Файл: Средства разработки клиентских программ (ГЛАВА 1. АНАЛИЗ СУЩЕСТВУЮЩИХ РЕШЕНИЙ).pdf
Добавлен: 04.07.2023
Просмотров: 116
Скачиваний: 2
2.3. Разработка метода
Разработка (проектирование) метода АА осуществляется на основе анализа существующих технических, технического задания и требований к реализуемому методу, описанных в разделе 2.1. данной работы. Данный раздел будет описан соответственно структуре раздела 1.2., так как за основу реализованного метода будет взята структура модели машинного обучения применительно к классификациям текстов.
Предварительная обработка текстовых данных. Из всех возможных путей по предварительной обработке данных было принято решение оставить только понижение регистра символов текстовых документов. Удаление стоп-слов является ресурсоёмкой задачей, которая вполне может быть решена на этапе отбора признакового описания при применении статистической меры IDF, позволяющей понизить веса больших признаков – часто встречающихся слов. Удаление пунктуационных символов производиться также не будет, ввиду того, что признаковое описание, состоящее из N-грамм, будет извлекаться из исходного текстового документа, так как считается, что N-граммы в их естественном употреблении текста наиболее полно описывают авторский стиль. Нормализация форм слов будет проводиться исключительно для дополнительного эксперимента, данная предобработка данных не войдёт в итоговую модель из-за высокой требовательности к ресурсам оперативной памяти и низкой скорости работы (найденные реализации нормализации форм слов русского языка позволяют производить порядка 200-800 операций в секунду, при объёме текстовой выборки в несколько сотен тысяч слов время работы программы выйдет за установленные нормы).
Извлечение признаков. Для численного описания каждого текстового будут использованы следующие признаки: распределение слов, распределение 2-,3-,4-,5-грамм, а также возможные комбинации этих двух признаков. Выбор такого признакового описания обусловлен многочисленными экспериментальными свидетельствами об их эффективности в задаче АА. Однако векторное представление такого признакового описания обладает большой размерностью, что накладывает серьёзные ограничения на выбор классификатора.
Для обработки признаков будут использованы алгоритмы нормализации данных, что является стандартным шагом во всех задачах машинного обучения. Также будут использованы меры TF и IDF, которые позволят привести веса признаков на всех текстах к одному основанию и отрегулировать веса слов с различной частотой обнаружения в тексте.
Алгоритм классификации. Для самой классификации были отобраны следующие алгоритмы: наивный байесовский классификатор, метод опорных векторов (линейный и нелинейный), а также k-ближайших соседей. Данные методы наиболее популярны в задачах классификации текстов на естественном языке, в том числе и для задачи АА. Помимо этих методов, также часто используются следующие: случайные леса, градиентный бустинг, нейронные сети, однако их применение затруднительно ввиду больших размеров признакового описания текстов. Данные методы очень чувствительны к большому числу признаков, что ухудшает их качество и серьёзно увеличивает время классификации.
Оценка результатов. Для оценки результатов работы основного классификатора будут использованы наиболее популярные метрики качества задач многоклассовой классификации, к которым относятся: достоверность (доля верных ответов), точность (усредненная величина уверенности на каждом классе), полнота (усредненные величины долей каждого класса, на которых классификатор срабатывает верно), f1-мера (метрика сглаживающего усреднения точности и полноты).
2.4.Проектирование программной реализации метода
Реализованная программа должна отражать основные этапы создания модели АА, описанные в разделах 1.2. и 2.1. данной работы. На рисунке 2 представлена IDEF0 диаграмма реализуемой программы, описывающая взаимосвязь функциональных блоков (этапов задачи АА)

Рисунок 2. IDEF0 модель метода АА
ГЛАВА 3. ПРОГРАММНАЯ РЕАЛИЗАЦИЯ МЕТОДА АА
3.1.Программная реализация
Программа проведения авторской атрибуции русских литературных произведений «AuthorAttributor» имеет следующие атрибуты:
- Наименование файла программы – AuthorAttributor.py.
- Размер файла программы – 57 480 байт.
- Версия продукта – 0.1.0
- Название продукта – AuthorAttributor.
- Язык – Русский, English (United Kingdom).
Для корректной работы программы AuthorAttributor.py необходимы системные программные средства, представленные операционной системой Windows 10. Также для функционирования «AuthorAttributor.py» необходим python интерпретатор (версия 3.6.5) со следующими библиотеками: Pandas (версия 0.22.0), NumPy (версия 1.11.1), SkLearn (версия 0.19.1), Pymorphy2(версия 0.3.1), RegExp (версия 3.5.0), OS (версия 16.1.0).
Исходным языком программы «AuthorAttributor.py» является Python 3.6.5. Среда разработки, интерактивная оболочка для языка программирования Python – Jupyter версии 5.4.1.
Программа «AuthorAttributor.py» предназначена для решения задачи авторской атрибуции русских литературных произведений. При вызове программы, из заданного системного каталога считываются текстовые файлы произведений русских писателей, из второго каталога считываются текстовые файлы литературных произведений с анонимным авторством. В результате работы программа предсказывает наиболее вероятное авторство для каждого анонимного документа, также программа выводит вероятности принадлежности текста к определённому автору. В случае отсутствия текстовых файлов в каталоге, программа выведет сообщение – «Текстовые документы не найдены», в случае некорректного пути к текстовым файлам, программа выведет сообщение – «Путь к файлам некорректен».
Алгоритм программы. На рисунке 3 приведена блок-схема общего алгоритма программы, описывающая основные структурные единицы и способы их взаимодействия. На рисунке 4 представлено описание функции text_extraction, функция осуществляет считывание текстовых файлов и их разметку по классам авторов. Алгоритмы большинства остальных функций программы построены из узко ориентированных библиотечных методов, и имеют простое алгоритмическое представление в виде последовательного вызова данных методов, в связи с чем нет необходимости в графическом представлении алгоритмов этих структурных единиц программы. Полный код реализованной программы приведён в приложении А данной работы.

Рисунок 3. Общий алгоритм программы.
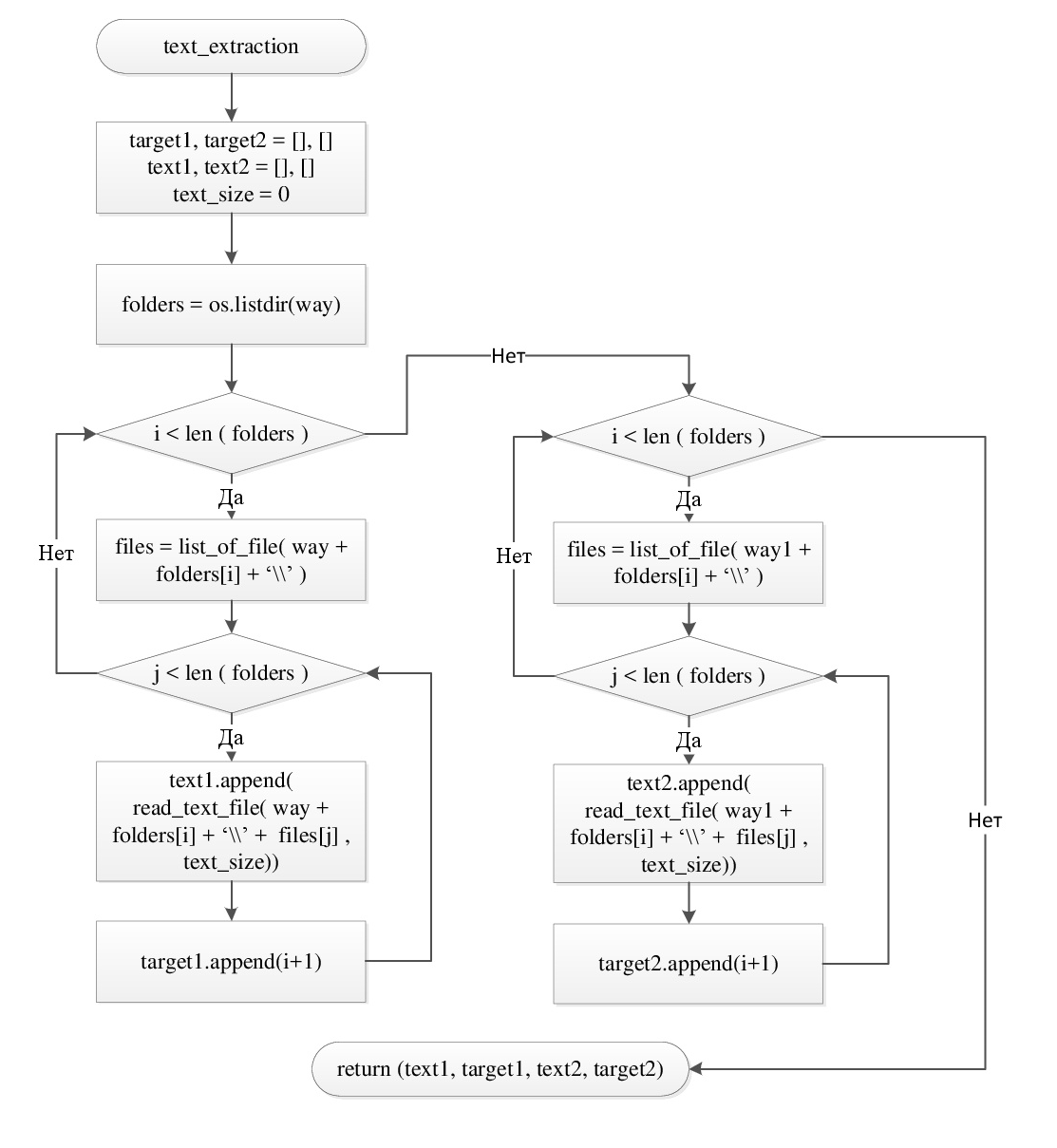
Рисунок 4. Схема алгоритма функции text_extraction.
Состав программы. Разработанная программа включает в себя следующие методы:
- list_of_file( directory ) – функция осуществляет получение имен текстовых файлов, находящихся по заданному пути. В качестве единственного аргумента функция принимает на вход строковую переменную directory, описывающую путь к директории с текстовыми файлами. В результате своей работы функция возвращает массив имён текстовых файлов files_in_dir. В случае подачи на вход функции некорректного пути, программа прекращает работу с выдачей системной ошибки.
- read_text_file ( way_to_file, text_size ) – функция осуществляет чтение содержимого текстового файла, находящегося по заданному пути. Функция принимает на вход в качестве аргументов way_to_file – строковая переменная с описанием пути к текстовому файлу и text_size – целочисленная переменная, описывает число символов, которое будет считано из файла. В результате работы функция возвращает строковую переменную text с текстом размера text_size.
- text_extraction (text_size = 60000) – функция предназначена для индексации текстовых документов разных авторов. Функция в качестве аргумента принимает целочисленную переменную text_size (значение по умолчанию 60000), описывающую ограничение на размер каждого текста выборки в символах. Алгоритм данной функции подробно описан на блок-схеме, представленной на рисунке 4. Результатом работы функции является кортеж из 4 массивов (тексты для обучения, тестирования, а также массивы меток классов для обучения и тестирования).
- text_token(text) – функция производящая нормализацию форм слов исходного текста, принимает на вход строковую переменную text с текстом литературного произведения. Далее производится разбиения текста на упорядоченный массив отдельных слов, которые приводятся в нормальную форму при помощи функционала библиотеки pymorphy2 [20]. После нормализации слова вновь склеиваются через пробелы в модифицированный текст, который и является результатом работы функции.
- text_clf_method(algorithm) – функция необходимая для описания классификатора, в качестве аргумента принимает на вход объект классификатора, созданный библиотекой sklearn. В данной функции при помощи метода pipeline [21], несколько основных этапов (извлечение признаков, предварительная обработка признаков) задачи АА объединяются в поток. Результатом работы функции является модифицированный объект классификатора.
- test_methods(clf_methods, text_size=60000) – функция производит тестирование нескольких классификаторов. В качестве аргументов принимает на вход clf_methods – массив объектов базовых параметризированных классификаторов и переменную text_size (значение по умолчанию 60000), описывающую ограничение на размер каждого текста выборки в символах. Функция осуществляет обучение каждого классификатора на обучающей выборке текстов и тестирует полученный метод на тестовой выборке. После чего при помощи предсказанных меток классов для каждого текста из тестовой выборки и истинных меток классов производится оценка качества алгоритма. Для этой задачи используется метод metrics [22] библиотеки sklearn. Результат работы функции – текстовое сообщение со значениями метрик качества для каждого классификатора.
- size_dependence(method, list_of_sizes) – функция предназначена для исследования зависимости качества классификатора от максимального размера текстов из обучающей и тестовой выборок. Функция принимает на вход в качестве аргументов method – объект классификатора с параметрами, а также list_of_sizes – массив со значениями максимальных размеров текстов. Функция последовательно обучает и тестирует классификатор на выборках, состоящих из различного размера текстов, на каждой итерации оценивается качество алгоритма (достоверность, точность, полнота и f1-мера), для каждой из метрик строится график зависимости величины метрики от размера текстов. Результатом работы функции являются 4 файловых дескриптора, содержащих графики по каждой метрике.
Входные данные представлены текстовыми файлами с текстами произведений различных авторов. Все текстовые файлы должны удовлетворять следующим требованиям:
- файловое расширение – txt;
- язык содержания файла – русский;
- разрешённые кодировки содержания – 1251, CP866, UTF8;
- минимальный размер файла – 10 Кб;
- максимальный размер файла – 4 Гб;
- рекомендуемый размер файла – 150 Кб.
На рисунке 5 представлена необходимая файловая структура входных данных. Все текстовые файлы разделены на два подмножества, первое необходимо для обучения алгоритма и содержится в папке Train, второе – для тестирования алгоритма (папка Test). Папки подвыборок содержат папки авторов, названия этих папок должны совпадать в обоих подмножествах, однако их количество может отличаться. В каждой папке автора содержатся текстовые файлы с произведениями этого автора, множества произведений одного автора из папки Train и Test не должны пересекаться, если того не предполагают условия эксперимента.

Рисунок 5. Файловая структура входных данных.
Выходные данные программы представляются пользователю следующим образом.
- Ошибки в работе программы, системные сообщения, предупреждения интерпретатора и среды разработки выводятся программой в стандартный поток данных.
- Результаты работы программы, в числе которых метрики качества модификаций метода, предсказанные метки классов и показатели уверенности классификатора также выводятся в стандартный поток данных и представляются пользователю в текстовом виде.
- Изображения графиков зависимости метрик качества метода от размера исходной выборки представлены в виде файлов с расширениями jpg и с названиями соответственно исследуемой метрики (accuracy, precision, recall, f1-score). Файлы сохраняются в директории хранения основной программы «AuthorAttributor.py».
3.2. Тестирование программы
После разработки программного кода, реализованное ПО было протестировано на тестовой выборке, описанной в разделе 4.1. текущей работы, в результате тестирования было определено соответствие фактического и необходимого функционала программы. Основным критерием проверки реализованной программы является время работы программы и необходимые ресурсы ЭВМ.
В таблице 3 представлены данные по тестированию ПО на затраты ресурсов ЭВМ. Программа была протестирована при использовании 4 основных классификаторов, с применением комбинации признаков распределения слов и 5-грамм символов текста, все признаки были нормализированы и обработаны при помощи меры TF-IDF. Каждый из подобных режимов был протестирован с использованием нормализации форм слов и без нормализации. Как видно из представленной таблицы 3, нормализация форм слов является вычислительной операцией, требующей больших затрат как по времени, так и по ОЗУ, при этом не давая критического эффекта повышения качества, в результате чего данная операция не войдёт в итоговую программу АА. Также все остальные алгоритмы без использования нормализации форм слов показывают хорошие результаты по затратам ресурсов ЭВМ, в следствие данные подходы будут использованы в дальнейшей работе.
Таблица 3
Тестирование ПО на затраты ресурсов
|
Классификатор |
Предварительная обработка признаков |
Время, с |
ОЗУ, Мб |
|
Наивный байесовский классификатор |
без нормализации |
12 |
67 |
|
с нормализацией |
543 |
259 |
|
|
Метод опорных векторов (линейный) |
без нормализации |
16 |
73 |
|
с нормализацией |
552 |
256 |
|
|
Метод опорных векторов (нелинейный) |
без нормализации |
16 |
74 |
|
с нормализацией |
549 |
253 |
|
|
k-ближайших соседей |
без нормализации |
13 |
66 |
|
с нормализацией |
561 |
245 |
3.3. Описание исследования
Для проведения эксперимента были отобраны русскоязычные современные литературные произведения. Для выборки были использованы ознакомительные фрагменты произведений объёмами от 60000 до 120000 символов, выложенные в свободный доступ порталом litres.ru, как следствие, все авторские права издателей и авторов произведений были полностью соблюдены. Всего было отобрано 120 произведений 20 авторов, то есть по 6 произведений для каждого автора. Совокупный объём выборки составил 1823456 символов или 45,6 печатных листов. Все произведения были опубликованы в период с 1990 по 2017 годы, предполагается, что выборка из произведений одной эпохи будет более репрезентативна. Все произведения выборки являются романами и относятся к следующим жанрам: художественная литература и фантастика.