Файл: Курсовая работа По дисциплине Теория языков программирования и методы трансляции Выполнил Группа.doc
Добавлен: 25.10.2023
Просмотров: 56
Скачиваний: 7
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Федеральное агентство связи
Сибирский Государственный Университет Телекоммуникаций и Информатики
Межрегиональный центр переподготовки специалистов
Курсовая работа
По дисциплине: Теория языков программирования и методы трансляции
Выполнил:
Группа:
Вариант: 6
Проверил: Бах О.А.
Новосибирск, 2016 г
Постановка задачи
Написать программу для автоматического построения грамматики, эквивалентной заданному регулярному выражению.
Язык задан регулярным выражением. При его записи могут быть использованы символы «0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c ,d ,e ,f ,g ,h, i, g, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z», а также: «+» (выбор одного из слагаемых), круглые скобки, «*» для обозначения итерации.
Программа должна:
-
по предложенному регулярному выражению строить эквивалентную грамматику, генерирующую этот же язык, в том виде, как она рассматривалась в теории; -
с помощью построенной грамматики генерировать все цепочки языка в заданном пользователем диапазоне длин.
Грамматика строится контекстно-свободная. Нетерминальный символ ‘S’ является целевым. Если в грамматике используется пустое правило, то пустая цепочка обозначается звездочкой ‘*’.
После построения грамматики пользователь может убедиться в её правильности путём генерации всех цепочек языка в том диапазоне длин, который он задаст. Генерацию каждой цепочки языка следует поэтапно отображать на экране в виде цепочки вывода.
Описание входных данных программы и её результатов
Вход программы: регулярное выражение в виде строки символов, 2 числа – диапазон длин для генерации цепочек.
Выход: построенная грамматика (все 4 элемента), результат генерации цепочек.
Алгоритм решения задачи
Для построения правил контекстно-свободной грамматики производим разбор исходного регулярного выражения. Каждая скобка обозначается своим нетерминалом. Если на скобке стоит звёздочка (итерация), значит, на этом нетерминале будет явная рекурсия и пустое правило. Если в выражении стоит «+», то это означает альтернативу в правилах.
Рассмотрим регулярное выражение
В результате получим грамматику:
По правилам полученной грамматики и с учетом диапазона длин генерировать цепочки языка. Вывод каждой цепочки отображать поэтапно.
Описание основных переменных и блоков программы
string VT - множество терминальных символов
string NT - множество нетерминальных символов
string S - целевой символ грамматики
string P - множество правил
char nonterminal – символ очередного нетерминала
string alphabet – алфавит регулярного выражения
List
List
- > rules – правила контекстно-свободной грамматики
List
List
- > order – содержит порядок порождения цепочек
void DefineGrammar() – формирует контекстно-свободную грамматику по полученным данным
bool CheckRegEx() – проверяет регулярное выражение
void ParseRegEx(string expression) – производит разбор регулярного выражения
void GenerateChains(string chain, string process, int numTerminals) – генерирует цепочки языка
void DisplayChains() – выводит цепочки на экран
Текст программы
using System;
using System.Collections;
using System.Collections.Generic;
using System.ComponentModel;
using System.IO;
using System.Data;
using System.Diagnostics;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace Term_project
{
public partial class Form1 : Form
{
private char nonterminal = 'A';
private string alphabet = "0123456789abcdefghijklmnopqrstuvwxyz()+*";
private List
private string VT = String.Empty;
private string NT = String.Empty;
private string S = "S";
private string P = String.Empty;
private List
- > rules = new List
- >();
private List
private ArrayList chains = new ArrayList();
private List
private List
- > order = new List
- >();
private List
private bool empty = false; // the chain contains the empty symbol
private bool leftHand = true;
string parse = String.Empty;
private string path = Application.StartupPath;
public Form1()
{
InitializeComponent();
}
// grammar definition
void DefineGrammar()
{
for (int i = 0; i < data.Count; i++)
{
char[] temp = data[i][1].ToCharArray();
for (int j = 0; j < temp.Length; j++)
{
if ((Char.IsLower(temp[j]) || Char.IsNumber(temp[j])) && !VT.Contains(temp[j]))
{
VT = VT + temp[j];
}
if (Char.IsUpper(temp[j]) && !NT.Contains(temp[j]))
{
NT = NT + temp[j];
}
}
if(i == data.Count - 1)
{
P = P + data[i][0] + " -> " + data[i][1];
}
else
{
P = P + data[i][0] + " -> " + data[i][1] + ";";
}
}
char[] arr = VT.ToCharArray();
Array.Sort(arr);
txtTerminals.Text = VT = String.Join(", ", arr);
txtNonterminals.Text = NT = String.Join(", ", (S + NT).ToCharArray());
txtTarget.Text = S;
txtRules.Lines = P.Split(';');
}
// make sure the regular expression is acceptable
bool CheckRegEx()
{
// check alphabet
for(int i = 0; i < txtRegEx.Text.Length; i++)
{
if(!alphabet.Contains(txtRegEx.Text[i]))
{
MessageBox.Show("Alphabet does not contain '" + txtRegEx.Text[i] + "'.");
txtRegEx.Select(i, 1);
txtRegEx.Focus();
return false;
}
}
// check brackets
if(txtRegEx.Text.Contains("(") || txtRegEx.Text.Contains(")"))
{
int bracket = 0;
List
for (int i = 0; i < txtRegEx.Text.Length; i++)
{
if (txtRegEx.Text[i] == '(')
{
bracket++;
brackets.Add(true);
}
else if (txtRegEx.Text[i] == ')')
{
bracket--;
if (i > 0)
{
// empty brackets
if (txtRegEx.Text[i - 1] == '(')
{
MessageBox.Show("Brackets must not be empty!");
txtRegEx.Select(i - 1, 2);
txtRegEx.Focus();
return false;
}
int index = brackets.LastIndexOf(true);
if (index > -1)
{
brackets[index] = false;
}
brackets.Add(false);
}
}
else
{
brackets.Add(false);
}
if (bracket < 0)
{
MessageBox.Show("A closing bracket ')' must be preceded by an opening bracket '('.");
txtRegEx.Select(i, 1);
txtRegEx.Focus();
return false;
}
}
if(bracket > 0)
{
MessageBox.Show("An opening bracket '(' must be followed by a closing bracket ')'.");
txtRegEx.Select(brackets.IndexOf(true), 1);
txtRegEx.Focus();
return false;
}
}
// check choice symbols
for (int i = 0; i < txtRegEx.Text.Length; i++)
{
if (txtRegEx.Text[i] == '+' && i == 0 || txtRegEx.Text[i] == '+' && i == txtRegEx.Text.Length - 1)
{
MessageBox.Show("A plus sign cannot take extreme left or right position.");
txtRegEx.Select(i, 1);
txtRegEx.Focus();
return false;
}
if (txtRegEx.Text[i] == '+' && i > 0)
{
switch (txtRegEx.Text[i - 1])
{
case '(':
MessageBox.Show("An opening bracket '(' must not be followed by a plus sign.");
txtRegEx.Select(i - 1, 2);
txtRegEx.Focus();
return false;
case '+':
MessageBox.Show("A double plus sign is not allowed.");
txtRegEx.Select(i - 1, 2);
txtRegEx.Focus();
return false;
}
}
if (txtRegEx.Text[i] == '+' && i < txtRegEx.Text.Length - 1)
{
switch (txtRegEx.Text[i + 1])
{
case ')':
MessageBox.Show("A closing bracket ')' must not be preceded by a plus sign.");
txtRegEx.Select(i, 2);
txtRegEx.Focus();
return false;
}
}
}
// remove excessive asterisks
int x = 0;
while (true)
{
if (txtRegEx.Text[x] == '*')
{
if (x > 0)
{
if (txtRegEx.Text[x - 1] != ')')
{
txtRegEx.Text = txtRegEx.Text.Remove(x--, 1);
}
}
else
{
txtRegEx.Text = txtRegEx.Text.Remove(0, 1);
x--;
}
}
if (++x == txtRegEx.Text.Length)
{
break;
}
}
return true;
}
// parse the source regular expression
private void ParseRegEx(string expression)
{
int flag = 0;
int start = -1;
int end = -1;
for (int i = 0; i < expression.Length; i++)
{
if(expression[i] == '(')
{
if(flag == 0 && i + 1 <= expression.Length)
{
start = i;
}
flag++;
}
else if (expression[i] == ')')
{
if (flag > 0)
{
flag--;
}
if (flag == 0)
{
bool asterisk = false;
if (i + 1 < expression.Length && expression[i + 1] == '*')
{
end = i + 1;
asterisk = true;
}
else
{
end = i;
}
string s = expression.Substring(start, end - start + 1);
bool match = false;
for (int j = 0; j < data.Count; j++)
{
if (data[j][1] == s && j == 0)
{
if (s.Contains('(') && s.Contains(')'))
{
if (asterisk)
{
s = s.Substring(1, s.Length - 3);
}
else
{
s = s.Substring(1, s.Length - 2);
}
ParseRegEx(s);
}
match = true;
break;
}
else if (data[j][1] == s)
{
match = true;
break;
}
}
if (!match)
{
data.Add(new string[] { (nonterminal++).ToString(), s });
if (s.Contains('(') && s.Contains(')'))
{
if (asterisk)
{
s = s.Substring(1, s.Length - 3);
}
else
{
s = s.Substring(1, s.Length - 2);
}
ParseRegEx(s);
}
}
}
}
}
}
// get the list of rules from a string
void RulesToList()
{
string[] temp = P.Split(new char[] { ';' });
index.Clear();
rules.Clear();
empty = false;
for (int i = 0; i < temp.Length; i++)
{
index.Add(temp[i].ElementAt(0));
temp[i] = temp[i].Substring(5).Replace(" ", String.Empty);
string[] rule = temp[i].Split(new char[] { '|' });
List
for (int j = 0; j < rule.Length; j++)
{
str.Add(rule[j]);
if (rule[j] == "*")
{
empty = true;
}
}
rules.Add(str);
}
}
// press 'build grammar' button
private void btnGrammar_Click(object sender, EventArgs e)
{
if (txtRegEx.Text.Length == 0 || !CheckRegEx())
{
return;
}
txtOutput.Clear();
nonterminal = 'A';
VT = String.Empty;
NT = String.Empty;
P = String.Empty;
data.Clear();
data.Add(new string[] { S, txtRegEx.Text });
ParseRegEx(txtRegEx.Text);
txtOutput.AppendText("The regular expression '" + txtRegEx.Text + "' parses into:");
txtOutput.AppendText(Environment.NewLine);
txtOutput.AppendText(Environment.NewLine);
/* Longer rules should be used first to make correct substitutions. */
// descending sort
for (int i = 0; i < data.Count - 1; i++)
{
if (data[i][1].Length < data[i + 1][1].Length)
{
string rule = data[i + 1][1];
string letter = data[i + 1][0];
data[i + 1][1] = data[i][1];
data[i + 1][0] = data[i][0];
data[i][1] = rule;
data[i][0] = letter;
}
}
// display parsing results
for (int i = 0; i < data.Count; i++)
{
txtOutput.AppendText(data[i][0] + " = " + data[i][1]);
txtOutput.AppendText(Environment.NewLine);
}
txtOutput.AppendText(Environment.NewLine);
// make substitutions
for (int i = 0; i < data.Count; i++)
{
for (int j = i + 1; j < data.Count; j++)
{
data[i][1] = data[i][1].Replace(data[j][1], data[j][0]);
}
}
// add recursion and empty rule
for (int i = 0; i < data.Count; i++)
{
if (data[i][1][data[i][1].Length - 1] == '*')
{
int j = 0;
while (j < data[i][1].Length)
{
if (data[i][1][j] == '*')
{
if (j > 0)
{
for (int z = 0; z < data.Count; z++)
{
if (data[z][0] == data[i][1][j - 1].ToString())
{
data[i][1] = data[i][1].Remove(j - 1, 1).Insert(j - 1, data[z][1]);
}
}
}
}
j++;
}
data[i][1] = data[i][1].Replace("+", data[i][0] + "|");
data[i][1] = data[i][1].Replace("*", String.Empty);
data[i][1] = data[i][1] + data[i][0] + "|*";
}
else
{
data[i][1] = data[i][1].Replace("+", "|");
}
data[i][1] = data[i][1].Replace("(", String.Empty);
data[i][1] = data[i][1].Replace(")", String.Empty);
}
DefineGrammar();
RulesToList();
txtOutput.AppendText("The context-free grammar for this expression is as follows:");
txtOutput.AppendText(Environment.NewLine);
txtOutput.AppendText(Environment.NewLine);
// display the grammar
txtOutput.AppendText("G({" + txtTerminals.Text + "}, {" + txtNonterminals.Text + "}, P, S), where P:");
txtOutput.AppendText(Environment.NewLine);
for (int i = 0; i < data.Count; i++)
{
txtOutput.AppendText(" " + data[i][0] + " -> " + data[i][1]);
txtOutput.AppendText(Environment.NewLine);
}
txtOutput.AppendText(Environment.NewLine);
btnGenerate.Enabled = true;
parse = txtOutput.Text;
}
// generate chains
void GenerateChains(string chain, string process, int numTerminals)
{
if (empty)
{
if (numTerminals > numMax.Value)
{
return;
}
}
else
{
if (chain.Length > numMax.Value)
{
return;
}
}
// update chain building process
try
{
process = process + chain + " " + "\u21D2" + " ";
}
catch (System.IO.IOException e)
{
MessageBox.Show(e.Message, "Error!");
this.Close();
}
bool terminal = true;
if (leftHand)
{
// cycle through the chain of symbols
for (int c = 0; c < chain.Length; c++)
{
// if a nonterminal found
if (NT.Contains(chain[c]))
{
// keep track of the nonterminals being substituted
track.Add(c);
terminal = false;
// apply all the rules for this nonterminal
for (int i = 0; i < rules[index.IndexOf(chain[c])].Count; i++)
{
string s = "";
// if came over an empty rule
if (rules[index.IndexOf(chain[c])][i] == "*")
{
// delete the nonterminal
s = chain.Remove(c, 1);
}
else
{
// replace the nonterminal as stated by the rules
s = chain.Remove(c, 1).Insert(c, rules[index.IndexOf(chain[c])][i]);
}
// calculate the number of terminal symbols in the resulting chain
numTerminals = 0;
if (empty)
{
for (int j = 0; j < s.Length; j++)
{
if (VT.Contains(s[j]))
{
numTerminals++;
}
}
}
GenerateChains(s, process, numTerminals);
}
// remove the substituted nonterminal
track.RemoveAt(track.Count - 1);
break;
}
}
}
else
{
for (int c = chain.Length - 1; c >= 0; c--)
{
if (NT.Contains(chain[c]))
{
track.Add(c);
terminal = false;
for (int i = rules[index.IndexOf(chain[c])].Count - 1; i >= 0; i--)
{
string s = "";
if (rules[index.IndexOf(chain[c])][i] == "*")
{
s = chain.Remove(c, 1);
}
else
{
s = chain.Remove(c, 1).Insert(c, rules[index.IndexOf(chain[c])][i]);
}
numTerminals = 0;
if (empty)
{
for (int j = 0; j < s.Length; j++)
{
if (VT.Contains(s[j]))
{
numTerminals++;
}
}
}
GenerateChains(s, process, numTerminals);
}
track.RemoveAt(track.Count - 1);
break;
}
}
}
if (terminal)
{
// ignore duplicates
if (!chains.Contains(chain) && chain.Length >= numMin.Value)
{
chains.Add(chain);
output.Add(process.Substring(0, process.Length - 3) + Environment.NewLine);
order.Add(new List
}
}
}
// press 'generate' button
private void btnGenerate_Click(object sender, EventArgs e)
{
txtOutput.Clear();
txtOutput.AppendText(parse);
txtOutput.AppendText("The grammar generates the following chains:");
txtOutput.AppendText(Environment.NewLine);
txtOutput.AppendText(Environment.NewLine);
chains.Clear();
output.Clear();
order.Clear();
btnGenerate.Enabled = false;
btnGrammar.Enabled = false;
foreach(ToolStripMenuItem item in menuStrip1.Items)
{
foreach (ToolStripItem subitem in item.DropDownItems)
{
if(subitem.Text == "Load" || subitem.Text == "Save")
{
subitem.Enabled = false;
}
}
}
progressBar1.Visible = true;
progressBar1.Style = ProgressBarStyle.Marquee;
progressBar1.MarqueeAnimationSpeed = 50;
BackgroundWorker bw = new BackgroundWorker();
bw.DoWork += bw_DoWork;
bw.RunWorkerCompleted += bw_RunWorkerCompleted;
bw.RunWorkerAsync();
lblInfo.Visible = true;
}
// generation and output of chains in a separate thread
void bw_DoWork(object sender, DoWorkEventArgs e)
{
GenerateChains(S, String.Empty, 0);
DisplayChains();
}
// auxiliary function for thread interchange during output
void AddText(char value, int type)
{
if (InvokeRequired)
{
this.Invoke(new Action
return;
}
switch(type)
{
case 0:
txtOutput.DeselectAll();
return;
case 1:
txtOutput.SelectionFont = new Font("Arial", 11, FontStyle.Bold);
return;
case 2:
txtOutput.SelectionFont = new Font("Arial", 11, FontStyle.Underline);
return;
case 3:
txtOutput.SelectionFont = new Font("Arial", 11, FontStyle.Regular);
return;
case 4:
txtOutput.AppendText(value.ToString());
return;
}
}
void DisplayChains()
{
// show results and format text
for (int i = 0; i < output.Count; i++)
{
int boldStart = output[i].LastIndexOf("\u21D2") + 2;
int count = 0;
int n = 0;
bool flag = false;
for (int j = 0; j < output[i].Length; j++)
{
AddText(output[i][j], 0);
// make resulting chains bold
if (j == boldStart)
{
AddText(output[i][j], 1);
}
// underline nonterminals being substituted
if (output[i][j] == '\u21D2' && j != boldStart - 2)
{
flag = true;
count++;
n = 0;
}
if (flag && output[i][j] != '\u21D2' && output[i][j] != ' ')
{
if (n++ == order[i][count])
{
AddText(output[i][j], 2);
AddText(output[i][j], 4);
AddText(output[i][j], 3);
flag = false;
continue;
}
}
AddText(output[i][j], 4);
}
}
}
// generation accomplished
void bw_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
progressBar1.MarqueeAnimationSpeed = 0;
progressBar1.Style = ProgressBarStyle.Blocks;
progressBar1.Value = progressBar1.Minimum;
progressBar1.Visible = false;
lblInfo.Visible = false;
btnGenerate.Enabled = true;
btnGrammar.Enabled = true;
foreach (ToolStripMenuItem item in menuStrip1.Items)
{
foreach (ToolStripItem subitem in item.DropDownItems)
{
if (subitem.Text == "Load" || subitem.Text == "Save")
{
subitem.Enabled = true;
}
}
}
}
// choose left/right-hand output
private void radioButtonOutput_CheckedChanged(object sender, EventArgs e)
{
if (radioLeft.Checked)
{
leftHand = true;
}
else
{
leftHand = false;
}
}
// set minimum chain length
private void numMin_ValueChanged(object sender, EventArgs e)
{
if (numMin.Value > numMax.Value)
{
numMin.Value = numMax.Value;
}
}
// set maximum chain length
private void numMax_ValueChanged(object sender, EventArgs e)
{
if (numMax.Value < numMin.Value)
{
numMax.Value = numMin.Value;
}
}
// select 'about' item
private void aboutToolStripMenuItem_Click(object sender, EventArgs e)
{
Form2 about = new Form2();
about.ShowDialog();
}
// select 'view help' item
private void viewHelpToolStripMenuItem_Click(object sender, EventArgs e)
{
Form3 help = new Form3();
help.ShowDialog();
}
// select 'load' item
private void loadToolStripMenuItem_Click(object sender, EventArgs e)
{
OpenFileDialog open = new OpenFileDialog();
open.Filter = "|*.txt";
open.InitialDirectory = path + "\\regex\\";
open.Title = "Load regular expression from file";
open.ShowDialog();
if(open.FileName != String.Empty)
{
using (StreamReader reader = new StreamReader(open.FileName))
{
txtRegEx.Text = reader.ReadToEnd();
}
}
}
// select 'save' item
private void saveToolStripMenuItem_Click(object sender, EventArgs e)
{
if (!Directory.Exists(path + "\\results\\"))
{
Directory.CreateDirectory(path + "\\results\\");
}
SaveFileDialog save = new SaveFileDialog();
save.Filter = "|*.txt";
save.InitialDirectory = path + "\\results\\";
save.OverwritePrompt = true;
save.Title = "Save results to file";
save.ShowDialog();
if (save.FileName != String.Empty)
{
using (StreamWriter writer = new StreamWriter(save.FileName, false, Encoding.Unicode))
{
for (int i = 0; i < txtOutput.Lines.Length; i++)
{
writer.WriteLine(txtOutput.Lines[i]);
}
}
}
}
// select 'exit' item
private void exitToolStripMenuItem_Click(object sender, EventArgs e)
{
this.Close();
}
// press 'results folder' button
private void btnResultsFolder_Click(object sender, EventArgs e)
{
Process.Start(path + "\\results\\");
}
// press 'regex folder' button
private void btnRegExFolder_Click(object sender, EventArgs e)
{
Process.Start(path + "\\regex\\");
}
}
}
Результаты работы программы
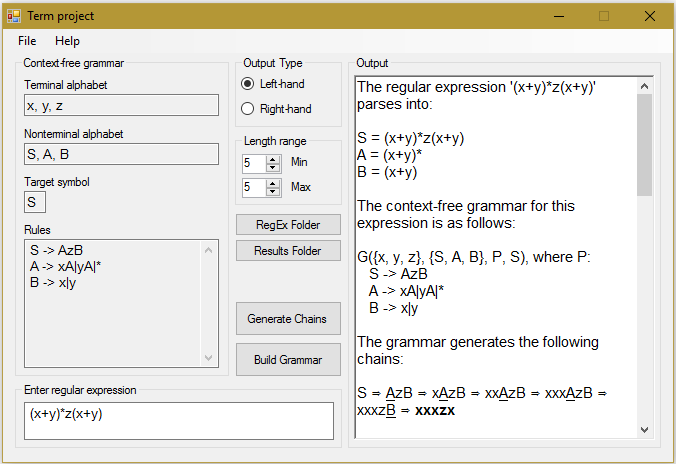
Распечатка файла результатов
The regular expression '(x+y)*z(x+y)' parses into:
Я бы полагала, что в этом примере следовало описать А как ВА| пусто.
S = (x+y)*z(x+y)
A = (x+y)*
B = (x+y)
The context-free grammar for this expression is as follows:
G({x, y, z}, {S, A, B}, P, S), where P:
S -> AzB
A -> xA|yA|*
B -> x|y
The grammar generates the following chains:
S ⇒ AzB ⇒ xAzB ⇒ xxAzB ⇒ xxxAzB ⇒ xxxzB ⇒ xxxzx
S ⇒ AzB ⇒ xAzB ⇒ xxAzB ⇒ xxxAzB ⇒ xxxzB ⇒ xxxzy
S ⇒ AzB ⇒ xAzB ⇒ xxAzB ⇒ xxyAzB ⇒ xxyzB ⇒ xxyzx
S ⇒ AzB ⇒ xAzB ⇒ xxAzB ⇒ xxyAzB ⇒ xxyzB ⇒ xxyzy
S ⇒ AzB ⇒ xAzB ⇒ xyAzB ⇒ xyxAzB ⇒ xyxzB ⇒ xyxzx
S ⇒ AzB ⇒ xAzB ⇒ xyAzB ⇒ xyxAzB ⇒ xyxzB ⇒ xyxzy
S ⇒ AzB ⇒ xAzB ⇒ xyAzB ⇒ xyyAzB ⇒ xyyzB ⇒ xyyzx
S ⇒ AzB ⇒ xAzB ⇒ xyAzB ⇒ xyyAzB ⇒ xyyzB ⇒ xyyzy
S ⇒ AzB ⇒ yAzB ⇒ yxAzB ⇒ yxxAzB ⇒ yxxzB ⇒ yxxzx
S ⇒ AzB ⇒ yAzB ⇒ yxAzB ⇒ yxxAzB ⇒ yxxzB ⇒ yxxzy
S ⇒ AzB ⇒ yAzB ⇒ yxAzB ⇒ yxyAzB ⇒ yxyzB ⇒ yxyzx
S ⇒ AzB ⇒ yAzB ⇒ yxAzB ⇒ yxyAzB ⇒ yxyzB ⇒ yxyzy
S ⇒ AzB ⇒ yAzB ⇒ yyAzB ⇒ yyxAzB ⇒ yyxzB ⇒ yyxzx
S ⇒ AzB ⇒ yAzB ⇒ yyAzB ⇒ yyxAzB ⇒ yyxzB ⇒ yyxzy
S ⇒ AzB ⇒ yAzB ⇒ yyAzB ⇒ yyyAzB ⇒ yyyzB ⇒ yyyzx
S ⇒ AzB ⇒ yAzB ⇒ yyAzB ⇒ yyyAzB ⇒ yyyzB ⇒ yyyzy
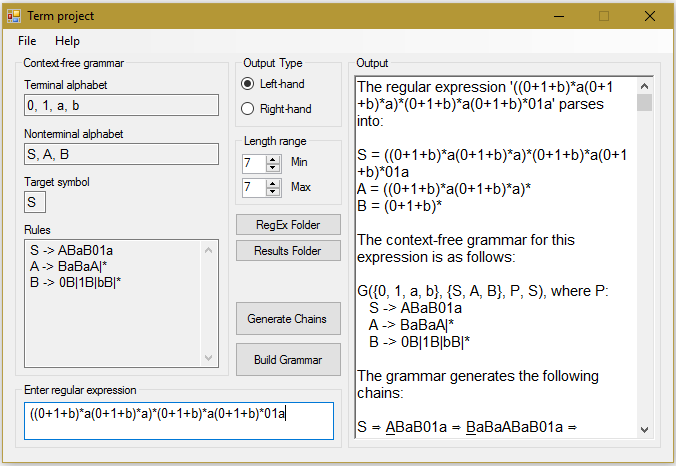
The regular expression '((0+1+b)*a(0+1+b)*a)*(0+1+b)*a(0+1+b)*01a' parses into:
S = ((0+1+b)*a(0+1+b)*a)*(0+1+b)*a(0+1+b)*01a
A = ((0+1+b)*a(0+1+b)*a)*
B = (0+1+b)*
The context-free grammar for this expression is as follows:
G({0, 1, a, b}, {S, A, B}, P, S), where P:
S -> ABaB01a
A -> BaBaA|*
B -> 0B|1B|bB|*
The grammar generates the following chains:
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ 0BaBaABaB01a ⇒ 0aBaABaB01a ⇒ 0aaABaB01a ⇒ 0aaBaB01a ⇒ 0aaaB01a ⇒ 0aaa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ 1BaBaABaB01a ⇒ 1aBaABaB01a ⇒ 1aaABaB01a ⇒ 1aaBaB01a ⇒ 1aaaB01a ⇒ 1aaa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ bBaBaABaB01a ⇒ baBaABaB01a ⇒ baaABaB01a ⇒ baaBaB01a ⇒ baaaB01a ⇒ baaa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ a0BaABaB01a ⇒ a0aABaB01a ⇒ a0aBaB01a ⇒ a0aaB01a ⇒ a0aa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ a1BaABaB01a ⇒ a1aABaB01a ⇒ a1aBaB01a ⇒ a1aaB01a ⇒ a1aa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ abBaABaB01a ⇒ abaABaB01a ⇒ abaBaB01a ⇒ abaaB01a ⇒ abaa01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aa0BaB01a ⇒ aa0aB01a ⇒ aa0a01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aa1BaB01a ⇒ aa1aB01a ⇒ aa1a01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aabBaB01a ⇒ aabaB01a ⇒ aaba01a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aaaB01a ⇒ aaa0B01a ⇒ aaa001a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aaaB01a ⇒ aaa1B01a ⇒ aaa101a
S ⇒ ABaB01a ⇒ BaBaABaB01a ⇒ aBaABaB01a ⇒ aaABaB01a ⇒ aaBaB01a ⇒ aaaB01a ⇒ aaabB01a ⇒ aaab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 000BaB01a ⇒ 000aB01a ⇒ 000a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 001BaB01a ⇒ 001aB01a ⇒ 001a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 00bBaB01a ⇒ 00baB01a ⇒ 00ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 00aB01a ⇒ 00a0B01a ⇒ 00a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 00aB01a ⇒ 00a1B01a ⇒ 00a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 00BaB01a ⇒ 00aB01a ⇒ 00abB01a ⇒ 00ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 010BaB01a ⇒ 010aB01a ⇒ 010a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 011BaB01a ⇒ 011aB01a ⇒ 011a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 01bBaB01a ⇒ 01baB01a ⇒ 01ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 01aB01a ⇒ 01a0B01a ⇒ 01a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 01aB01a ⇒ 01a1B01a ⇒ 01a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 01BaB01a ⇒ 01aB01a ⇒ 01abB01a ⇒ 01ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0b0BaB01a ⇒ 0b0aB01a ⇒ 0b0a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0b1BaB01a ⇒ 0b1aB01a ⇒ 0b1a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0bbBaB01a ⇒ 0bbaB01a ⇒ 0bba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0baB01a ⇒ 0ba0B01a ⇒ 0ba001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0baB01a ⇒ 0ba1B01a ⇒ 0ba101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0bBaB01a ⇒ 0baB01a ⇒ 0babB01a ⇒ 0bab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a0B01a ⇒ 0a00B01a ⇒ 0a0001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a0B01a ⇒ 0a01B01a ⇒ 0a0101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a0B01a ⇒ 0a0bB01a ⇒ 0a0b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a1B01a ⇒ 0a10B01a ⇒ 0a1001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a1B01a ⇒ 0a11B01a ⇒ 0a1101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0a1B01a ⇒ 0a1bB01a ⇒ 0a1b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0abB01a ⇒ 0ab0B01a ⇒ 0ab001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0abB01a ⇒ 0ab1B01a ⇒ 0ab101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 0BaB01a ⇒ 0aB01a ⇒ 0abB01a ⇒ 0abbB01a ⇒ 0abb01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 100BaB01a ⇒ 100aB01a ⇒ 100a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 101BaB01a ⇒ 101aB01a ⇒ 101a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 10bBaB01a ⇒ 10baB01a ⇒ 10ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 10aB01a ⇒ 10a0B01a ⇒ 10a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 10aB01a ⇒ 10a1B01a ⇒ 10a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 10BaB01a ⇒ 10aB01a ⇒ 10abB01a ⇒ 10ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 110BaB01a ⇒ 110aB01a ⇒ 110a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 111BaB01a ⇒ 111aB01a ⇒ 111a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 11bBaB01a ⇒ 11baB01a ⇒ 11ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 11aB01a ⇒ 11a0B01a ⇒ 11a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 11aB01a ⇒ 11a1B01a ⇒ 11a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 11BaB01a ⇒ 11aB01a ⇒ 11abB01a ⇒ 11ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1b0BaB01a ⇒ 1b0aB01a ⇒ 1b0a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1b1BaB01a ⇒ 1b1aB01a ⇒ 1b1a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1bbBaB01a ⇒ 1bbaB01a ⇒ 1bba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1baB01a ⇒ 1ba0B01a ⇒ 1ba001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1baB01a ⇒ 1ba1B01a ⇒ 1ba101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1bBaB01a ⇒ 1baB01a ⇒ 1babB01a ⇒ 1bab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a0B01a ⇒ 1a00B01a ⇒ 1a0001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a0B01a ⇒ 1a01B01a ⇒ 1a0101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a0B01a ⇒ 1a0bB01a ⇒ 1a0b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a1B01a ⇒ 1a10B01a ⇒ 1a1001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a1B01a ⇒ 1a11B01a ⇒ 1a1101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1a1B01a ⇒ 1a1bB01a ⇒ 1a1b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1abB01a ⇒ 1ab0B01a ⇒ 1ab001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1abB01a ⇒ 1ab1B01a ⇒ 1ab101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ 1BaB01a ⇒ 1aB01a ⇒ 1abB01a ⇒ 1abbB01a ⇒ 1abb01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b00BaB01a ⇒ b00aB01a ⇒ b00a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b01BaB01a ⇒ b01aB01a ⇒ b01a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b0bBaB01a ⇒ b0baB01a ⇒ b0ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b0aB01a ⇒ b0a0B01a ⇒ b0a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b0aB01a ⇒ b0a1B01a ⇒ b0a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b0BaB01a ⇒ b0aB01a ⇒ b0abB01a ⇒ b0ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b10BaB01a ⇒ b10aB01a ⇒ b10a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b11BaB01a ⇒ b11aB01a ⇒ b11a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b1bBaB01a ⇒ b1baB01a ⇒ b1ba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b1aB01a ⇒ b1a0B01a ⇒ b1a001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b1aB01a ⇒ b1a1B01a ⇒ b1a101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ b1BaB01a ⇒ b1aB01a ⇒ b1abB01a ⇒ b1ab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bb0BaB01a ⇒ bb0aB01a ⇒ bb0a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bb1BaB01a ⇒ bb1aB01a ⇒ bb1a01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bbbBaB01a ⇒ bbbaB01a ⇒ bbba01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bbaB01a ⇒ bba0B01a ⇒ bba001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bbaB01a ⇒ bba1B01a ⇒ bba101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ bbBaB01a ⇒ bbaB01a ⇒ bbabB01a ⇒ bbab01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba0B01a ⇒ ba00B01a ⇒ ba0001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba0B01a ⇒ ba01B01a ⇒ ba0101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba0B01a ⇒ ba0bB01a ⇒ ba0b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba1B01a ⇒ ba10B01a ⇒ ba1001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba1B01a ⇒ ba11B01a ⇒ ba1101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ ba1B01a ⇒ ba1bB01a ⇒ ba1b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ babB01a ⇒ bab0B01a ⇒ bab001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ babB01a ⇒ bab1B01a ⇒ bab101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ bBaB01a ⇒ baB01a ⇒ babB01a ⇒ babbB01a ⇒ babb01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a00B01a ⇒ a000B01a ⇒ a00001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a00B01a ⇒ a001B01a ⇒ a00101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a00B01a ⇒ a00bB01a ⇒ a00b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a01B01a ⇒ a010B01a ⇒ a01001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a01B01a ⇒ a011B01a ⇒ a01101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a01B01a ⇒ a01bB01a ⇒ a01b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a0bB01a ⇒ a0b0B01a ⇒ a0b001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a0bB01a ⇒ a0b1B01a ⇒ a0b101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a0B01a ⇒ a0bB01a ⇒ a0bbB01a ⇒ a0bb01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a10B01a ⇒ a100B01a ⇒ a10001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a10B01a ⇒ a101B01a ⇒ a10101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a10B01a ⇒ a10bB01a ⇒ a10b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a11B01a ⇒ a110B01a ⇒ a11001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a11B01a ⇒ a111B01a ⇒ a11101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a11B01a ⇒ a11bB01a ⇒ a11b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a1bB01a ⇒ a1b0B01a ⇒ a1b001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a1bB01a ⇒ a1b1B01a ⇒ a1b101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ a1B01a ⇒ a1bB01a ⇒ a1bbB01a ⇒ a1bb01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab0B01a ⇒ ab00B01a ⇒ ab0001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab0B01a ⇒ ab01B01a ⇒ ab0101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab0B01a ⇒ ab0bB01a ⇒ ab0b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab1B01a ⇒ ab10B01a ⇒ ab1001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab1B01a ⇒ ab11B01a ⇒ ab1101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ ab1B01a ⇒ ab1bB01a ⇒ ab1b01a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ abbB01a ⇒ abb0B01a ⇒ abb001a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ abbB01a ⇒ abb1B01a ⇒ abb101a
S ⇒ ABaB01a ⇒ BaB01a ⇒ aB01a ⇒ abB01a ⇒ abbB01a ⇒ abbbB01a ⇒ abbb01a