Добавлен: 29.10.2018
Просмотров: 47968
Скачиваний: 190

12.4. Производительность
1091
Лозунг, применимый к оптимизации производительности, мог бы звучать так: «Луч-
шее — враг хорошего».
Под этим мы подразумеваем, что как только удается достичь приемлемого уровня про-
изводительности, то попытки выжать последние несколько процентов, видимо, уже не
стоят затрачиваемых усилий и усложнения программы. Если алгоритм планирования
достаточно хорош и обеспечивает 90 %-ную загрузку центрального процессора, воз-
можно, этого достаточно. Разработка значительно более сложного алгоритма, на 5 %
лучше имеющегося, не всегда представляет собой удачную идею. Аналогично если
частота подкачки страниц довольно низка, то есть подкачка не является узким местом,
то, как правило, нет смысла лезть из кожи вон, чтобы добиться оптимальной произ-
водительности. Недопущение сбоев в работе системы представляется намного более
важной задачей, нежели достижение оптимальной производительности, особенно
если алгоритм, оптимальный при одном уровне загруженности компьютера, может
оказаться неоптимальным при другом уровне. Другим вопросом является такой: что
оптимизировать и когда? Некоторые программисты, как только что-либо заработает,
стремятся оптимизировать абсолютно все, что они разрабатывают. Проблема в том, что
после оптимизации система может стать менее понятной и более сложной для обслу-
живания и отладки. Кроме того, ее будет труднее адаптировать, а позднее, возможно,
оптимизировать удачнее. Эта проблема называется преждевременной оптимизацией.
Дональд Кнут, которого иногда называют отцом анализа алгоритмов, однажды сказал:
«Преждевременная оптимизация является корнем всех зол».
12.4.3. Выбор между оптимизацией по скорости
и по занимаемой памяти
При увеличении производительности программы приходится идти на компромисс
между сокращением времени выполнения программы и увеличением занимаемой ею
памяти. Программисты часто оказываются перед выбором между медленным, но ком-
пактным алгоритмом и более быстрым, но занимающим значительно больше памяти.
Занимаясь важной оптимизацией, следует искать алгоритмы, дающие увеличение
скорости за счет использования большего объема памяти или, наоборот, сберегающие
драгоценную память за счет выполнения большего количества вычислений.
Иногда может быть полезен метод, заключающийся в замене небольших процедур ма-
кросами. Использование макроса устраняет накладные расходы, связанные с вызовом
процедуры. Выигрыш оказывается особенно существенным, если процедура вызывает-
ся многократно в цикле. Например, предположим, что мы используем битовый массив
для учета ресурсов и нам часто приходится узнавать, сколько единиц свободно в неко-
торой области битового массива. Для этой цели нужна процедура bit_count, считающая
количество единичных битов в байте. Простая процедура показана в листинге 12.4, а.
Эта процедура в цикле перебирает биты в байте, считая их по одному на каждом цикле.
Все довольно просто и понятно.
Листинг 12.4. а — процедура для подсчета битов в байте; б — макрос для подсчета
битов; в — макрос для поиска числа битов в таблице
#define BYTE_SIZE 8 /* Байт содержит 8 бит */
int bit_count(int byte)
{ /* Подсчет битов в байте */

1092
Глава 12. Разработка операционных систем
int i, count = 0;
for (i = 0; i < BYTE_SIZE; i++) /* Цикл по битам байта */
if ((byte >> i) & 1) count++; /* если бит равен 1, увеличить на
единицу сумму */
return(count); /* вернуть сумму */
}
а
/* Макрос для подсчета суммы битов в байте */
#define bit_count(b) (b&1) + ((b>>1)&1) + ((b>>2)&1) + ((b>>3)&1) + \
((b>>4)&1) + ((b>>5)&1) + ((b>>6)&1) + ((b>>7)&1)
б
/* Макрос для поиска числа битов в таблице */
char bits[256] = {0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2,
3, 3, ...};
#define bit_count(b) (int) bits[b]
в
У этой процедуры два источника неэффективности. Во-первых, ей нужно передавать
управление, для чего требуется выделение стека, а после работы процедура должна
вернуть результат и управление. Эти накладные расходы есть у каждого вызова про-
цедуры. Во-вторых, процедура содержит цикл, а с циклом всегда связаны определенные
накладные расходы.
Совершенно иной подход применен при использовании макроса в листинге 12.4, б. Это
выражение вычисляет сумму битов, последовательно сдвигая аргумент и выделяя при
помощи маски младший бит. Этот макрос трудно назвать произведением искусства, но
он встречается в программе всего один раз. Вызов этого макроса выглядит идентично
вызову процедуры:
sum = bit_count(table[i]);
Таким образом, если не считать несколько беспорядочного определения, макрос вы-
глядит не хуже процедуры, но является намного более эффективным, так как в случае
макроса устраняются накладные расходы процедурного вызова и накладные расходы
цикла.
Оптимизация данного алгоритма может быть продолжена. Зачем вообще считать сумму
битов? Почему не посмотреть результат в таблице? В конце концов, байт может при-
нимать всего 256 значений, а число битов в байте может быть от 0 до 8. Мы можем объ-
явить массив bits из 256 значений, содержащий значения сумм битов, инициализируе-
мые во время компиляции программы. При таком методе во время работы программы
потребуется всего одна команда обращения к массиву по индексу. Соответствующий
макрос показан в листинге 12.4, в.
Показанные ранее макросы представляют собой понятные примеры выигрыша в ско-
рости за счет увеличения размеров программы. Однако в деле оптимизации мы могли
бы пойти еще дальше. Если требуется количество битов в 32-разрядном слове, то с по-
мощью макроса bit_count нам потребовалось бы для каждого слова выполнить четыре
обращения к массиву. Если мы увеличим размер таблицы до 65 536 элементов, то
сможем обойтись всего двумя обращениями к таблице на слово за счет значительного
увеличения таблицы.
12.4. Производительность
1093
Поиск значений в таблице может использоваться и в других ситуациях. В общеизвестной
технологии сжатия изображений GIF для кодирования 24-разрядных пикселов формата
RGB применяется поиск в таблице. Но алгоритм GIF работает только с изображениями,
содержащими не более 256 цветов. Для каждого сжимаемого изображения формируется
палитра из 256 цветов, хранящихся в формате RGB. Сжатое изображение состоит из
8-разрядных индексов таблицы вместо 24-разрядных значений цвета, благодаря чему
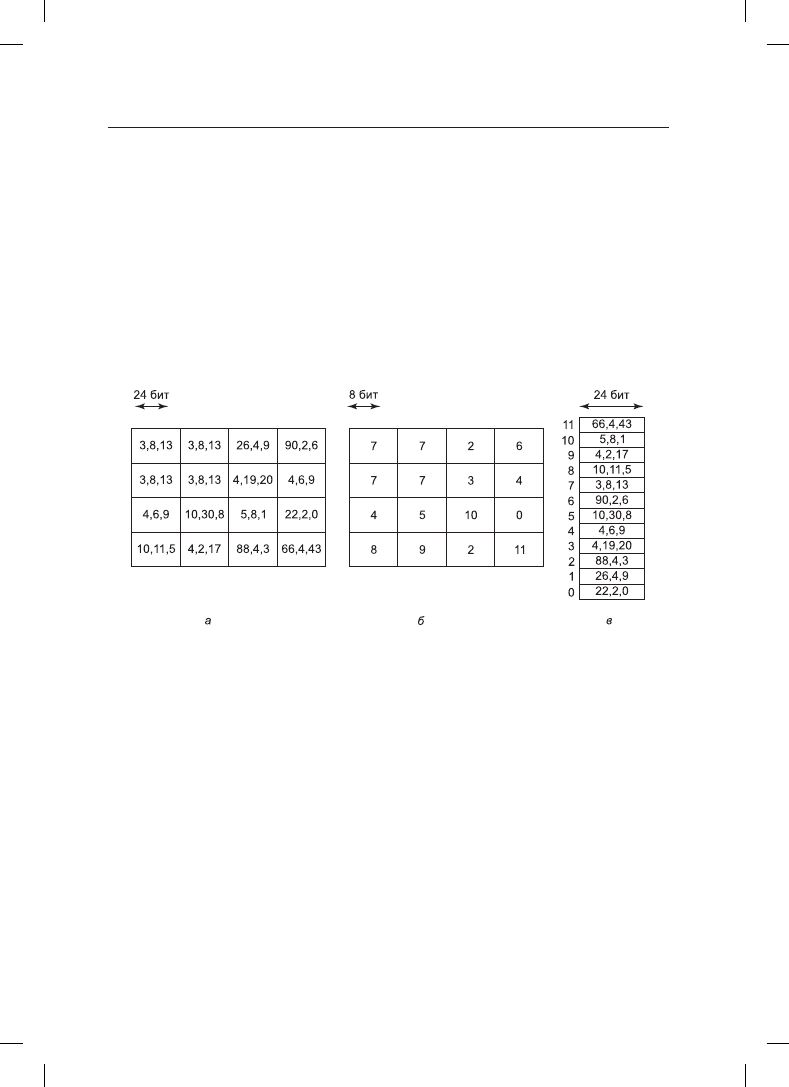
достигается сжатие в три раза. Эта идея проиллюстрирована для фрагмента изображения
4 × 4 пиксела на рис. 12.4. Несжатое изображение показано на рис. 12.4, а. Каждый пиксел
здесь представляет собой 24-разрядное число, в котором каждый из трех байтов содержит
интенсивность красного, зеленого и синего цвета. Соответствующее этому фрагменту
изображение в формате GIF показано на рис. 12.4, б. Палитра цветов, показанная на
рис. 12.4, в, хранится прямо в файле GIF. В действительности формат GIF несколько
сложнее, но основная идея заключается в применении таблицы цветов.
Рис. 12.4. Фрагмент изображения с 24 битами на пиксел: а — несжатый;
б — сжатый при помощи алгоритма GIF с 8 битами на пиксел; в — палитра цветов
Существует и другой способ уменьшить размер изображения, служащий иллюстраци-
ей еще одного компромисса. Для описания изображений может использоваться язык
программирования PostScript. (В действительности для этой цели может применяться
любой язык, но PostScript предназначен именно для этого.) Многие принтеры имеют
встроенный интерпретатор языка PostScript.
Например, если на изображении имеется прямоугольный блок пикселов одного цвета,
программа на языке PostScript для этого изображения будет содержать команды для
помещения прямоугольника в определенное место изображения и заполнения его
определенным цветом. Для хранения этих команд потребуется всего несколько битов.
Когда принтер получает изображение, интерпретатор запускает программу и создает
изображение. Таким образом, язык PostScript позволяет добиться сжатия данных за
счет большего объема вычислений. Этот подход диаметрально противоположен рассма-
тривавшемуся ранее примеру оптимизации по скорости с поиском значения в таблице,
но он также очень полезен, когда не хватает памяти или пропускной способности.
Другие примеры оптимизации включают структуры данных. Двойные связные списки
занимают больше памяти, чем одинарные связные списки, зато они часто предостав-

1094
Глава 12. Разработка операционных систем
ляют более быстрый доступ к элементам списка. Хэш-таблицы занимают еще больше
памяти, но значительнее ускоряют поиск. Короче говоря, при оптимизации участка
программы следует уделить особое внимание проблеме компромисса между занимае-
мой памятью и скоростью выполнения программы.
12.4.4. Кэширование
Хорошо известным методом повышения производительности является кэширование .
Оно может применяться каждый раз, когда с большой вероятностью можно предска-
зать, что много раз потребуется один и тот же результат. Общий метод заключается
в том, чтобы выполнить всю работу в первый раз, а затем сохранить результат в кэше.
При последующих попытках в первую очередь будет проверяться кэш. Если результат
находится в кэше, то нужно всего лишь достать его оттуда. В противном случае необ-
ходимо проделать всю работу сначала.
Мы уже наблюдали использование кэша в файловой системе, где он хранит некоторое
количество недавно использовавшихся блоков диска, что позволяет избежать об-
ращения к диску при чтении блока. Однако кэширование может применяться и для
других целей. Например, обработка путей к файлам отнимает удивительно много
процессорного времени. Рассмотрим снова пример из системы UNIX, показанный
на рис. 6.35. Чтобы найти файл
/usr/ast/mbox
, потребуется выполнить следующие
обращения к диску:
1. Прочитать i-узел корневого каталога (i-узел 1).
2. Прочитать корневой каталог (блок 1).
3. Прочитать i-узел каталога
/usr
(i-узел 6).
4. Прочитать каталог
/usr
(блок 132).
5. Прочитать i-узел каталога
/usr/ast
(i-узел 26).
6. Прочитать каталог
/usr/ast
(блок 406).
Чтобы просто определить номер i-узла искомого файла, нужно как минимум шесть раз
обратиться к диску. Если размер файла меньше размера блока (например, 1024 байт),
то чтобы прочитать содержимое файла, нужны восемь обращений к диску.
В некоторых операционных системах обработка путей файлов оптимизируется при
помощи кэширования пар (путь, i-узел). Например, на рис. 6.35 кэш будет содержать
первые три записи табл. 12.1 после обработки пути
/usr/ast/mbox
. Последние три запи-
си попадают в таблицу после обработки других путей.
Таблица 12.1. Часть кэша i-узлов
Путь
Номер i-узла
/usr
6
/usr/ast
26
/usr/ast/mbox
60
/usr/ast/books
92
/usr/bal
45
/usr/bal/papers.ps
85

12.4. Производительность
1095
Когда файловая система должна найти файл по пути, обработчик путей сначала
обращается к кэшу и ищет в нем самую длинную подстроку, соответствующую об-
рабатываемому пути. Если обрабатывается путь
/usr/ast/grants/stw
, кэш отвечает, что
номер i-узла каталога
/usr/ast
равен 26, так что поиск может быть начат с этого места
и количество обращений к диску уменьшено на четыре.
Недостаток кэширования путей состоит в том, что соответствие имени файла номеру
его i-узла не является постоянным. Представьте, что файл
/usr/ast/mbox
удаляется и его
i-узел используется для другого файла, владельцем которого может быть другой поль-
зователь. Затем файл
/usr/ast/mbox
создается снова, но на этот раз он получает i-узел
с номером 106. Если не предпринять специальных мер, запись кэша будет указывать
на неверный номер i-узла. Поэтому при удалении файла или каталога следует удалять
из кэша запись, соответствующую этому файлу, а если удаляется каталог, то следует
удалить также все записи для содержавшихся в этом каталоге файлов и подкаталогов
1
.
Кэшироваться могут не только блоки дисков и пути к файлам. Можно кэшировать
также i-узлы. Если для обработки прерываний используются временные потоки, для
каждого из них требуется стек и некоторый дополнительный механизм. Эти исполь-
зовавшиеся ранее потоки также можно кэшировать, так как обновить уже использо-
вавшийся поток легче, чем создать новый (применение кэша позволяет избежать не-
обходимости в выделении памяти новому процессу). Кэширование может применяться
почти для всего, что трудновоспроизводимо.
12.4.5. Подсказки
Элементы кэша всегда должны быть корректными. Поиск в кэше может завершить-
ся неудачей, но если элемент найден, то его корректность гарантируется, поэтому
найденный элемент может использоваться без дополнительных хлопот. В некоторых
системах бывает удобно содержать таблицу подсказок . Подсказки представляют собой
предложения решений, но их корректность не гарантируется. Обращающийся к этой
таблице процесс должен сам проверять корректность результата.
Хорошо известным примером подсказок являются указатели URL, содержащиеся
в веб-страницах. Когда пользователь щелкает мышью на ссылке, он не получает
гарантии, что соответствующая веб-страница находится там, куда указывает URL.
В действительности может оказаться, что требующаяся страница удалена несколько
лет назад. Таким образом, информация, содержащаяся на веб-странице, представляет
собой всего лишь подсказку.
Подсказки используются также при работе с удаленными файлами. Информация,
содержащаяся в подсказке, сообщает нечто об удаленном файле, например его место-
нахождение. Однако, возможно, этот файл уже удален или перемещен в другое место,
поэтому всегда требуется проверка корректности подсказки.
12.4.6. Использование локальности
Процессы и программы действуют не случайным образом. Они оказываются в значи-
тельной степени локальными как во времени, так и в пространстве, и эта информация
1
Во всех файловых системах удаляться могут только пустые каталоги. — Примеч. пер.