Файл: Операции, производимые с данными (Основные структуры данных).pdf
Добавлен: 29.03.2023
Просмотров: 75
Скачиваний: 1
Деревья
В качестве примера дерева может служить любая иерархическая струк-тура.
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья похожи на графы, главное отличие состоит в том, что в дереве не бывает циклов.
Деревья широко используются в области искусственного интеллекта и в сложных алгоритмах, выступая в качестве эффективного хранилища информации при решении задач.
На рисунке показана схема простого дерева и базовая терминология, связанная с этой структурой данных:
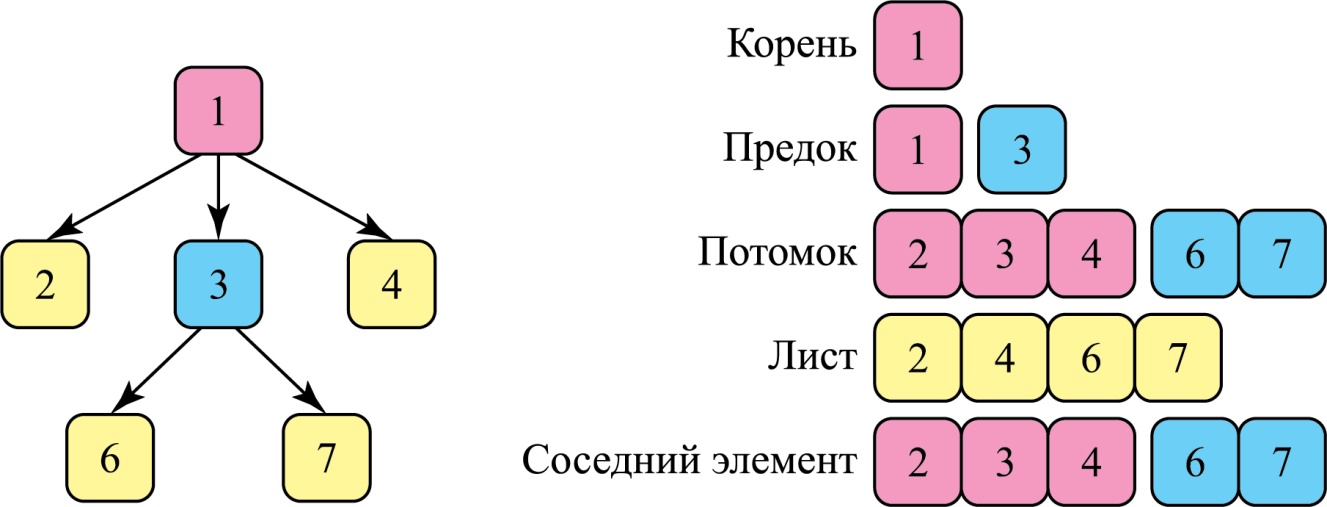
Существуют деревья следующих типов:
- N-арное дерево
- Сбалансированное дерево
- Двоичное дерево
- Двоичное дерево поиска
- АВЛ-дерево
- Красно-черное дерево
- 2–3 дерево
Из вышеперечисленных деревьев чаще всего используются двоичное дерево и двоичное дерево поиска.
Префиксные деревья
Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним. Например, так работает функция автозаполнения Т9 в любом сматрфоне.

Пример префиксного дерева
Префиксное (нагруженное) дерево — это разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве.
Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним. Чтобы составить слово, нужно следовать по ветвям дерева, проходя один узел за раз (получая одну букву).
Map
Map (англ. карта) — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных.
Хэш таблицы
Хэш-таблица — это похожая на Map структура, которая содержит пары ключ/значение. Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
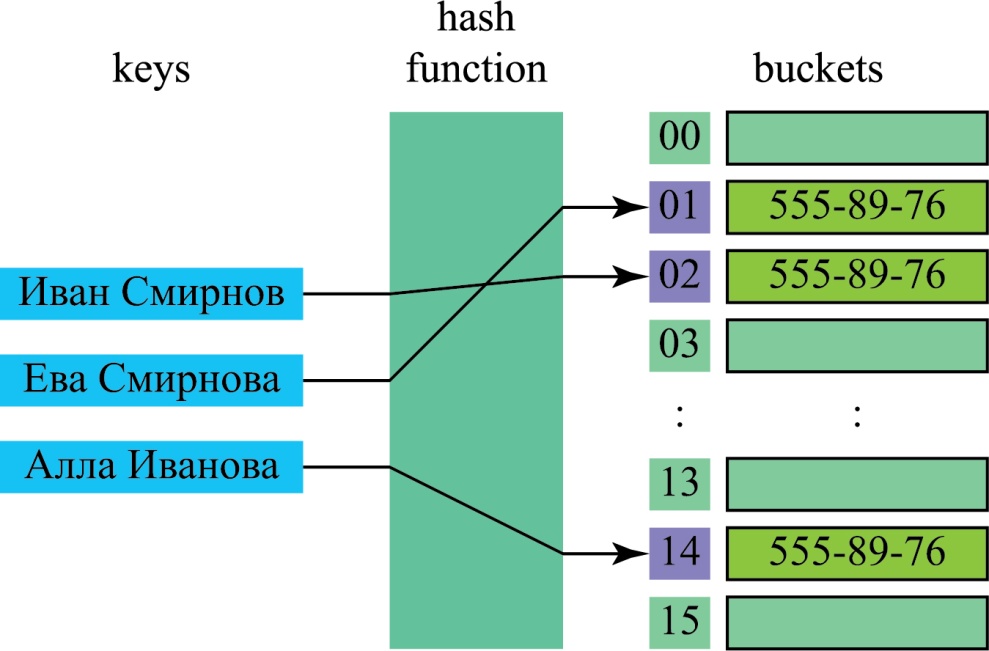
Так работают хэш-таблица и хэш-функция
Обычно хэш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хэш-функция должна возвращать одинаковое число. Если два разных ввода хэшируются с одним и тем же итогом, возникает коллизия. Цель в том, чтобы таких случаев было как можно меньше.
Таким образом, когда вы вводите пару ключ/значение в хэш-таблицу, ключ проходит через хэш-функцию и превращается в число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введёте тот же ключ, хэш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Такой подход заметно сокращает среднее время поиска.
Множества
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ряд важных функций, которые можно применять к двум множествам сразу.
|
Функция |
Результат |
|
Объединение |
комбинирует все элементы из обоих исходных множеств (без дубликатов) |
|
Пересечение |
анализирует два множества и создает новое множество из тех элементов, которые присутствуют и в первом, и во втором изначальных множествах |
|
Разность |
возвращает список уникальных элементов, которые есть в одном множестве, но отсутствуют в другом |
|
Подмножество |
выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества |
Базы данных
Структурированные данные принято называть базами данных (БД).
База данных (в узком смысле слова) — поименованная совокупность структурированных данных относящихся к некоторой предметной области.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных — это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД). СУБД обеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.
В реальной деятельности в основном используют системы БД.
Система баз данных (СБД) — это компьютеризированная система хранения структурированных данных, основная цель которой — хранить информацию и предоставлять ее по требованию.
Системы БД существуют и на малых, менее мощных компьютерах, и на больших, более мощных. На больших применяют в основном многопользовательские системы, на малых — однопользовательские.
Однопользовательская система (single-user system) — это система, в которой в одно и то же время к БД может получить доступ не более одного пользователя.
Многопользовательская система (multi-user system) — это система, в которой в одно и то же время к БД может получить доступ несколько пользователей.
Основная задача большинства многопользовательских систем — позволить каждому отдельному пользователю работать с системой как с однопользовательской.
Различия однопользовательской и многопользовательской систем — в их внутренней структуре, конечному пользователю они практически не видны.
Система баз данных содержит четыре основных элемента: данные, аппаратное обеспечение, программное обеспечение и пользователи.
Способов хранения данных внутри БД существует множество (способы хранения называются моделями представления или хранения данных). Наиболее популярные — объектная и реляционная модели данных.
Автором реляционной модели считается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данных представляет собой набор таблиц, связанных между собой. Строка в таблице соответствует сущности реального мира.
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной модели положена концепция объектно-ориен-тированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone, ONTOS.
В последнее время производители СУБД стремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры таких СУБД — IBM DB2 for Common Servers, Oracle8.
Сортировка данных
Объем данных, содержащийся в реальных БД, может быть огромным (количество может измеряться миллионами записей). При работе с подобными БД одним из ключевых предъявляемых требований является скорость отклика, (время от момента указания задачи управления данными, например, поиска или создания записи, до момента выполнения этой задачи). Операции управления данными выполняются существенно быстрей в отсортированных данных.
Сортировка данных — упорядочивание данных по заданному признаку с целью удобства их использования; сортировка данных повышает доступность информации.
Виды сортировок данных
Существует множество алгоритмов сортировок, со своими достоинствами и недостатками. Вот некоторые из них:
Сортировка пузырьком / Bubble sort
Шейкерная сортировка / Shaker sort
Сортировка вставками / Insertion sort
Сортировка Шелла / Shellsort
Гномья сортировка / Gnome sort
Сортировка выбором / Selection sort
Пирамидальная сортировка / Heapsort
Быстрая сортировка / Quicksort
Сортировка слиянием / Merge sort
Блочная сортировка / Bucket sort
Архивация данных
Как говорилось выше, количество записей в базе данных может измеряться миллионами. Соответственно, объем памяти необходимый для ее хранения — может быть существенен. Особенно критичным этот параметр может стать во время перемещения базы данных. Уменьшить объем памяти, выделенной для хранения БД, можно с помощью архивации данных.
Архивация данных — организация хранения данных в компактной сжатой форме; архивация данных повышает общую надежность информационного процесса и используется для снижения затрат по хранению данных.
Сжатие информации в файлах происходит за счет устранения избыточности различными способами. Например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Применяют различные алгоритмы сжатия информации. Например, алгоритмы Хаффмана, Лемпеля-Зива.
Архивация (упаковка) — помещение (загрузка) исходных файлов в архивный файл в сжатом или не сжатом виде.
Разархивация (распаковка) — процесс восстановления файлов из архива точно в таком виде, какой он имел до загрузки в архив. При распаковке файлы извлекаются из архива и помещаются на диск или в оперативную память.
Программы, осуществляющие упаковку и распаковку файлов, называются программами архиваторами.
В настоящее время применяется несколько десятков программ–архиваторов, которые отличаются перечнем функций и параметрами работы. Из числа наиболее популярных программ можно выделить: WinZip, WinRar, 7z.
Защита данных
Развитие средств, методов и форм автоматизации процессов хранения и обработки данных, массовое применение персональных компьютеров, сетей и облачных хранилищ делают данные более уязвимыми. Данные могут быть незаконно изменены, похищены или уничтожены и поэтому так важна и актуальна защита данных.
Защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и изменения данных.
Для обеспечения защиты хранимых данных используется несколько методов и механизмов их реализации. Рассмотрим основные способы защиты.
Физические способы защиты основаны на создании физических препятствий для злоумышленника, преграждающих ему путь к защищаемой информации (строгая система пропуска на территорию и в помещения с аппаратурой или с носителями информации).
Законодательные средства защиты составляют законодательные акты, которые регламентируют правила использования и обработки информации ограниченного доступа и устанавливают меры ответственности за нарушение этих правил.
Управление доступом представляет способ защиты информации путем регулирования доступа ко всем ресурсам системы (техническим, программным, элементам баз данных). В автоматизированных системах для информационного обеспечения должны быть регламентированы порядок работы пользователей и персонала, право доступа к отдельным файлам в базах данных и т. д. Управление доступом предусматривает следующие функции защиты:
Идентификация пользователей. Присвоение каждому объекту персонального идентификатора: имени, кода, пароля и т. п.
Аутентификация. Опознание (установление подлинности) объекта или субъекта по предъявляемому им идентификатору; Самым распространенным методом аутентификации является метод паролей. Парольная защита широко применяется в системах защиты информации. Ее основными достоинствами являются небольшая цена и простота реализации, малые затраты машинных ресурсов. Однако парольная защита часто не дает достаточного эффекта.
Авторизация. Проверка полномочий (проверку соответствия дня недели, времени суток, запрашиваемых ресурсов и процедур установленному регла-менту).
Разрешение и создание условий работы в пределах установленного регламента.
Регистрация. Протоколирование обращений к защищаемым ресурсам.
Реагирование. Сигнализация, отключение, задержка работ, отказ в запросе при попытках несанкционированных действий.
Криптографические методы защиты информации. Для реализации мер безопасности используются различные способы шифрования (криптографии), суть которых состоит в том, что данные зашифровываются и тем самым преобразуются в шифрограмму или закрытый текст. Санкционированный пользователь получает данные или сообщение, дешифрует их посредством обратного преобразования криптограммы, в результате чего получается исходный текст. Методу преобразования в криптографической системе соответствует использование специального алгоритма. Действие такого алгоритма запускается уникальным числом (или битовой последовательностью), обычно называемым шифрующим ключом.