Добавлен: 29.10.2018
Просмотров: 48036
Скачиваний: 190
176
Глава 2. Процессы и потоки
согласно которому ни один из процессов не может перейти к следующей фазе, пока
все процессы не будут готовы перейти к следующей фазе. Добиться выполнения этого
правила можно с помощью барьеров, поставленных в конце каждой фазы. Когда про-
цесс достигает барьера, он блокируется до тех пор, пока этого барьера не достигнут все
остальные процессы. Это позволяет синхронизировать группы процессов. Действие
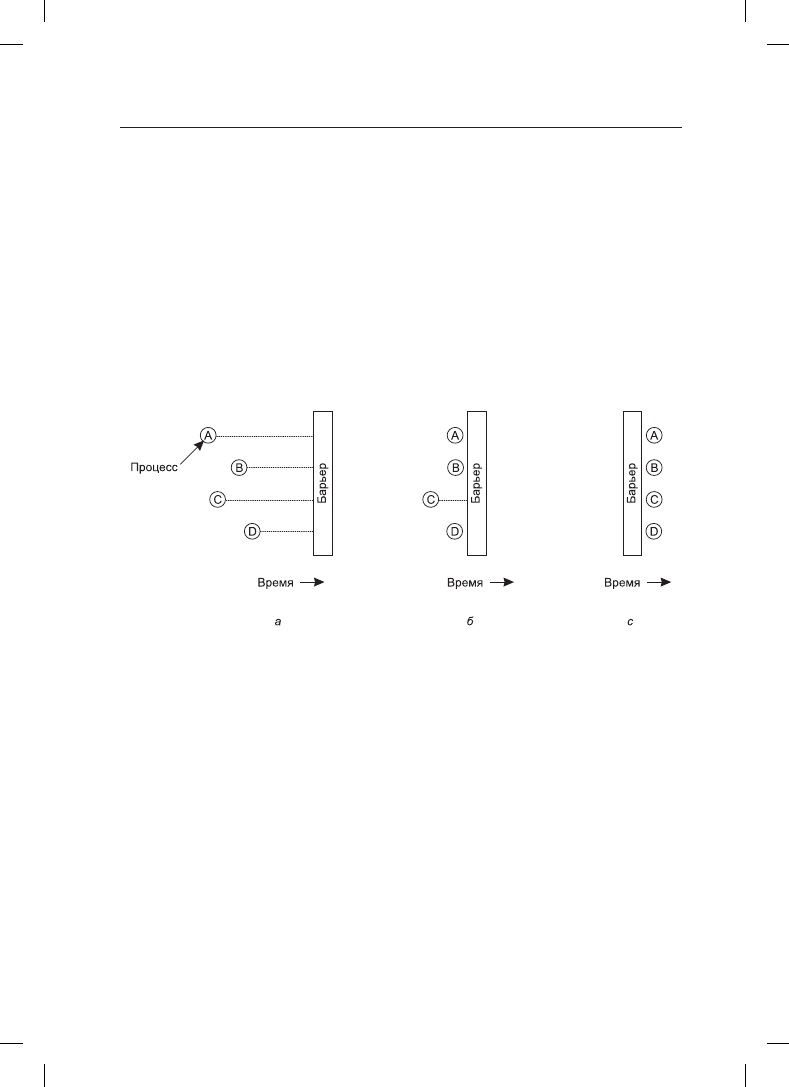
барьера представлено на рис. 2.18.
На рис. 2.18, а показаны четыре процесса, приближающихся к барьеру. Это означает,
что они еще заняты вычислениями и не достигли завершения текущей фазы. Через не-
которое время первый процесс заканчивает все вычисления, необходимые для заверше-
ния первой фазы работы. Он выполняет примитив barrier, вызывая обычно библиотеч-
ную процедуру. Затем этот процесс приостанавливается. Чуть позже первую фазу своей
работы завершают второй и третий процессы, которые также выполняют примитив
barrier. Эта ситуация показана на рис. 2.18, б. И наконец, как показано на рис. 2.18, в,
когда последний процесс, C, достигает барьера, все процессы освобождаются.
Рис. 2.18. Использование барьера: а — процесс достигает барьера; б — все процессы, кроме
одного, заблокированы на барьере; в — последний процесс достигает барьера, и все процессы
преодолевают этот барьер
В качестве примера задачи, для решения которой нужны барьеры, рассмотрим обычную
в физике или в машиностроении задачу затухания. Обычно это матрица, содержащая
некоторые исходные значения. Эти значения могут представлять собой температуру
в разных точках листа металла. Замысел может состоять в определении скорости рас-
пространения разогрева от пламени, воздействующего на один из его углов.
Начиная с текущих значений, к матрице для получения ее следующей версии приме-
няется преобразование, соответствующее, к примеру, законам термодинамики, чтобы
посмотреть все температурные показания через время ΔT. Затем процесс повторяется
снова и снова, представляя температурные значения в виде функции, зависящей от
времени нагревания листа. Со временем алгоритм производит серию матриц, каждая
из которых соответствует заданной отметке времени.
Теперь представим, что матрица имеет слишком большие размеры (скажем, миллион
на миллион) и для ускорения ее вычисления требуется использование параллельных
процессов (возможно, на многопроцессорной машине). Разные процессы работают над
разными частями матрицы, вычисляя новые элементы матрицы на основе прежних

2.3. Взаимодействие процессов
177
значений в соответствии с законами физики. Но ни один процесс не может приступить
к итерации n + 1, пока не завершится итерация n, то есть пока все процессы не завершат
текущую работу. Способ достижения этой цели — запрограммировать каждый про-
цесс на выполнение операции barrier после того, как он завершит свою часть текущей
итерации. Когда все процессы справятся со своей работой, новая матрица (предостав-
ляющая входные данные для следующей итерации) будет завершена и все процессы
будут освобождены для начала следующей итерации.
2.3.10. Работа без блокировок:
чтение — копирование — обновление
Самые быстрые блокировки — это отсутствие всяких блокировок. Вопрос в том, можно
ли разрешить одновременный доступ для чтения и записи к общим структурам данных
без блокировки. Если говорить в общем смысле, то ответ, конечно же, будет отрица-
тельный. Представим себе, что процесс А сортирует числовой массив, в то же время
процесс Б вычисляет среднее значение. Поскольку A перемещает значения по массиву,
процессу Б некоторые значения могут попасться несколько раз, а некоторые не встре-
титься вообще. Результат может быть каким угодно, но, скорее всего, неправильным.
И тем не менее в некоторых случаях можно позволить процессу, ведущему запись, об-
новить структуру данных, даже если ею пользуются другие процессы. Здесь важно обе-
спечить, чтобы каждый считывающий процесс читал либо старую, либо новую версию
данных, но не некую непонятную комбинацию из старой и новой версий. В качестве
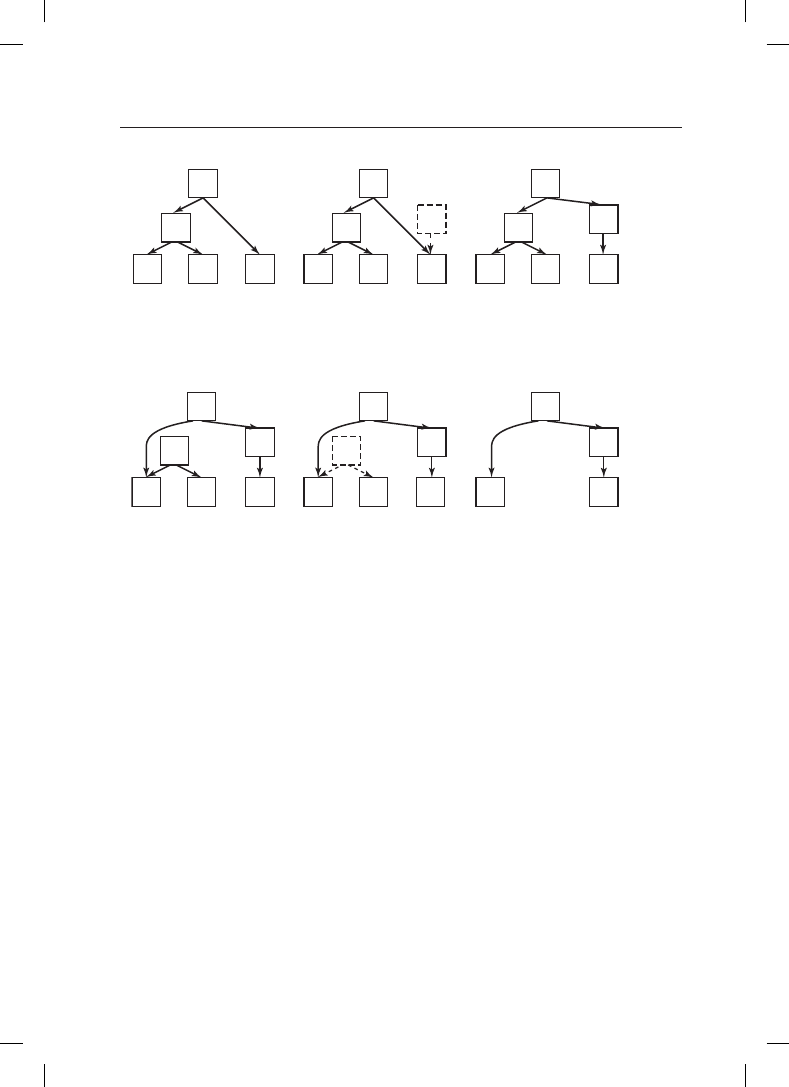
иллюстрации рассмотрим дерево, показанное на рис. 2.19. Читатели обходят дерево от
корня до листьев. В верхней половине рисунка добавлен новый узел X. Перед тем как
сделать этот узел видимым в дереве, мы доводим его до полной готовности: инициа-
лизируем все значения в узле X, включая его дочерние указатели. Затем с помощью
одной атомарной записи превращаем X в дочерний элемент узла A. Несогласованную
версию не сможет считать ни один читатель. В нижней части рисунка последовательно
удаляются узлы B и D. Сначала мы перенацеливаем левый дочерний указатель узла A
на узел C. Все читатели, попавшие в A, продолжат считывание с узла C и никогда не
увидят узел B или D. Иными словами, они увидят только новую версию. В то же время
все читатели, находящиеся в этот момент в узле B или D, продолжат чтение, следуя
указателям исходной структуры данных, и увидят старую версию. Все будет хорошо,
и блокировка вообще не понадобится. Удаление B и D работает без блокировки струк-
туры данных в основном потому, что RCU (Read — Copy — Update, чтение — копиро-
вание — обновление) отделяет фазу удаления от фазы восстановления обновления.
Но есть и проблема. Пока нет уверенности в полном отсутствии читателей в B или D,
мы не можем фактически от них избавиться. Но сколько же должно продлиться ожи-
дание? Одну минуту? Десять минут? Мы вынуждены ждать до тех пор, пока эти узлы
не оставит последний читатель. RCU обязательно определяет максимальное время,
в течение которого читатель может удерживать ссылку на структуру данных. По исте-
чении этого срока память может быть безопасно освобождена. Точнее говоря, читатели
получают доступ к структуре данных в области, которая известна как критический
раздел чтения
(read-side critical section), где может содержаться любой код, посколь-
ку он не заблокирован или не пребывает в режиме ожидания. В этом случае известно
максимальное время вынужденного ожидания. А именно нами определяется отсрочка
(grace period) в виде любого периода времени, в течение которого известно, что каждый
178
Глава 2. Процессы и потоки
(a) èñõîäíîå äåðåâî
(á) èíèöèàëèçàöèÿ óçëà X
è ïîäêëþ÷åíèå E ê X.
Íà ëþáûõ ÷èòàòåëåé,
íàõîäÿùèõñÿ â A è E,
ýòî íå ïîâëèÿåò
X
A
B
E
D
C
D
D
C
C
D
D
C
C
A
B
E
(â) ïîñëå ïîëíîé èíèöèàëèçàöèè X
ïîäêëþ÷åíèå X ê A. ×èòàòåëè,
íàõîäÿùèåñÿ â ýòî âðåìÿ â E,
ïðî÷èòàþò ñòàðóþ âåðñèþ äåðåâà,
à ÷èòàòåëè, íàõîäÿùèåñÿ â A,
ïîëó÷àò íîâóþ âåðñèþ
X
A
B
E
(ã) îòñîåäèíåíèå B îò A.
Çàìåòüòå, ÷òî â B âñå åùå
ìîãóò áûòü ÷èòàòåëè. Âñå
÷èòàòåëè â B áóäóò âèäåòü
ñòàðóþ âåðñèþ, à âñå
÷èòàòåëè, íàõîäÿùèåñÿ
â ýòî âðåìÿ â A, óâèäÿò
íîâóþ âåðñèþ
X
A
B
E
(ä) îæèäàíèå ïîëíîé
óâåðåííîñòè â òîì, ÷òî
âñå ÷èòàòåëè ïîêèíóëè B è C.
Áîëüøå äîñòóïà ê ýòèì óçëàì
íå áóäåò
X
A
B
E
C
E
(å) òåïåðü B è D ìîæíî
ñïîêîéíî óäàëèòü
X
A
Äîáàâëåíèå óçëà:
Óäàëåíèå óçëîâ:
Рис. 2.19. RCU: вставка узла в дерево с последующим удалением ветви,
и все это без блокировок
поток будет вне критического раздела для чтения по крайней мере однократно. Если
период ожидания перед восстановлением будет как минимум равен отсрочке, все будет
хорошо. Поскольку код в критическом разделе для чтения не разрешено блокировать
или переводить в режим ожидания, простым критерием будет ожидание до тех пор,
пока все потоки не выполнят контекстное переключение.
2.4. Планирование
Когда компьютер работает в многозадачном режиме, на нем зачастую запускается сра-
зу несколько процессов или потоков, претендующих на использование центрального
процессора. Такая ситуация складывается в том случае, если в состоянии готовности
одновременно находятся два или более процесса или потока. Если доступен только
один центральный процессор, необходимо выбрать, какой из этих процессов будет
выполняться следующим. Та часть операционной системы, на которую возложен этот
выбор, называется планировщиком, а алгоритм, который ею используется, называется
алгоритмом планирования
. Именно эта тема и станет предметом рассмотрения в сле-
дующих разделах.

2.4. Планирование
179
Многие однотипные вопросы, применяемые к планированию процессов, могут приме-
няться и к планированию потоков, хотя существуют и некоторые различия. Когда ядро
управляет потоками, планирование обычно касается каждого из потоков, практически
не различая, какому именно процессу они принадлежат (или все же делая небольшие
различия). Сначала мы сконцентрируемся на вопросах планирования, применимых как
к процессам, так и к потокам. После этого рассмотрим исключительно планирование
потоков и ряд возникающих при этом уникальных вопросов. А многоядерные процес-
соры будут рассмотрены в главе 8.
2.4.1. Введение в планирование
Если вернуться к прежним временам пакетных систем, где ввод данных осуществлялся
в форме образов перфокарт, перенесенных на магнитную ленту, то алгоритм плани-
рования был довольно прост: требовалось всего лишь запустить следующее задание.
С появлением многозадачных систем алгоритм планирования усложнился, посколь-
ку в этом случае обычно фигурировали сразу несколько пользователей, ожидавших
обслуживания. На некоторых универсальных машинах до сих пор пакетные задачи
сочетаются с задачами в режиме разделения времени, и планировщику нужно решать,
какой должна быть очередная работа: выполнение пакетного задания или обеспечение
интерактивного общения с пользователем, сидящим за терминалом. (Между прочим,
в пакетном задании мог содержаться запрос на последовательный запуск нескольких
программ, но в данном разделе мы будем придерживаться предположения, что запрос
касается запуска только одной программы.) Поскольку на таких машинах процессорное
время является дефицитным ресурсом, хороший планировщик может существенно
повлиять на ощущаемую производительность машины и удовлетворенность пользо-
вателя. Поэтому на изобретение искусного и эффективного алгоритма планирования
было потрачено немало усилий.
С появлением персональных компьютеров ситуация изменилась в двух направлениях.
Во-первых, основная часть времени отводилась лишь одному активному процессу. Вряд
ли случалось такое, что пользователь, вводивший документ в текстовый процессор,
одновременно с этим компилировал программу в фоновом режиме. Когда пользо-
ватель набирал команду для текстового процессора, планировщику не приходилось
напрягаться, определяя, какой процесс нужно запустить, — текстовый процессор был
единственным кандидатом.
Во-вторых, с годами компьютеры стали работать настолько быстрее, что центральный
процессор практически перестал быть дефицитным ресурсом. Большинство программ
для персонального компьютера ограничены скоростью предоставления пользователем
входящей информации (путем набора текста или щелчками мыши), а не скоростью,
с которой центральный процессор способен ее обработать. Даже задачи компиляции
программ, в прошлом главный потребитель процессорного времени, теперь в большин-
стве случаев занимают всего несколько секунд. Даже при одновременной работе двух
программ, например текстового процессора и электронной таблицы, вряд ли имеет
значение, которую из них нужно пропустить вперед, поскольку пользователь, скорее
всего, ждет результатов от обеих. Поэтому на простых персональных компьютерах
планирование не играет особой роли. Конечно, существуют приложения, которые по-
глощают практически все ресурсы центрального процессора: например, визуализация
одночасового видео высокого разрешения при корректировке цветовой гаммы каж-
дого из 107 892 кадров (в NTSC) или 90 000 кад ров (в PAL) требует вычислительной

180
Глава 2. Процессы и потоки
мощности промышленной компьютерной системы, но подобные приложения скорее
являются исключением из правил.
Когда же дело касается сетевых служб, ситуация существенно изменяется. Здесь в кон-
курентную борьбу за процессорное время вступают уже несколько процессов, поэтому
планирование снова приобретает значение. Например, когда центральному процессору
нужно выбирать между запущенным процессом, собирающим ежедневную статистику,
и одним из процессов, обслуживающих запросы пользователя, если приоритет будет
сразу же отдан последнему из процессов, пользователь будет чувствовать себя намного
лучше. Многие мобильные устройства, такие как смартфоны (за исключением разве что
самых мощных моделей), и узлы сенсорных сетей «обилием ресурсов» также похвастать-
ся не могут. У них все еще может быть маломощный центральный процессор и неболь-
шой объем памяти. Более того, поскольку одним из наиболее важных ограничений на
этих устройствах является ресурс аккумуляторов, некоторые планировщики стараются
оптимизировать потребление электроэнергии.
Планировщик наряду с выбором «правильного» процесса должен заботиться также об
эффективной загрузке центрального процессора, поскольку переключение процессов
является весьма дорогостоящим занятием. Сначала должно произойти переключение
из пользовательского режима в режим ядра, затем сохранено состояние текущего про-
цесса, включая сохранение его регистров в таблице процессов для их последующей
повторной загрузки. На некоторых системах должна быть сохранена также карта
памяти (например, признаки обращения к страницам памяти). После этого запуска-
ется алгоритм планирования для выбора следующего процесса. Затем в соответствии
с картой памяти нового процесса должен быть перезагружен блок управления памятью.
И наконец, новый процесс должен быть запущен. Вдобавок ко всему перечисленному
переключение процессов обесценивает весь кэш памяти, заставляя его дважды дина-
мически перезагружаться из оперативной памяти (после входа в ядро и после выхода
из него). В итоге слишком частое переключение может поглотить существенную долю
процессорного времени, что наводит на мысль: этого нужно избегать.
Поведение процесса
На рис. 2.19 показано, что практически у всех процессов пики вычислительной ак-
тивности чередуются с запросами (дискового или сетевого) ввода-вывода. Зачастую
центральный процессор некоторое время работает без остановок, затем происходит
системный вызов для чтения данных из файла или для их записи в файл. Когда си-
стемный вызов завершается, центральный процессор возобновляет вычисления до тех
пор, пока ему не понадобятся дополнительные данные или не потребуется записать
дополнительные данные на диск и т. д. Следует заметить, что некоторые операции
ввода-вывода считаются вычислениями. Например, когда центральный процессор ко-
пирует биты в видеопамять, чтобы обновить изображение на экране, то он занимается
вычислением, а не вводом-выводом, поскольку при этом задействован он сам. В этом
смысле ввод-вывод происходит в том случае, когда процесс входит в заблокированное
состояние, ожидая, пока внешнее устройство завершит свою работу.
По поводу изображения на рис. 2.19 следует заметить, что некоторые процессы, как тот,
что показан на рис. 2.19, а, проводят основную часть своего времени за вычислениями,
а другие, как тот, что показан на рис. 2.19, б, основную часть своего времени ожида-
ют завершения операций ввода-вывода. Первые процессы называются процессами,