
в i-узле есть место для тройного косвенного блока (triple indirect block) . Его указатели
показывают на множество двойных косвенных блоков. Такая схема адресации позволя-
ет работать с размерами файлов до 224 блоков по 1 Кбайт (это 16 Гбайт). При размере
блоков в 8 Кбайт такая схема адресации поддерживает файлы размером до 64 Тбайт.
Файловая система Ext4 в Linux
Для предотвращения потерь данных после сбоев системы и отказов электропитания
файловой системе ext2 пришлось бы записывать каждый блок данных на диск немед-
ленно после его создания. Вызванные перемещением головок записи задержки были
бы такими значительными, что производительность стала бы недопустимо низкой.
Поэтому записи откладываются, и изменения могут находиться в не зафиксированном
на диске состоянии до 30 с, что является очень длинным (для современного компью-
терного оборудования) промежутком времени.
Для повышения живучести файловой системы Linux использует журналируемые
файловые системы
(journaling file systems). Примером такой системы является ext3 —
продолжательница файловой системы ext2. Продолжательница ext3, файловая система
ext4
, также является журналируемой, но в отличие от ext3 она изменяет схему адре-
сации блоков, используемую своими предшественницами, поддерживая за счет этого
как более объемные файлы, так и в целом более объемную файловую систему. Далее
будет дано описание некоторых ее свойств.
Основная идея такого типа файловой системы состоит в поддержке журнала, который
в последовательном порядке описывает все операции файловой системы. При такой
последовательной записи изменений в данных файловой системы или ее метаданных
(i-узлах, суперблоке и т. д.) операции записи не страдают от издержек перемещения
дисковых головок (во время случайных обращений к диску). В итоге изменения запи-
сываются (фиксируются) в соответствующее место на диске — и соответствующие им
записи журнала можно удалить. Если же до фиксации изменений происходит систем-
ный сбой или отказ электропитания, то при последующем запуске система обнаружит,
что файловая система не была должным образом размонтирована, просмотрит журнал
и выполнит все (описанные в журнале) изменения в файловой системе.

10.6. Файловая система UNIX
865
Ext4 спроектирована таким образом, чтобы быть в значительной степени совместимой
с ext2 и ext3, хотя основные структуры данных и компоновка диска претерпели из-
менения. Но, несмотря на это, размонтированная файловая система ext2 может быть
затем смонтирована как система ext4 и обеспечивать журналирование.
Журнал — это файл, с которым работают как с кольцевым буфером. Журнал может
храниться как на том же устройстве, что и основная файловая система, так и на другом.
Поскольку операции с журналом не журналируются, файловая система ext4 с ними не
работает. Для выполнения операций чтения/записи в журнал используется отдельное
блочное устройство журналирования JBD (Journaling Block Device).
JBD поддерживает три основные структуры данных: запись журнала (log record), опи-
сатель атомарной операции (atomic operation handle), транзакцию (transaction). Запись
журнала описывает операцию низкого уровня в файловой системе (которая обычно
приводит к изменениям внутри блока). Поскольку системный вызов (такой, как write)
обычно приводит к изменениям во многих местах — i-узлах, блоках существующих
файлов, новых блоках файлов, списке свободных блоков и т. д., — соответствующие
записи журнала группируются в атомарные операции. Ext4 уведомляет JBD о на-
чале и конце обработки системного вызова (чтобы устройство JBD могло обеспечить
фиксацию либо всех записей журнала данной атомарной операции, либо никаких).
И наконец, в основном из соображений эффективности JBD обрабатывает коллекции
атомарных операций как транзакции. В транзакции записи журнала хранятся после-
довательно. JBD позволяет удалять фрагменты файла журнала только после того, как
все принадлежащие к транзакции записи журнала надежно зафиксированы на диске.
Поскольку запись элемента журнала для каждого изменения диска может быть до-
рогой, то ext4 можно настроить таким образом, чтобы она хранила журнал либо всех
изменений на диске, либо только тех изменений, которые относятся к метаданным
файловой системы (i-узлы, суперблоки, битовые массивы и т. д.). Журналирование
только метаданных снижает издержки системы и повышает производительность, но
не защищает от повреждения данные в файлах. Некоторые другие журнальные фай-
ловые системы ведут журналы только для операций с метаданными (например, XFS
в SGI). Кроме того, надежность журнала может быть повышена за счет использования
контрольных сумм.
Основным изменением в ext4 по сравнению с ее предшественниками является ис-
пользование экстентов. Экстенты представляют собой непрерывные блоки хранилища:
например, 128 Мбайт непрерывных 4-килобайтовых блоков в противовес индивиду-
альным блокам хранения, указываемым в ext2. В отличие от предшественников, в ext4
для каждого блока хранилища операции с метаданными не требуются. Эта схема также
сокращает фрагментацию длинных файлов. В результате ext4 может обеспечить более
быстрые операции файловой системы и поддержку более объемных файлов и более
крупных размеров файловой системы. Например, для размера блока в 1 Кбайт ext4
увеличивает максимальный размер файла с 16 Гбайт до 16 Тбайт, а максимальный
размер файловой системы — до 1 Эбайт (экзабайт).
Файловая система /proc
Еще одна файловая система Linux — это /proc (process — процесс). Идея этой файловой
системы изначально была реализована в 8-й редакции операционной системы UNIX,
созданной лабораторией Bell Labs, а позднее скопирована в версиях 4.4BSD и System V.