Файл: перации, производимые с данными (Процессы обработки данных).pdf
Добавлен: 25.06.2023
Просмотров: 51
Скачиваний: 2
Таким образом, многократное преобразование данных также необходимо в случае транспортировки данных, в частности, если транспортировка осуществляется средствами, которые не предназначены для транспортировки этого вида данных. К примеру, для транспортировки по каналам телефонных сетей цифровых потоков данных требуется преобразовать цифровые данные в определенное подобие звуковых сигналов, чем и занимаются специальные устройства, именуемые телефонными модемами.
2. ПРОЦЕССЫ ОБРАБОТКИ ДАННЫХ
2.1 Кодирование данных двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления. Для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа. Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов) [8, с. 149].
История знает интересные, хотя и безуспешные попытки создания «универсальных» языков и азбук. По-видимому, безуспешность попыток их внедрения связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных непременно приводит к изменению общественных методов (то есть норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое [5, с. 83].
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит). 
Рисунок 1- Примеры различных систем кодирования
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11 данные обработка носитель кодирование
Тремя битами можно закодировать восемь различных значений: 000 001 010 011 100 101 ПО 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N=
где N является количеством независимых кодируемых значений;
m — разрядностью двоичного кодирования, которая принята в данной системе [8, с. 151].
2.2 Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом довольно просто — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9 + 1
9:2=4+1
4 : 2 = 2 +-0
2:2=1+0
Таким образом, 1910= 100112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 • 101 300 000 = 0,3 • 106
123 456 789 - 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком) [5, с. 86].
2.3 Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности [6, с. 59].
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 2.
Таблица 2
Базовая таблица кодировки ASCII

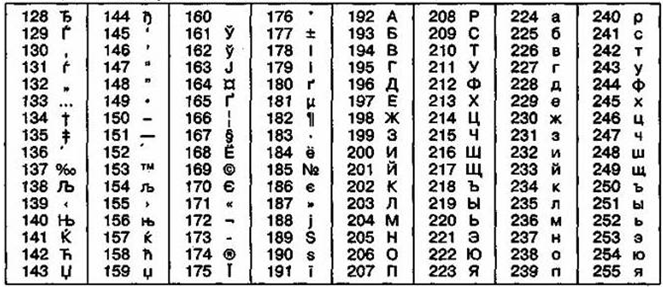
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 3).
Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Таблица 3
Кодировка Windows 1251
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица4). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернет.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 5).
Таблица 4
Кодировка КОИ-8
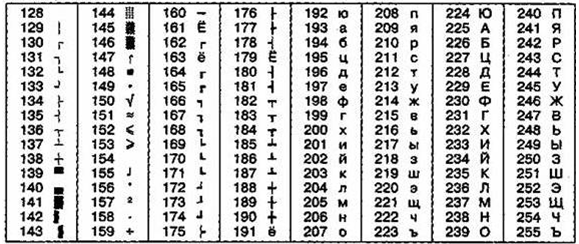
Таблица 5
Кодировка ISO
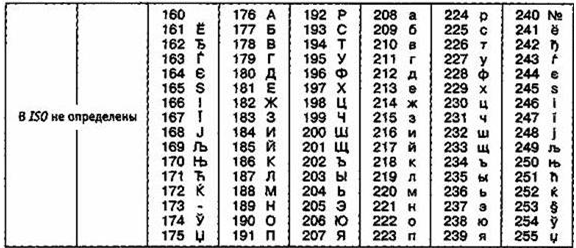
Таблица 6
ГОСТ-альтернативная кодировка
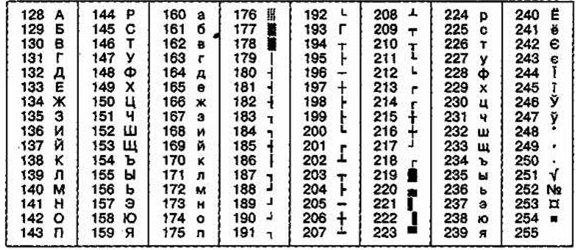
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 6).
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
2.4 Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше [12, с. 176].
Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Unicode (Юникод или Уникод, англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. В MicrosoftWindows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей крупнейшие IT-корпорации.
Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы [5, с. 89].
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов; цифры; знаки пунктуации; специальные знаки (математические, технические, идеограммы и пр.); разделители.
Юникод является системой для линейного представления текста. Символы, которые имеют дополнительные над- или подстрочные элементы, можно отобразить как построенную по определённым правилам последовательность кодов (составной вариант, composite character) либо как единый симвоа (монолитный вариант, precomposed character) [1, с. 113].
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки.
Особый тип модифицирующих символов — селекторы варианта начертания (variation selectors). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов письма Phags-Pa.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
- Форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
- Форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода.
В любой последовательности символов, стартующей с начального символа S символ C блокируется от S если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки прошедшие каноническую декомпозицию [11, с. 15].
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода.
Символ X может быть первично совмещен с символом Y если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>.
Если очередной символ C не блокируется последним встреченным начальным базовым символом L, и он может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется.
- Форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
- Форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией [10, с. 68].
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.