Добавлен: 29.10.2018
Просмотров: 48141
Скачиваний: 190

406
Глава 5. Ввод и вывод информации
5.3.3. Программное обеспечение ввода-вывода,
не зависящее от конкретных устройств
Наряду со специфическим программным обеспечением ввода-вывода есть и другая
его составляющая, не зависящая от конкретных устройств. Где проходит четкая гра-
ница между драйверами и программным обеспечением, не зависящим от конкретных
устройств, определяется системой (и устройством), поскольку ряд функций, которые
могут быть реализованы независимыми от устройств, могут вообще-то входить в состав
драйверов из соображений эффективности или в силу каких-нибудь других причин.
Функции, перечисленные в табл. 5.2, обычно реализуются в составе программного
обеспечения, не зависящего от конкретных устройств.
Основная роль программного обеспечения, не зависящего от конкретного устройства,
состоит в выполнении общих для всех устройств функций ввода-вывода и предо-
ставлении унифицированного интерфейса для программного обеспечения на уровне
пользователя. Далее перечисленные задачи будут рассмотрены более подробно.
Таблица 5.2. Функции программного обеспечения, не зависящего от конкретных
устройств
Предоставление унифицированного интерфейса для драйверов устройств
Буферизация
Сообщение об ошибках
Распределение и освобождение выделенных устройств
Предоставление размера блока, не зависящего от конкретных устройств
Предоставление унифицированного интерфейса
для драйверов устройств
Одной из острых проблем при создании операционных систем является придание всем
устройствам и драйверам ввода-вывода более или менее однообразного вида. Если бы
диски, принтеры, клавиатуры и т. д. сопрягались с компьютером по-разному, то при
выпуске каждого нового устройства операционную систему пришлось бы под него
модифицировать. Подстройку операционных систем под каждое новое устройство
вряд ли можно признать удачным решением.
Один из аспектов этой проблемы — интерфейс между драйверами устройств и осталь-
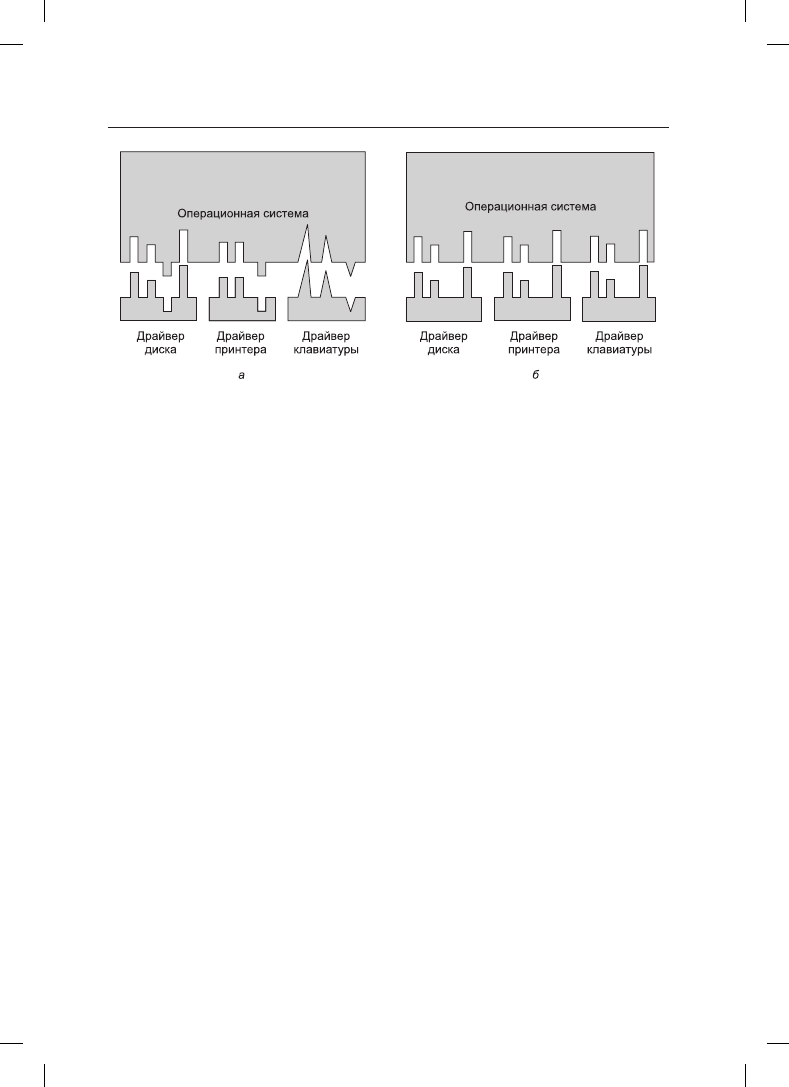
ной операционной системой. На рис. 5.11, а показана ситуация, в которой у каждого
драйвера устройства имеется собственный интерфейс с операционной системой. Это
означает, что функции драйвера, доступные для вызова системой, различаются от
драйвера к драйверу. Это может означать, что и функции ядра, в которых нуждается
драйвер, различаются от драйвера к драйверу. Все вместе взятое это означает, что обе-
спечение интерфейса с каждым новым драйвером требует множества новых усилий по
созданию программного кода.
В противоположность этому на рис. 5.11, б показана другая конструкция, в которой
у всех драйверов имеется одинаковый интерфейс. Теперь стало намного проще под-
ключить новый драйвер, обеспечив его соответствие интерфейсу драйверов. Также
5.3. Уровни программного обеспечения ввода-вывода
407
Рис. 5.11. Стандартный интерфейс драйверов: а — отсутствие; б — наличие
это означает, что создатели драйверов знают, чего от них ожидают. Фактически не
все устройства абсолютно одинаковы, но обычно приходится иметь дело лишь с не-
большим количеством типов устройств, и даже они в целом практически одинаковы.
Все это работает следующим образом. Для каждого класса устройств, таких как диски
или принтеры, операционной системой определяется набор функций, которые драй-
вер должен поддерживать. Для диска в этот набор будут входить не только чтение
и запись, но и включение и выключение электропитания, форматирование и другие
присущие диску операции. Зачастую драйвер содержит таблицу с указателями на эти
функции. При загрузке драйвера операционная система записывает адрес таблицы
указателей на функции, чтобы, когда потребуется вызвать одну из этих функций,
она могла выполнить опосредованный вызов через таблицу. Таблица указателей на
функции определяет интерфейс между драйвером и всей остальной операционной
системой. Все устройства определенного класса (диски, принтеры и т. д.) должны
соответствовать этому условию.
Другим аспектом использования унифицированного интерфейса является способ
присвоения имен устройствам ввода-вывода. Независимое от устройств программное
обеспечение берет на себя отображение символических имен устройств на соответ-
ствующие драйверы. Например, в системе UNIX имя устройства, такое как
/dev/disk0
,
однозначно определяет i-узел для специального файла, и этот i-узел содержит старший
номер устройства
, который используется для определения соответствующего драйвера.
В i-узле содержится также младший номер устройства, который передается в качестве
параметра драйверу, чтобы определить конкретное устройство для проведения опера-
ции чтения или записи. У всех устройств есть старший и младший номера, и доступ
ко всем драйверам осуществляется с использованием старшего номера, по которому
происходит выбор драйвера.
С присвоением имен тесно связан вопрос защиты. Как система препятствует доступу
пользователей к тем устройствам, к которым они не имеют права доступа? Как в UNIX,
так и в Windows устройства появляются в файловой системе в виде поименованных
объектов, что означает распространение обычных правил защиты файлов также на
устройства ввода-вывода. Системный администратор может в таком случае установить
соответствующие права доступа для каждого устройства.
408
Глава 5. Ввод и вывод информации
Буферизация
Буферизация по многим причинам также является актуальным вопросом как для
блочных, так и для символьных устройств. Чтобы понять, в чем состоит одна из таких
причин, рассмотрим процесс, которому необходимо прочитать данные, получаемые от
ADSL-модема, который многие используют дома для связи с Интернетом. По одной из
возможных стратегий работы с поступающими символами нужно заставить пользова-
тельский процесс осуществить системный вызов read и заблокироваться в ожидании
одного символа. При этом прерывание возникает по случаю поступления каждого
символа. Процедура обработки прерывания передает символ пользовательскому про-
цессу и снимает с него блокировку. Поместив куда-нибудь символ, процесс переходит
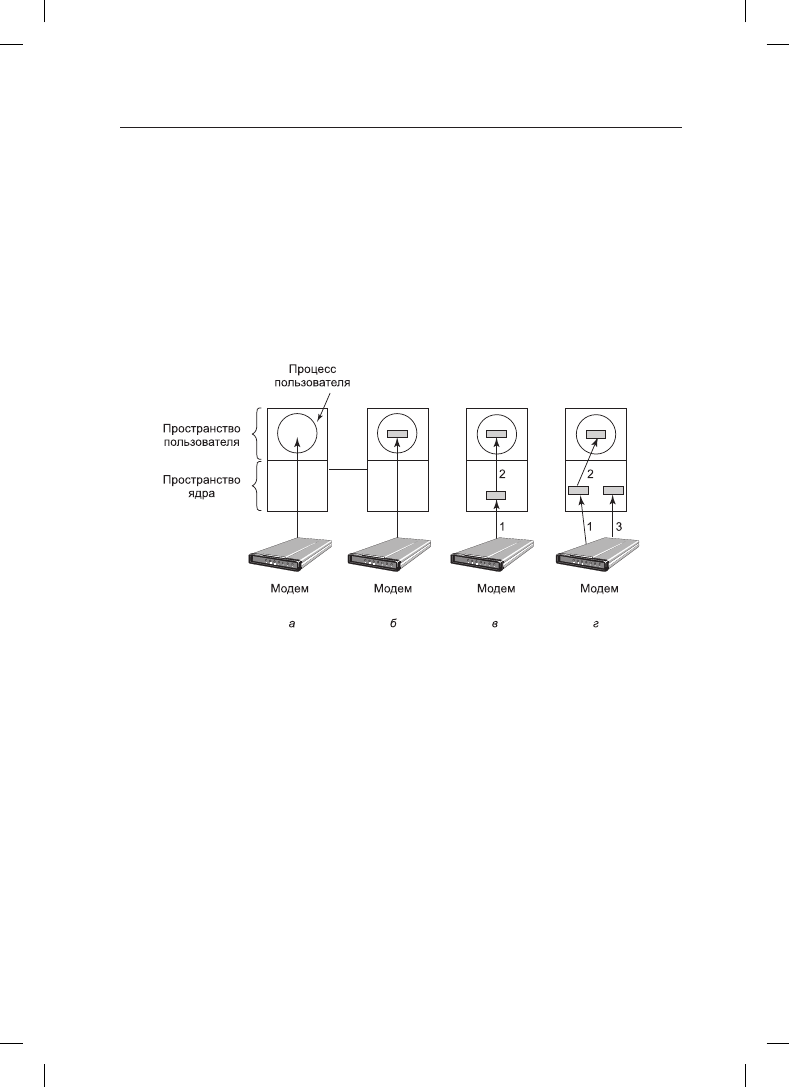
к чтению следующего символа и снова блокируется. Эта модель показана на рис. 5.12, а.
Рис. 5.12. а — небуферизированный ввод; б — буферизация в пространстве пользователя;
в — буферизация в ядре с последующим копированием в пространство пользователя;
г — двойная буферизация в ядре
Проблема реализации такого способа заключается в том, что пользовательский процесс
должен возобновляться для каждого поступающего символа. Из-за низкой эффектив-
ности многократных краткосрочных запусков процесса это далеко не самая лучшая
модель.
Улучшенный вариант показан на рис. 5.12, б. Здесь пользовательский процесс предо-
ставляет буфер объемом n символов и выполняет чтение такого же количества симво-
лов. Процедура обработки прерывания помещает поступающие символы в этот буфер
до тех пор, пока он не заполнится. Затем она возобновляет работу пользовательского
процесса. Эта схема работает намного эффективнее предыдущей, но у нее есть один
недостаток. Что получится, если буфер выйдет за границу страницы при поступлении
очередного символа? Буфер будет зафиксирован в памяти, но если множество процес-
сов начнет фиксировать страницы в памяти, то запас доступных страниц сократится
и производительность резко снизится.
Другой подход предусматривает создание буфера внутри ядра и возложение на об-
работчик прерывания обязанности помещать символы в этот буфер (рис. 5.12, в).

5.3. Уровни программного обеспечения ввода-вывода
409
Когда этот буфер заполнится, то вводится, если нужно, страница с буфером поль-
зователя и буфер копируется в нее за одну операцию. Эта схема работает еще более
эффективно.
Но даже эта улучшенная схема не обходится без проблемы. Что произойдет с символа-
ми, которые поступят в тот момент, когда страница с пользовательским буфером будет
извлекаться с диска? Поскольку буфер заполнен, его будет некуда поместить. Выхо-
дом из положения может стать второй буфер ядра. Как показано на рис. 5.12, г, после
заполнения первого буфера, но перед его опустошением используется второй буфер.
Когда второй буфер заполнится, его можно будет скопировать в буфер пользователя
(если предположить, что пользователь просил об этом). Пока второй буфер будет ко-
пироваться в пространство пользователя, для новых символов может использоваться
первый буфер. Таким образом, два буфера работают по очереди: пока один из них
копируется в пространство пользователя, другой аккумулирует новые поступления.
Эта схема называется двойной буферизацией.
Другой широко распространенной формой буферизации является использование
кольцевого буфера
. Он состоит из области памяти и двух указателей, один из которых
указывает на следующее свободное слово, в которое можно поместить новые данные,
а другой — на первое слово тех данных в буфере, которые еще не были из него выведе-
ны. Во многих случаях аппаратура по мере добавления данных (например, только что
поступивших из сети) передвигает вперед первый указатель; операционная система,
по мере того как она выводит из буфера и обрабатывает данные, перемещает вперед
второй указатель. Оба указателя ходят по кругу, переходя обратно к нижним адресам
буфера, как только достигнут его верхних адресов.
Буферизация играет важную роль и при выводе данных. Рассмотрим, к примеру, как
осуществляется вывод данных на модем без буферизации с использованием модели,
показанной на рис. 5.12, б. Пользовательский процесс, чтобы вывести n символов,
осуществляет системный вызов write. В этот момент у системы есть два варианта вы-
бора. Она может заблокировать пользовательский процесс до тех пор, пока не будут
записаны все символы, но при использовании телефонной линии это займет очень
много времени. Система может также немедленно освободить пользовательский
процесс и заняться операциями ввода-вывода, пока этот процесс будет заниматься
какими-то другими вычислениями, но это приведет к еще более серьезной проблеме.
Как пользовательский процесс узнает, что вывод данных был завершен и он может
опять воспользоваться буфером? Система может выставить сигнал или программное
прерывание, но такой стиль программирования слишком сложен и склонен к созда-
нию состязательных условий. Намного более удачным решением будет копирование
ядром данных в буфер ядра аналогично варианту, показанному на рис. 5.12, в (но в об-
ратную сторону), и сразу после этого разблокирование вызывающего процесса.
Теперь неважно, когда фактически завершится процесс ввода-вывода. Пользова-
тельский процесс с момента разблокирования может использовать буфер повторно.
Буферизация является широко используемой технологией, но у нее имеются и не-
достатки. Если данные будут подвергаться буферизации слишком часто, упадет
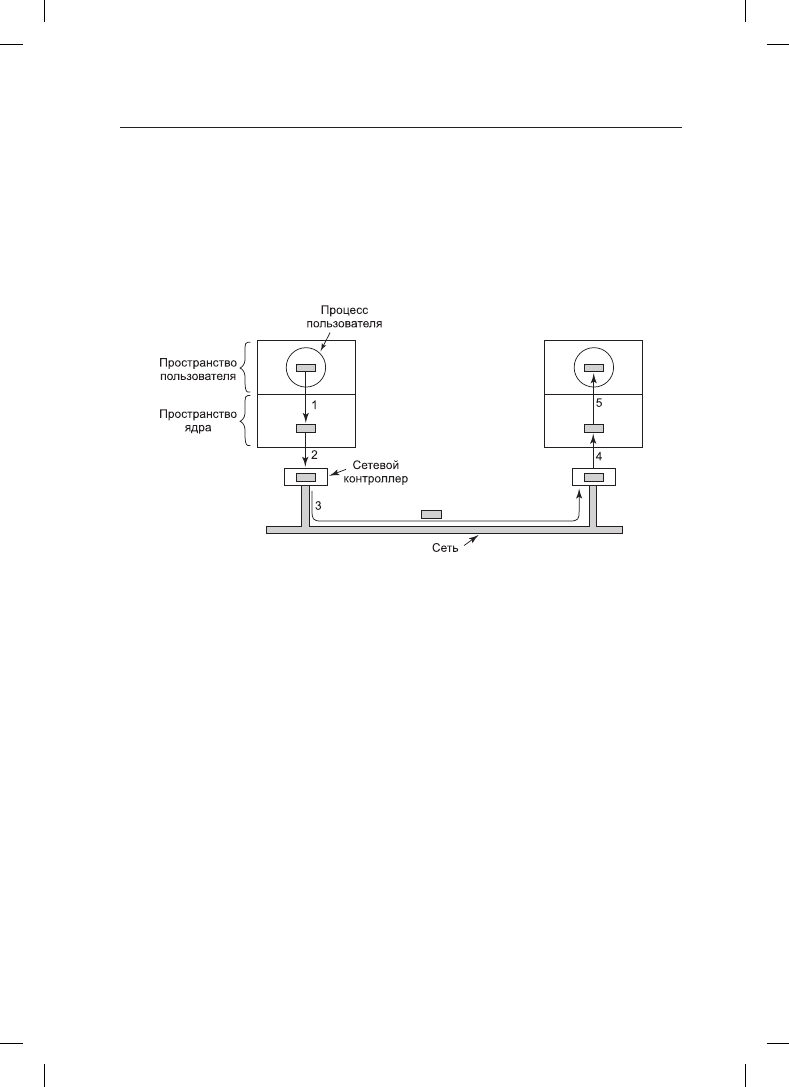
производительность. Рассмотрим, к примеру, сеть, показанную на рис. 5.13. Здесь
пользовательский процесс осуществляет системный вызов для записи данных по сети.
Ядро копирует пакет данных в буфер ядра, позволяя пользовательскому процессу
немедленно возобновить работу (шаг 1). Теперь пользовательская программа может
использовать буфер повторно.
410
Глава 5. Ввод и вывод информации
Когда вызывается драйвер, он копирует пакет в контроллер для его последующего вы-
вода (шаг 2). Причина, по которой он не осуществляет вывод в сеть непосредственно из
памяти ядра, состоит в том, что как только будет запущена передача пакета, она должна
продолжаться на постоянной скорости. Драйвер не может гарантировать, что он будет
получать доступ к памяти на постоянной скорости, поскольку множество циклов обра-
щения к шине могут отвлекать на себя каналы DMA и другие устройства ввода-вывода.
Неудача при своевременном получении слова приведет к порче пакета. Эту проблему
можно устранить за счет буферизации пакета внутри контроллера.
Рис. 5.13. Передача данных по сети может сопровождаться
многочисленным копированием пакета
После того как пакет будет скопирован во внутренний буфер контроллера, он копи-
руется в сеть (шаг 3). Биты поступают получателю вскоре после их отправки, поэтому
сразу же после отправки последнего бита этот бит поступает получателю, у которого
пакет попадает в буфер контроллера. Затем пакет копируется в буфер ядра получателя
(шаг 4). И наконец он копируется в буфер процесса получателя (шаг 5). Обычно после
этого получатель посылает подтверждение. Когда отправитель получает подтвержде-
ние, он имеет возможность послать следующий пакет. Но при этом следует понимать,
что операции копирования существенно снижают скорость передачи данных, посколь-
ку шаги должны осуществляться последовательно.
Сообщения об ошибках
При вводе-выводе данных ошибки являются более распространенным событием, чем
в других сферах работы компьютерных устройств. При возникновении ошибок опера-
ционная система должна их обработать наилучшим образом. Многие ошибки зависят
от специфики конкретного устройства и должны обрабатываться соответствующим
драйвером, но структура обработки ошибок не зависит от специфики устройств.
К одному из классов ошибок ввода-вывода относятся ошибки программирования. Они
возникают в том случае, если процесс запрашивает что-нибудь невозможное, к примеру
запись в устройство ввода информации (клавиатуру, сканер, мышь и т. д.) или чтение из