Файл: Распределенные системы обработки информации (Понятие информации и данных ).pdf
Добавлен: 29.06.2023
Просмотров: 75
Скачиваний: 3
СОДЕРЖАНИЕ
ГЛАВА 1. ПОНЯТИЕ ДАННЫХ И ИНФОРМАЦИОННЫХ СИСТЕМ
1.1 Понятие информации и данных
1.2 Понятие и сущность информационной системы
ГЛАВА 2. МОДЕЛИ ПРЕДСТАВЛЕНИЯ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
2.1 Абстрактная модель представления данных
2.2 Реляционная модель представления данных
2.3 Иерархическая модель представления данных
2.4 Сетевая модель представления данных
2.5 Постреляционная модель представления данных
2.6 Многомерная модель представления данных
Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательную привязку данных к времени. Статичность данных позволяет использовать при их обработке специализированные методы хранения, загрузки, индексации и выборки. Привязка данных к времени необходима, поскольку запросы, как правило, содержат в критерии на выборку данных время и дату.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Основными понятиями многомерной модели данных являются:
- показатель – это величина (обычно числового типа), которая собственно и является предметом анализа. Это, например, объем продаж некоторого товара, или выручка от продаж товара. Один OLAP-куб может обладать одним или несколькими показателями;
- измерение (dimension) – это множество объектов одного или нескольких типов, организованных в виде иерархической структуры и обеспечивающих информационный контекст числового показателя. Измерение принято визуализировать в виде ребра многомерного куба;
- члены измерений (members) – объекты, совокупность которых и образует измерение. Члены измерений визуализируют как точки или участки, откладываемые на осях гиперкуба. Например, временное измерение: день, месяц, квартал, год – наиболее часто используются в анализе, может содержать следующие члены: 28 ноября 2018 года, ноябрь 2018 года, четвертый квартал 2018 года и 2018 год. Объекты в измерениях могут быть различного типа, например, «производители – марки автомобиля» или «годы – кварталы»;
- ячейка (cell) – атомарная структура куба, соответствующая конкретному значению некоторого показателя. Ячейки при визуализации располагаются внутри куба. Здесь же принято отображать соответствующее значение показателя [8, с. 130].
Пример многомерной модели данных представлен на рисунке 7. Для многомерной модели с мерностью больше двух необязательно информацию представлять в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю зачастую более удобно иметь дело с двухмерными таблицами, которые представляют собой «срезы» многомерных данных, выполненные с разной степенью детализации.

Рисунок 2.7 - OLAP-куб c тремя измерениями [3, с. 211]
В многомерных СУБД применяют два основных варианта организации данных (схемы):
1) поликубическую схему, когда в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней;
2) гиперкубическую схему, когда в БД все показатели определяются одним и тем же набором измерений; при наличии нескольких гиперкубов все они имеют одинаковую размерность и совпадающие измерения.
Для многомерной модели применяют ряд специальных операций.
1) «Срез» (Slice) –представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование срезов выполняется для ограничения используемых пользователем значений, поскольку все значения гиперкуба практически никогда одновременно не используются. Пример: если ограничить значения измерения «модель авто» в гиперкубе (рис. 7) маркой «Жигули», то получится двухмерная таблица продаж этой марки различными менеджерами по годам (табл. 5).
Таблица 5
Продажи автомобилей «Жигули»
|
Продавец \ год |
1994 |
1995 |
1996 |
|
Петров |
4 |
10 |
2 |
|
Смирнов |
9 |
3 |
8 |
|
Яковлев |
7 |
5 |
6 |
2) «Вращение» (Rotate) – применяется при двухмерном представлении данных. Суть операции заключается в изменении порядка следования измерений при визуальном представлении данных. Пример: «вращение» (табл. 4) приведет к изменению вида таблицы таким образом, что по оси Х будет марка телефона, а по оси Y – месяцы. Эту операцию можно обобщить и на многомерный случай, если под ней понимать процедуру изменения порядка следования измерений.
3) «Агрегация» (Drill Up) – переход к более общему порядку представления информации пользователю из гиперкуба. Пример: пусть имеется гиперкуб с измерениями: Год, Менеджер, Модель авто, Подразделение, Регион, Фирма, Страна. В этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями:
Менеджер
Подразделение
Регион
Фирма
Страна
Пусть в гиперкубе определено, насколько успешно менеджер Петров в 1995 году продавал автомобили марки «Жигули» и «Волга». Тогда, поднимаясь на уровень выше по иерархии, с помощью операции «агрегация» можно выяснить, как выглядит соотношение продаж этих же марок на уровне подразделения, где работает Петров.
4) «Детализация» (Drill Down) – переход к более детальному представлению информации пользователю из гиперкуба. Эта операция противоположна «агрегации».
Достоинства многомерной модели: удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных в реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размера базы данных и существенное увеличение затрат оперативной памяти на хранение индексных файлов. Недостатки многомерной модели: громоздкость модели для простейших задач обычной оперативной обработки информации.
Примеры СУБД, поддерживающих многомерную модель: Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle), Cache (InterSystems) и др. Некоторые системы, например, Media Multi-matrix, позволяют одновременно работать с многомерными и реляционными БД. С СУБД Cache, где внутренней моделью является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
2.7 Объектно-ориентированная модель представления данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи БД. Между записями БД и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, аналогичных подобным средствам в объектно-ориентированных языках программирования.
Стандартизированная объектно-ориентированная модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group – группа управления объектно-ориентированными БД). Рассмотрим несколько упрощенную объектно-ориентированную модель, поскольку в полном объеме рекомендации ODMG-93 пока не реализованы.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, string) или типом, создаваемым пользователем (определяется как class). Значением свойства типа string является строка символов. Значением свойства типа class является объект, представляющий собой экземпляр соответствующего класса. Каждый объект- экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект - экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в объектно-ориентированной БД образуют связную иерархию объектов.
Пример логической структуры объектно-ориентированной БД для предметной области «Обслуживание в библиотеке» представлен на рис. 8.
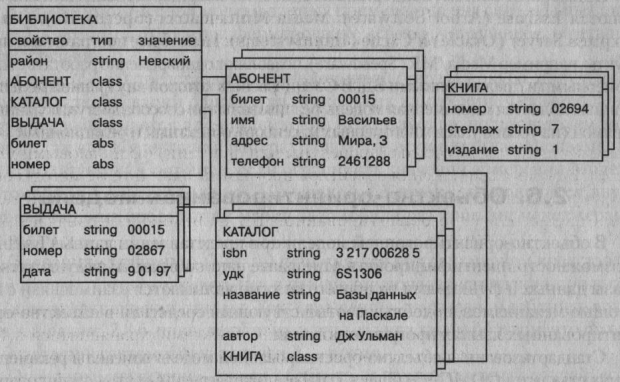
Рисунок 2.8 - Логическая структура объектно-ориентированной БД [5, с. 160]
Объект «Библиотека» является родителем для объектов- экземпляров классов «Абонент», «Каталог» и «Выдача». Различные объекты типа «Книга» могут иметь одного или разных родителей. Объекты типа «Книга», имеющие одного и того же родителя, должны различать по крайней мере номером (уникален для каждого экземпляра книги), но могут иметь одинаковые значения свойств isbn, удк, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними заключается в методах манипулирования данными. Для выполнения действий над данными в объектно-ориентированной БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов, содержащих информацию для быстрого поиска данных.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа «Каталог» добавить свойство телефон для автора книги, то мы получим одноименные свойства у объектов «Каталог» и «Абонент». Смысл такого свойства будет определяться тем объектом, в котором оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа «Книга», являющимся потомками объекта типа «Каталог», можно приписать свойства объектародителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство abs. Так, определение абстрактных свойств билет и номер в объекте «Библиотека» приводит к наследованию этих свойств всеми дочерними объектами «Абонент», «Каталог» и «Выдача». Именно поэтому значения свойства билет классов «Абонент» и «Выдача» одинаковые (00015 – на рис. 8).
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Практически это означает, что в объектах разного типа можно иметь методы (процедуры, функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к объектно-ориентированной БД полиморфизм означает, что объекты класса «Книга», имеющие разных родителей из класса «Каталог», могут иметь разный набор свойств. Следовательно, программы работы с объектами класса «Книга» могут содержать полиморфный код.
Поиск в объектно-ориентированной БД заключается в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-целью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Как объект-цель, так и результат выполнения запроса, могут храниться в БД.
Пример запроса о номерах читательских билетов и именах читателей, получивших в библиотеке хотя бы одну книгу, приведен на рисунке 9.
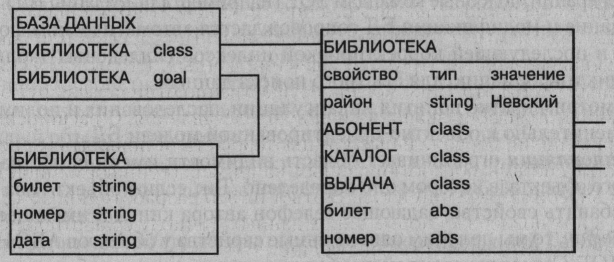
Рисунок 2.9 - Фрагмент БД с объектом-целью [5, с. 163]
Достоинства объектно-ориентированной модели: возможность отображения информации о сложных взаимосвязях объектов, возможность идентифицировать отдельную запись БД и определить для нее функции обработки. Недостатки объектно-ориентированной модели: высокая понятийная сложность, неудобство обработки данных, низкая скорость выполнения запросов.
СУБД на основе объектно-ориентированной модели: G-Base (Grapael), GemStone (Servio-Logic совместно с OGI), Statice (Symbolics), ObjectStore (Object Design), Objectivity/DB (Objectivity), Versant (Versant Technologies), O2 (Ardent Software), ODB-Jupiter (НПЦ «Интелтек Плюс»), Iris, Orion, Postgres и др.
ЗАКЛЮЧЕНИЕ
Таким образом, информационная система – это совокупность базы данных и всего комплекса аппаратно-программных средств для ее хранения, изменения и поиска информации, для взаимодействия с пользователем.
База данных является основой информационной системы, объект ее обработки. База данных (БД) является совокупностью сведений о конкретных объектах реального мира в какой-либо предметной области или ее разделе.
В информационных системах существуют различные модели представления данных.
Модель данных – это абстрактное логическое определение объектов, операторов и других элементов, в совокупности составляющих абстрактную машину, с которой взаимодействуют пользователи. Модель данных - это графическое и (или) словесное представление данных, задающее их структуру и взаимосвязи.
При проектировании баз данных для различных ИС используются три основные модели представления данных: реляционная модель, иерархическая модель, сетевая модель. Так же применяются постреляционная, многомерная и объектно-ориентированная модели.
К достоинствам реляционной модели относятся простота и наглядность представления данных; наличие теоретического обоснования, так как модель основана на хорошо проработанной теории отношений; наличие математического аппарата – реляционной алгебры. К недостаткам модели относится сложность реализации связей 1 : М и М : М, которая ведет к дублированию данных.
К достоинствам иерархической модели относятся простота понимания и использования, наличие хорошо зарекомендовавших себя СУБД, простота оценки операционных характеристик благодаря заранее заданным взаимосвязям. К недостаткам модели относится трудность организации выполнения таких операций как включение, добавление и удаление данных, возможность доступа к любому сегменту только через все предшествующие сегменты включая обязательно корневой сегмент и другие проблемы, связанные со спецификой модели.