Добавлен: 29.10.2018
Просмотров: 48000
Скачиваний: 190

1.8. Устройство мира согласно языку C
101
#define max(a, b) (a > b?a:b)
позволяющие программисту написать
i = max(j, k+1)
и в результате получить
i = (j > k+1 ? j : k+1)
для сохранения большего значения из j и k + 1 в переменной i. В заголовочных файлах
могут также содержаться условия компиляции, например:
#ifdef X86
Intel_int_ack();
#endif
которые при компиляции превращаются в вызов функции intel_int_ack, если определен
макрос X86, и ни во что не превращаются в противном случае. Условная компиляция
широко используется для изоляции архитектурно-зависимого фрагмента программы,
чтобы определенный код вставлялся только в том случае, если система компилируется
на x86, а другой код — только в том случае, если система компилируется на SPARC,
и т. д. Благодаря использованию директивы #include файл с расширением
.c
может
в конечном счете включать в себя произвольное количество заголовочных файлов на-
чиная с нуля. Также существует множество заголовочных файлов, общих практически
для всех файлов с расширением
.c
. Такие файлы хранятся в определенном каталоге.
1.8.3. Большие программные проекты
Для создания операционной системы каждый файл с расширением
.c
с помощью ком-
пилятора C превращается в объектный файл. Объектные файлы, имеющие имена, за-
канчивающиеся символами
.o
(
.o
-файлы), содержат двоичные инструкции для целевой
машины. Позже они будут непосредственно выполняться центральным процессором.
В мире C нет ничего подобного байтовому коду Java или Pyton.
Первый проход компилятора C называется препроцессором C. По мере чтения каж-
дого файла с расширением
.c
при каждой встрече директивы #include он переходит
к указанному в этой директиве заголовочному файлу, обрабатывает его содержимое,
расширяя макросы и управляя условной компиляцией (и другими определенными
вещами), и передает результаты следующему проходу компилятора, как будто они
были физически включены в
.c
-файл.
Поскольку операционная система имеет очень большой объем (нередко составляющий
порядка 5 000 000 строк), необходимость постоянной перекомпиляции всего кода
при внесении изменений всего лишь в один файл была бы просто невыносимой. В то
же время изменение ключевого заголовочного файла, включенного в тысячи других
файлов, требует перекомпиляции всех этих файлов. Отслеживать зависимости тех
или иных объектных файлов от определенных заголовочных файлов без посторонней
помощи невозможно.
К счастью, компьютеры прекрасно справляются именно с задачами такого рода. В UNIX-
системах есть программа под названием make (имеющая многочисленные варианты,
например gmake, pmake и т. д.), читающая файл
Makefile
, в котором описываются зависи-
мости одних файлов от других. Программа make работает следующим образом. Сначала
она определяет, какие объектные файлы, необходимые для создания двоичного файла
102
Глава 1. Введение
операционной системы, нужны именно сейчас. Затем для каждого из них проверяет,
были ли изменены со времени последнего создания объектного файла какие-нибудь
файлы (заголовочные файлы или файлы основного текста программ), от которых объ-
ектный файл зависит. Если такие изменения были, этот объектный файл должен быть
перекомпилирован. Когда программа make определит, какие файлы с расширением
.c
должны быть перекомпилированы, она вызывает компилятор C для их перекомпиляции,
сокращая таким образом количество компиляций до необходимого минимума. В боль-
ших проектах при создании
Makefile
трудно избежать ошибок, поэтому существуют
средства, которые делают это автоматически.
Когда все файлы с расширением
.o
будут готовы, они передаются программе, которая
называется компоновщиком. Эта программа объединяет все эти файлы в один исполня-
емый двоичный файл. На этом этапе также добавляются все вызываемые библиотечные
функции, разрешаются все ссылки между функциями и перемещаются на нужные места
машинные адреса. Когда компоновщик завершает свою работу, на выходе получается
исполняемая программа, которая в UNIX-системах традиционно называется a.out.
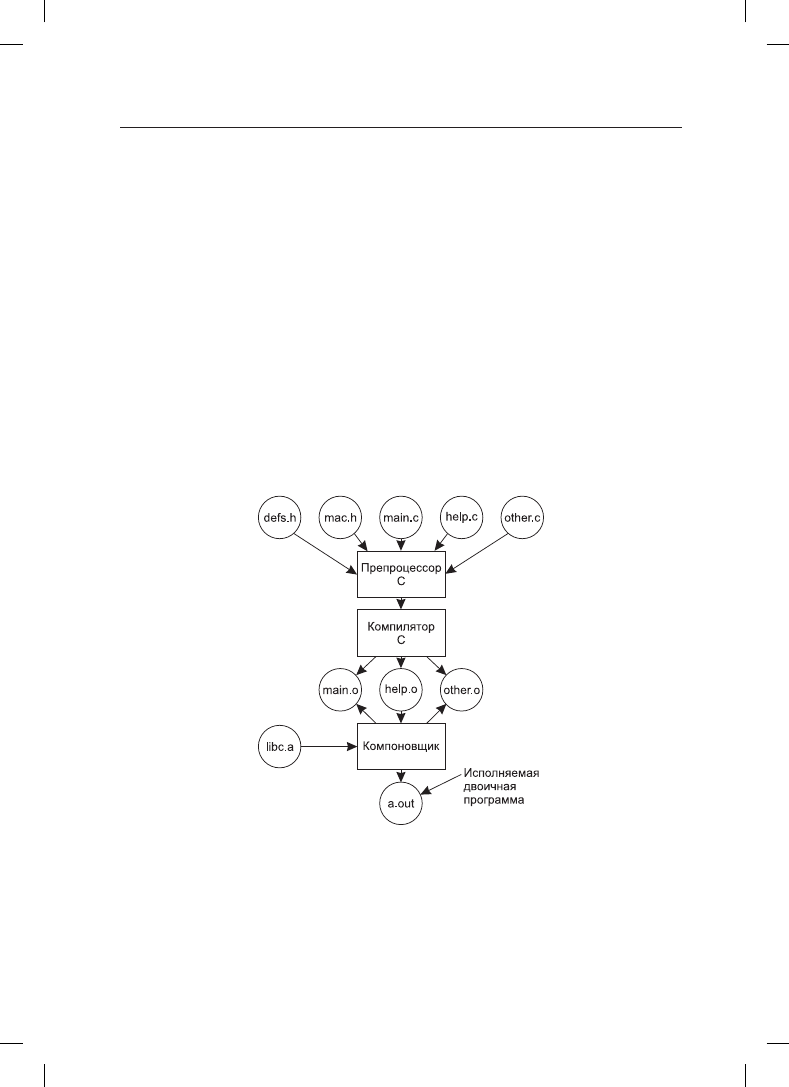
Последовательность этапов процесса получения исполняемого файла для программы,
состоящей из трех файлов исходных текстов на языке C и двух заголовочных файлов,
показана на рис. 1.26. Несмотря на то что здесь мы рассматриваем разработку операци-
онной системы, все это применимо к процессу разработки любой большой программы.
Рис. 1.26. Процесс получения исполняемого файла из программы на языке С и заголовочных
файлов: обработка препроцессором, компиляция, компоновка
1.8.4. Модель времени выполнения
Как только будет выполнена компоновка двоичного файла операционной системы,
компьютер может быть перезапущен с загрузкой новой операционной системы. По-
сле запуска операционная система может в динамическом режиме подгружать те

1.9. Исследования в области операционных систем
103
части, которые не были статически включены в двоичный файл, например драйверы
устройств и файловые системы. Во время выполнения операционная система может
состоять из множества сегментов: для текста (программного кода), данных и стека.
Сегмент текста обычно является постоянным, не изменяясь в процессе выполнения.
Сегмент данных с самого начала имеет определенный размер и проинициализирован
конкретными значениями, но если потребуется, он может изменять размер (обычно
разрастаться при необходимости). Стек сначала пустует, но затем он увеличивается
и сокращается по мере вызова функций и возвращения из них. Чаще всего сегмент тек-
ста помещается в районе младших адресов памяти, сразу над ним располагается сегмент
данных, который может расти вверх, а в старшем виртуальном адресе находится сег-
мент стека, способный расти вниз. Тем не менее разные системы работают по-разному.
В любом случае, код операционной системы выполняется непосредственно компью-
терным оборудованием, не подвергаясь интерпретации и just-in-time-компиляции
(то есть компиляции по мере необходимости), являющихся обычными технологиями
при работе с Java.
1.9. Исследования в области
операционных систем
Информатика и вычислительная техника — это быстро прогрессирующая область,
направления развития которой довольно трудно предсказать. Исследователи в универ-
ситетах и промышленных научно-исследовательских лабораториях постоянно выдают
новые идеи, часть из которых не получают дальнейшего развития, а другие становятся
основой будущих продуктов и оказывают существенное влияние на промышленность
и пользователей. Сказать, какие именно проявят себя в этой роли, можно только по
прошествии времени. Отделить зерна от плевел особенно трудно, поскольку порой
проходит 20–30 лет между зарождением идеи и ее расцветом.
Например, когда президент Эйзенхауэр учредил в 1958 году в Министерстве обороны
США управление перспективных исследований и разработок — Advanced Research
Projects Agency (ARPA), он пытался воспрепятствовать уничтожению флота и ВВС
и предоставил Пентагону средства на исследования. Он вовсе не планировал изобрести
Интернет. Но одной из сторон деятельности ARPA было выделение ряду университетов
средств на исследования в неизученной области пакетной коммутации, которые привели
к созданию первой экспериментальной сети с пакетной коммутацией — ARPANET. Она
появилась в 1969 году. Вскоре к ARPANET подключились другие исследовательские сети,
финансируемые ARPA, в результате чего родился Интернет. Затем Интернет в течение
20 лет успешно использовался для обмена сообщениями по электронной почте в академи-
ческой исследовательской среде. В начале 1990-х годов Тим Бернерс-Ли (Tim Berners-Lee)
из исследовательской лаборатории CERN в Женеве изобрел Всемирную паутину —World
Wide Web, а Марк Андресен (Marc Andreesen) из университета Иллинойса создал для
нее графический браузер. Неожиданно для всех Интернет заполонили общающиеся под-
ростки, чего явно не планировал Эйзенхауэр (он бы в гробу перевернулся, узнав об этом).
Исследования в области операционных систем также привели к существенным изме-
нениям в используемых системах. Ранее упоминалось, что все первые коммерческие
компьютерные системы были системами пакетной обработки до тех пор, пока в начале
1960-х в Массачусетском технологическом институте не изобрели интерактивную си-

104
Глава 1. Введение
стему с разделением времени. Все компьютеры работали только в текстовом режиме,
пока в конце 1960-х Даг Энгельбарт (Doug Engelbart) из Стэнфордского исследова-
тельского института не изобрел мышь и графический пользовательский интерфейс.
Кто знает, что появится вслед за всем этим?
В этом разделе, а также в соответствующих разделах книги мы кратко опишем некото-
рые из исследований в области операционных систем, которые проводились в течение
последних 5–10 лет, чтобы дать представление о том, что может появиться в будущем.
Это введение не претендует на полноту и основано главным образом на материалах,
опубликованных в рамках конференций по передовым исследованиям, поскольку пред-
ставленные идеи успешно преодолели перед публикацией по крайней мере жесткий про-
цесс рецензирования со стороны специалистов. Следует заметить, что в компьютерной
науке, в отличие от других научных сфер, основная часть исследований публикуется на
конференциях, а не в журналах. Большинство статей, цитируемых в разделах, посвящен-
ных исследованиям, были опубликованы ACM, IEEE Computer Society или USENIX
и доступны в Интернете для членов этих организаций. Более подробная информация
об этих организациях и их электронных библиотеках находится на следующих сайтах:
ACM —
http://www.acm.org
IEEE Computer Society —
http://www.computer.org
USENIX —
http://www.usenix.org
Практически все исследователи понимают, что существующие операционные системы
излишне громоздки, недостаточно гибки, ненадежны, небезопасны и в той или иной
степени содержат ошибки (но не будем переходить на личности). Поэтому естественно,
что огромное количество исследований посвящено тому, как создать более совершен-
ные операционные системы. Недавно опубликованные работы касались, кроме всего
прочего, ошибок и отладки (Renzelmann et al., 2012; Zhou et al., 2012), восстановления
после аварии (Correia et al., 2012; Ma et al., 2013; Ongaro et al., 2011; Yeh and Cheng, 2012),
управления электропитанием (Pathak et al., 2012; Petrucci and Loques, 2012; Shen et al.,
2013), файлов и систем хранения (Elnably and Wang, 2012; Nightingale et al., 2012; Zhang
et al., 2013), высокопроизводительного ввода-вывода (De Bruijn et al., 2011; Li et al.,
2013; Rizzo, 2012), гипер- и многопоточности (Liu et al., 2011), оперативного обновления
(Giuffrida et al., 2013), управления графическими процессорами (Rossbach et al., 2011),
управления памятью (Jantz et al., 2013; Jeong et al., 2013), многоядерных операционных
систем (Baumann et al., 2009; Kapritsos, 2012; Lachaize et al., 2012; Wentzlaff et al., 2012),
корректности операционных систем (Elphinstone et al., 2007; Yang et al., 2006; Klein et
al., 2009), надежности операционных систем (Hruby et al., 2012; Ryzhyk et al., 2009, 2011;
Zheng et al., 2012), конфиденциальности и безопасности (Dunn et al., 2012; Giuffrida et
al., 2012; Li et al., 2013; Lorch et al., 2013; Ortolani and Crispo, 2012; Slowinska et al., 2012;
Ur et al., 2012), мониторинга использования и производительности (Harter et al., 2012;
Ravindranath et al., 2012), а также виртуализации (Agesen et al., 2012; Ben-Yehuda et al.,
2010; Colp et al., 2011; Dai et al., 2013; Tarasov et al., 2013; Williams et al., 2012).
1.10. Краткое содержание остальных
глав этой книги
На этом мы завершаем введение и рассмотрение операционных систем с высоты
птичьего полета. Настала пора перейти к подробностям. Как уже говорилось, с точки

1.11. Единицы измерения
105
зрения программиста главной целью операционной системы является предоставле-
ние ряда ключевых абстракций, самые важные из которых — это процессы и потоки,
адресные пространства и файлы. Соответственно следующие три главы посвящены
этим весьма важным темам.
Глава 2 посвящена процессам и потокам. В ней рассматриваются их свойства и порядок
связи друг с другом. Здесь содержится также ряд подробных примеров, показывающих,
как организовать работу взаимосвязанных процессов и обойти встречающиеся на этом
пути подводные камни.
В главе 3 мы подробно изучим адресные пространства и все, что с ними связано, а также
систему управления памятью. Будут рассмотрены весьма важная тема виртуальной
памяти и тесно связанные с ней понятия разбиения на страницы и сегментации памяти.
В главе 4 мы займемся крайне важной темой файловых систем. В определенной мере
все, что видит пользователь, в основном относится к файловой системе. Будут рас-
смотрены интерфейс файловой системы и ее реализация.
В главе 5 рассматриваются вопросы ввода-вывода информации. Будет уделено внима-
ние понятиям независимости и зависимости устройств. В качестве примеров исполь-
зован ряд важных устройств: диски, клавиатуры и дисплеи.
Глава 6 посвящена взаимным блокировкам. В этой главе будет коротко показана суть
взаимных блокировок, но разговор о них этим не ограничится. Будут рассмотрены пути
предотвращения взаимных блокировок и способы уклонения от них.
На этом мы завершим изучение основных принципов построения однопроцессорных
операционных систем. Но тема этим не исчерпывается, особенно если говорить о рас-
ширенных возможностях. В главе 7 мы рассмотрим виртуализацию. Речь пойдет как
о принципах, так и о подробностях некоторых сущестующих виртуализационных
решений. Поскольку виртуализация широко используется в облачных вычислениях,
мы также посмотрим на существующие облака. Другая перспективная тема касается
многопроцессорных систем, включая многоядерные и параллельные компьютеры,
а также распределенные системы. Все это будет рассмотрено в главе 8.
Чрезвычайно важной темой является безопасность операционной системы. Она будет
рассмотрена в главе 9. Вопросами, обсуждаемыми в этой главе, станут различные угро-
зы (например, вирусы и черви), механизмы защиты и модели безопасности.
Затем мы займемся изучением практических примеров операционных систем. Будут
рассмотрены UNIX, Linux и Android (глава 10) и Windows 8 (глава 11). Ну а глава 12
станет закономерным итогом, в ней изложен ряд соображений и размышлений по по-
воду проектирования операционных систем.
1.11. Единицы измерения
Во избежание путаницы стоит особо отметить, что в этой книге, как и во всей ком-
пьютерной науке, вместо традиционных английских единиц измерения используют-
ся единицы метрической системы. Основные метрические приставки перечислены
в табл. 1.4. Обычно приставки сокращаются до первых букв, причем если единица
измерения больше 1, используются заглавные буквы. Например, база данных раз-
мером 1 Тбайт занимает на диске около 10
12
байт, а часы с интервалом в 100 пс будут
тикать каждые 10
–10
с. Так как приставки милли- и микро- начинаются с буквы «м»,