Добавлен: 29.10.2018
Просмотров: 48049
Скачиваний: 190

196
Глава 2. Процессы и потоки
Система реального времени, отвечающая этому критерию, называется планируемой.
Это означает, что такая система фактически может быть реализована. Процесс, не от-
вечающий этому тесту, не может быть планируемым, поскольку общее время централь-
ного процессора, требуемое процессу, в совокупности больше того времени, которое
этот центральный процессор может предоставить.
В качестве примера рассмотрим гибкую систему реального времени с тремя периоди-
ческими событиями с периодами 100, 200 и 500 мс соответственно. Если на обработку
каждого из этих событий требуется, соответственно, 50, 30 и 100 мс процессорного
времени, работа системы может быть спланирована, поскольку 0,5 + 0,15 + 0,2 < 1.
Если будет добавлено четвертое событие с периодом 1 с, то система будет сохранять
планируемость до тех пор, пока на обработку этого события не потребуется более
150 мс процессорного времени. В этом вычислении подразумевается, что издержки на
переключение контекста настолько малы, что ими можно пренебречь.
Алгоритмы планирования работы систем реального времени могут быть статиче-
скими или динамическими. Первый из них предусматривает принятие решений по
планированию еще до запуска системы, а второй — их принятие в реальном времени,
после того как начнется выполнение программы. Статическое планирование рабо-
тает только при условии предварительного обладания достоверной информацией
о выполняемой работе и о крайних сроках, которые нужно соблюсти. Алгоритмы
динамического планирования подобных ограничений не имеют. Изучение конкрет-
ных алгоритмов мы отложим до главы 7, где будут рассмотрены мультимедийные
системы реального времени.
2.4.5. Политика и механизмы
До сих пор негласно подразумевалось, что все процессы в системе принадлежат разным
пользователям и поэтому конкурируют в борьбе за процессорное время. Хотя зачастую
это и соответствует действительности, иногда бывает так, что у одного процесса есть
множество дочерних процессов, запущенных под его управлением. Например, про-
цесс системы управления базой данных может иметь множество дочерних процессов.
Каждый из них может работать над своим запросом или обладать специфическими
выполняемыми функциями (разбор запроса, доступ к диску и т. д.). Вполне возможно,
что основной процесс великолепно разбирается в том, какой из его дочерних процессов
наиболее важен (или критичен по времени выполнения), а какой — наименее важен.
К сожалению, ни один из ранее рассмотренных планировщиков не воспринимает
никаких входных данных от пользовательских процессов, касающихся принятия ре-
шений по планированию. В результате этого планировщик довольно редко принимает
наилучшие решения.
Решение этой проблемы заключается в укоренившемся принципе разделения механиз-
ма
и политики планирования (Levin et al., 1975). Это означает наличие какого-нибудь
способа параметризации алгоритма планирования, предусматривающего возможность
пополнения параметров со стороны пользовательских процессов. Рассмотрим еще раз
пример использования базы данных. Предположим, что ядро применяет алгоритм при-
оритетного планирования, но предоставляет системный вызов, с помощью которого
процесс может установить (или изменить) приоритеты своих дочерних процессов. Та-
ким образом родительский процесс может всесторонне управлять порядком планирова-
ния работы дочерних процессов, даже если сам планированием не занимается. Здесь мы
2.4. Планирование
197
видим, что механизм находится в ядре, а политика устанавливается пользовательским
процессом. Ключевой идеей здесь является отделение политики от механизма.
2.4.6. Планирование потоков
Когда есть несколько процессов и у каждого — несколько потоков, у нас появляется
два уровня параллелизма: процессы и потоки. Планирование в таких системах в зна-
чительной степени зависит от того, на каком уровне поддерживаются потоки — на
пользовательском, на уровне ядра или на обоих уровнях.
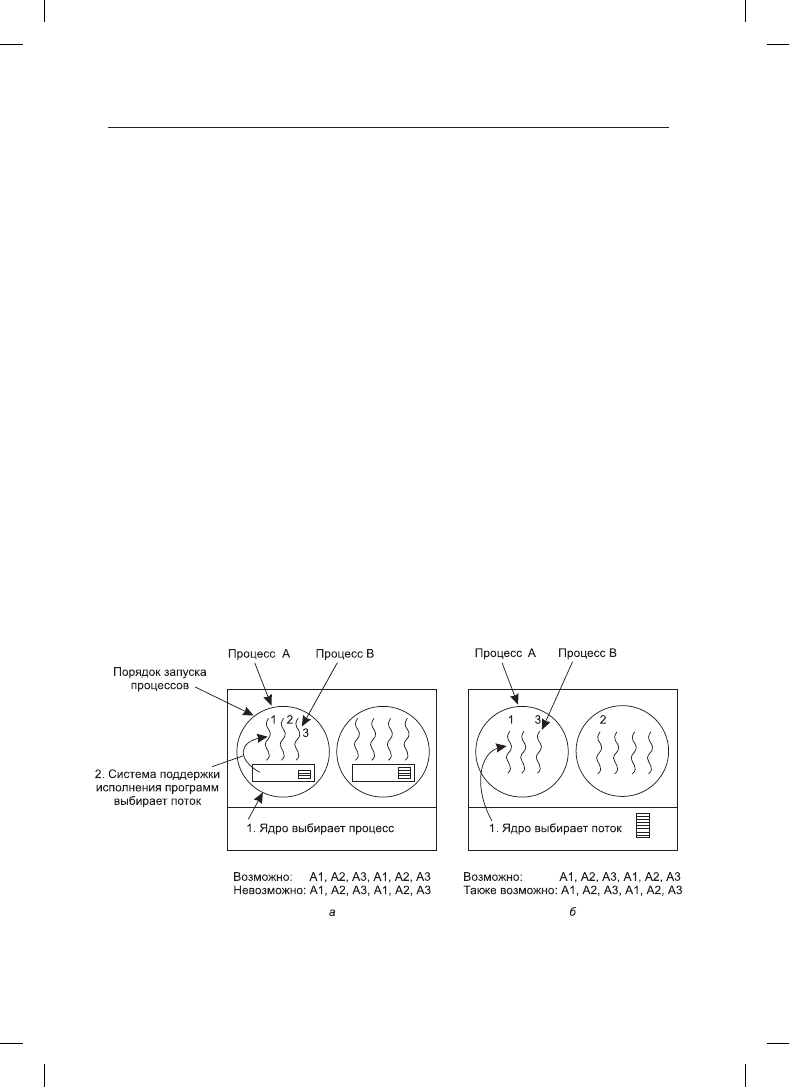
Сначала рассмотрим потоки на уровне пользователя. Поскольку ядро о существовании
потоков не знает, оно работает в обычном режиме, выбирая процесс, скажем, A, и пере-
дает процессу A управление до истечения его кванта времени. Планировщик потоков
внутри процесса A решает, какой поток запустить, — скажем, A1. Из-за отсутствия
таймерных прерываний для многозадачных потоков этот поток может продолжать
работу, сколько ему понадобится. Если он полностью израсходует весь квант времени,
отведенный процессу, ядро выберет для запуска другой процесс.
Когда процесс A будет наконец-то снова запущен, поток A1 также возобновит работу.
Он продолжит расходовать все отведенное процессу A время, пока не закончит рабо-
ту. Но его недружелюбное поведение никак не отразится на других процессах. Они
получат то, что планировщик посчитает их долей, независимо от того, что происходит
внутри процесса A.
Теперь рассмотрим случай, когда потоки процесса A выполняют непродолжительную
относительно доли выделенного процессорного времени работу, например работу
продолжительностью 5 мс при кванте времени 50 мс. Следовательно, каждый из них
запускается на небольшой период времени, возвращая затем центральный процессор
планировщику потоков. При этом, перед тем как ядро переключится на процесс B,
может получиться следующая последовательность: A1, A2, A3, A1, A2, A3, A1, A2, A3,
A1. Эта ситуация показана на рис. 2.24, а.
Рис. 2.24. Возможный вариант планирования потоков: а — на уровне пользователя с квантом
времени 50 мс и потоками, работающими по 5 мс при работе центрального процессора
в пределах этого кванта; б — на уровне ядра с теми же характеристиками

198
Глава 2. Процессы и потоки
Алгоритм планирования, используемый системой поддержки исполнения программ,
может быть любым из ранее рассмотренных. На практике наиболее широко распростра-
нены циклическое и приоритетное планирование. Единственным ограничением будет
отсутствие таймерного прерывания в отношении потока, выполняемого слишком долго.
Но поскольку потоки взаимодействуют, обычно это не вызывает проблем.
Теперь рассмотрим ситуацию с потоками, реализованными на уровне ядра. Здесь
конкретный запускаемый поток выбирается ядром. Ему не нужно учитывать принад-
лежность этого потока конкретному процессу, но если понадобится, то он может это
сделать. Потоку выделяется квант времени, по истечении которого его работа при-
останавливается. Если выделен квант 50 мс, а запущен поток, который блокируется
через 5 мс, то очередность потоков на период продолжительностью 30 мс может быть
следующей: A1, B1, A2, B2, A3, B3, что невозможно получить при таких параметрах на
пользовательском уровне. Эта ситуация частично показана на рис. 2.24, б.
Потоки на уровне пользователя и потоки на уровне ядра различаются в основном произ-
водительностью работы. Для переключения потоков, реализованных на уровне пользова-
теля, требуется лишь небольшое количество машинных команд, а для потоков на уровне
ядра требуется полное контекстное переключение, смена карты памяти и аннулирование
кэша, что выполняется на несколько порядков медленнее. В то же время поток на уровне
ядра, заблокированный на операции ввода-вывода, не вызывает приостановку всего про-
цесса, как поток на уровне пользователя. Поскольку ядру известно, что на переключение
с потока из процесса A на поток из процесса B затрачивается больше времени, чем на
запуск второго потока из процесса A (из-за необходимости изменения карты памяти
и обесценивания кэша памяти), то оно может учесть эти сведения при принятии решения.
К примеру, если взять два равнозначных во всем остальном потока, один из которых при-
надлежит тому процессу, чей поток был только что заблокирован, а второй принадлежит
другому процессу, предпочтение может быть отдано первому потоку.
Другой важный фактор заключается в том, что потоки, реализованные на уровне поль-
зователя, могут использовать планировщик потоков, учитывающий особенности при-
ложения. Рассмотрим, к примеру, веб-сервер, показанный на рис. 2.6. Предположим, что
рабочий поток был только что заблокирован, а поток диспетчера и два рабочих потока
находятся в состоянии готовности. Какой из потоков должен быть запущен следующим?
Система поддержки исполнения программ, владеющая информацией о том, чем зани-
маются все потоки, может без труда выбрать следующим для запуска диспетчер, чтобы
тот запустил следующий рабочий процесс. Эта стратегия доводит до максимума степень
параллелизма в среде, где рабочие потоки часто блокируются на дисковых операциях
ввода-вывода. Когда потоки реализованы на уровне ядра, само ядро никогда не будет
обладать информацией, чем занимается каждый поток (хотя им могут быть присвоены
разные приоритеты). Но в целом планировщики потоков, учитывающие особенности
приложений, могут лучше подстроиться под приложение, чем ядро.
2.5. Классические задачи
взаимодействия процессов
В литературе по операционным системам можно встретить множество интересных
проблем использования различных методов синхронизации, ставших предметом

2.5. Классические задачи взаимодействия процессов
199
широких дискуссий и анализа. В данном разделе мы рассмотрим наиболее известные
проблемы.
2.5.1. Задача обедающих философов
В 1965 году Дейкстра сформулировал, а затем решил проблему синхронизации, на-
званную им задачей обедающих философов. С тех пор все изобретатели очередного
примитива синхронизации считали своим долгом продемонстрировать его наилучшие
качества, показав, насколько элегантно с его помощью решается задача обедающих
философов. Суть задачи довольно проста. Пять философов сидят за круглым столом,
и у каждого из них есть тарелка спагетти. Эти спагетти настолько скользкие, что есть
их можно только двумя вилками. Между каждыми двумя тарелками лежит одна вилка.
Внешний вид стола показан на рис. 2.25.
Рис. 2.25. Обед на факультете философии
Жизнь философа состоит из чередующихся периодов приема пищи и размышлений.
(Это положение из разряда абстракций даже в отношении философов, но вся их
остальная деятельность к задаче не относится.) Когда философ становится голоден,
он старается поочередно в любом порядке завладеть правой и левой вилками. Если
ему удастся взять две вилки, он на некоторое время приступает к еде, затем кладет обе
вилки на стол и продолжает размышления. Основной вопрос состоит в следующем:
можно ли написать программу для каждого философа, который действует предпо-
лагаемым образом и никогда при этом не попадает в состояние зависания? (Можно
заметить, что потребность в двух вилках выглядит несколько искусственно. Может
быть, стоит переключиться с итальянской на китайскую кухню, заменив спагетти ри-
сом, а вилки — палочками для еды?)
В листинге 2.13 показано самое простое решение этой задачи. Процедура take_fork
ждет, пока вилка не освободится, и берет ее. К сожалению, это решение ошибочно.

200
Глава 2. Процессы и потоки
Допустим, что все пять философов одновременно берут левую от себя вилку. Тогда
никто из них не сможет взять правую вилку, что приведет к взаимной блокировке.
Листинг 2.13. Ошибочное решение задачи обедающих философов
#define N 5 /* количество философов */
void philosopher(int i) /* i: номер философа (от 0 до 4) */
{
while (TRUE) {
think( ); /* философ размышляет */
take_fork(i); /* берет левую вилку */
take_fork((i+1) % N); /* берет правую вилку; */
/* % - оператор деления по модулю */
eat(); /* ест спагетти */
put_fork(i); /* кладет на стол левую вилку */
put_fork((i+1) % N); /* кладет на стол правую вилку */
}
}
Можно без особого труда изменить программу так, чтобы после получения левой вилки
программа проверяла доступность правой вилки. Если эта вилка недоступна, философ
кладет на место левую вилку, ожидает какое-то время, а затем повторяет весь процесс.
Это предложение также ошибочно, но уже по другой причине. При некоторой доле не-
везения все философы могут приступить к выполнению алгоритма одновременно и, взяв
левые вилки и увидев, что правые вилки недоступны, опять одновременно положить
на место левые вилки, и так до бесконечности. Подобная ситуация, при которой все
программы бесконечно работают, но не могут добиться никакого прогресса, называется
голоданием
, или зависанием процесса. (Эта ситуация называется голоданием даже
в том случае, если проблема возникает вне стен итальянского или китайского ресторана.)
Можно подумать, что стоит только заменить одинаковое для всех философов время
ожидания после неудачной попытки взять правую вилку на случайное, и вероятность,
что все они будут топтаться на месте хотя бы в течение часа, будет очень мала. Это
правильное рассуждение, и практически для всех приложений повторная попытка че-
рез некоторое время не вызывает проблемы. К примеру, если в популярной локальной
сети Ethernet два компьютера одновременно отправляют пакет данных, каждый из них
выжидает случайный отрезок времени, а затем повторяет попытку. И на практике это
решение неплохо работает. Но в некоторых приложениях может отдаваться предпо-
чтение решению, которое срабатывает всегда и не может привести к отказу по причине
неудачной череды случайных чисел. Вспомним о системе управления безопасностью
атомной электростанции.
В программу, показанную в листинге 2.13, можно внести улучшение, позволяющее
избежать взаимной блокировки и зависания. Для этого нужно защитить пять опера-
торов, следующих за вызовом think, двоичным семафором. Перед тем как брать вилки,
философ должен выполнить в отношении переменной mutex операцию down. А после
того как он положит вилки на место, он должен выполнить в отношении переменной
mutex операцию up. С теоретической точки зрения это вполне достаточное решение.
Но с практической — в нем не учтен вопрос производительности: в каждый момент
времени может есть спагетти только один философ. А при наличии пяти вилок одно-
временно могут есть спагетти два философа.