Файл: Лекция 1 (03. 02. 2021) Тема 1 Основные сведения о геоинформационных системах (гис) Понятия информации и данных.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.11.2023
Просмотров: 105
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Тип значений в ячейках растра определяется как реальным явлением, так и особенностями ГИС.
Угол между направлением на север и положением колонок растра.
Растр не требует предварительного знакомства с явлениями и пространственными объектами. Данные собираются с равномерно расположенной сети точек.
Растровые модели проще при обработке данных и этим обеспечивают более высокое быстродействие по сравнению с векторными моделями. Многие растровые модели позволяют вводить векторные данные, в то время как обратная процедура затруднительна.
Наиболее часто растровые модели применяют не только в ГИС, но и при помощи зондирования.
Недостатки:
- проблема низкой пространственной точности, которая уменьшает достоверность измерения площади и расстояний;
- необходимость большого объема памяти компьютера для хранения и обработки данных.
Методы сжатия растровых данных
-
Групповое кодирование. В строку последовательно вводят значения атрибута и номер конечного столбца группы с одинаковыми атрибутами. Данные вводятся парой чисел: первое обозначает длину группы, второе значение. -
Метод цепочечного кодирования. Указываются координаты x и y начала, значения ячеек для всей области. А затем вектора направлений, показывающие куда двигаться дальше, где повернуть и как далеко идти. Обычно векторы описываются количеством ячеек и направлением в виде чисел 0,1,2,3, которые соответствуют движению вверх, вниз, вправо и влево. -
Квадродерево. Основано на квадратных группах ячеек растра. В этом случае вся карта последовательно делится на квадраты с одинаковым значением атрибута внутри, и квадрата, если один из них однороден, т.е. содержит ячейки с одним значением, то он записывается и больше не делится. Каждые оставшиеся квадраты проверяются на однородность => делятся (однородные), пока вся карта не будет записана как множество квадратных групп ячеек). Мельчайшим квадратом является ячейка растра. Система с переменным разрешением – система квадродерева. -
Векторный метод. Векторная модель данных показывает только геометрию объектов. Это цифровое представление точечных, линейных и полигональных объектов в виде набора координатных пар.
Векторно-нетопологическая модель (спагетти-модель). Число слоев может быть большим.
Векторно-топологическая модель. Топология описывается набором узлов и дуг. Узел – пересечение двух или более дуг. Каждая дуга начинается в точке пересечения узлов, не принадлежащих друг другу, в точке с другой дугой. Дуги образуются последов. отрезков, соседних промежутков. Каждая линия имеет 2 набора чисел. Каждая дуга имеет свой идентификационный номер. Области, ограниченные дугами, также имеют идентифицирующие их коды, которые используются для определения их отношений с дугами. Каждая дуга имеет информацию о номере областей слева и справа от нее. Это позволяет компьютеру знать действительное отношение между графическими объектами.
Векторная модель (TIN-модель) для представления поверхности. Каждая точка имеет свою высоту. Для описания рельефа.
Методы сжатия векторных данных
Цепочечные коды Фрэнсиса Гальтона и Фримена-Хофмана.
Форматы данные, используемые в ГИС
Растровые форматы:
TIFF – большая глубина цвета; PNG – лучше всего подходит для карт; JPEG, GIF – 8 бит на pix; BMP, WMF, PCX, GeoSpot, GeoTIFF, MrSID, F1M – роскартография; SYE – венно-топографическая служба; GeoJSON – открытый формат, предназначенный для хранения географических структур данных, основанных на JSON.
Основные обменные форматы:
SHP, EOO, GEN (ESPI), VEC (IDRISI), MIF (MapInfo Corp), DWG, DXF, WMF (Microsoft), DGN (Bentley)
Лекция №4 (17.03.2021)
Основы баз данных
База данных – совокупность данных некоторой предметной области, структурируемых и организованных по правилам, устанавливающих общие принципы описания, хранения и управления данными.
Ядром любой БД являются модели данных.
Модель данных – совокупность правил порождения структур данных в БД, операций над ними, а также ограничений целостности, определяющих допустимые связи и значения данных и последовательности их изменения.
Таким образом в модель данных входят 3 составляющие:
-
Средство для организации данных -
Операции для обработки и манипулировании данными -
Ограничения, обеспечивающие целостность данных
Классификация моделей данных



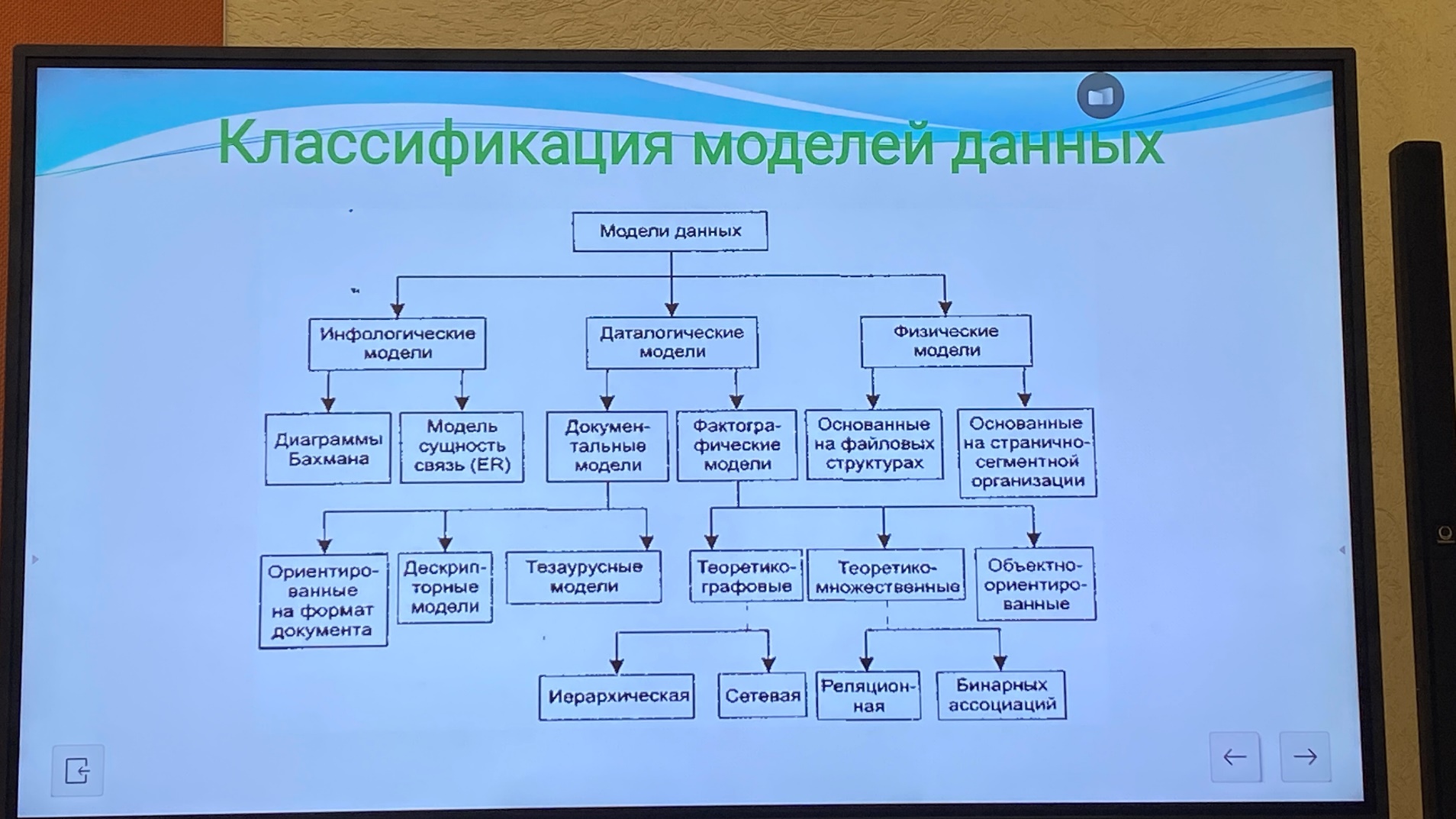
В ГИС для организации пространственных данных применяются теоретико-графовые и теоретико-множественные модели.
Теоретико-графовые модели отражают совокупность объектов реального мира в виде графо-взаимосвязанных информационных объектов.
В зависимости от типа графа различают иерархическую и сетевую модели.
Иерархическая модель данных представляет собой совокупность элементов данных, расположенных в порядке их подчинения и образующих по структуре перевернутое дерево. К основным понятиям этой модели относится уровень, узел и связь.
Узел – совокупность атрибутов данных, описывающих информационный объект.

Иерархическая структура должна удовлетворять следующим требованиям:
- каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне;
- существует только один корневой узел на самом верхнем уровне, не подчиненный никакому другому узлу;
- каждому узлу существует только один путь от корневого узла.
Атрибут (элемент данных, поле) – наименьшая неделимая единица данных, доступная пользователю.
Сетевая модель (ЧАРЛЬЗ БАХМАН)
Сетевая модель – это структура, каждый элемент которой может быть связан с любым другим элементом.

Сетевая модель основана на тех же понятиях, что и иерархическая модель – уровень, узел и связь.
Кроме данных, записи содержат указатели, определяющие местоположение других записей, связанных с ними.
Сетевые модели используют отношения многие ко многим, при котором один объект может иметь множество атрибутов, а каждый из них связан со множеством объектов. Такие модели трудно редактировать, например, удалять записи, так как вместе с данными нужно редактировать и указатели.
Реляционная модель данных - представляет собой совокупность множества взаимосвязанных «отношений».
Предложен Эдгаром Коддом в 1970 г.
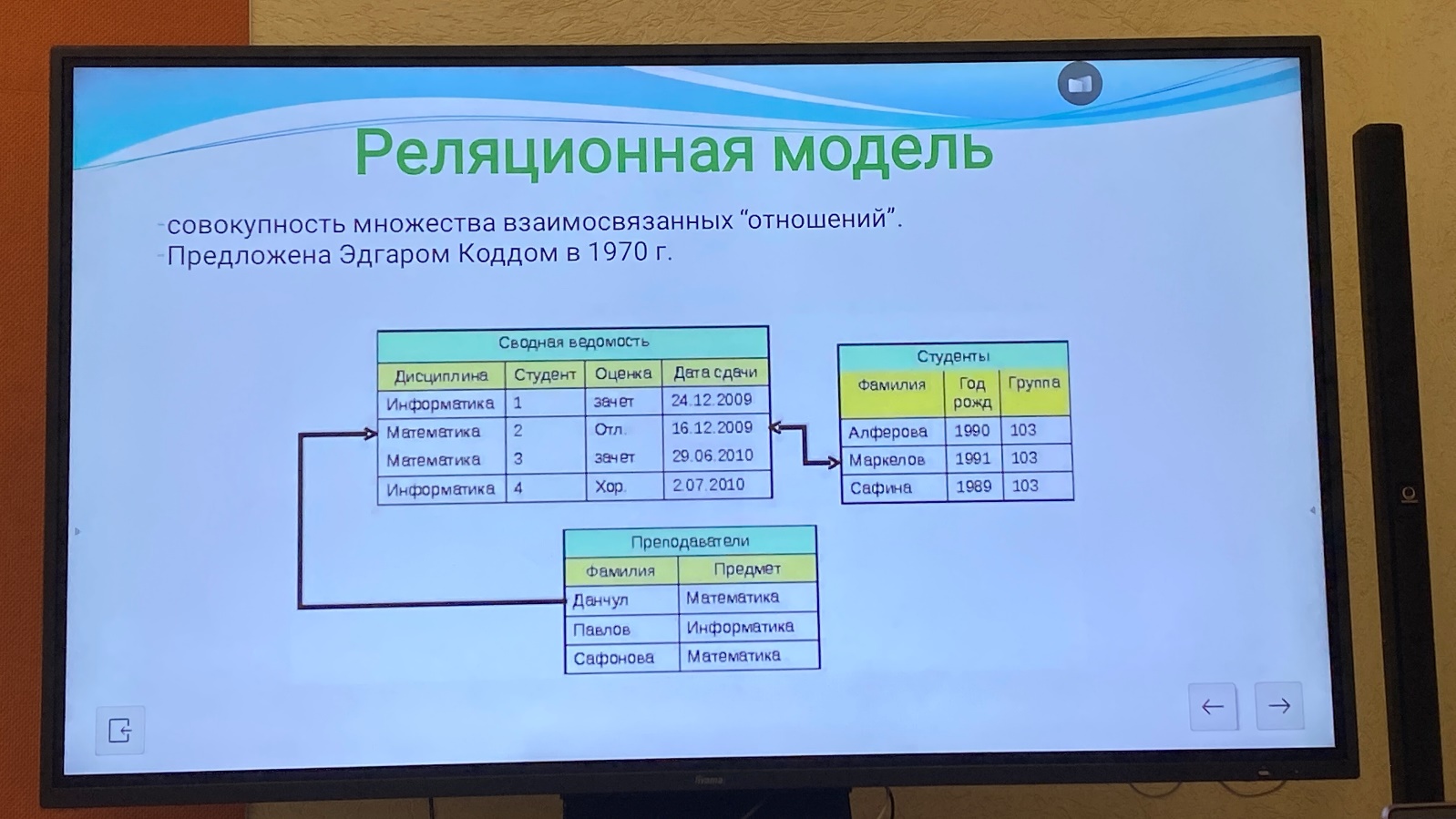
Отношения в БД графически интерпретируются в виде таблицы, столбцы которой соответствуют атрибутам и называются полями. Строки соответствуют кортежам и называются записями.
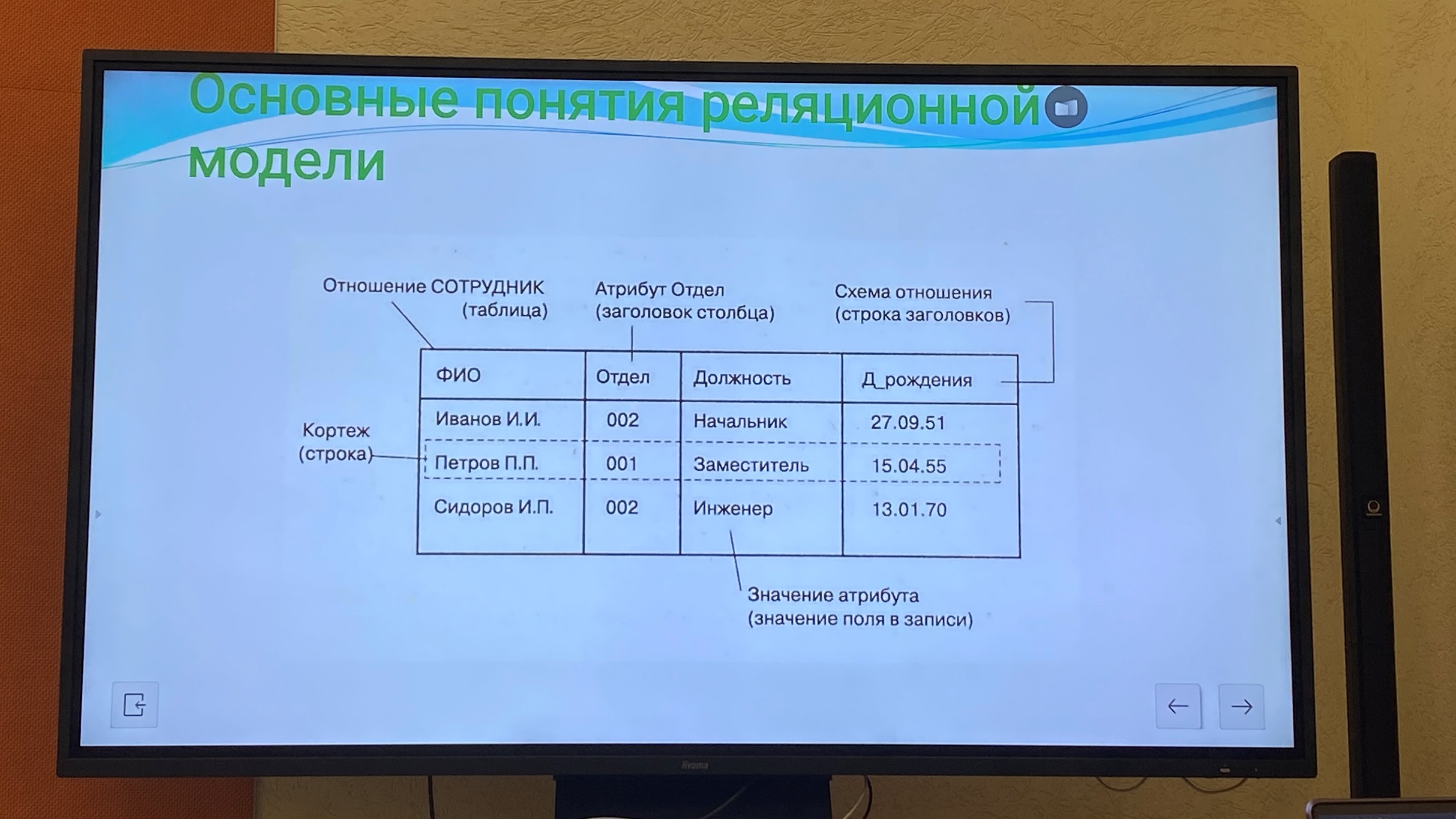
Таблица – это совокупность записи одной структуры.
Запись (строка в таблице, кортеж) – совокупность логически связанных полей.
Поле (столбец в таблице, атрибут) – элементарная единица логической организации данных.
Для описания полей используются характеристики:
- имя;
- тип поля (символьный, логический, числовой, денежный, календарный);
- длина (в байтах или символах);
- точность (количество знаков после запятой).
Все таблицы характеризуются набором
свойств:
- в таблице нет двух одинаковых строк;
- все столбцы в таблице однородны (все элементы в столбце имеют одинаковую тип и длину);
- каждый атрибут в отношении имеют уникальное имя;
- порядок строк и столбцом в таблице произвольный.
Так как строки в реляционной таблице не упорядочены, то нельзя выбрать строку по ее порядковому номеру в таблице. Поэтому для однозначного определения записи в таблице все поля в таблице подразделяют на ключевые и описательные.
Ключевое поле (первичный ключ) – поле, каждое значение которого однозначно определяет соответствующую запись. Если в таблице имеет только одно ключевое поле, то такая таблица имеет простой ключ. Если записи однозначно определяются значениями нескольких полей, то такая таблица имеет составной ключ.
В силу того, что в таблицах реляционной БД допускается произвольный порядок столбцов, возникает необходимость в такой группировке полей, при которой обеспечивалось бы минимальное дублирование данных и упрощение процедур их обработки и управлений. Для этого используется аппарат нормализации отношений.
Нормализация отношений – механизм последовательного преобразования таблиц в совершенной нормальной форме.
Домен – множество значений, которые может принимать некоторый атрибут.
В БД связи между отношениями поддерживаются через наборы атрибутов, который называются внешними ключами или внешними ключевыми полями.
Внешний ключ – столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом для одной таблицы.
Связи 1:1 предполагают, что одной записи таблицы А, соответствуют не более одной записи таблицы B и наоборот.
При типе связей 1:М (ко многим) одной записи таблицы C соответствует 0, 1 или более записей таблицей B, но одна запись таблице B связана не более чем с одной записью таблицы C.
Связь М:М предполагает, что одной записи таблице C соответствует 0, 1 и более записей таблицы B и наоборот.
Достоинства и недостатки реляционных моделей
Достоинства реляционной модели:
* простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является "таблица";
* строгие правила проектирования, базирующиеся на математическом аппарате;
* полная независимость данных. Изменения в прикладной программе при изменении реляционной БД минимальны;
* для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти.
Недостатки реляционной модели:
* далеко не всегда предметная область может быть представлена в виде "таблиц";
* в результате логического проектирования появляется множество "таблиц". Это приводит к трудности понимания структуры данных;
* БД занимает относительно много внешней памяти;
* относительно низкая скорость доступа к данным.
Система управления БД (СУБД)
Создание БД, её поддержка, обеспечение доступа пользователя к информации осуществляется с помощью специального инструмента, который называется СУБД.
Т.о. СУБД – комплекс программных и языковых средств, необходимых для создания БД, а также поддержания их в рабочем состоянии и организации поиска необходимой информации.
Современные СУБД классифицируется в соответствии с используемой моделью данных и в зависимости от объема, поддерживаемых БД и используемого числа пользователей.
СУБД подразделяются на высший уровень, средний, низший и настольные СУБД.
Высший уровень СУБД поддерживают крупные БД, сотни и тысячи Гб и более, обслуживающие тысячи пользователей.
Средний уровень поддерживают БД до нескольких сотен Гб и обслуживают сотни пользователей.
Нижний уровень составляют системы, которые поддерживают БД до 1 Гб и имеют менее 100 пользователей. Их используют в небольших подразделениях.
Настольные СУБД предназначены для 1 пользователя, применяются для ведения настольной БД. Они имеют ограниченные возможности по обработке данных и у них отсутствует возможность установки в сети.
Среди основных функций СУБД принято выделять следующие:
- управление данными во внешней памяти, структурируя ее как для хранения данных в БД, так и для служебных целей, например для убыстрения доступа к данным;
- управления буферами оперативной памяти, создаваемыми для устранения зависимости от скорости работы устройств внешней памяти;
- операции над БД заключающиеся в обеспечении эффективности управлениями транзакциями.
Транзакция – неделимая с точки зрения воздействия на БД последовательность операций манипулирования данными, рассматриваемая СУБД как единое целое.
- обеспечение надежности хранения данных в БД. Заключается в способности СУБД восстанавливать состояние после аппаратного или программного сбоя.
- поддержка специального языка управления БД.
Этапы проектирования базы данных
В процессе проектирования базы данных выделяют 3 основных этапа (уровня