Добавлен: 29.10.2018
Просмотров: 48120
Скачиваний: 190
356
Глава 4. Файловые системы
слова будет в четыре раза медленнее, но к этому следует добавить 5–10 мс на установ-
ку головок на дорожку и ожидание, когда под головку подойдет нужный сектор. Если
нужно считать только одно слово, то доступ к памяти примерно в миллион раз бы-
стрее, чем доступ к диску. В результате такой разницы во времени доступа во многих
файловых системах применяются различные усовершенствования, предназначенные
для повышения производительности. В этом разделе будут рассмотрены три из них.
Кэширование
Наиболее распространенным методом сокращения количества обращений к диску
является блочное кэширование или буферное кэширование. (Термин «кэш» про-
исходит от французского cacher — скрывать.) В данном контексте кэш представляет
собой коллекцию блоков, логически принадлежащих диску, но хранящихся в памяти
с целью повышения производительности.
Для управления кэшем могут применяться различные алгоритмы, но наиболее рас-
пространенный из них предусматривает проверку всех запросов для определения того,
имеются ли нужные блоки в кэше. Если эти блоки в кэше имеются, то запрос на чтение
может быть удовлетворен без обращения к диску. Если блок в кэше отсутствует, то он
сначала считывается в кэш, а затем копируется туда, где он нужен. Последующий запрос
к тому же самому блоку может быть удовлетворен непосредственно из кэша.
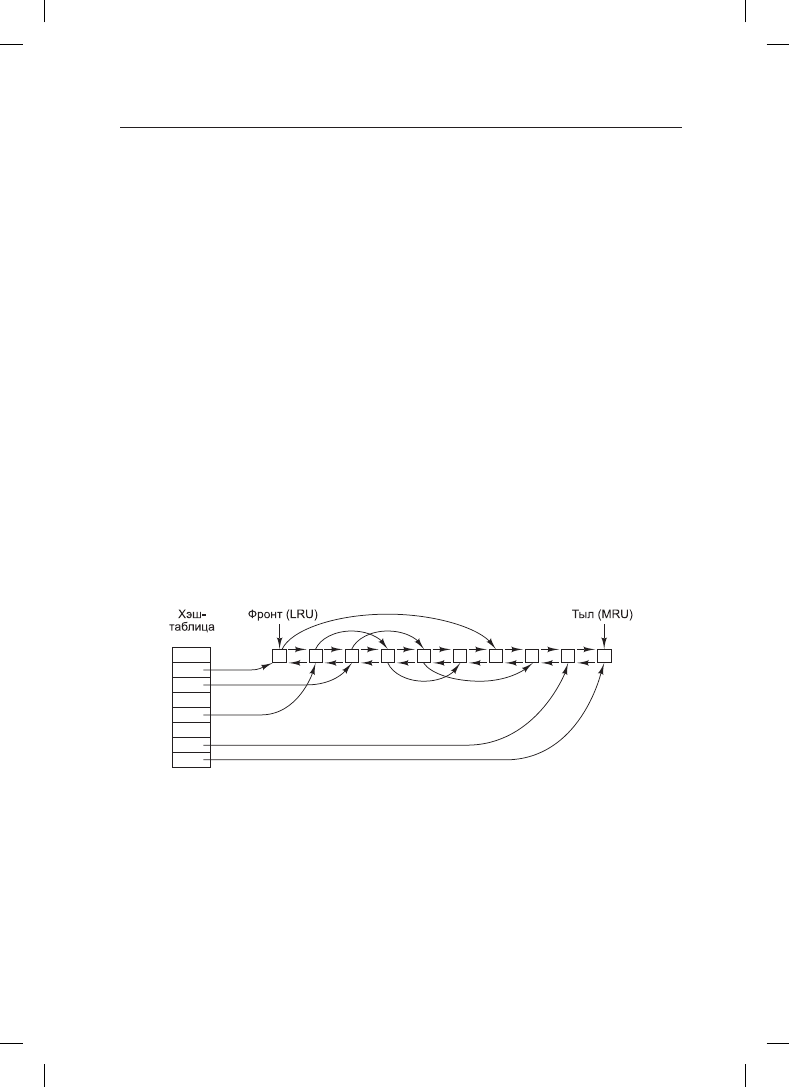
Работа кэша показана на рис. 4.24. Поскольку в кэше хранится большое количество
(обычно несколько тысяч) блоков, нужен какой-нибудь способ быстрого определения,
присутствует ли заданный блок в кэше или нет. Обычно хэшируются адрес устройства
и диска, а результаты ищутся в хэш-таблице. Все блоки с таким же значением хэша
собираются в цепочку (цепочку коллизий) в связанном списке.
Рис. 4.24. Структура данных буферного кэша
Когда блок необходимо загрузить в заполненный кэш, какой-то блок нужно удалить
(и переписать на диск, если он был изменен со времени его помещения в кэш). Эта
ситуация очень похожа на ситуацию со страничной организацией памяти, и все
общепринятые алгоритмы замещения страниц, рассмотренные в главе 3, включая
FIFO, «второй шанс» и LRU, применимы и в данной ситуации. Одно приятное от-
личие кэширования от страничной организации состоит в том, что обращения к кэшу
происходят относительно нечасто, поэтому вполне допустимо хранить все блоки
в строгом порядке LRU (замещения наименее востребованного блока), используя
связанные списки.

4.4. Управление файловой системой и ее оптимизация
357
На рис. 4.24 показано, что в дополнение к цепочкам коллизий, начинающихся в хэш-
таблице, используется также двунаправленный список, в котором содержатся номера
всех блоков в порядке их использования, с наименее востребованным блоком (LRU)
в начале этого списка и с наиболее востребованным блоком (MRU) в его конце. Когда
происходит обращение к блоку, он может удаляться со своей позиции в двунаправлен-
ном списке и помещаться в его конец. Таким образом может поддерживаться точный
LRU-порядок.
К сожалению, здесь имеется один подвох. Теперь, когда сложилась ситуация, позволяю-
щая в точности применить алгоритм LRU, оказывается, что это как раз и нежелательно.
Проблема возникает из-за сбоев и требований непротиворечивости файловой системы,
рассмотренных в предыдущем разделе. Если какой-нибудь очень важный блок, на-
пример блок i-узла, считывается в кэш и изменяется, но не переписывается на диск,
то сбой оставляет файловую систему в противоречивом состоянии. Если блок i-узла
помещается в конец LRU-цепочки, может пройти довольно много времени, перед тем
как он достигнет ее начала и будет записан на диск.
Более того, к некоторым блокам, например блокам i-узлов, редко обращаются дважды
за короткий промежуток времени. Исходя из этих соображений можно прийти к мо-
дифицированной LRU-схеме, в которой берутся в расчет два фактора:
1. Велика ли вероятность того, что данный блок вскоре снова понадобится?
2. Важен ли данный блок с точки зрения непротиворечивости файловой системы?
При ответе на оба вопроса блоки могут быть разделены на такие категории, как блоки
i-узлов, косвенные блоки, блоки каталогов, заполненные блоки данных и частично
заполненные блоки данных. Блоки, которые, возможно, в ближайшее время не пона-
добятся, помещаются в начало, а не в конец списка LRU, поэтому вскоре занимаемые
ими буферы будут использованы повторно. Блоки, которые вскоре могут снова по-
надобиться, например частично заполненные блоки, в которые производится запись,
помещаются в конец списка, поэтому они останутся в кэше надолго.
Второй вопрос не связан с первым. Если блок важен для непротиворечивости файло-
вой системы (в основном таковы все блоки, за исключением блоков данных) и он был
изменен, его тут же нужно записать на диск независимо от того, в каком конце LRU-
списка он находится. Быстрая запись важных блоков существенно снижает вероятность
аварии файловой системы. Конечно, пользователь может расстроиться, если один из
его файлов будет поврежден в случае аварии, но он расстроится еще больше, если будет
потеряна вся файловая система.
Даже при таких мерах сохранения целостности файловой системы, слишком долгое
хранение в кэше блоков данных без их записи на диск также нежелательно. Войдем
в положение писателя, который работает на персональном компьютере. Даже если он
периодически заставляет редактор текста сбрасывать редактируемый файл на диск,
есть вполне реальная вероятность того, что весь его труд все еще находится в кэше, а на
диске ничего нет. Если произойдет сбой, структура файловой системы повреждена не
будет, но вся работа за день окажется утрачена.
Подобная ситуация складывается нечасто, если только не попадется слишком неве-
зучий пользователь. Чтобы справиться с этой проблемой, система может применять
два подхода. В UNIX используется системный вызов sync, вынуждающий немедленно
записать все измененные блоки на диск. При запуске системы в фоновом режиме
начинает действовать программа, которая обычно называется
update
. Она работает

358
Глава 4. Файловые системы
в бесконечном цикле и осуществляет вызовы sync, делая паузу в 30 с между вызовами.
В результате при аварии теряется работа не более чем за 30 с.
Хотя в Windows теперь есть системный вызов, эквивалентный sync, который называ-
ется FlushFileBuffers, в прошлом такого вызова не было. Вместо этого использовалась
другая стратегия, которая в чем-то была лучше, чем подход, используемый в UNIX (но
в чем-то хуже). При ее применении каждый измененный блок записывался на диск
сразу же, как только попадал в кэш. Кэш, в котором все модифицированные блоки
немедленно записываются обратно на диск, называется кэшем со сквозной записью.
Он требует большего объема операций дискового ввода-вывода по сравнению с кэшем
без сквозной записи.
Различия между этими двумя подходами можно заметить, когда программа посимволь-
но записывает полный блок размером 1 Кбайт. Система UNIX будет собирать все сим-
волы в кэше и записывать блок на диск или каждые 30 с, или в случае, когда блок будет
удаляться из кэша. При использовании кэша со сквозной записью обращение к диску
осуществляется при записи каждого символа. Разумеется, большинство программ
выполняют внутреннюю буферизацию, поэтому, как правило, они записывают при
каждом системном вызове write не символ, а строку или еще более крупный фрагмент.
Последствия этого различия в стратегии кэширования состоят в том, что удаление дис-
ка из системы UNIX без осуществления системного вызова sync практически никогда
не обходится без потери данных, а часто приводит еще и к повреждению файловой
системы. При кэшировании со сквозной записью проблем не возникает. Столь разные
стратегии были выбраны из-за того, что система UNIX разрабатывалась в среде, где
все используемые диски были жесткими и не удалялись из системы, а первая файловая
система Windows унаследовала свои черты у MS-DOS, которая вышла из мира гибких
дисков. Когда в обиход вошли жесткие диски, стал нормой подход, реализованный
в UNIX, обладающий более высокой эффективностью (но меньшей надежностью),
и теперь он также используется для жестких дисков в системе Windows. Но в файловой
системе NTFS, как рассматривалось ранее, для повышения надежности предприняты
другие меры (например, журналирование).
В некоторых операционных системах буферное кэширование объединено со странич-
ным. Такое объединение особенно привлекательно при поддержке файлов, отобража-
емых на память. Если файл отображен на память, то некоторые из его страниц могут
находиться в памяти, поскольку они были востребованы. Такие страницы вряд ли
отличаются от файловых блоков в буферном кэше. В таком случае они могут рас-
сматриваться одинаковым образом в едином кэше, используемом как для файловых
блоков, так и для страниц.
Опережающее чтение блока
Второй метод, улучшающий воспринимаемую производительность файловой системы,
заключается в попытке получить блоки в кэш еще до того, как они понадобятся, чтобы
повысить соотношение удачных обращений к кэшу. В частности, многие файлы чита-
ются последовательно. Когда у файловой системы запрашивается блок k какого-нибудь
файла, она выполняет запрос, но, завершив его выполнение, проверяет присутствие
в кэше блока k + 1. Если этот блок в нем отсутствует, она планирует чтение блока k + 1
в надежде, что, когда он понадобится, он уже будет в кэше. В крайнем случае уже будет
в пути.

4.4. Управление файловой системой и ее оптимизация
359
Разумеется, стратегия опережающего чтения работает только для тех файлов, которые
считываются последовательно. При произвольном обращении к файлу опережающее
чтение не поможет. Будет досадно, если скорость передачи данных с диска снизится
из-за чтения бесполезных блоков и ради них придется удалять полезные блоки из кэша
(и, возможно, при этом еще больше снижая скорость передачи данных с диска из-за
возвращения на него измененных блоков). Чтобы определить, стоит ли использовать
опережающее чтение блоков, файловая система может отслеживать режим доступа
к каждому открытому файлу. К примеру, в связанном с каждым файлом бите можно
вести учет режима доступа к файлу, устанавливая его в режим последовательного до-
ступа или в режим произвольного доступа. Изначально каждому открываемому файлу
выдается кредит доверия, и бит устанавливается в режим последовательного доступа.
Но если для этого файла проводится операция позиционирования указателя текущей
позиции в файле, бит сбрасывается. При возобновлении последовательного чтения бит
будет снова установлен. Благодаря этому файловая система может выстраивать вполне
обоснованные догадки о необходимости опережающего чтения. И ничего страшного,
если время от времени эти догадки не будут оправдываться, поскольку это приведет
всего лишь к незначительному снижению потока данных с диска.
Сокращение количества перемещений блока головок диска
Кэширование и опережающее чтение — далеко не единственные способы повышения
производительности файловой системы. Еще одним важным методом является сокра-
щение количества перемещений головок диска за счет размещения блоков с высокой
степенью вероятности обращений последовательно, рядом друг с другом, предпочти-
тельно на одном и том же цилиндре. При записи выходного файла файловой системе
нужно распределить блоки по одному в соответствии с этим требованием. Если запись
о свободных блоках ведется в битовом массиве и весь этот массив находится в памя-
ти, несложно выбрать свободный блок как можно ближе к предыдущему блоку. Если
ведется список свободных блоков, часть из которых находится на диске, то задача раз-
мещения блоков как можно ближе друг к другу значительно усложняется.
Но даже при использовании списка свободных блоков несколько блоков можно объеди-
нить в кластеры. Секрет в том, чтобы отслеживать пространство носителя не в блоках,
а в группах последовательных блоков. Если все сектора содержат 512 байт, в системе
могут использоваться блоки размером 1 Кбайт (2 сектора), но дисковое пространство
может распределяться единицами по 2 блока (4 сектора). Это не похоже на использова-
ние дисковых блоков по 2 Кбайт, поскольку в кэше по-прежнему будут использоваться
блоки размером 1 Кбайт и передача данных с диска будет вестись блоками размером
1 Кбайт, но последовательное чтение файла на ничем другим не занятой системе сокра-
тит количество поисковых операций вдвое, существенно повысив производительность.
Вариацией на ту же тему является сокращение количества позиционирований блока
головок на нужную дорожку. При распределении блоков система стремится поместить
последовательные блоки файла на один и тот же цилиндр.
Еще одно узкое место файловых систем, использующих i-узлы или что-то им подоб-
ное, заключается в том, что даже короткие файлы требуют двух обращений к диску:
одного для i-узла и второго для блока данных. Обычное размещение i-узлов показано
на рис. 4.25, а. Здесь все i-узлы размещены ближе к началу диска, поэтому среднее
расстояние между i-узлом и его блоками будет составлять половину всего количества
цилиндров, требуя больших перемещений блока головок.

360
Глава 4. Файловые системы
Рис. 4.25. Диск: а — i-узлы расположены в его начале; б — разделен на группы цилиндров,
каждая со своими собственными блоками и i-узлами
Слегка улучшить производительность можно за счет помещения i-узлов в середину
диска, а не в его начало, сократив таким образом вдвое среднее число перемещений
головок между i-узлом и первым блоком. Еще одна идея, показанная на рис. 4.25, б,
заключается в разделении диска на группы цилиндров, каждая из которых будет иметь
свои i-узлы, блоки и список свободных узлов (McKusick et al., 1984). При создании
нового файла может быть выбран любой i-узел, но система стремится найти блок
в той же группе цилиндров, в которой находится i-узел. Если это невозможно, исполь-
зуется блок в ближайшей группе цилиндров. Разумеется, перемещение блока головок
и время подхода нужного сектора уместны, только если они есть у диска. Все больше
компьютеров оснащается твердотельными дисками (solid-state disk, SSD), у которых
вообще нет подвижных частей. У этих дисков, созданных по такой же технологии, что
и флеш-накопители, произвольный доступ осуществляется почти так же быстро, как
и последовательный, и многие проблемы традиционных дисков уходят в прошлое.
К сожалению, возникают новые. Например, когда дело доходит до чтения, записи и уда-
ления, у SSD-накопителей проявляются особые свойства. В частности, в каждый блок
запись может производиться ограниченное количество раз, поэтому большое внимание
уделяется равномерному распределению износа по диску.
4.4.5. Дефрагментация дисков
При начальной установке операционной системы все нужные ей программы и файлы
устанавливаются последовательно с самого начала диска, каждый новый каталог сле-
дует за предыдущим. За установленными файлами единым непрерывным участком
следует свободное пространство. Но со временем по мере создания и удаления файлов
диск обычно приобретает нежелательную фрагментацию, где повсеместно встречают-
ся файлы и области свободного пространства. Вследствие этого при создании нового
файла используемые им блоки могут быть разбросаны по всему диску, что ухудшает
производительность.
Производительность можно восстановить за счет перемещения файлов с места на
место, чтобы они размещались непрерывно, и объединения всего (или, по крайней
мере, основной части) свободного дискового пространства в один или в несколько не-
прерывных участков на диске. В системе Windows имеется программа defrag, которая