ВУЗ: Томский государственный университет систем управления и радиоэлектроники
Категория: Учебное пособие
Дисциплина: Базы данных
Добавлен: 28.11.2018
Просмотров: 10877
Скачиваний: 43
6.1 Структуры внешней памяти, методы организации индексов
121
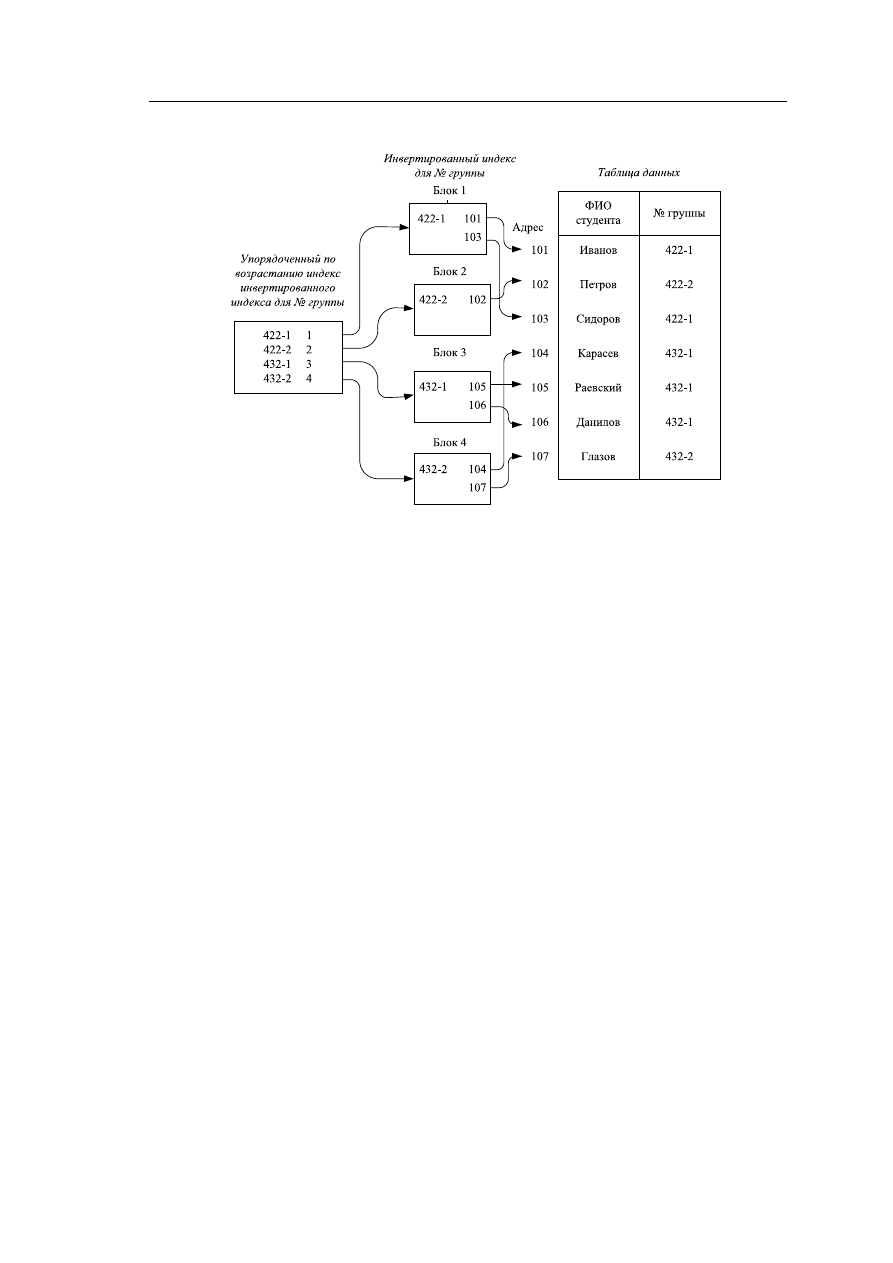
Рис. 6.1 – Инвертированный метод доступа
Прямой метод доступа
Основная особенность прямого метода доступа заключается во взаимно од-
нозначном соответствии между ключом записи и ее физическим адресом. Физи-
ческое местоположение записи определяется непосредственно из значения ключа.
Доступ к записи осуществляется за одно обращение к таблице, поскольку в данном
случае речь идет о необходимости наличия уникального индекса. Эффективность
хранения зависит от плотности ключей. При низкой плотности память расходу-
ется впустую, поскольку резервируются адреса, соответствующие отсутствующим
ключам. В ряде случаев не требуется однозначное соответствие между ключом
и физическим адресом; записи вполне достаточно, чтобы группа ключей ссыла-
лась на один и тот же физический адрес. Такой метод доступа называется методом
доступа посредством хеширования.
Метод хеширования
Метод хеширования — разновидность метода прямого доступа, обеспечиваю-
щего быструю выборку и обновление записей.
Общей идеей методов хеширования является применение к значению ключа
некоторой функции свертки (функции хеширования), вырабатывающей значение
меньшего размера. Свертка значения ключа затем используется для доступа к за-
писи.
Хешированием называется метод доступа, обеспечивающий прямую адреса-
цию данных путем преобразования значения ключа в относительный или абсо-
лютный физический адрес. Алгоритм преобразования ключа называют также под-
программой рандомизации. При использовании функции хеширования возможно
преобразование двух или более ключей в один и тот же физический адрес, кото-
рый называется собственным адресом.
Записи, ключи которых отображаются в один и тот же физический адрес, на-
зываются синонимами, а случай преобразования нового ключа в уже заданный

122
Глава 6. Физическая организация баз данных
собственный адрес называется коллизией. Поскольку по адресу, определяемому
функцией хеширования, может физически храниться только одна запись, синони-
мы должны храниться в каких-нибудь других ячейках памяти. При возникновении
коллизий образуются цепочки синонимов, необходимых для обеспечения механиз-
ма поиска синонимов (рис. 6.2).
Рис. 6.2 – Пример цепочки синонимов
Сущность метода хеширования заключается в том, что все адресное простран-
ство делится на несколько областей фиксированного размера, которые называются
бакетами. В качестве бакета может выступать цилиндр, дорожка, блок, страница,
т. е. любой участок памяти, адресуемый в операционной среде как единое целое.
Наименьшая составная единица бакета называется фрагментом записи или секци-
ей. Если при занесении нового значения индекса все бакеты заняты, то для него
выделяется дополнительная область памяти, называемая областью переполнения.
Главным ограничением этого метода является фиксированный размер таблицы.
Если таблица заполнена слишком сильно или переполнена, то возникнет слишком
много цепочек переполнения и главное преимущество хеширования — доступ к за-
писи почти всегда за одно обращение к таблице — будет утрачено. Расширение таб-
лицы требует ее полной переделки на основе новой хеш-функции (со значением
свертки большего размера).
Применительно к базам данных такие действия абсолютно неприемлемы. По-
этому обычно вводят промежуточные таблицы-справочники, содержащие значения
ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполне-
нии справочника требуется только его переделка, что вызывает меньше накладных
расходов.
Характеристики метода хеширования:
1) при хеш-файлах распределение ключевых значений оказывает значитель-
ное влияние на распределение собственных адресов и количество синонимов;
2) вид функции хеширования оказывает влияние на распределение собствен-
ных адресов и на количество синонимов;
3) упорядоченность данных при загрузке данных влияет на общую произво-
дительность системы;
4) объем адресного пространства или количество бакетов влияет на количе-
ство синонимов и коэффициент резервирования памяти;
6.1 Структуры внешней памяти, методы организации индексов
123
5) большой размер бакета обеспечивает гибкость обработки коллизий без ис-
пользования области переполнения;
6) метод обработки переполнения влияет на время обслуживания и зависит
от метода хеширования ключа;
7) хеширование ключа обеспечивает эффективную выборку и обновление за-
писей, но при этом возникает нарушение логической упорядоченности файла;
8) хеширование допускает возможность вторичного преобразования по спе-
циальному ключу.
Двоичный масочный индекс (bitmap)
В индексе этого типа двоичная маска формируется на основе значений, до-
пустимых для столбца индексируемой таблицы, с учетом их действительных зна-
чений, уже внесенных в таблицу. Бит устанавливается равным единице (1), если
соответствующее значение из набора допустимых совпадает со значением в дан-
ной строке таблицы. В противном случае биту присваивается значение ноль (0).
Если набор допустимых значений в столбце невелик, то такой масочный индекс
оказывается более компактным и обрабатывается быстрее, чем классические ин-
дексы [19]. Пример двоичного индекса представлен на рисунке 6.3.
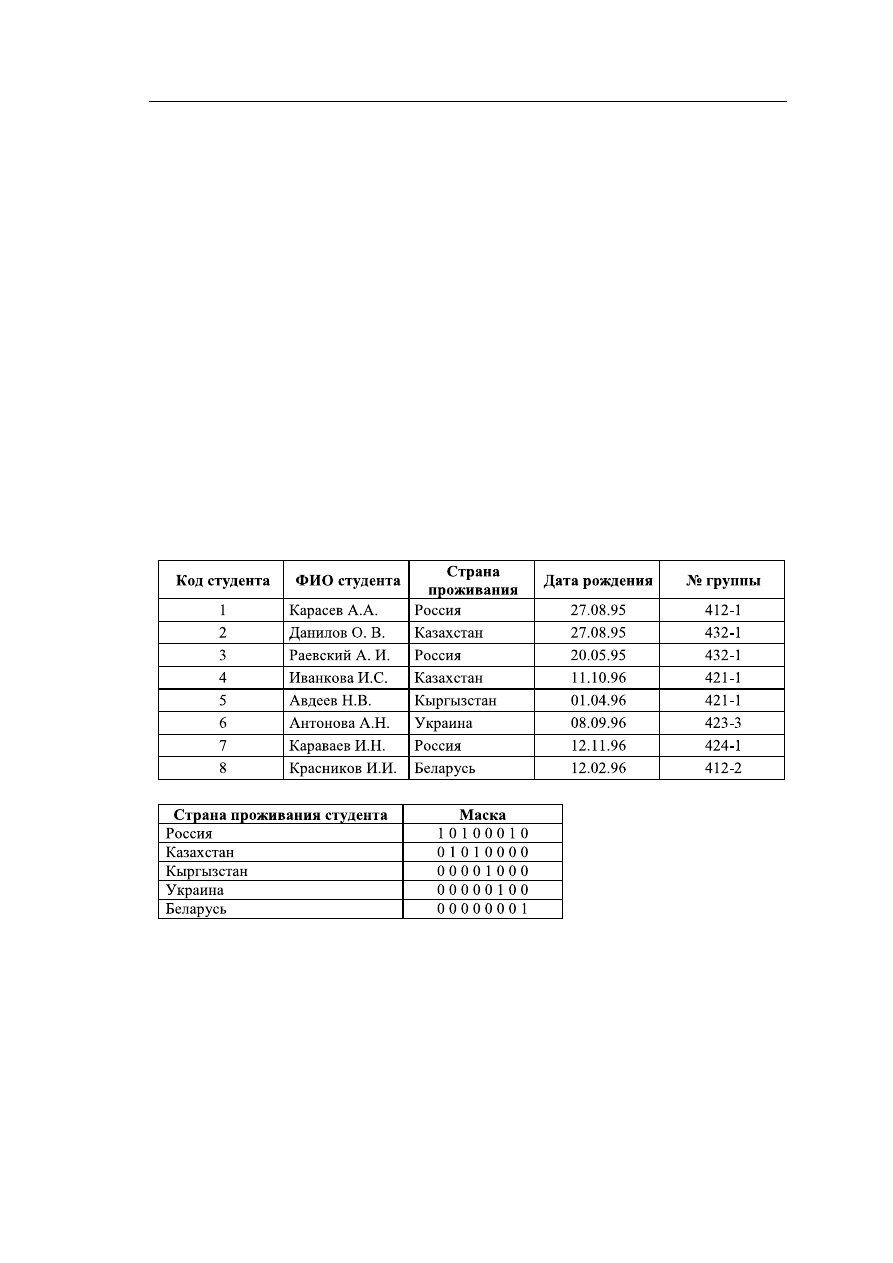
Рис. 6.3 – Таблица «Студент» и масочный индекс для таблицы «Студент»
В данном примере представлены двоичные маски для таблицы «Студент».
Ключом индекса является поле «Страна проживания». В таблице «Студент» 8 запи-
сей. В маске каждый бит соответствует одной записи и устанавливается равным 1,
если значение атрибута «Страна проживания» совпадает со значением параметра
для этой маски. В таблице «Студент» в записях 1, 3, 7 указана страна проживания
Россия, в строке 8 — Беларусь и т. д. Такой метод индексирования широко приме-
няется в СУБД Oracle.

124
Глава 6. Физическая организация баз данных
Кластерный индекс
Следует отметить наличие в некоторых СУБД кластеров таблиц. Кластеры таб-
лиц — это объект БД, который физически группирует совместно используемые таб-
лицы в пределах одного блока. Кластеризация таблиц дает значительный эффект
в том случае, если в системе приходится оперировать запросами, которые требуют
совместной обработки данных из нескольких таблиц. В кластере таблицы хранятся
ключ кластера (столбец, который используется для объединения таблиц) и значе-
ния из столбцов в кластеризованных таблицах. Поскольку кластеризованные таб-
лицы хранятся в одном блоке БД, время на выполнение операций ввода-вывода
заметно сокращается [19].
В некоторых СУБД по идеологии кластеров таблиц строится кластерный ин-
декс, который использует столбец (ключ кластера). В отличие от обычного индекса
в кластерном индексе хранится значение ключа только один раз, независимо от то-
го, сколько раз ключ встречается в таблице.
Представляет интерес реализация механизма кластерного индекса для некото-
рых форматов настольных СУБД Paradox, dBase. В этих СУБД кластерный индекс
состоит из одного или нескольких неключевых полей, которые в совокупности
позволяют расположить все записи таблицы в заранее определенном порядке, при
этом кластерный индекс предоставляет возможность эффективного доступа к за-
писям таблицы, в которой значения индекса могут не быть уникальными.
Управление индексами
Поскольку организация индексов в большинстве СУБД является довольно слож-
ной, управление индексами требует повышенного внимания. Зачастую с целью
улучшения производительности БД программисты стараются увеличить количе-
ство индексов.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Однако увеличение количества индексов может привести к обрат-
ному эффекту и значительно ухудшить производительность в опе-
рациях обновления. В связи с этим необходимо следить за индек-
сами и удалять те из них, которые не используются.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
В некоторых СУБД существует специальная функция, позволяющая выяснить,
даст ли добавление индекса желаемый эффект.
6.1.4 Словарь данных
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Словарь данных — это хранилище информации обо всех объектах,
входящих в состав БД.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
СУБД использует словарь для получения информации об объектах и ограни-
чения прав доступа к ним. Конкретные пользователи и администратор БД могут
получить из словаря интересующую информацию о БД, а именно: информацию
о таблицах, индексах, представлениях, пакетах и процедурах [18].

6.1 Структуры внешней памяти, методы организации индексов
125
Например, словарь данных СУБД Oracle может предоставлять следующую ин-
формацию:
• имена пользователей Oracle;
• привилегии и роли, которые были предоставлены каждому пользователю;
• имена объектов схем (таблиц, представлений, снимков, индексов, класте-
ров, синонимов, последовательностей, процедур, функций, пакетов, триг-
геров и т. д.);
• информацию об ограничениях целостности;
• значения по умолчанию для полей таблиц;
• объем распределенного и в данный момент времени используемого объек-
тами в базе данных пространства;
• информацию аудита, например имена пользователей, обращавшихся к раз-
личным объектам и обновлявших данные.
Доступ к словарю данных возможен только в режиме чтения.
Одной из составляющих словаря данных и ключевым компонентом всей ин-
формационной структуры, являются системные таблицы БД, содержащие слу-
жебную информацию. К ним обращается система за всей внутренней информа-
цией о текущем состоянии и процессах, происходящих в системе. Имена этих
таблиц зашифрованы и в некоторых СУБД скрыты от пользователя, а в большин-
стве случаев структура их не документирована, так что предпринять осмысленные
действия с системной таблицей даже администратору БД проблематично. Однако
в них хранится множество сведений и данных о конфигурации системы.
Словарь данных призван помочь пользователю обеспечить выполнение следу-
ющих функций [9]:
• установление связи с другими пользователями;
• осуществление простого и эффективного управления элементами данных
при вводе в систему новых элементов или изменения описания существу-
ющих;
• уменьшение избыточности и противоречивости данных;
• определение степени влияния изменений в элементах данных на всю БД;
• централизация управления элементами данных с целью упрощения проек-
тирования БД и расширения ее структуры.
Существует понятие идеального словаря данных, т. е. словаря, обеспечиваю-
щего полноценную связь между всеми уровнями моделей БД и объектами БД.
Такой словарь должен [9]:
1) поддерживать концептуальную, физическую и внешние модели данных;
2) быть интегрированным в СУБД;
3) поддерживать возможность хранения нескольких версий программной ре-
ализации;
4) обеспечивать эффективный обмен информацией между внешними програм-
мами и СУБД (в идеале привязка внешних и внутренних моделей должна
происходить во время выполнения программ, использующих БД, при этом
должно осуществляться динамическое построение описания БД).