Добавлен: 29.10.2018
Просмотров: 48066
Скачиваний: 190

226
Глава 3. Управление памятью
Когда процессы и пустые пространства содержатся в списке отсортированными по
адресам, то для выделения памяти создаваемому процессу (или существующему
процессу, загружаемому в результате свопинга с диска) могут быть использованы
несколько алгоритмов. Предположим, что диспетчер памяти знает, сколько памяти
нужно выделить. Простейший алгоритм называется «первое подходящее». Диспетчер
памяти сканирует список сегментов до тех пор, пока не найдет пустое пространство
подходящего размера. Затем пустое пространство разбивается на две части: одна для
процесса и одна для неиспользуемой памяти, за исключением того статистически
маловероятного случая, когда процесс в точности помещается в пус тое пространство.
«Первое подходящее» — это быстрый алгоритм, поскольку поиск ведется с наимень-
шими затратами времени.
Незначительной вариацией алгоритма «первое подходящее» является алгоритм «сле-
дующее подходящее
». Он работает так же, как и «первое подходящее», за исключени-
ем того, что отслеживает свое местоположение, как только находит подходящее пустое
пространство. При следующем вызове для поиска пустого пространства он начинает
поиск в списке с того места, на котором остановился в прошлый раз, а не приступает
к поиску с самого начала, как при работе алгоритма «первое подходящее». Модели-
рование работы алгоритма «следующее подходящее», выполненное Бэйсом (Bays,
1977), показало, что его производительность несколько хуже, чем алгоритма «первое
подходящее».
Другой хорошо известный и широко используемый алгоритм — «наиболее подходя-
щее
». При нем поиск ведется по всему списку, от начала до конца, и выбирается наи-
меньшее соответствующее пустое пространство. Вместо того чтобы разбивать большое
пустое пространство, которое может пригодиться чуть позже, алгоритм «наиболее
подходящее» пытается подыскать пустое пространство, близкое по размеру к необ-
ходимому, чтобы наилучшим образом соответствовать запросу и имеющимся пустым
пространствам.
В качестве примера алгоритмов «первое подходящее» и «наиболее подходящее» вер-
немся к рис. 3.6. Если необходимо пространство в два единичных блока, то, согласно
алгоритму «первое подходящее», будет выделено пустое пространство, начинающееся
с адреса 5, а согласно алгоритму «наиболее подходящее», будет выделено пустое про-
странство, начинающееся с адреса 18.
Алгоритм «наиболее подходящее» работает медленнее, чем «первое подходящее», по-
скольку при каждом вызове он должен вести поиск по всему списку. Как ни странно,
но его применение приводит к более расточительному использованию памяти, чем ис-
пользование алгоритмов «первое подходящее» и «следующее подходящее», поскольку
он стремится заполнить память, оставляя небольшие бесполезные пустые пространства.
В среднем при использовании алгоритма «первое подходящее» образуются более про-
тяженные пустые пространства.
При попытке обойти проблему разбиения практически точно подходящих пространств
памяти на память, отводимую под процесс, и небольшие пустые пространства можно
прийти к идее алгоритма «наименее подходящее», то есть к неизменному выбору са-
мого большого подходящего пустого пространства, чтобы вновь образующееся пустое
пространство было достаточно большим для дальнейшего использования. Моделиро-
вание показало, что применение алгоритма «наименее подходящее» также далеко не
самая лучшая идея.

3.3. Виртуальная память
227
Работа всех четырех алгоритмов может быть ускорена за счет ведения отдельных
списков для процессов и пустых пространств. При этом все усилия этих алгоритмов
сосредоточиваются на просмотре списков пустых пространств, а не списков процессов.
Неизбежной ценой за это ускорение распределения памяти становится дополнительное
усложнение и замедление процедуры ее освобождения, поскольку освободившийся сег-
мент должен быть удален из списка процессов и внесен в список пустых пространств.
Если для процессов и пустых пространств ведутся разные списки, то для более бы-
строго обнаружения наиболее подходящих свободных мест список пустых пространств
должен сортироваться по размеру. Когда при работе алгоритма «наиболее подходящее»
поиск пустых пространств ведется от самых маленьких до самых больших, то при обна-
ружении подходящего пространства становится понятно, что найденное пространство
является наименьшим, в котором может быть выполнено задание, следовательно, оно
и есть наиболее подходящее. Дальнейший поиск, как при системе, использующей один
список, уже не потребуется. При использовании списка пустых пространств, отсор-
тированного по размеру, алгоритмы «первое подходящее» и «наиболее подходящее»
работают с одинаковой скоростью, а алгоритм «следующее подходящее» теряет смысл.
Когда список пустых пространств ведется отдельно от списка процессов, можно прове-
сти небольшую оптимизацию. Вместо того чтобы создавать отдельный набор структур
данных для обслуживания списка пустых пространств, как это сделано на рис. 3.6, в,
можно хранить информацию в самих пустых пространствах. В первом слове каждого
пустого пространства может содержаться размер этого пространства, а второе слово
может служить указателем на следующую запись. Элементы списка, показанного на
рис. 3.6, в, для которых требуются три слова и один бит (P/H), больше не нужны.
Еще один алгоритм распределения памяти называется «быстро искомое подходящее».
Его использование предусматривает ведение отдельных списков для некоторых наи-
более востребованных искомых размеров. К примеру, у него может быть таблица из
n записей, в которой первая запись является указателем на вершину списка пустых
пространств размером 4 Кбайт, вторая — указателем на список пустых пространств раз-
мером 8 Кбайт, третья — указателем на список пустых пространств размером 12 Кбайт
и т. д. Пустые пространства размером, скажем, 21 Кбайт могут быть помещены либо
в список пустых пространств размером 20 Кбайт, либо в специальный список пустых
пространств с нечетным размером.
При использовании алгоритма «быстро искомое подходящее» поиск пустого про-
странства требуемого размера выполняется исключительно быстро, но в нем имеется
недостаток, присущий всем системам, сортирующим пустые пространства по размеру,
а именно когда процесс завершается или выгружается процедурой свопинга, слишком
много времени тратится на то, чтобы определить, можно ли высвобождаемое простран-
ство объединить с соседними. Если не проводить объединение, то память очень быстро
окажется разбитой на большое количество небольших по размеру пустых фрагментов,
в которых не смогут поместиться процессы.
3.3. Виртуальная память
В то время как для создания абстракции адресного пространства могут быть исполь-
зованы базовые и ограничительные регистры, нужно решить еще одну проблему:
управления ресурсоемким программным обеспечением. Несмотря на быстрый рост

228
Глава 3. Управление памятью
объемов памяти, объемы, требующиеся программному обеспечению, растут намного
быстрее. В 1980-е годы многие университеты работали на машинах VAX, имеющих па-
мять объемом 4 Мбайт, под управлением систем с разделением времени, которые одно-
временно обслуживали с десяток (более или менее удовлетворенных) пользователей.
Теперь корпорация Microsoft рекомендует использовать как минимум 2 Гбайт памяти
для 64-разрядной Windows 8. Тенденция к использованию мультимедиа предъявляет
к объему памяти еще более весомые требования.
Последствия такого развития выразились в необходимости запуска программ, объем
которых не позволяет им поместиться в памяти, при этом конечно же возникает потреб-
ность в системах, поддерживающих несколько одновременно запущенных программ,
каждая из которых помещается в памяти, но все вместе они превышают имеющийся
объем памяти. Свопинг — не слишком привлекательный выбор, поскольку обычный
диск с интерфейсом SATA обладает пиковой скоростью передачи данных в несколько
сотен мегабайт в секунду, а это означает, что свопинг программы объемом 1 Гбайт
займет секунды, и еще столько же времени будет потрачено на загрузку другой про-
граммы в 1 Гбайт.
Проблемы программ, превышающих по объему размер имеющейся памяти, возникли
еще на заре компьютерной эры, правда, проявились они в таких узких областях, как
решение научных и прикладных задач (существенные объемы памяти требуются
для моделирования возникновения Вселенной или даже для авиасимулятора нового
самолета). В 1960-е годы было принято решение разбивать программы на небольшие
части, называемые оверлеями. При запуске программы в память загружался только
администратор оверлейной загрузки, который тут же загружал и запускал оверлей
с порядковым номером 0. Когда этот оверлей завершал свою работу, он мог сообщить
администратору загрузки оверлеев о необходимости загрузки оверлея 1 либо выше
оверлея 0, находящегося в памяти (если для него было достаточно пространства), либо
поверх оверлея 0 (если памяти не хватало). Некоторые оверлейные системы имели до-
вольно сложное устройство, позволяя множеству оверлеев одновременно находиться
в памяти. Оверлеи хранились на диске, и их свопинг с диска в память и обратно осу-
ществлялся администратором загрузки оверлеев.
Хотя сама работа по свопингу оверлеев с диска в память и обратно выполнялась
операционной системой, разбиение программ на части выполнялось программистом
в ручном режиме. Разбиение больших программ на небольшие модульные части было
очень трудоемкой, скучной и не застрахованной от ошибок работой. Преуспеть в этом
деле удавалось далеко не всем программистам. Прошло не так много времени, и был
придуман способ, позволяющий возложить эту работу на компьютер.
Изобретенный метод (Fotheringham, 1961) стал известен как виртуальная память.
В основе виртуальной памяти лежит идея, что у каждой программы имеется собствен-
ное адресное пространство, которое разбивается на участки, называемые страницами.
Каждая страница представляет собой непрерывный диапазон адресов. Эти страницы
отображаются на физическую память, но для запуска программы одновременное при-
сутствие в памяти всех страниц необязательно. Когда программа ссылается на часть
своего адресного пространства, находящегося в физической памяти, аппаратное обе-
спечение осуществляет необходимое отображение на лету. Когда программа ссылается
на часть своего адресного пространства, которое не находится в физической памяти,
операционная система предупреждается о том, что необходимо получить недостающую
часть и повторно выполнить потерпевшую неудачу команду.

3.3. Виртуальная память
229
В некотором смысле виртуальная память является обобщением идеи базового и огра-
ничительного регистров. У процессора 8088 было несколько отдельных базовых реги-
стров (но не было ограничительных регистров) для текста и данных программы. При
использовании виртуальной памяти вместо отдельного перемещения только сегмента
текста или только сегмента данных программы на физическую память в сравнительно
небольших блоках может быть отображено все адресное пространство. Реализация
виртуальной памяти будет показана далее.
Виртуальная память неплохо работает и в многозадачных системах, когда в памяти
одновременно содержатся составные части многих программ. Пока программа ждет
считывания какой-либо собственной части, центральный процессор может быть отдан
другому процессу.
3.3.1. Страничная организация памяти
Большинство систем виртуальной памяти используют технологию под названием стра-
ничная организация памяти
(paging), к описанию которой мы сейчас и приступим. На
любом компьютере программы ссылаются на набор адресов памяти. Когда программа
выполняет команду
MOV REG,1000
она осуществляет копирование содержимого ячейки памяти с адресом 1000 в REG
(или наоборот, в зависимости от компьютера). Адреса могут генерироваться с исполь-
зованием индексной адресации, базовых регистров, сегментных регистров и другими
способами.
Такие сгенерированные программным способом адреса называются виртуальными
адресами
, именно они и формируют виртуальное адресное пространство. На ком-
пьютерах, не использующих виртуальную память, виртуальные адреса выставляются
непосредственно на шине памяти, что приводит к чтению или записи слова физической
памяти с таким же адресом. При использовании виртуальной памяти виртуальные
адреса не выставляются напрямую на шине памяти. Вместо этого они поступают в дис-
петчер памяти
(Memory Management Unit (MMU)), который отображает виртуальные
адреса на адреса физической памяти (рис. 3.8).
Очень простой пример работы такого отображения показан на рис. 3.9. В этом при-
мере у нас есть компьютер, генерирующий 16-разрядные адреса, от 0 и до 64K – 1. Это
виртуальные адреса. Но у этого компьютера есть только 32 Кбайт физической памяти.
И хотя для него можно написать программы объемом 64 Кбайт, целиком загрузить
в память и запустить такие программы не представляется возможным. Но полный ду-
бликат содержимого памяти всей программы, вплоть до 64 Кбайт, может размещаться
на диске, позволяя вводить ее по частям по мере надобности.
Виртуальное адресное пространство состоит из блоков фиксированного размера, на-
зываемых страницами. Соответствующие блоки в физической памяти называются
страничными блоками
. Страницы и страничные блоки имеют, как правило, одина-
ковые размеры. В нашем примере их размер составляет 4 Кбайт, но в реальных си-
стемах используются размеры страниц от 512 байт до 1 Гбайт. При наличии 64 Кбайт
виртуального адресного пространства и 32 Кбайт физической памяти мы получаем
16 виртуальных страниц и 8 страничных блоков. Перенос информации между опе-
ративной памятью и диском всегда осуществляется целыми страницами. Многие
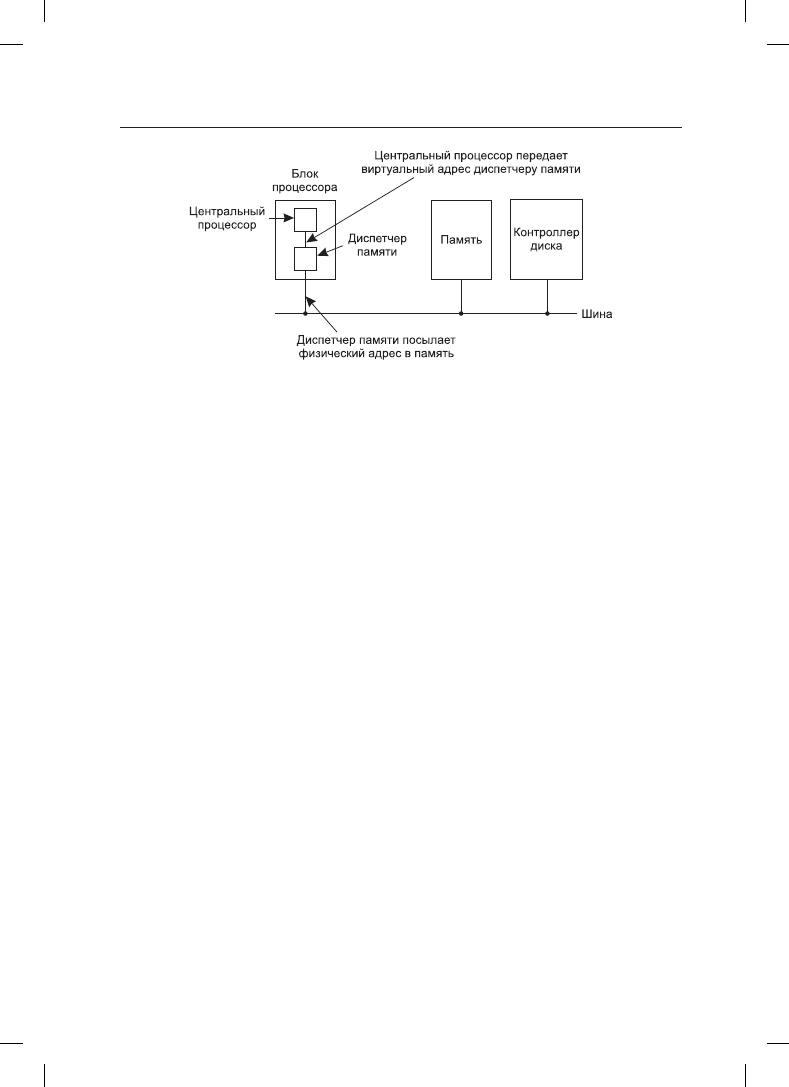
230
Глава 3. Управление памятью
Рис. 3.8. Расположение и предназначение диспетчера памяти. Здесь он показан в составе
микросхемы центрального процессора, как это чаще всего и бывает в наши дни. Но логически
он может размещаться и в отдельной микросхеме, как было в прошлом
процессоры поддерживают несколько размеров страниц, которые могут быть смешаны
и подобраны по усмотрению операционной системы. Например, архитектура x86-64
поддерживает страницы размером 4 Кбайт, 2 Мбайт и 1 Гбайт, поэтому для пользова-
тельских приложений можно использовать страницы размером 4 Кбайт, а для ядра —
одну страницу размером 1 Гбайт. Почему иногда лучше использовать одну большую
страницу, а не много маленьких, будет объяснено позже.
На рис. 3.9 приняты следующие обозначения. Диапазон, помеченный 0K–4K, означает,
что виртуальные или физические адреса этой страницы составляют от 0 до 4095. Диа-
пазон 4K–8K ссылается на адреса от 4096 до 8191 и т. д. Каждая страница содержит
строго 4096 адресов, которые начинаются с чисел, кратных 4096, и заканчиваются
числами на единицу меньше чисел, кратных 4096.
К примеру, когда программа пытается получить доступ к адресу 0, используя команду
MOV REG,0
диспетчеру памяти посылается виртуальный адрес 0. Диспетчер видит, что этот вир-
туальный адрес попадает в страницу 0 (от 0 до 4095), которая в соответствии со своим
отображением представлена страничным блоком 2 (от 8192 до 12 287). Соответственно,
он трансформируется в адрес 8192, который и выставляется на шину. Память вообще
не знает о существовании диспетчера и видит только запрос на чтение или запись по
адресу 8192, который и выполняет. Таким образом диспетчер памяти эффективно
справляется с отображением всех виртуальных адресов между 0 и 4095 на физические
адреса от 8192 до 12 287.
Аналогично этому команда
MOV REG,8192
эффективно преобразуется в
MOV REG,24576
поскольку виртуальный адрес 8192 (в виртуальной странице 2) отображается на
24 576 (в физической странице 6). В качестве третьего примера виртуальный адрес
20 500 отстоит на 20 байт от начала виртуальной страницы 5 (виртуальные адреса от
20 480 до 24 575) и отображается на физический адрес 12 288 + 20 = 12 308.