Добавлен: 29.10.2018
Просмотров: 47972
Скачиваний: 190

1076
Глава 12. Разработка операционных систем
кухню, договоры с компаниями, продающими товары по кредитным карточкам, и т. д.
Политика, то есть что будет в меню, определяется шеф-поваром. Если шеф-повар
решит, что тофу кончился, а большие бифштексы остались, то новая политика может
быть выполнена существующим механизмом.
Теперь рассмотрим некоторые примеры из области операционных систем. Прежде
всего взглянем на планирование потоков. В ядре может располагаться приоритетный
планировщик с k уровнями приоритетов. Этот механизм представляет собой массив,
проиндексированный уровнем приоритета, как в UNIX и Windows 8. Каждый элемент
массива представляет собой заголовок списка готовых потоков с данным уровнем
приоритета. Планировщик просто просматривает массив, начиная с максимального
приоритета, выбирая первый подходящий поток. Политика заключается в установ-
ке приоритетов. В системе могут быть различные классы пользователей: например,
у каждого пользователя может быть свой приоритет. Система может также позволять
процессам устанавливать относительные приоритеты для своих потоков. Приоритеты
могут увеличиваться после завершения операции ввода-вывода или уменьшаться, когда
процесс истратил отпущенный ему квант. Может применяться и еще множество других
политических подходов, но основной принцип состоит в разделении между установкой
политики и претворением ее в жизнь.
Вторым примером является страничная подкачка. Механизм включает в себя управ-
ление блоком MMU, поддержку списка занятых и свободных страниц, а также про-
грамму для перемещения страниц с диска в память и обратно. Политика в данном
случае заключается в принятии решения о выполняемых действиях при возникновении
страничного прерывания. Политика может быть локальной или глобальной, основы-
ваться на алгоритме LRU, FIFO или каком-либо другом, но она может (и должна) быть
полностью отделена от механики фактической работы со страницами.
Третий пример — возможность загрузки модулей в ядро. Механизм определяет то, как
они устанавливаются в ядро, как связываются, к каким вызовам могут обращаться
и какие вызовы могут сами предоставлять. Политика определяет список пользовате-
лей, которым разрешается загружать модуль в ядро, а также список модулей, которые
разрешается загружать каждому пользователю. Возможно, только суперпользователь
может загружать модули, но разрешение загружать модули может предоставляться
любому пользователю, если у модуля есть цифровая подпись соответствующей авто-
ритетной организации.
12.3.3. Ортогональность
Хорошая системная организация включает в себя отдельные концепции, которые
можно независимо смешивать. Например, в языке C есть примитивные типы данных,
включающие целые, символьные числа и числа с плавающей точкой. Существуют
механизмы для комбинирования типов данных, включая массивы, структуры и объ-
единения. Эти концепции независимы друг от друга, что позволяет создавать целые
массивы, символьные массивы, массивы структур, структуры, состоящие из массивов,
и т. д. Действительно, как только определен новый тип данных, например массив целых
чисел, он может использоваться в качестве члена структуры или объединения, как
если бы был примитивным типом данных. Возможность независимо комбинировать
раздельные концепции называется ортогональностью . Это свойство является прямым
следствием простоты и полноты принципов.

12.3. Реализация
1077
Понятие ортогональности также встречается в операционных системах в различных
формах. Одним из примеров является системный вызов clone операционной системы
Linux, создающий новый поток. В качестве параметра этот вызов принимает битовый
массив, задающий такие режимы, как независимое друг от друга совместное исполь-
зование или копирование адресного пространства, рабочего каталога, дескрипторов
файлов и сигналов. Если копируется всё, то мы получаем новый процесс, как и при
использовании системного вызова fork. Если ничего не копируется, это означает, что
создается новый поток в текущем процессе. Однако вероятно и создание промежуточ-
ных форм, невозможных в традиционных системах UNIX. Разделение свойств и их
ортогональность позволяют получить более детальную степень управления.
Другое применение ортогональности — разделение понятий процесса и потока
в Windows 8. Процесс представляет собой контейнер для ресурсов, не более и не ме-
нее. Поток представляет собой объект планирования. Когда один процесс получает
дескриптор от другого процесса, не имеет значения, сколько у него потоков. Когда
планировщик выбирает поток, неважно, какому процессу он принадлежит. Эти по-
нятия ортогональны.
Наш последний пример ортогональности возьмем из операционной системы UNIX.
Создание процесса происходит здесь в два этапа: при помощи системных вызовов fork
и exec. Создание нового адресного пространства и заполнение его новым образом памя-
ти в данном случае разделены, что позволяет выполнить определенные действия между
этими этапами. В операционной системе Windows 8 эти два этапа нельзя разделить,
то есть концепции создания нового адресного пространства и его заполнения новым
образом памяти не являются ортогональными в этой системе. Последовательность
системных вызовов clone и exec в системе Linux является еще более ортогональной,
так как в данном случае возможно еще более детальное управление этими действиями.
Общее правило может быть сформулировано следующим образом: наличие небольшого
количества ортогональных элементов, которые могут комбинироваться различными
способами, позволяет создать небольшую простую и элегантную систему.
12.3.4. Именование
У большинства долгоживущих структур данных, используемых операционной систе-
мой, есть имя или идентификатор, по которым к ним можно обращаться. Среди оче-
видных примеров можно назвать регистрационные имена, имена файлов, устройств,
идентификаторов процессов и т. д. Способ создания и использования этих имен пред-
ставляет собой важный вопрос при проектировании и реализации системы.
Имена, создаваемые для использования их людьми, представляют собой символьные
строки формата ASCII или Unicode и, как правило, являются иерархическими. Так,
иерархия отчетливо видна на примере путей файлов. Например, путь
/usr/ast/books/
mos2/chap-12
состоит из имен каталогов, поиск которых следует начинать в корневом
каталоге. Адреса URL также являются иерархическими. Например, URL
www.cs.vu.
nl/~ast/
указывает на определенную машину (
www
) определенного факультета (
cs
)
определенного университета (
vu
) определенной страны (
nl
). Участок URL после слеша
обозначает определенный файл на указанной машине, в данном случае по умолчанию
это файл
www/index.html
в домашнем каталоге пользователя
ast
. Обратите внимание на
то, что URL (а также адреса DNS вообще, включая адреса электронной почты) пишутся
«задом наперед», начинаясь с нижнего уровня дерева, в отличие от имен файлов, на-
1078
Глава 12. Разработка операционных систем
чинающихся с вершины дерева. На это можно взглянуть и по-другому, если положить
дерево горизонтально. При этом в одном случае дерево будет начинаться слева и расти
направо, а в другом случае, наоборот, будет начинаться справа и расти влево.
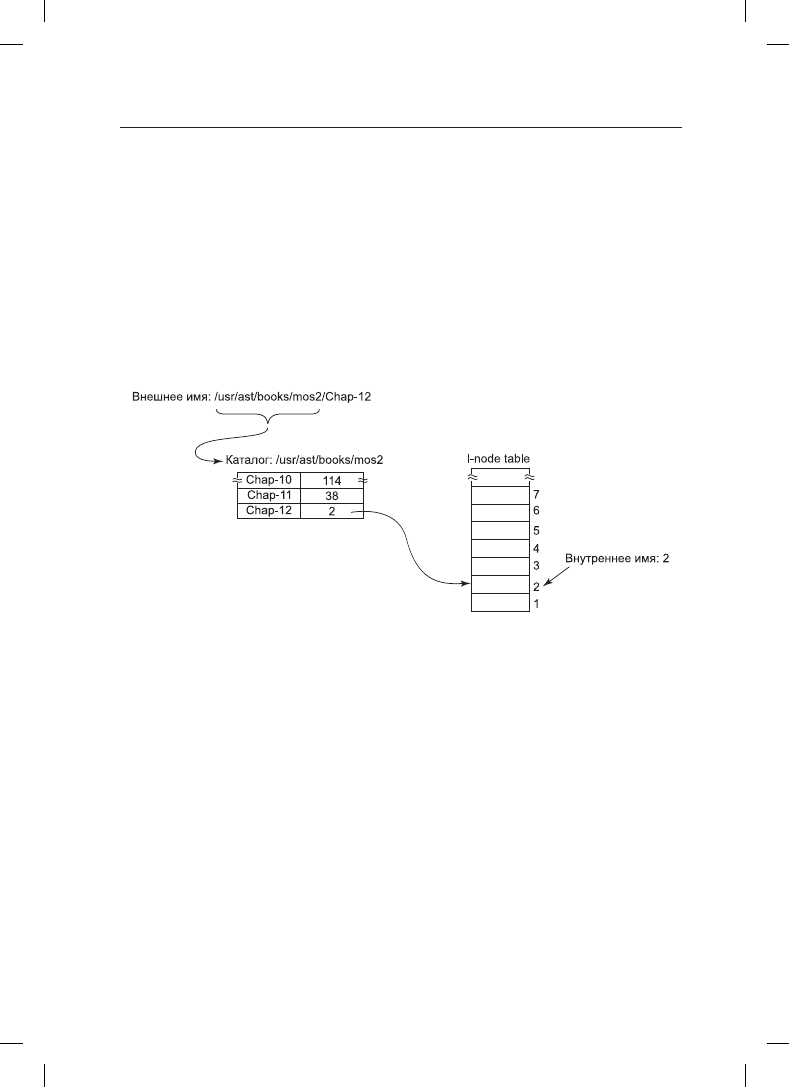
Часто используется двухуровневое именование: внешнее и внутреннее. Например,
к файлам всегда можно обратиться по имени, представляющему собой символьную
строку в ASCII или Unicode, чтобы их было удобнее использовать людям. Кроме этого,
почти всегда существует внутреннее имя, используемое системой. В операционной
системе UNIX реальным именем файла является номер его i-узла. Имя в формате
ASCII вообще не используется внутри системы. В действительности это имя даже не
является уникальным, так как на файл может указывать несколько ссылок. А в опе-
рационной системе Windows 8 в качестве внутреннего имени используется индекс
файла в таблице MFT. Работа каталога заключается в преобразовании внешних имен
во внутренние (рис. 12.3).
Рис. 12.3. Каталоги используются для преобразования внешних имен во внутренние
Во многих случаях (таких, как приведенный ранее пример с именем файла) внутреннее
имя файла представляет собой уникальное целое число, служащее индексом в таблице
ядра. Другие примеры имен-индексов — дескрипторы файлов в системе UNIX и де-
скрипторы объектов в Windows 8. Обратите внимание на то, что ни у одного из данных
примеров имен нет внешнего представления. Они предназначены исключительно для
внутреннего использования системой и работающими процессами. В целом использо-
вание для временных имен табличных индексов, не сохраняющихся после перезагрузки
системы, является удачным замыслом.
Операционные системы часто поддерживают несколько пространств имен, как внеш-
них, так и внутренних. Например, в главе 11 мы рассмотрели три внешних пространства
имен, поддерживаемых операционной системой Windows 8: имена файлов, имена объ-
ектов и регистрационные имена (существует также пространство имен Active Directory,
которое мы не обсуждали). Кроме того, существует бесчисленное количество внутрен-
них пространств имен, для которых используются целые числа без знака, — дескрипто-
ры объектов, записи таблицы MFT и т. д. Хотя имена во внешних пространствах имен
представляют собой строки формата Unicode, поиск файла по имени в реестре не будет
работать, как не будет работать и попытка использования индекса MFT в таблице объ-
ектов. В правильно спроектированной операционной системе обязательно уделяется

12.3. Реализация
1079
определенное внимание тому, сколько требуется пространств имен, какой синтаксис
используется в каждом из них, как можно отличить одно от другого, существуют ли
абсолютные и относительные имена и т. д.
12.3.5. Время связывания
Как мы видели, для обращения к объектам в операционных системах используются
различные типы имен. Иногда преобразование имени в объект является фиксирован-
ным, а иногда — нет. В последнем случае может быть важным, когда имя связывается
с объектом. Вообще говоря, раннее связывание проще, но не обладает гибкостью, тогда
как позднее связывание сложнее, зато часто является более гибким.
Чтобы внести ясность в понятие времени связывания, давайте рассмотрим примеры
из реального мира. Примером раннего связывания может быть практика некоторых
колледжей, позволяющих родителям зачислять своего ребенка в колледж с момента
рождения и вносить плату за его обучение заранее. Когда спустя 18 лет студент при-
ходит в колледж, его обучение уже полностью оплачено независимо от стоимости
обучения на данный момент.
В промышленности ранним связыванием является заказ деталей заранее. Напротив,
производство продукта точно в срок требует от поставщиков способности предостав-
лять требуемые детали прямо на месте, без предварительного заказа. Такая схема пред-
ставляет собой пример позднего связывания.
Языки программирования часто поддерживают различные виды связывания для
переменных. Глобальные переменные связывает с конкретным виртуальным адресом
компилятор. Это пример раннего связывания. Локальным переменным процедуры вир-
туальные адреса назначаются (в стеке) во время выполнения процедуры. Это пример
промежуточного связывания. Переменным, хранящимся в куче (память для которых
выделяется при помощи процедуры malloc в программах на языке C или процедуры new
в программах на языке Java), виртуальный адрес назначается только на время их фак-
тического использования. Это пример позднего связывания.
Для большей части структур данных в операционных системах чаще применяется
раннее связывание, но иногда для гибкости используется позднее связывание. К этому
вопросу имеет отношение выделение памяти. В ранних многозадачных системах из-
за отсутствия аппаратной перенастройки адресов приходилось загружать программу
по определенному адресу памяти и настраивать ее на работу по этому адресу. Если
эта программа когда-либо выгружалась на диск, ее нужно было потом загрузить в те
же адреса памяти, в противном случае она не могла работать. Напротив, виртуальная
память с постраничной подкачкой представляет собой пример позднего связывания.
Фактический физический адрес, соответствующий данному виртуальному адресу, не
известен до тех пор, пока страница не будет физически перенесена в память.
Другим примером позднего связывания является размещение окна в графическом
интерфейсе пользователя. В отличие от старых графических систем, в которых про-
граммист должен был указывать абсолютные экранные координаты для всех изображе-
ний, в современных графических интерфейсах пользователя программное обеспечение
использует координаты относительно исходного окна. Такие координаты не известны
до тех пор, пока это окно не будет выведено на экран, и даже могут быть со временем
изменены.

1080
Глава 12. Разработка операционных систем
12.3.6. Статические и динамические структуры
Разработчики операционных систем постоянно вынуждены выбирать между статиче-
скими и динамическими структурами данных . Статические структуры всегда проще
для понимания, легче для программирования и быстрее в использовании. Динами-
ческие структуры обладают большей гибкостью. Очевидный пример — таблица про-
цессов. В ранних системах для каждого процесса просто выделялся фиксированный
массив структур. Если таблица процесса состояла из 256 элементов, то в любой момент
могло существовать не более 256 процессов. Попытка создания 257-го процесса закан-
чивалась неудачей по причине отсутствия места в таблице. Аналогичные соображения
были справедливы для таблицы открытых файлов (как для каждого пользователя в от-
дельности, так и для системы в целом) и различных других таблиц ядра.
Альтернативная стратегия заключается в создании таблицы процессов в виде связного
списка мини-таблиц, начиная с одной-единственной мини-таблицы. Когда эта таблица
заполняется, в глобальном пуле выделяется память под следующую таблицу, которая
связывается с первой таблицей. Таким образом, таблица процесса не переполнится,
пока не закончится вся память у ядра.
В то же время использование связных списков приводит к усложнению программы
поиска записей в таблице. Например, программа для поиска идентификатора процесса
pid в статической таблице процессов показана в листинге 12.2. Эта программа проста
и эффективна. Чтобы выполнить ту же задачу для связного списка мини-таблиц, по-
требуется больше работы.
Листинг 12.2. Программа для поиска в таблице идентификатора процесса
found = 0;
for (p = &proc_table[0]; p < &proc_table[PROC_TABLE_SIZE]; p++) {
if (p->proc_pid == pid) {
found = 1;
break;
}
}
Статические таблицы лучше всего использовать, когда имеется много памяти или когда
заранее можно довольно точно предсказать размер таблицы. Например, в однополь-
зовательской системе маловероятно, что пользователь запустит одновременно более
128 процессов, и поэтому не случится катастрофы, если пользователю будет отказано
в запуске 129-го процесса.
Альтернативный метод заключается в использовании таблицы фиксированного раз-
мера, но с выделением, когда эта таблица заполнится, новой таблицы фиксированного
размера, например, в два раза большей. При этом текущие записи копируются из старой
таблицы в новую, а память, которая была занята старой таблицей, возвращается в пул.
Таким образом, таблица всегда остается непрерывной, а не связной. Недостаток этого
подхода состоит в том, что требуется определенное управление памятью, кроме того,
адрес таблицы будет переменным вместо константы.
То же самое относится к стекам ядра. Когда поток переключается из пользователь-
ского режима в режим ядра или когда запускается поток в режиме ядра, этому потоку
требуется стек в адресном пространстве ядра. Для потоков пользователя стек можно
инициализировать так, чтобы он рос вниз от вершины виртуального адресного про-