Файл: Методические указания по выполнению лабораторных работ по дисциплине (модулю) Лингвистическое и программное обеспечение автоматизированных систем.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.01.2024
Просмотров: 528
Скачиваний: 3
СОДЕРЖАНИЕ
2.Общие положения (теоретические сведения)
2.1. Принцип рекурсии в правилах грамматики
2.2. Запись правил грамматик с использованием метасимволов
2.3. Запись правил грамматик в графическом виде
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2.Общие положения (теоретические сведения)
2.1. Разработка лексического анализатора
2.2. Разработка синтаксического анализатора
2.3. Пример построения простого синтаксического анализатора
2.4. Анализаторы для сложных рекурсивных грамматик
2. Общие положения (теоретические сведения)
2.5. Логическая структура XML-документа
2.8. Описание структуры XML-документов
2.9. Язык XML Sсhema Definition (XSD)
2.10. Программная обработка XML-документов
2.11. Обработка XML-данных с использованием модели DOM
2.14. Сопоставление объектной иерархии с XML-данными
2.16. Считывание XML-документа в DOM
2.17. Директивы таблицы стилей, встроенные в документ
2.18. Загрузка данных из модуля чтения
2.19. Доступ к атрибутам в модели DOM
2.20. Получение всех атрибутов в виде коллекции
2.21. Получение единичного узла атрибута
2.22. Считывание объявлений сущностей и ссылок на сущности в DOM
2.23. Сохраняемые ссылки на сущности
2.24. Разворачиваемые и не сохраняемые ссылки на сущности
2.25. Создание новых узлов в модели DOM
2.26. Создание новых атрибутов для элементов в модели DOM
2.29. Проверка имен XML-элементов и атрибутов при создании новых узлов
2.30. Создание новых ссылок на сущности
2.32. Копирование существующих узлов
2.33. Копирование существующих узлов из одного документа в другой
2.34. Копирование фрагментов документа
2.35. Удаление узлов, содержимого и значений из XML-документа
2.36. Изменение узлов, содержимого и значений в XML-документе
2.37. Проверка XML-документа в DOM
2.38. Проверка XML-документа в DOM
2.39. Обработка ошибок проверки и предупреждений
2.40. Сохранение и запись документа
2.42. Запись содержимого документа с помощью свойства OuterXml
3.Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3. Задание на лабораторную работу
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
4. Ход работы (порядок выполнения работы)
2. Общие положения (теоретические сведения)
3.5. Эскизы в документах Деталей
3.6. Взаимодействие с пользователем
3 Задание на работу (рабочее задание)
5. Цикл вида
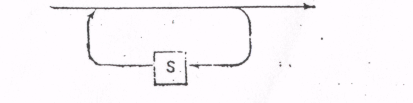
while (ch == L[i]) T(S);
переводится в оператор
где T(S) есть отображение S в соответствии с правилами З-7, a L есть множество начальных символов нетерминального символа S (см. предыдущее правило).
6 Элемент графа, обозначающий другой граф А
7. Элемент графа, обозначающий терминальный символ,
if (ch = x) ReadLex(ch);
else error;
переводится в:
где error - процедура, к которой обращаются при появлении неправильной конструкции; ReadLex(ch) – процедура чтения следующей лексемы в переменную ch.
2.3. Пример построения простого синтаксического анализатора
Реализуем синтаксический анализатор в виде следующего класса:
public partial class TSyntaxAnalyzer
{
private string Ferr; //Сообщение об ошибке
private ushort FerrPos; //Позиция ошибки во входной строке
private Tresult[] Flex; //Входной массив лексем после лексического разбора
private Int32 Count; //Номер текущей лексемы
public ushort ErrorPos { get { return FerrPos; } }
public String Error { get { return Ferr; } }
public TSyntaxAnalyzer(Tresult[] Lexems) //Конструктор
{
Ferr = "";
FerrPos = 0;
Flex = Lexems;
Count = 0;
}
Как видно, при создании объекта класса TSyntaxAnalyzer его конструктору на вход подается массив лексем, сформированный ранее лексическим анализатором.
В методе GetLex в случае, если лексемы в массиве кончились, всегда возвращается лексема FINISH.
private Tresult GetLex()
{
if (Count <= Flex.Length - 1)
{
Count++;
return Flex[Count - 1];
}
else
{
Tresult FinishRes;
FinishRes.lexeme = "FINISH";
FinishRes.name = "";
FinishRes.value = 0;
FinishRes.position = 0;
return FinishRes;
}
}
Самое сложное – процедура PARSE, отвечающая на вопрос соответствия заданной последовательности лексем грамматике языка. Ее алгоритм программируется в точном соответствии с правилом грамматики:
Для удобства введены два константных множества Operation и Item.
Алгоритм имеет следующий вид:
public void Parse()
{
string[] Operation = { "PLUS", "MINUS" }, item = { "ID", "NUMBER" };
Tresult Curlex = GetLex();
do
{
if (Array.IndexOf(item, Curlex.lexeme) != -1)
{
Curlex = GetLex();
if (Curlex.lexeme == "FINISH") break;
do
{
if (Array.IndexOf(Operation, Curlex.lexeme) != -1)
{
Curlex = GetLex();
if (Array.IndexOf(item, Curlex.lexeme) == -1)
{
Ferr = "Синтаксическая ошибка. Ожидается слагаемое";
FerrPos = Curlex.position;
break;
}
}
else
{
Ferr = "Синтаксическая ошибка. Ожидается операция";
FerrPos = Curlex.position;
break;
}
Curlex = GetLex();
}
while (Curlex.lexeme != "FINISH");
}
else
{
Ferr = "Синтаксическая ошибка. Неизвестная лексема!";
FerrPos = Curlex.position;
break;
}
}
while (Curlex.lexeme != "FINISH");
}
Все! Легко убедиться, что данный синтаксический анализатор действительно корректно проверяет введенное выражение.
2.4. Анализаторы для сложных рекурсивных грамматик
Следует заметить, что для более сложных случаев, когда в грамматике встречается рекурсия, т.е. какой-то нетерминальный символ определяется через самого себя, необходимо при нисходящем разборе создавать отдельные процедуры для обработки каждого такого символа. Скажем, язык целочисленных математических выражений со скобками и учетом приоритета операций определяется грамматикой:
(символ
Здесь символ
Добавим в наш лексический анализатор возможность распознавания новых лексем:
public static string[] TLexemeType = { "NUMBER", "ID", "PLUS", "MINUS", "FINISH", "MUL", "DIVIDE", "LP", "RP"};
Здесь MUL соответствует символу "*", DIVIDE – символу "/", LP – "(", RP – ")". Изменения в самом лексическом анализаторе очень просты – надо лишь добавить четыре строчки в процедуру Run:
if (s[i] == '+') AddLex(3, 0, "+");
else if (s[i] == '-') AddLex(4, 0, "-");
else if ((char.IsLetter(s, i)) || (s[i] == '_')) ReadID();
else if (char.IsDigit(s, i)) ReadNumber();
else if (s[i] == '*') AddLex(6, 0, "*");
else if (s[i] == '/') AddLex(7, 0, "/");
else if (s[i] == '(') AddLex(8, 0, "(");
else if (s[i] == ')') AddLex(9, 0, ")");
else
{
Ferr = "Недопустимый символ в коде!";
break;
}
А вот синтаксический анализатор придется писать заново. Как и в примере с КА, создадим его как потомка класса TSyntaxAnalyzer. Метод Parse будет иметь в своём составе вложенные рекурсивно вызываемые процедуры, соответствующие нетерминальным символам:
string[] Operation2 = { "MUL", "DIVIDE" };
Tresult CurLex;
bool Flag = false;
public TSyntaxAnalyser3(Tresult[] Lexems) : base(Lexems) { } //Конструктор
public override void Parse()
{
while ((Error != "") | !Flag) TermF();
}
private void TermF()
{
CurLex = GetLex();
Expr();
if (Ferr != "") FerrPos = CurLex.position;
}
void Expr()
{
Term();
while (Array.IndexOf(Operation, CurLex.lexeme) != -1)
{
CurLex = GetLex();
Term();
}
}
void Term()
{
Factor();
while (Array.IndexOf(Operation2, CurLex.lexeme) != -1)
{
CurLex = GetLex();
Factor();
}
}
void Factor()
{
if (Array.IndexOf(item, CurLex.lexeme) != -1)
{
CurLex = GetLex();
Flag = true;
}
else
if (CurLex.lexeme == "LP")
{
CurLex = GetLex();
Expr();
if (CurLex.lexeme != "RP")
{
Ferr = "Непарные скобки";
FerrPos = CurLex.position;
Flag = true;
}
else CurLex = GetLex();
}
else
{
Ferr = "Синтаксическая ошибка!";
FerrPos = CurLex.position;
Flag = true;
}
}
}
Все процедуры (Expr, Term, Factor) описаны в полном соответствии с заданной грамматикой. Подобный анализатор корректно разбирает сложные выражения со вложенными скобками.
3. Задание на лабораторную работу
Разработать синтаксический анализатор для грамматики в соответствии с индивидуальным заданием лабораторной работы 1.
4. Ход работы (порядок выполнения работы)
1) Ознакомится теоретической справкой.
2) Разработать ПО для реализации задания.
3) Оформить отчет.
4) Защитить работу преподавателю.
5. Содержание отчета
1) Титульный лист
2) Задание
3) Описание грамматики в любой форме.
4) Описание выделяемых лексем и метода синтаксического анализа.
5) Описание ошибок, выдаваемых в процессе анализа.
6) Алгоритм работы лексического анализатора.
7) Алгоритм работы синтаксического анализатора.
8) Скриншоты с демонстрацией работы программы.
9) Выводы по работе
10) Список используемой литературы
11) Приложение – текст программы.
Лабораторная работа № 3
Работа с XML
1. Цель и задачи работы
Цель работы – освоить навыки работы с XML в C#.
Для достижения поставленной цели необходимо выполнить следующие задачи:
- Освоить язык XML.
- Освоить средства DTD.
- Освоить язык XSD.
- Освоить принципы работы с XML в C# с использованием DOM.
- Разработать программу в соответствии с заданием.
2. Общие положения (теоретические сведения)
Расширяемый язык разметки XML (eXtensible Markup Language) приобрел известность в конце 1990-х гг., когда он начал широко использоваться для переноса данных между различными информационными системами и описания бизнес-транзакций.
XML — это язык разметки документов, предназначенный для хранения структурированных данных, обмена информацией между программами, а также для создания на его основе специализированных производных языков [17, 15, 35].
XML описывает определенный класс объектов, называемых XMLдокументами. Документ представляется в виде дерева элементов, каждый из которых может иметь набор атрибутов, а также содержать другие элементы или текст.
XML-документ описывается в терминах логической и физической структуры. Приведем краткие сведения об элементах логической и физической структуры XML-документов.
2.5. Логическая структура XML-документа
Логическая структура состоит из следующих элементов:
-
объявление; -
определения типа документа; -
элементы; -
комментарии; -
ссылки; -
инструкции по обработке документа.
В табл. 2.1 представлены основные требования спецификации XML 1.0, предъявляемые к синтаксису XML-документов.
Приведем пример XML-документа.
<Контрагенты>
<Контрагент Код="Ю023">
<Наименование>Рога и копытаНаименование>
<ИНН>1232345678ИНН>
<КПП>775003657КПП>
<Адрес Индекс="118200" Город="Москва" Улица="Широкая"
Дом="100">
Адрес>
<КонтактноеЛицо ФИО="Иванов Иван Иванович" >
<Телефон>
<СлужебныйТелефон>74952113477СлужебныйТелефон>
<МобильныйТелефон>79056784523МобильныйТелефон>
Телефон>
КонтактноеЛицо>
Контрагент>
Контрагенты>
Таблица 2.1
Синтаксис XML
| Элемент логической структуры | Описание | Пример |
| Объявление | Размещается в начале документа. Ограничивается тегами . Включает атрибуты:
Если атрибуты не определены, то им присваивается значение по умолчанию | |
| Определения типа документа | DTD (Document Type Declaration) заключается между символами и может занимать несколько строк. В этой части объявляются теги, использованные в документе, или приводится ссылка на файл, в котором записаны такие объявления. Секция DTD должна располагаться перед корневым элементом | Пример см. в п. «Языки описания структуры» |
| Элементы | Элементы являются основными составляющими XML-документа; бóльшая часть данных в XMLдокументах содержится в элементах. Элемент представляется в XML-документе с помощью открывающего (<>) и закрывающего (>) тэгов. Открывающий тэг записывается в формате <ИмяЭлемента>, а закрывающий тэг — в формате ИмяЭлемента>. Имя элемента не может содержать пробелов. Содержимым элемента могут быть символьные данные (текст), другие элементы (известные как дочерние элементы), а также оно может отсутствовать (пустой элемент). XML-документ должен содержать обязательный корневой элемент. Элемент может содержать любое число атрибутов, содержащих дополнительную информацию о данных, которые представляет элемент. Атрибуты указываются в виде пар «название-значение» в открывающем тэге элемента. Значения атрибутов заключаются в кавычки. Названия атрибутов уникальны в рамках одного элемента (в одном элементе не может быть двух атрибутов с одинаковым именем) | <Книга> Книга> <Книга isbn="978-5- 9775-0778-3"> Книга> |
| Комментарии | Ограничиваются тегами . Используются для документирования. Могут располагаться в любом месте документа | |
| Ссылки | Ограничиваются символами «&» и «;». Используются для подстановки вместо них символов (ссылки на символы) или различных данных (ссылки на сущности), описанных в определении DTD. Ссылки на символы позволяют вставить в текст документа некоторый символ, который, например, отсутствует в раскладке клавиатуры либо может быть неправильно истолкован анализатором. | код_символа_в_ Unicode Шестнадцатеричный_код_символа имя_сущности |
| | Ссылки на сущности позволяют включать любые строковые константы в содержание элементов или значения атрибутов. Ссылки на сущности указывают программе-анализатору подставить вместо них строку символов, заранее заданную в определении типа документа. Для включения в XML-документ символьных данных, которые не следует обрабатывать, используется секция | |
| Инструкции по обработке | Ограничиваются тегами и ?>. Предназначены для передачи информации приложению, работающему с XML-документом. За начальным вопросительным знаком записывается имя программного модуля, которому предназначена инструкция. Далее через пробел записывается инструкция, передаваемая программному модулю | Эта инструкция предназначена программе, обрабатывающей документ XML. Инструкция передает ей номер версии и кодировку, в которой записан документ |