Добавлен: 29.10.2018
Просмотров: 48091
Скачиваний: 190
286
Глава 3. Управление памятью
больше не играют ту же роль и не предлагают реальную сегментацию. Но системы x86-32
до сих пор поставляются оборудованными по полной схеме, и именно этот центральный
процессор и будет рассматриваться в данном разделе.
Основа виртуальной памяти системы x86 состоит их двух таблиц: локальной таблицы
дескрипторов
(Local Descriptor Table (LDT)) и глобальной таблицы дескрипторов
(Global Descriptor Table (GDT)). У каждой программы есть собственная таблица LDT,
но глобальная таблица дескрипторов, которую совместно используют все программы
в компьютере, всего одна. В таблице LDT описываются сегменты, локальные для каж-
дой программы, включая код этих программ, их данные, стек и т. д., а в таблице GDT
описываются системные сегменты, включая саму операционную систему.
Чтобы получить доступ к сегменту, программа, работающая в системе x86, сначала за-
гружает селектор для этого сегмента в один из шести сегментных регистров машины.
Во время выполнения программы регистр CS содержит селектор для сегмента кода,
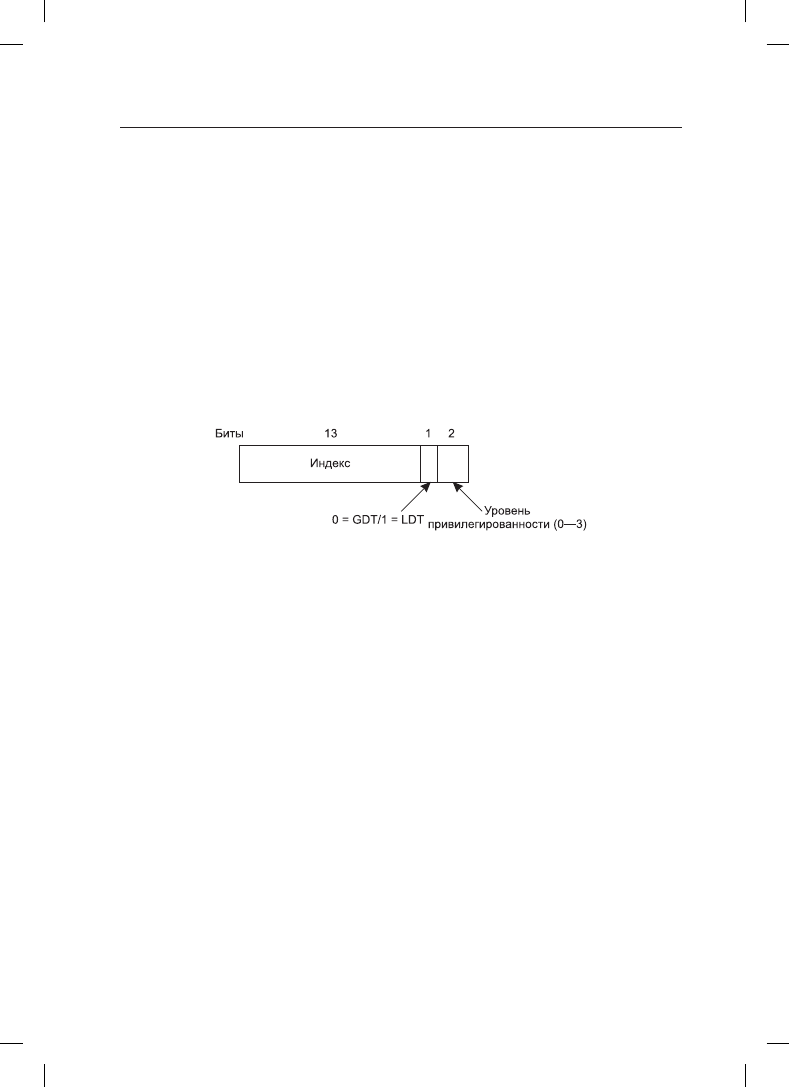
а регистр DS хранит селектор для сегмента данных. Каждый селектор (рис. 3.35) пред-
ставляет собой 16-разрядное целое число.
Рис. 3.35. Селектор системы Pentium
Один из битов селектора несет информацию о том, является ли данный сегмент локаль-
ным или глобальным (то есть к какой таблице дескрипторов он относится, локальной
или глобальной). Следующие 13 битов определяют номер записи в таблице дескрипто-
ров, поэтому в каждой из этих таблиц не может содержаться более чем 8 К сегментных
дескрипторов. Остальные 2 бита имеют отношение к защите и будут рассмотрены
позже. Дескриптор 0 запрещен. Его можно без всякой опаски загрузить в сегментный
регистр, чтобы обозначить, что этот сегментный регистр в данный момент недоступен.
Попытка им воспользоваться приведет к системному прерыванию.
Во время загрузки селектора в сегментный регистр из локальной или глобальной
таблицы дескрипторов извлекается соответствующий дескриптор, который, чтобы
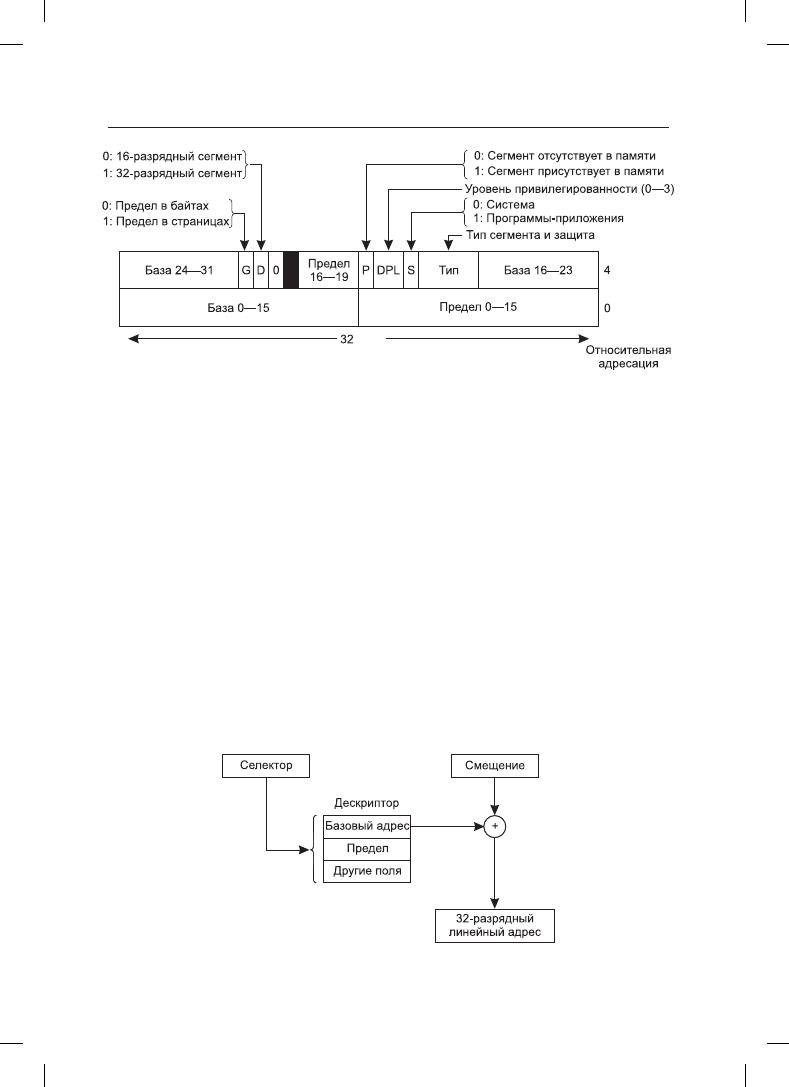
ускорить к нему обращение, сохраняется в микропрограммных регистрах. Как показано
на рис. 3.36, дескриптор состоит из 8 байтов, в которые входят базовый адрес сегмента,
размер и другая информация.
Чтобы облегчить определение местоположения дескриптора, был искусно подобран
формат селектора. Сначала на основе бита 2 селектора выбирается локальная или
глобальная таблица дескрипторов. Затем селектор копируется во внутренний рабочий
регистр, и значения трех младших битов устанавливаются в 0. Наконец, к этой копии
прибавляется адрес одной из таблиц, LDT или GDT, чтобы получить прямой указатель
на дескриптор. Например, селектор 72 ссылается на запись 9 в глобальной таблице
дескрипторов, которая расположена по адресу в таблице GDT + 72.
Теперь проследим шаги, с помощью которых пара (селектор, смещение) преобразуется
в физический адрес. Как только микропрограмма узнает, какой сегментный регистр
3.7. Сегментация
287
бита
Рис. 3.36. Дескриптор сегмента кода в системе Pentium.
Сегменты данных имеют незначительные отличия
используется, она может найти в своих внутренних регистрах полный дескриптор, со-
ответствующий этому селектору. Если сегмент не существует (селектор равен 0) или
в данный момент выгружен, возникает системное прерывание.
Затем аппаратура использует поле предела Limit, чтобы проверить, не выходит ли сме-
щение за предел сегмента, и в этом случае также возникает системное прерывание. По
логике, для предоставления размера сегмента в дескрипторе должно быть 32-разрядное
поле, но доступны только 20 бит, поэтому используется другая схема. Если поле Gbit
(Granularity — степень детализации) равно 0, в поле Limit содержится точный размер
сегмента вплоть до 1 Мбайт. Если оно равно 1, то в поле Limit предоставляется размер
сегмента в страницах, а не в байтах. При размере страниц, равном 4 Кбайт, 20 битов
вполне достаточно для сегментов размером до 2
32
байт.
Предположим, что сегмент находится в памяти и смещение попало в нужный интервал,
тогда система x86 прибавляет 32-разрядное поле Base (база) в дескрипторе к смеще-
нию, формируя то, что называется линейным адресом (рис. 3.37). Поле Base разбито
на три части, которые разбросаны по дескриптору для совместимости с процессором
Intel 80286, в котором поле Base имеет только 24 бита. В сущности, поле Base позволяет
каждому сегменту начинаться в произвольном месте внутри 32-разрядного линейного
адресного пространства.
Рис. 3.37. Преобразование пары «селектор — смещение» в линейный адрес
288
Глава 3. Управление памятью
Если страничная организация отключена (установкой бита в глобальном управляю-
щем регистре), линейный адрес интерпретируется как физический адрес и посылается
в память для чтения или записи. Таким образом, при отключенной страничной схеме
памяти мы получаем чистую схему сегментации с базовым адресом каждого сегмента,
выдаваемым его дескриптором. Сегменты не предохранены от наложения друг на друга,
возможно, из-за слишком больших хлопот и слишком больших временных затрат на
проверку того факта, что все они друг от друга отделены.
С другой стороны, если включена подкачка страниц, линейный адрес интерпрети-
руется как виртуальный и отображается на физический адрес с помощью таблицы
страниц практически так же, как в предыдущих примерах. Единственное реальное
затруднение заключается в том, что при 32-разрядном виртуальном адресе и странице
размером 4 Кбайт сегмент может содержать 1 млн страниц, поэтому используется
двухуровневое отображение с целью уменьшения размера таблицы страниц для не-
больших сегментов.
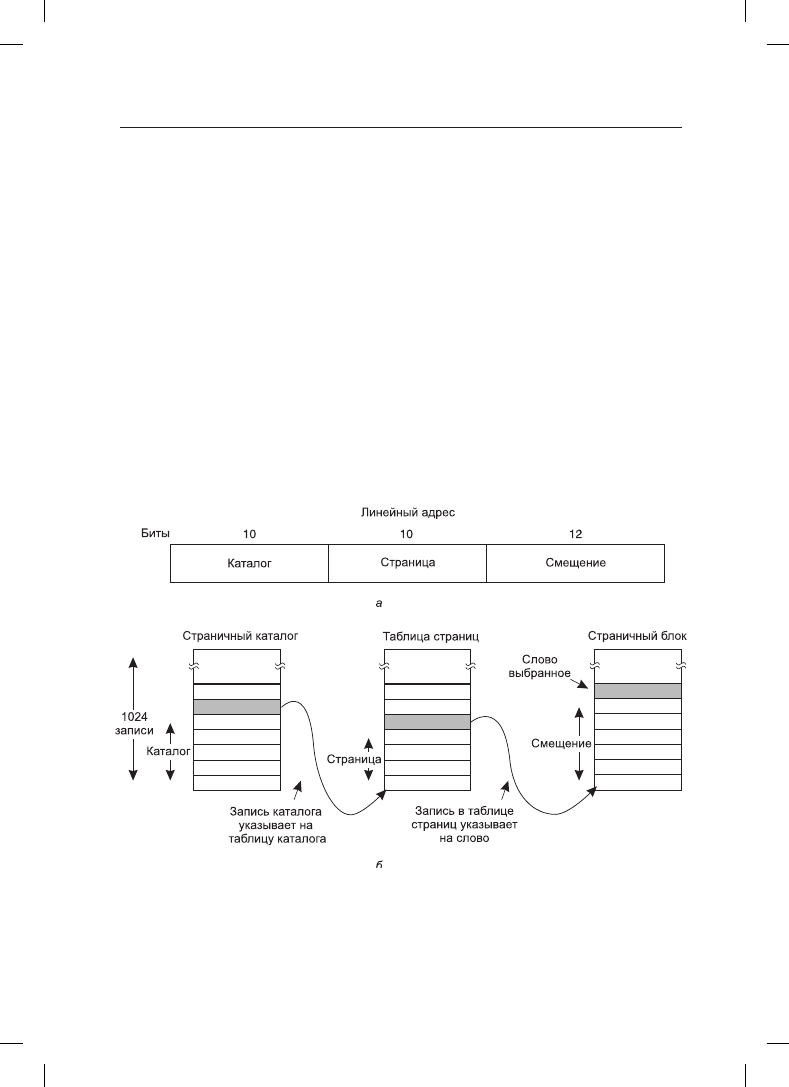
У каждой работающей программы есть страничный каталог, состоящий из 1024 32-раз-
рядных записей. Он расположен по адресу, который указан в глобальном регистре.
Каждая запись в каталоге указывает на таблицу страниц, также содержащую 1024
32-разрядных записи. Записи в таблицах страниц, в свою очередь, указывают на стра-
ничные блоки. Эта схема показана на рис. 3.38.
Рис. 3.38. Отображение линейного адреса на физический
Здесь показан линейный адрес, разделенный на три поля: Каталог, Страница и Сме-
щение. Поле Каталог используется как индекс в страничном каталоге, определяющий
расположение указателя на правильную таблицу страниц. Поле Страница использует-

3.7. Сегментация
289
ся в качестве индекса в таблице страниц, чтобы найти физический адрес страничного
блока. И наконец, чтобы получить физический адрес требуемого байта или слова,
к адресу страничного блока прибавляется поле Смещение.
Каждая запись в таблице страниц имеет размер 32 бита, 20 из которых содержат номер
страничного блока. Остальные биты включают в себя биты доступа и бит изменения
страницы, устанавливаемые аппаратурой для операционной системы, биты защиты
и другие полезные биты.
Каждая таблица страниц включает в себя записи для 1024 страничных блоков размером
по 4 Кбайт, таким образом, одна таблица страниц справляется с 4 Мбайт памяти. Сег-
мент, длина которого меньше 4 Мбайт, будет иметь страничный каталог с единственной
записью — указателем на его единственную таблицу страниц. Следовательно, в случае
короткого сегмента на поддержку таблиц страниц расходуется только две страницы
вместо 1 млн, которые были бы нужны в одноуровневой таблице страниц.
Чтобы избежать повторных обращений к памяти, система x86, как и система MULTICS,
имеет небольшой буфер быстрого преобразования адреса (TLB), который напрямую
отображает наиболее часто использующиеся комбинации Каталог — Страница на
физический адрес страничного блока. Механизм, показанный на рис. 3.38, задейству-
ется лишь при отсутствии текущей комбинации в буфере TLB, при этом сам буфер
обновляется. Если отсутствие нужной информации в буфере TLB встречается довольно
редко, система достигает неплохой производительности.
Также следует отметить, что эта модель работает и в том случае, когда некоторые
приложения не требуют сегментации, а просто довольствуются единым, разбитым на
страницы 32-разрядным адресным пространством. Все сегментные регистры могут
быть настроены тем же самым селектором, в дескрипторе которого поле Base = 0, а поле
Limit установлено на максимум. Тогда смещение команды будет линейным адресом
и будет использоваться только одно адресное пространство, что приведет к обычной
страничной организации памяти. Фактически таким образом работают все современ-
ные операционные системы для компьютера x86. Единственным исключением была
система OS/2, в которой использовались все возможности архитектуры диспетчера
памяти (MMU) фирмы Intel.
Так почему же Intel отменила то, что было вариантом весьма неплохой модели памяти
MULTICS, поддерживаемой на протяжении почти трех десятилетий? Возможно, ос-
новной причиной стало то, что ни UNIX, ни Windows никогда не использовали этот
вариант, несмотря на его высокую эффективность, по причине исключения системных
вызовов и превращения их в молниеносные вызовы процедур по соответствующим
адресам внутри защищенного сегмента операционной системы. Ни один из разработ-
чиков любой UNIX- или Windows-системы не захотел менять свою модель памяти
на нечто присущее только x86, так как это нарушило бы переносимость на другие
платформы. Поскольку эта возможность оказалась невостребованной со стороны про-
граммного обеспечения, компании Intel надоело тратить впустую площадь микросхемы
на ее поддержку и из 64-разрядных процессоров она была убрана.
В конце концов, кто-то же должен похвалить разработчиков системы x86. При столь
противоречивых задачах: реализовать чистую страничную организацию памяти, чистое
сегментирование и страничные сегменты и в то же время обеспечить совместимость
с 286-м процессором, а кроме того, сделать все это эффективно, — у них получилась
удивительно простая и понятная конструкция.

290
Глава 3. Управление памятью
3.8. Исследования в области управления памятью
Традиционное управление памятью, особенно алгоритмы замещения страниц для цен-
тральных процессоров с одним ядром, когда-то было весьма плодотворной областью
исследований, но, похоже, большая часть этих исследований, по крайней мере для
универсальных систем, в настоящее время уже отмерла, хотя имеются и те, кто с этим
категорически не согласен (Moruz et al., 2012) или сосредоточился на некоторых при-
ложениях, таких как оперативная обработка транзакций, которая имеет специализи-
рованные требования (Stoica and Ailamaki, 2013). Даже на однопроцессорных системах
замещение страниц на твердотельных накопителях, а не на жестких дисках вызвало
новые вопросы и потребовало новых алгоритмов (Chen et al., 2012). Замещение страниц
на многообещающей энергонезависимой памяти на основе фазовых переходов также
потребовало переосмысления этого замещения с целью повышения производительно-
сти (Lee et al., 2013), а также по причине задержек (Saito and Oikawa, 2012) или износа
при слишком интенсивном использовании (Bheda et al., 2011, 2012).
В целом исследования по замещению страниц все еще продолжаются, но сосредотачи-
ваются на новых видах систем. Например, интерес к управлению памятью возродили
виртуальные машины (Bugnion et al., 2012). К той же области относится и работа Jantz
et al. (2013), позволяющая приложениям ориентировать систему относительно приня-
тия решения о физической странице для поддержки виртуальной страницы. Требует
новых алгоритмов и аспект объединения серверов в облаке, что влияет на замещение
страниц из-за возможности изменения со временем того объема физической памяти,
который доступен виртуальной машине (Peserico, 2013).
Новой областью активных исследований стало замещение страниц в многоядерных
системах (Boyd-Wickizer et al., 2008, Baumann et al., 2009). Одним из побуждающих
факторов является стремление иметь в многоядерных системах множество кэшей, со-
вместно используемых довольно сложными путями (Lopez-Ortiz and Salinger, 2012).
Тесно связанным с этой работой по многоядерности является исследование замещения
страниц в NUMA-системах, где к разным частям памяти может быть разное время до-
ступа (Dashti et al., 2013; Lankes et al., 2012).
Кроме того, в небольшие персональные компьютеры превратились смартфоны и план-
шетные устройства, и многие из них сбрасывают страницы оперативной памяти на
«диск», вот только в качестве диска у них выступает флеш-память. О некоторых по-
следних работах имеется сообщение от Joo et al. (2012).
И наконец, по-прежнему существует интерес к управлению памятью в системах реаль-
ного времени (Kato et al., 2011).
3.9. Краткие выводы
Эта глава была посвящена исследованию вопросов управления памятью. Мы увидели,
что свопинг или страничная организация памяти в простейших системах вообще не
используются. Программа, загруженная в память, остается в ней до своего завершения.
Некоторые операционные системы не позволяют находиться в памяти более чем од-
ному процессу, в то время как другие поддерживают многозадачность. Эта модель все
еще распространена на небольших встроенных системах реального времени.