ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 09.11.2023
Просмотров: 46
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
8. Определение длины словаря
Чтобы выяснить сколько пар ключ-значение содержится в словаре, достаточно воспользоваться функцией len():
>>> print(population)
{'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056}
>>> print(len(population))
5
9. Итерация словаря
9.1 Итерация ключей
Чтобы перебрать все ключи, достаточно провести итерацию по элементам объекта словаря:
>>> for city in population:
... print(city)
...
Berlin
Hamburg
Munich
Cologne
Frankfurt
9.2 Итерация значений
Вычислим сколько людей проживает в пяти крупнейших городах страны. Применим метод dict.values(), возвращающий список значений словаря:
>>> print(population)
{'Berlin': 3748148, 'Hamburg': 1822445, 'Munich': 1471508, 'Cologne': 1085664, 'Frankfurt': 753056}
>>> inhabitants = 0
>>> for number in population.values():
... inhabitants += number
...
>>> print(inhabitants)
8880821
9.3 Итерация ключей и значений
В случае, если нужно работать с ключами и значениями одновременно, обратимся к методу dict.items(), возвращающему пары ключ-значение в виде списка кортежей.
>>> min_grade = 10
>>> min_student = ''
>>> for student, grade in grades.items():
... if grade < min_grade:
... min_student = student
... min_grade = grade
...
>>> print(min_student)
Normando
10. Генераторы словарей
Цикл for удобен, но сейчас попробуем более эффективный и быстрый способ – генератор словарей. Синтаксис выглядит так: {key: value for vars in iterable}
Отфильтруем товары из словаря products по цене ниже 100 евро, используя как цикл for, так и генератор словарей.
>>> print(products)
{'table': 120, 'chair': 40, 'lamp': 14, 'bed': 250, 'mattress': 100, 'pillow': 10, 'shelf': 70, 'sofa': 400}
>>> products_low = {}
>>> for product, value in products.items():
... if value < 100:
... products_low.update({product: value})
...
>>> print(products_low)
{'chair': 40, 'lamp': 14, 'pillow': 10, 'shelf': 70}
>>> products_low = {product: value for product, value in products.items() if value < 100}
>>> print(products_low)
{'chair': 40, 'lamp': 14, 'pillow': 10, 'shelf': 70}
11. Вложенные словари
Вложенные словари – это словари, содержащие другие словари. Мы можем создать вложенный словарь так же, как мы создаем обычный словарь, используя фигурные скобки.
Следующий вложенный словарь содержит информацию о пяти известных произведениях искусства. Как можно заметить, значениями словаря являются другие словари.
# вложенный словарь, содержащий информацию об известных произведениях искусства
works_of_art = {'The_Starry_Night': {'author': 'Van Gogh', 'year': 1889, 'style': 'post-impressionist'},
'The_Birth_of_Venus': {'author': 'Sandro Botticelli', 'year': 1480, 'style': 'renaissance'},
'Guernica': {'author': 'Pablo Picasso', 'year': 1937, 'style': 'cubist'}, 'American_Gothic': {'author': 'Grant Wood', 'year': 1930, 'style': 'regionalism'}, 'The_Kiss': {'author': 'Gustav Klimt', 'year': 1908, 'style': 'art nouveau'}}
Создадим вложенный словарь, используя dict(), передавая пары ключ-значение в качестве именованных аргументов.
# вложенный словарь, созданный при помощи dict().
works_of_art = dict(The_Starry_Night={'author': 'Van Gogh', 'year': 1889, 'style': 'post-impressionist'},
The_Birth_of_Venus={'author': 'Sandro Botticelli', 'year': 1480, 'style': 'renaissance'},
Guernica={'author': 'Pablo Picasso', 'year': 1937, 'style': 'cubist'},
American_Gothic={'author': 'Grant Wood', 'year': 1930, 'style': 'regionalism'},
The_Kiss={'author': 'Gustav Klimt', 'year': 1908, 'style': 'art nouveau'})
Для доступа к элементам во вложенном словаре указываем ключи, используя несколько квадратных скобок ([ ][ ]).
>>> print(works_of_art['Guernica']['author'])
Pablo Picasso
>>> print(works_of_art['American_Gothic']['style'])
regionalism
12. Альтернативные типы данных
Модуль collections предоставляет альтернативные типы данных: OrderedDict, defaultdict и Counter, расширяющие возможности обычных словарей. У нас есть подробная статья о модуле collections, которая помогает не изобретать уже известные структуры данных Python. Здесь мы остановимся на трех типах данных, наиболее близких к словарям.
12.1. OrderedDict
OrderedDict содержит словарь, хранящий порядок добавления ключей. словари запоминают порядок, также можно использовать OrderedDict.
>>> import collections
>>> dictionary = collections.OrderedDict({'hydrogen': 1, 'helium': 2, 'carbon': 6, 'oxygen': 8})
>>> print(type(dictionary))
С OrderedDict можно использовать операции с элементами, методы и функции, как при работе с обычным словарем.
13.2. defaultdict
defaultdict – подкласс словаря, присваивающий значение по умолчанию при отсутствии ключа. Он никогда не выдаст KeyError, если мы попробуем получить доступ к элементу, который отсутствует в словаре. Будет создана новая запись. В приведенном ниже примере ключи создаются с различными значениями в зависимости от функции, используемой в качестве первого аргумента.
>>> default_1 = collections.defaultdict(int)
>>> default_1['missing_entry']
0
>>> print(default_1)
defaultdict(, {'missing_entry': 0})
>>> default_2 = collections.defaultdict(list, {'a': 1, 'b': 2})
>>> default_2['missing_entry']
[]
>>> print(default_2)
defaultdict(, {'a': 1, 'b': 2, 'missing_entry': []})
>>> default_3 = collections.defaultdict(lambda : 'Not given', a=1, b=2)
>>> default_3['missing_entry']
'Not given'
>>> print(default_3)
defaultdict( at 0x7f75d97d6840>, {'a': 1, 'b': 2, 'missing_entry': 'Not given'})
>>> import numpy as np
>>> default_4 = collections.defaultdict(lambda: np.zeros(2))
>>> default_4['missing_entry']
array = ([0., 0.])
>>> print(default_4)
defaultdict( at 0x7f75bf7198c8>, {'missing_entry': array([0., 0.])})
13.3. Counter
Counter – подкласс словаря, подсчитывающий объекты хеш-таблицы. Функция возвращает объект Counter, в котором элементы хранятся как ключи, а их количество в виде значений. Эта функция позволяет подсчитать элементы списка:>>> letters = ['a', 'a', 'c', 'a', 'a', 'b', 'c', 'a']
>>> counter = collections.Counter(letters)
>>> print(counter)
Counter({'a': 5, 'c': 2, 'b': 1})
>>> print(counter.most_common(2))
[('a', 5), ('c', 2)]
Как показано выше, мы можем легко получить наиболее часто используемые элементы с помощью метода most_common([n]). Этот метод возвращает список n наиболее часто встречающихся элементов и их количество.
13. Создание Pandas DataFrame из словаря
Pandas DataFrame – это двумерная таблица со строками и столбцами, создаваемая в библиотеке анализа данных pandas. Это очень мощная библиотека для работы с данными. Ранее мы рассказывали как можно анализировать данные с помощью одной строки на в pandas (да и вообще о разных трюках работы с библиотекой).
Объект DataFrame создается с помощью функции pandas.DataFrame(), принимающей различные типы данных (списки, словари, массивы numpy). В этой статье разберем только те способы создания датафрейма, которые предполагают использование словарей.
13.1. Создание DataFrame из словаря
Создадим DataFrame из словаря, где ключами будут имена столбцов, а значениями – данные столбцов:
import pandas as pd
# создать Pandas DataFrame из словаря - ключ (название столбца) - значение (информация в столбце)
df = pd.DataFrame({'name': ['Mario', 'Violeta', 'Paula'],
'age': [22, 27, 19],
'grades': [9, 8.5, 7]})
print(df)
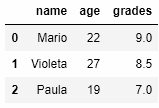
По умолчанию индексом является номер строки (целое число, начинающееся с 0). Изменим индексы, передав список индексов в DataFrame.
# создать Pandas DataFrame из словаря - ключ (название столбца) - значение (информация в столбце) - с собственными индексами
import pandas as pd
df_index = pd.DataFrame({'name': ['Mario', 'Violeta', 'Paula'],
'age': [22, 27, 19],
'grades': [9, 8.5, 7]}, index=['student_1', 'student_2', 'student_3'])
print(df_index)
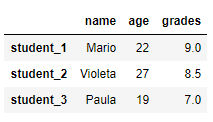
Кортеж (tuple) это: последовательность элементов, которые разделены между собой запятой и заключены в скобки неизменяемый упорядоченный тип данных. Грубо говоря, кортеж - это список, который нельзя изменить. То есть, в
кортеже есть только права на чтение. Это может быть защитой от случайных изменений.
По своей природе они очень схожи со списками, но, в отличие от последних, являются неизменяемыми.
Зачем использовать кортеж вместо списка?
Тем, кто уже успел познакомиться со списками, может показаться не очевидным смысл использования кортежей. Ведь фактически, списки могут делать всё то же самое и даже больше. Это вполне естественный вопрос, но, разумеется, у создателей языка найдётся на него ответ:
Неизменяемость — именно это свойство кортежей, порой, может выгодно отличать их от списков.
Скорость — кортежи быстрее работают. По причине неизменяемости кортежи хранятся в памяти особым образом, поэтому операции с их элементами выполняются заведомо быстрее, чем с компонентами списка.
Безопасность — неизменяемость также позволяет им быть идеальными кандидатами на роль констант. Константы, заданные кортежами, позволяют сделать код более читаемым и безопасным.
Использование tuple в других структурах данных — кортежи применимы в отдельных структурах данных, от которых python требует неизменяемых значений. Например ключи словарей (dicts) должны состоять исключительно из данных immutable-типа.
-
Создание
Способ №1: Литеральное объявление:
literal_creation = ('any', 'object')
print(literal_creation)
> ('any', 'object')
print(type(literal_creation))
> <class 'tuple'>
Способ №2: Через функцию tuple():
tuple_creation = tuple('any iterable object')
print(tuple_creation)
> ('a', 'n', 'y', ' ', 'i', 't', 'e', 'r', 'a', 'b', 'l', 'e', ' ', 'o', 'b', 'j', 'e', 'c', 't')
print(type(tuple_creation))
> <class 'tuple'>
Важно, чтобы аргумент, передаваемый в tuple() был итерируемым объектом:
incorrect_creation = tuple(777) >
Traceback (most recent call last):
incorrect_creation = tuple(777)
TypeError: 'int' object is not iterable
-
Упаковка

Упаковкой кортежа называют присваивание его какой-то переменной, что, по сути, совпадает с операцией объявления.
Стоит обратить внимание 2 момента:
1) Выражения some_tuple = (11, 12, 13) и some_tuple = 11, 12, 13 тождественны.
2) Для объявления кортежа, включающего один единственный элемент, нужно использовать завершающую запятую:
is_tuple = ('a',)
is_tuple_too = 'b',
not_a_tuple = 'c'
print(type(is_tuple))
print(type(is_tuple_too))
print(type(not_a_tuple))
>
>
>
-
Распаковка
Обратная операция, смысл которой в том, чтобы присвоить значения элементов кортежа отдельным переменным.
notes = ('Do', 'Re', 'Mi', 'Fa', 'Sol', 'La', 'Si')
do, re, mi, fa, sol, la, si = notes
print(mi)
> Mi
Количество переменных должно совпадать с числом элементов tuple
Однако, если необходимо получить лишь какие-то отдельные значения, то в качестве "ненужных" переменных позволено использовать символ нижнего подчеркивания "_":
night_sky = 'Moon', 'Stars'
moon, _ = night_sky
print(moon)
> Moon
-
Обращение к элементу и поиск в кортеже

Обратиться к элементу кортежа можно по номеру его позиции. Причём как с начала, так и с конца:
# Mike - [0], Leo - [1], Don - [2], Raph - [3]
turtles = ('Mike', 'Leo', 'Don', 'Raph')
# Mike - [-4], Leo - [-3], Don - [-2], Raph - [-1]
print(turtles[1])
print(turtles[-2])
print(turtles[2] == turtles[-2])
> Leo
> Don
> True
Если элемент кортежа есть вложенный кортеж, то применяются дополнительные квадратные скобки (в зависимости от уровня вложенности). Например, чтобы обратиться ко второму элементу второго элемента, следует поступить так:
input_box = ('firstbox', (15, 150))
# помним про индексацию, ведущую своё начало с 0
print(input_box[1][1])
> 150
Узнать, присутствует ли объект среди элементов кортежа, можно с помощью оператора in:
song = ('Roses', 'are', 'Red')
print('Red' in song)
print('Violet' in song)
> True
> False
-
Сравнение
tuple_A = 2 * 2,
tuple_B = 2 * 2 * 2,
tuple_C = 'a',
tuple_D = 'z',
tuple_E = (42, 'maximum')
tuple_F = (42, 'minimum')
tuple_Z = 999,
# при сравнении кортежей, числа сравниваются по значению
print(tuple_A < tuple_B)
> True
# строки в лексикографическом порядке
print(tuple_C < tuple_D)
> True
# при равенстве элементов на одинаковых позициях, сравниваются элементы на следующих
print(tuple_E < tuple_F)
> True
# сравнение элементов продолжается до первого неравенства
print(tuple_Z < tuple_F)
> False
-
Перебор

Наиболее простым и очевидным способом перебрать элементы кортежа является обход его в цикле for:
my_tuple = ('Wise', 'men', 'say', 'only', 'fools', 'rush', 'in')
# Вывести все элементы кортежа
for word in my_tuple:
print(word)
>
Wise
men
say
only
fools
rush
in
-
Сортировка
Нет ничего проще, чем отсортировать готовый кортеж. В этом наш друг и помощник — прекрасная функция sorted():
not_sorted_tuple = (10**5, 10**2, 10**1, 10**4, 10**0, 10**3)
print(not_sorted_tuple)
> (100000, 100, 10, 10000, 1, 1000)
sorted_tuple = tuple(sorted(not_sorted_tuple))
print(sorted_tuple)
> (1, 10, 100, 1000, 10000, 100000)
-
Удаление

Добавить или удалить элемент содержащийся в tuple нельзя, по причине всё той же неизменяемости. Однако сам кортеж стереть с цифрового лица Земли возможно. Оператор del к нашим услугам:
some_useless_stuff = ('sad', 'bad things', 'trans fats')
del some_useless_stuff
print(some_useless_stuff)
>
Traceback (most recent call last):
print(some_useless_stuff)
NameError: name 'some_useless_stuff' is not defined
Методы и особые операции
-
Срез
Слайсы кортежей предельно похожи на таковые у строк, а выглядят они следующим образом:
tuple[start:fin:step]
Где start — начальный элемент среза (включительно), fin — конечный (не включительно) и step— "шаг" среза.
float_tuple = (1.1, 0.5, 45.5, 33.33, 9.12, 3.14, 2.73)
print(float_tuple[0:3])
> (1.1, 0.5, 45.5)
# тождественная запись
print(float_tuple[:3])
> (1.1, 0.5, 45.5)
# если не указывать конечное значение, будут выведены все элементы до конца
print(float_tuple[0:])
> (1.1, 0.5, 45.5, 33.33, 9.12, 3.14, 2.73)
# не указывать начальное - с начала
print(float_tuple[:])
> (1.1, 0.5, 45.5, 33.33, 9.12, 3.14, 2.73)
# выведем элементы с шагом 2
print(float_tuple[-7::2])
> (1.1, 45.5, 9.12, 2.73)
# отрицательный шаг позволит вывести tuple в обратном порядке
print(float_tuple[::-1])
> (2.73, 3.14, 9.12, 33.33, 45.5, 0.5, 1.1)
-
Длина кортежа
Используя функцию len(), получаем длину/количество элементов:
php = ('p', 'h', 'p')
print(len(php))
> 3
-
Конкатенация
Для tuple определена операция конкатенации:
storm_1 = ('Lightning')Union = (' and ')
storm_2 = ('Thunder')
print(storm_1 + Union + storm_2)
> Lightning and Thunder
-
Повторение
Как и в случае с конкатенацией, для кортежей, впрочем, как и для строк, определена операция повторения:
dog_do = ('woof!',)
print(dog_do * 3)
> ('woof!', 'woof!', 'woof!')
-
Индекс заданного элемента
Метод index() позволяет получить индекс элемента. Достаточно передать нужное значение элемента, как аргумент метода:
rom = ('I', 'II', 'III', 'IV', 'V', 'VI', 'VII', 'VIII', 'IX', 'X')
print(rom.index('X'))
> 9
-
Число вхождений элемента
Метод count() ведет подсчет числа вхождений элемента в кортеж.
AT = ('Finn', 'Jake', 'BiMo', 'Marceline', 'Princess Bubblegum', 'BiMo')
print(AT.count('Finn'))
> 1
print(AT.count('BiMo'))
> 2
-
Преобразование
tuple → str
Представляем вашему вниманию лёгкий способ преобразовать кортеж в строку при помощи метода join():
game_name = ('Breath', ' ', 'of', ' ', 'the', ' ', 'Wild')
game_name = ''.join(game_name)
print(game_name)
> Breath of the Wild
tuple → list
Тут всё ещё проще. Для такой конвертации необходимо всего лишь передать кортеж, как аргумент функции list():
dig_tuple = (1111, 2222, 3333)
print(dig_tuple)
> (1111, 2222, 3333)
dig_list = list(dig_tuple)
print(dig_list)
> [1111, 2222, 3333]
tuple → dict
А вот для преобразования кортежа в словарь придётся применить небольшую хитрость, а именно — генератор словарей:
score = (('Eric', 65000), ('Stephany', 87000))
score_dict = dict((x, y) for x, y in score)
print(score_dict)
> {'Eric': 65000, 'Stephany': 87000}
-
Именованные кортежи
Именованный кортеж (или named tuple) - позволяет программисту обращаться к элементу кортежа не по индексу, а через удобочитаемый заранее заданный идентификатор.
# для начала импортируем сам модуль
from collections import namedtuple
citizen = namedtuple("Citizen", "name age status")
Alex = citizen(name='Alex Mercer', age=27, status='show businessman')
print(Alex.name)
> Alex Mercer
print(Alex.status)
> show businessman
точечная нотация при обращении к свойству объекта может вызвать невольную ассоциацию с классами. В общем-то одно из применений namedtuple как раз связано с ситуациями, когда нужно передать несколько свойств объекта одним куском.