Файл: Требования к средствам оперативной аналитической обработки данных.pdf
Добавлен: 12.07.2023
Просмотров: 72
Скачиваний: 2
В сложных задачах с многоуровневыми измерениями имеет смысл обратиться к расширениям схемы звезды - схеме созвездия (fact constellation schema) и схеме снежинки (snowflake schema). В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений. Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.
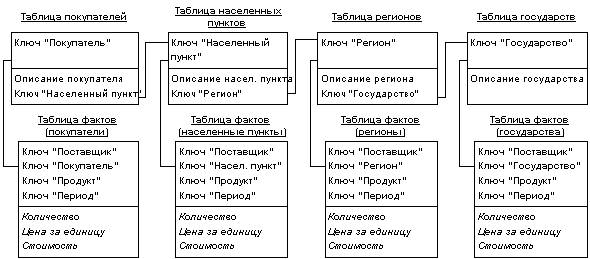
Увеличение числа таблиц фактов в базе данных может проистекать не только из множественности уровней различных измерений, но и из того обстоятельства, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем далеко не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы звезды из внешних источников и сложностям администрирования. Частично решают эту проблему расширения языка SQL (операторы "GROUP BY CUBE", "GROUP BY ROLLUP" и "GROUP BY GROUPING SETS"); кроме того, авторы статей предлагают механизм поиска компромисса между избыточностью и быстродействием, рекомендуя создавать таблицы фактов не для всех возможных сочетаний измерений, а только для тех, значения ячеек которых не могут быть получены с помощью последующей агрегации более полных таблиц фактов.
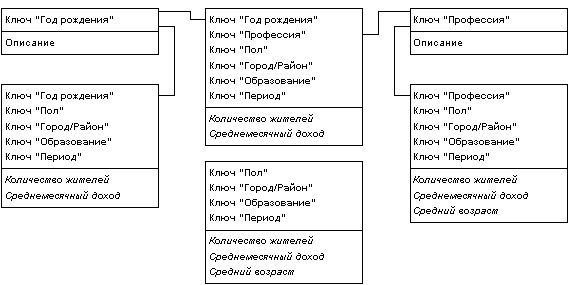
В любом случае, если многомерная модель реализуется в виде реляционной базы данных, следует создавать длинные и "узкие" таблицы фактов и сравнительно небольшие и "широкие" таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных, распределенных по незвездообразным нормализованным структурам, хотя при этом следует помнить, что включающие агрегацию запросы при высоконормализованной структуре БД могут выполняться довольно медленно.
Ориентация на представление многомерной информации с помощью звездообразных реляционных моделей позволяет избавиться от проблемы оптимизации хранения разреженных матриц, остро стоящей перед многомерными СУБД (где проблема разреженности решается специальным выбором схемы). Хотя для хранения каждой ячейки используется целая запись, которая помимо самих значений включает вторичные ключи - ссылки на таблицы измерений, несуществующие значения просто не включаются в таблицу фактов.
Интеллектуальный анализ данных
ИАД (Data Mining) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания.
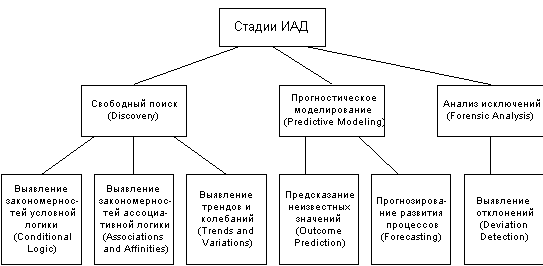
В общем случае процесс ИАД состоит из трёх стадий:
1) выявление закономерностей (свободный поиск);
2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
3) анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
Иногда в явном виде выделяют промежуточную стадию проверки достоверности найденных закономерностей между их нахождением и использованием (стадия валидации).
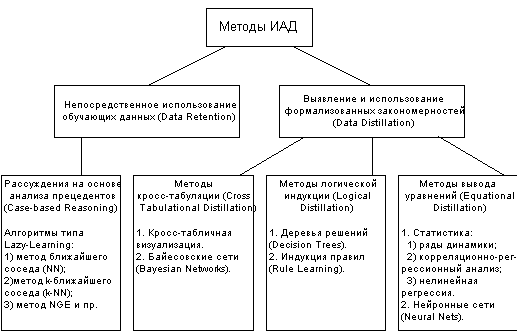
Все методы ИАД подразделяются на две большие группы по принципу работы с исходными обучающими данными.
- В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений; это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
- Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода). Согласно предыдущей классификации, этот этап выполняется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо "прозрачными" (интерпретируемыми), либо "черными ящиками" (нетрактуемыми).
Две эти группы и примеры входящих в них методов представлены на рисунке.
Интеграция OLAP и ИАД
Оперативная аналитическая обработка и интеллектуальный анализ данных - две составные части процесса поддержки принятия решений. Но сегодня большинство систем OLAP заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти два вида анализа должны быть тесно объединены, то есть системы OLAP должны фокусироваться не только на доступе, но и на поиске закономерностей. Как заметил N. Raden, "многие компании создали ... прекрасные хранилища данных, идеально разложив по полочкам горы неиспользуемой информации, которая сама по себе не обеспечивает ни быстрой, ни достаточно грамотной реакции на рыночные события".
K. Parsaye вводит составной термин "OLAP Data Mining" (многомерный интеллектуальный анализ) для обозначения такого объединения. J. Han предлагает еще более простое название - "OLAP Mining", и предлагает несколько вариантов интеграции двух технологий.
- "Cubing then mining". Возможность выполнения интеллектуального анализа должна обеспечиваться над любым результатом запроса к многомерному концептуальному представлению, то есть над любым фрагментом любой проекции гиперкуба показателей.
- "Mining then cubing". Подобно данным, извлечённым из хранилища, результаты интеллектуального анализа должны представляться в гиперкубической форме для последующего многомерного анализа.
- "Cubing while mining". Этот гибкий способ интеграции позволяет автоматически активизировать однотипные механизмы интеллектуальной обработки над результатом каждого шага многомерного анализа (перехода между уровнями обобщения, извлечения нового фрагмента гиперкуба и т. д.).
К сожалению, очень немногие производители предоставляют сегодня достаточно мощные средства интеллектуального анализа многомерных данных в рамках систем OLAP. Проблема также заключается в том, что некоторые методы ИАД (байесовские сети, метод k-ближайшего соседа) неприменимы для задач многомерного интеллектуального анализа, так как основаны на определении сходства детализированных примеров и не способны работать с агрегированными данными [20].
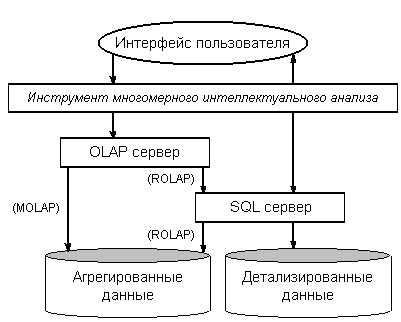
Критерии оценки существующих продуктов
Как и в любой другой области, в сфере OLAP не может существовать однозначных рекомендаций по выбору инструментальных средств. Можно только заострить внимание на ряде ключевых моментов и сопоставить предлагаемые возможности программного обеспечения с потребностями организации.
- Удобство и богатство возможностей средств администрирования. Работа администратора является самой важной и самой сложной частью эксплуатации OLAP-системы. Поэтому следует обращать внимание на удобство интерфейса администрирования, а более того - на спектр его функциональных возможностей. Как формируются новые измерения? Как модифицируется существующая модель? Требуется ли создание базы данных жестко заданной структуры, или можно анализировать данные, собранные в ранее созданных базах (в случае ROLAP)? На все эти вопросы необходимо получить ясный и четкий ответ.
- Гибкость настройки и наглядность форм демонстрации результатов. Интуитивность представления информации - главная изюминка OLAP. Насколько качественно и удобно формируются отчёты? Наглядны ли графические возможности, существует ли связь с ГИС-технологиями? Налажены ли механизмы экспорта результатов в стандартные форматы?
- Спектр методов постобработки данных, доступность средств интеллектуального анализа. Богаты ли аналитические возможности инструмента? Есть ли в нём элементы Data Mining, и если есть, какие преимущества они могут обеспечить при использовании?
- Возможность обработки больших хранилищ данных с приемлемой производительностью. Если необходим планомерный непрерывный анализ большого хранилища данных организации, требуется выяснить объективные ограничения продукта с точки зрения предельных размеров исходных баз данных.
- Возможность увязки OLAP-инструментария со всеми СУБД, используемыми в организации. Как показывает практика, интеграция разнородных продуктов в устойчиво работающую систему - один из наиболее важных вопросов, и его решение в ряде случаев может быть связано с большими проблемами. Необходимо разобраться, насколько просто и надёжно можно интегрировать средства OLAP с существующими в организации СУБД.
Источники
- https://docs.microsoft.com/ru-ru/azure/architecture/data-guide/relational-data/online-analytical-processing
- https://infopedia.su/17xedca.html
- http://www.e-biblio.ru/book/bib/01_informatika/inform_analit_systemy/posob/332.2.5.html
- https://studopedia.net/1_50319_trebovaniya-k-sredstvam-operativnoy-analiticheskoy-obrabotki-dannih.html
- Петров В.Ю. Информационные технологии в менеджменте. Учебное пособие - Санкт-Петербург: СПб: Университет ИТМО, 2015