Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 347
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Анализ отклонений позволяет отыскать среди множества событий те, которые существенно отличаются от нормы. Задача оценивания сводится
к предсказанию непрерывных значений признака, а анализ связей –
к обнаружению зависимостей в наборе данных.
Глава 3. Модели представления знаний
Знания – это хорошо структурированные данные или мета данные (см. п. 1.1). Для представления поверхностных знаний используются модульные модели (продукционные, формально-логические), а для представления глубинных знаний – сетевые (фреймовые, семантические сети) [1, 2, 9, 12, 16, 22].
3.1. Продукционная модель
Продукционная модель, или модель, основанная на правилах, позволяет представить знания в виде конструкций типа «ЕСЛИ <условие>, ТО <действие>». Под условием (антецедентом) понимается некоторое предложение – образец, по которому осуществляется поиск в БЗ, а под действием (консеквентом) – действия, выполняемые при успешном исходе поиска. Они могут быть промежуточными, выступающими далее как условия, и терминальными (целевыми), завершающими работу системы.
Пример 3.1
ЕСЛИ <двигатель не заводится> И <стартер не работает>, ТО <неполадки в системе электропитания стартера>.
Антецедент и консеквент формируются из атрибутов (двигатель, стартер) и значений (не заводится, не работает).
Пример 3.2
ЕСЛИ <матрица значений регрессоров мультиколлинеарна> И сокращение числа регрессоров невозможно>, ТО <необходимо использование для построения линейной модели метода гребневой (ридж) регрессии> [20].
В данном случае атрибутами являются матрица значений ре-грессоров и число регрессоров, а значениями – мультиколлинеарность и сокращение числа регрессоров невозможно.
В рабочей памяти продукционной системы хранятся пары «атрибут – значение», истинность которых установлена в процессе решения конкретной задачи к текущему моменту времени. Содержание рабочей памяти изменяется в процессе решения задачи по мере срабатывания правил. Правило срабатывает, если при сопоставлении содержащихся
в рабочей памяти фактов с образцом правила имеет место совпадение. Для представления реальных знаний используются описания с помощью триплета «объект – атрибут – значение». С введением триплета правила из
БЗ могут срабатывать более одного раза в процессе одного логического вывода, поскольку одно правило может применяться к различным объектам.
Существует два типа продукционных систем – с прямым и обратным выводом. Прямой логический вывод реализует стратегию
от фактов к заключению или от данных к поиску цели. При обратном выводе выдвигаются гипотезы, которые могут быть подтверждены
или опровергнуты на основании фактов, поступающих в рабочую па-мять [3].
При использовании продукционной модели представления знаний БЗ состоит из набора правил, а программа, управляющая перебором правил, называется интерпретатором правил или машиной вывода. Интерпретатор правил – это программа, имитирующая логический вывод эксперта, пользующегося продукционной БЗ для интерпретации поступивших в систему данных [24].
Интерпретатор правил выполняет две функции:
Механизм вывода представляет собой программу, включающую два компонента, один из которых реализует собственно вывод, а другой управляет этим процессом. Действие компонента вывода основано на применении правила, называемого modus ponens: «Если известно, что истинно утверждение А и существует правило вида «Если А, то В», то утверждение В также истинно». Таким образом, правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение. Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может быть неточным, однако система не должна оста-навливаться из-за того, что отсутствует какая-либо часть входной ин-формации.
Управляющий компонент определяет порядок применения правил и выполняет следующие функции:
Цикл работы интерпретатора правил представлен на рис. 3.1.
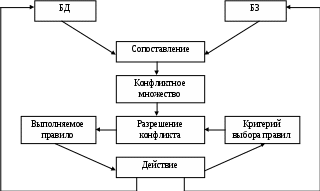
Рис. 3.1. Цикл работы интерпретатора правил
В каждом цикле интерпретатор правил просматривает все правила, чтобы выявить те посылки, которые совпадают с известными на данный момент фактами из БД. После выбора правило срабатывает, его за-ключение заносится в БД, и цикл повторяется. В одном цикле может срабатывать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по опре-деленному критерию единственного правила, которое срабатывает в данном цикле. Совокупность отобранных правил составляет конфликтное множество. Работа интерпретатора правил зависит только от состояния БД и состава БЗ.
От выбранной стратегии решения зависит порядок применения и срабатывания правил. Процедура вывода сводится к определению на-правления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем когнитологи не имеют к ним доступа и, следовательно, не могут в них ничего изменить.
При разработке стратегии управления выводом важны:
исходная точка в пространстве состояний. От выбора этой точки зависит метод осуществления поиска – в прямом или обратном на-правлении;
метод и стратегия перебора – поиск в глубину; поиск в ширину; разбиение на подзадачи.
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует. Прямой вывод часто называют выводом, управляемым данными. В системах с обратным выводом вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам и пытаясь найти те из них, которые подтверждают гипотезу. Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. После этого отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями. Существуют системы, в которых вывод основывается на сочетании упомянутых методов, – обратного и ограниченного прямого. Такой комбинированный метод получил название циклического.
Пример 3.3
Пусть задан фрагмент продукционной БЗ, описывающий ситуацию «Покупка легкового автомобиля» в виде шести правил [19]:
П1. ЕСЛИ <у покупателя много денег И он желает купить автомобиль>, ТО <нужно ехать в автосалон>;
П2. ЕСЛИ <у покупателя мало денег И он желает купить автомобиль>, ТО <нужно ехать на вторичный автомобильный рынок>;
П3. ЕСЛИ <у покупателя есть время И нужно ехать в автосалон>, ТО <необходимо определиться с маркой автомобиля>;
П4. ЕСЛИ <у покупателя есть время И нужно ехать на вторичный автомобильный рынок>, ТО <необходимо определиться с пробегом автомобиля>;
П5. ЕСЛИ <покупатель приехал в автосалон И определился с мар-кой автомобиля>, ТО <нужно произвести покупку нового автомобиля>;
П6. ЕСЛИ <покупатель приехал на вторичный рынок автомобилей И определился с пробегом автомобиля>, ТО <нужно произвести покупку подержанного автомобиля>.
Предположим, что в БД интеллектуальной системы имеются следующие факты:
Ф1. У покупателя много денег;
Ф2. Покупатель желает купить автомобиль;
Ф3. У покупателя есть время.
В случае реализации прямого (индуктивного) логического вы-
вода необходимо просматривать все правила из БЗ и выбирать те, у которых выполняются условия (антецедент) из БД. Если срабатываает несколько правил, то формируется конфликтное множество, подлежащее разрешению. Действие (консеквент) выбранного правила добавляется
в БД.
Проход 1. Срабатывает только правило П1. Консеквент «нужно ехать в автосалон» добавляется в БД.
Проход 2. Срабатывает только правило П3. Консеквент «необходимо определиться с маркой автомобиля» добавляется в БД.
Проход 3. Срабатывает только правило П5. Получена рекомендация: «произвести покупку нового автомобиля». При добавлении данного консеквента в БД четвертый проход подтвердит, что ни одно правило больше не сработало.
В случае реализации обратного (дедуктивного) логического вывода при просмотре БЗ следует искать то правило, у которого выдвинутая гипотеза (цель) находится в правой части. Затем, отыскав такое правило, нужно проверить наличие его условий из левой части в БД. Если какого-либо условия (антецедента) там нет, то оно становится новой подцелью на текущей итерации.
Пусть от покупателя в БД интеллектуальной системы поступили следующие факты:
Ф1. У покупателя мало денег;
Ф2. Покупатель желает купить автомобиль;
Ф3. У покупателя есть время.
Покупателем выдвинута цель – «покупка подержанного авто-мобиля».
Проход 1. Просматриваются все правила из БЗ и ищется цель в правой части. Подходит только правило П6. Формируется новая подцель – «ехать на вторичный автомобильный рынок».
Проход 2. Ищется новая подцель в правой части. Подходит только правило П2. В БД добавляется новый факт – «ехать на вторичный автомобильный рынок».
Проход 3. Выполняется для предыдущей подцели, которая в данном случае является главной, – «покупка подержанного автомобиля». Срабатывает только правило П6. Новая подцель – «определиться с пробегом».
Проход 4. Ищется новая подцель в правой части продукционного правила. Подходит только правило П4. В БД добавляется новый факт – «определиться с пробегом».
Проход 5. Выполняется для главной цели – «покупка по-держанного автомобиля». Срабатывает правило П6. Все условия есть в БД. Выдается рекомендация: «произвести покупку подержанного авто-мобиля».
В системах, БЗ которых насчитывают сотни правил, желательным является использование стратегий управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета-алгоритм.
При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. При поиске в ширину вначале анализируют все факты (симптомы), находящиеся на одном уровне пространства состояний. Разбиение на подзадачи подразумевает выделение подзадач, решение которых рас-сматривается как достижение промежуточных целей на пути к конечной цели. Если удастся правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей и соответствующих подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимальным. Альфа-бета-алгоритм позволяет умень-
шить пространство состояний путем удаления ветвей, неперспектив-
ных для успешного поиска. Затем просматриваются только те вершины,
в которые можно попасть в результате следующего шага, после
чего неперспективные направления исключаются. Данный алгоритм на-
шел широкое применение в системах, ориентированных на различные игры.
Продукционная модель представления знаний используется
более чем в 80 % ЭС, поскольку обладает наглядностью, высокой модульностью, легкостью внесения дополнений и изменений, простотой программной реализации логического вывода. К недостаткам про-дукционных моделей следует отнести отличие от структуры знаний, свойственной человеку; неясность взаимных отношений правил; слож-ность оценки целостного образа знаний; низкую эффективность об-работки знаний. В настоящее время имеется большое число программ-ных средств (ПС), реализующих продукционный подход по построе-
нию БЗ (например, языки высокого уровня CLIPS, OPSS, «пустые»
ЭС EXSYS, Kappa, GURU, инструментальные системы KEE, ARTS, PIES).
к предсказанию непрерывных значений признака, а анализ связей –
к обнаружению зависимостей в наборе данных.
Глава 3. Модели представления знаний
Знания – это хорошо структурированные данные или мета данные (см. п. 1.1). Для представления поверхностных знаний используются модульные модели (продукционные, формально-логические), а для представления глубинных знаний – сетевые (фреймовые, семантические сети) [1, 2, 9, 12, 16, 22].
3.1. Продукционная модель
Продукционная модель, или модель, основанная на правилах, позволяет представить знания в виде конструкций типа «ЕСЛИ <условие>, ТО <действие>». Под условием (антецедентом) понимается некоторое предложение – образец, по которому осуществляется поиск в БЗ, а под действием (консеквентом) – действия, выполняемые при успешном исходе поиска. Они могут быть промежуточными, выступающими далее как условия, и терминальными (целевыми), завершающими работу системы.
Пример 3.1
ЕСЛИ <двигатель не заводится> И <стартер не работает>, ТО <неполадки в системе электропитания стартера>.
Антецедент и консеквент формируются из атрибутов (двигатель, стартер) и значений (не заводится, не работает).
Пример 3.2
ЕСЛИ <матрица значений регрессоров мультиколлинеарна> И сокращение числа регрессоров невозможно>, ТО <необходимо использование для построения линейной модели метода гребневой (ридж) регрессии> [20].
В данном случае атрибутами являются матрица значений ре-грессоров и число регрессоров, а значениями – мультиколлинеарность и сокращение числа регрессоров невозможно.
В рабочей памяти продукционной системы хранятся пары «атрибут – значение», истинность которых установлена в процессе решения конкретной задачи к текущему моменту времени. Содержание рабочей памяти изменяется в процессе решения задачи по мере срабатывания правил. Правило срабатывает, если при сопоставлении содержащихся
в рабочей памяти фактов с образцом правила имеет место совпадение. Для представления реальных знаний используются описания с помощью триплета «объект – атрибут – значение». С введением триплета правила из
БЗ могут срабатывать более одного раза в процессе одного логического вывода, поскольку одно правило может применяться к различным объектам.
Существует два типа продукционных систем – с прямым и обратным выводом. Прямой логический вывод реализует стратегию
от фактов к заключению или от данных к поиску цели. При обратном выводе выдвигаются гипотезы, которые могут быть подтверждены
или опровергнуты на основании фактов, поступающих в рабочую па-мять [3].
При использовании продукционной модели представления знаний БЗ состоит из набора правил, а программа, управляющая перебором правил, называется интерпретатором правил или машиной вывода. Интерпретатор правил – это программа, имитирующая логический вывод эксперта, пользующегося продукционной БЗ для интерпретации поступивших в систему данных [24].
Интерпретатор правил выполняет две функции:
-
просмотр существующих данных из БД и правил из БЗ и добавление в БД новых фактов; -
определение порядка просмотра и применения правил. Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашивает у него ин-формацию, когда для срабатывания очередного правила в БД оказывается недостаточно данных.
Механизм вывода представляет собой программу, включающую два компонента, один из которых реализует собственно вывод, а другой управляет этим процессом. Действие компонента вывода основано на применении правила, называемого modus ponens: «Если известно, что истинно утверждение А и существует правило вида «Если А, то В», то утверждение В также истинно». Таким образом, правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение. Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может быть неточным, однако система не должна оста-навливаться из-за того, что отсутствует какая-либо часть входной ин-формации.
Управляющий компонент определяет порядок применения правил и выполняет следующие функции:
-
Сопоставление – образец правила сопоставляется с имеющи-мися фактами. -
Выбор – если в конкретной ситуации могут быть применены сразу несколько правил, то из них выбирается одно, наиболее подходящее по заданному критерию (разрешение конфликта). -
Срабатывание – если образец правила при сопоставлении совпал с какими-либо фактами из БД, то правило срабатывает. -
Действие – БД подвергается изменению путем добавления в нее заключения сработавшего правила.
Цикл работы интерпретатора правил представлен на рис. 3.1.
Рис. 3.1. Цикл работы интерпретатора правил
В каждом цикле интерпретатор правил просматривает все правила, чтобы выявить те посылки, которые совпадают с известными на данный момент фактами из БД. После выбора правило срабатывает, его за-ключение заносится в БД, и цикл повторяется. В одном цикле может срабатывать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по опре-деленному критерию единственного правила, которое срабатывает в данном цикле. Совокупность отобранных правил составляет конфликтное множество. Работа интерпретатора правил зависит только от состояния БД и состава БЗ.
От выбранной стратегии решения зависит порядок применения и срабатывания правил. Процедура вывода сводится к определению на-правления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем когнитологи не имеют к ним доступа и, следовательно, не могут в них ничего изменить.
При разработке стратегии управления выводом важны:
исходная точка в пространстве состояний. От выбора этой точки зависит метод осуществления поиска – в прямом или обратном на-правлении;
метод и стратегия перебора – поиск в глубину; поиск в ширину; разбиение на подзадачи.
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует. Прямой вывод часто называют выводом, управляемым данными. В системах с обратным выводом вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам и пытаясь найти те из них, которые подтверждают гипотезу. Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. После этого отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями. Существуют системы, в которых вывод основывается на сочетании упомянутых методов, – обратного и ограниченного прямого. Такой комбинированный метод получил название циклического.
Пример 3.3
Пусть задан фрагмент продукционной БЗ, описывающий ситуацию «Покупка легкового автомобиля» в виде шести правил [19]:
П1. ЕСЛИ <у покупателя много денег И он желает купить автомобиль>, ТО <нужно ехать в автосалон>;
П2. ЕСЛИ <у покупателя мало денег И он желает купить автомобиль>, ТО <нужно ехать на вторичный автомобильный рынок>;
П3. ЕСЛИ <у покупателя есть время И нужно ехать в автосалон>, ТО <необходимо определиться с маркой автомобиля>;
П4. ЕСЛИ <у покупателя есть время И нужно ехать на вторичный автомобильный рынок>, ТО <необходимо определиться с пробегом автомобиля>;
П5. ЕСЛИ <покупатель приехал в автосалон И определился с мар-кой автомобиля>, ТО <нужно произвести покупку нового автомобиля>;
П6. ЕСЛИ <покупатель приехал на вторичный рынок автомобилей И определился с пробегом автомобиля>, ТО <нужно произвести покупку подержанного автомобиля>.
Предположим, что в БД интеллектуальной системы имеются следующие факты:
Ф1. У покупателя много денег;
Ф2. Покупатель желает купить автомобиль;
Ф3. У покупателя есть время.
В случае реализации прямого (индуктивного) логического вы-
вода необходимо просматривать все правила из БЗ и выбирать те, у которых выполняются условия (антецедент) из БД. Если срабатываает несколько правил, то формируется конфликтное множество, подлежащее разрешению. Действие (консеквент) выбранного правила добавляется
в БД.
Проход 1. Срабатывает только правило П1. Консеквент «нужно ехать в автосалон» добавляется в БД.
Проход 2. Срабатывает только правило П3. Консеквент «необходимо определиться с маркой автомобиля» добавляется в БД.
Проход 3. Срабатывает только правило П5. Получена рекомендация: «произвести покупку нового автомобиля». При добавлении данного консеквента в БД четвертый проход подтвердит, что ни одно правило больше не сработало.
В случае реализации обратного (дедуктивного) логического вывода при просмотре БЗ следует искать то правило, у которого выдвинутая гипотеза (цель) находится в правой части. Затем, отыскав такое правило, нужно проверить наличие его условий из левой части в БД. Если какого-либо условия (антецедента) там нет, то оно становится новой подцелью на текущей итерации.
Пусть от покупателя в БД интеллектуальной системы поступили следующие факты:
Ф1. У покупателя мало денег;
Ф2. Покупатель желает купить автомобиль;
Ф3. У покупателя есть время.
Покупателем выдвинута цель – «покупка подержанного авто-мобиля».
Проход 1. Просматриваются все правила из БЗ и ищется цель в правой части. Подходит только правило П6. Формируется новая подцель – «ехать на вторичный автомобильный рынок».
Проход 2. Ищется новая подцель в правой части. Подходит только правило П2. В БД добавляется новый факт – «ехать на вторичный автомобильный рынок».
Проход 3. Выполняется для предыдущей подцели, которая в данном случае является главной, – «покупка подержанного автомобиля». Срабатывает только правило П6. Новая подцель – «определиться с пробегом».
Проход 4. Ищется новая подцель в правой части продукционного правила. Подходит только правило П4. В БД добавляется новый факт – «определиться с пробегом».
Проход 5. Выполняется для главной цели – «покупка по-держанного автомобиля». Срабатывает правило П6. Все условия есть в БД. Выдается рекомендация: «произвести покупку подержанного авто-мобиля».
В системах, БЗ которых насчитывают сотни правил, желательным является использование стратегий управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета-алгоритм.
При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. При поиске в ширину вначале анализируют все факты (симптомы), находящиеся на одном уровне пространства состояний. Разбиение на подзадачи подразумевает выделение подзадач, решение которых рас-сматривается как достижение промежуточных целей на пути к конечной цели. Если удастся правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей и соответствующих подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимальным. Альфа-бета-алгоритм позволяет умень-
шить пространство состояний путем удаления ветвей, неперспектив-
ных для успешного поиска. Затем просматриваются только те вершины,
в которые можно попасть в результате следующего шага, после
чего неперспективные направления исключаются. Данный алгоритм на-
шел широкое применение в системах, ориентированных на различные игры.
Продукционная модель представления знаний используется
более чем в 80 % ЭС, поскольку обладает наглядностью, высокой модульностью, легкостью внесения дополнений и изменений, простотой программной реализации логического вывода. К недостаткам про-дукционных моделей следует отнести отличие от структуры знаний, свойственной человеку; неясность взаимных отношений правил; слож-ность оценки целостного образа знаний; низкую эффективность об-работки знаний. В настоящее время имеется большое число программ-ных средств (ПС), реализующих продукционный подход по построе-
нию БЗ (например, языки высокого уровня CLIPS, OPSS, «пустые»
ЭС EXSYS, Kappa, GURU, инструментальные системы KEE, ARTS, PIES).