Файл: 1. Что такое Maven Для чего он нужен Как добавлять в проект библиотеки без него.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 30.11.2023
Просмотров: 398
Скачиваний: 6
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
1. Что такое Maven? Для чего он нужен? Как добавлять в проект библиотеки без него?
Что такое Maven?
Для чего он нужен?
Как добавлять в проект библиотеки без него?
2. Как добавить dependency в Maven? Для чего они нужны? Откуда они скачиваются?
Как добавить dependency в Maven?
Для чего они нужны?
Откуда они скачиваются?
Параметры GAV. Что такое groupId и artifactId?
3. Основные фазы проекта под управлением Maven?
Особенность фаз clean и site
Пример передачи фаз:
4. Что такое JDBC? Какие классы/интерфейсы относятся к JDBC?
Что такое JDBC?
Какие классы/интерфейсы относятся к JDBC?
5. Для чего нужен DriverManager?
6. Что такое Statement, PreparedStatement, CallableStatement?
Что такое хранимая процедура?
7. Что такое sql-injection?
Как защитить приложение от sql-injection?
Отличие Statement от PreparedStatement?
8. Что такое ResultSet? Как с ним работать?
Что такое ResultSet?
Как с ним работать?
Как с помощью ResultSet получить данные из 2 строки 2 колонки таблицы?
Методы и их описание
9. Рассказать про паттерн DAO
Должен состоять из:
Особенности использования паттерна DAO:
Преимущества использования паттерна DAO:
10. Что такое JPA?
11. Что такое ORM?
Преимущества ORM в сравнение с JDBC:
12. Что такое Hibernate?
Зачем нужен:
13. В чем разница между JPA и Hibernate? Как связаны все эти понятия?
14. Какие классы/интерфейсы относятся к JPA/Hibernate?
15. Основные аннотации Hibernate, рассказать.
16. Чем HQL отличается от SQL?
Преимущества HQL:
Недостатки HQL:
17. Что такое Query? Как передать в объект Query параметры?
Что такое Query?
Как передать в объект Query параметры?
18. Какие можно устанавливать параметры в hbm2ddl, рассказать про каждый из них.
19. Требования JPA к Entity-классам? Не менее пяти.
20. Жизненный цикл Entity в Hibernate? Рассказать.
1. Что такое Maven? Для чего он нужен? Как добавлять в проект библиотеки без него?
Что такое Maven?
(Apache) Maven — это инструмент для автоматизации сборки и управления зависимостями проектов.
Для чего он нужен?
Maven обеспечивает простой способ определения зависимостей (указывая их в файле pom.xml (Project Object Model)), позволяет автоматически скачивать и добавлять в проект все необходимые библиотеки и плагины, координировать их версии, (создавать и) управлять жизненным циклом проекта, (а также создавать документацию).
Как добавлять в проект библиотеки без него?
Чтобы добавить библиотеку в проект без Maven нужно скачать jar-файлы библиотеки и добавить его в папку (lib) проекта, после чего добавить их в проект используя IDE. Также нужно убедиться, что установлены все необходимые зависимости и конфигурации для работы библиотек.
(Чтобы добавить библиотеку в проект без использования Maven нужно:
1) Скачать jar-файл библиотеки из интернета;
2) Поместите jar-файл в каталог lib проекта;
3) Добавьте этот файл как класс path используемого IDE.
4) Использовать импорты со стандартным способом import com.example.library.*)
2. Как добавить dependency в Maven? Для чего они нужны? Откуда они скачиваются?
Как добавить dependency в Maven?
Для добавления зависимости в Maven нужно отредактировать файл pom.xml (Project Object Model) в корне проекта. В этом файле нужно добавить блок
(В Maven библиотека называется (является) артефактом и имеет groupId, artifactId и version.)
(Например, чтобы добавить библиотеку Gson версии 2.8.6, нужно добавить следующий блок кода:
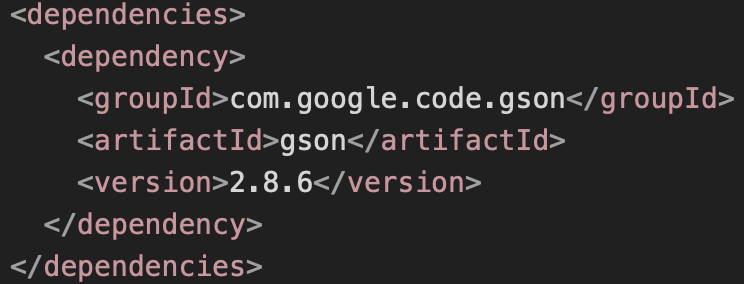
Таким образом, мы указываем, что нам нужна зависимость с groupId равным com.google.code.gson, artifactId равным gson и version равной 2.8.6.)
Для чего они нужны?
Зависимости в Maven нужны для того, чтобы проект мог использовать функциональность, которая реализована в сторонних библиотеках. Без использования зависимостей разработчикам пришлось бы реализовывать все необходимые функции самостоятельно.
Откуда они скачиваются?
Зависимости скачиваются из удаленного репозитория при сборке проекта. По умолчанию Maven использует центральный репозиторий, где находятся большинство популярных библиотек. Также можно использовать другие репозитории, как локальные, так и удаленные. Если нужной зависимости нет в центральном репозитории, Maven попытается скачать ее из другого указанного репозитория.
Стоит еще раз упомянуть Мавен-репозиторий, потому что их на самом деле у нас два — внешний (глобальный) и локальный, у тебя на компьютере.
Все библиотеки, которые ты добавляются в проекты, сохраняются в локальном репозитории. Когда Maven добавляет необходимую зависимость в проект, он сначала проверяет локальный репозиторий на наличие библиотеки, и только если не находит её там — обращается к внешнему.
(добавить зависимость в локальный репозиторий можно командой mvn install:install-file)
(Если зависимость не найдена в локальном кэше пользователя, то она будет загружена из удаленного репозитория при первом использовании.)
Параметры GAV. Что такое groupId и artifactId?
(groupId и artifactId — это два основных идентификатора, которые используются для идентификации зависимостей в Maven.)
groupId - это уникальный идентификатор группы, к которой относится проект или библиотека. Он часто используется для идентификации организации или команды, которая создала проект или библиотеку.
artifactId - это уникальный идентификатор проекта или библиотеки. Он используется для идентификации конкретного артефакта, созданного группой, которая указана в groupId.
version - версия описываемого объекта. Для незавершенных проектов принято добавлять суффикс SNAPSHOT. (Например, 1.0.0-SNAPSHOT.)
(Например, если у вас есть проект, который создан командой "myteam" и имеет название "myproject", вы можете задать groupId как "com.myteam" и artifactId как "myproject".)
3. Основные фазы проекта под управлением Maven?
Процесс построения приложения называют жизненным циклом Maven-проекта, и состоит он из фаз (phase). Посмотреть на них ты можешь в IDEA, нажав на Maven - example - Lifecycle в правом верхнем углу.
Все фазы выполняются последовательно: нельзя запустить, скажем, четвертую фазы, пока не завершены фазы 1-3.
1) clean — удаляются все скомпилированные файлы из каталога target (место, в котором сохраняются готовые артефакты) (необязательна);
2) validate — идет проверка, вся ли информация доступна для сборки проекта;
3) compile — компилируются файлы с исходным кодом;
4) test — запускаются тесты;
5) package — упаковываются скомпилированные файлы (в jar, war и т.д. архив);
6) verify — выполняются проверки для подтверждения готовности упакованного файла;
7) install — пакет помещается в локальный репозиторий. Теперь он может использоваться другими проектами как внешняя библиотека;
8) site — создается документация проекта (необязательна);
9) deploy — собранный архив копируется в удаленный репозиторий.
Также у каждой фазы есть пре- и пост-фазы: например, pre-deploy, post-deploy, pre-clean, post-clean, но используются они довольно редко.
Кроме этого, у каждой фазы есть цели (goal). Стандартные цели заложены по умолчанию, дополнительные добавляются Maven-плагинами.
Особенность фаз clean и site
Фазы clean и site не выполняются, если специально не указаны в строке запуска. (Если бы clean было частью обычного жизненного цикла, проект подвергался бы чистке при каждом построении, что нежелательно.)
Пример передачи фаз:
mvn package - при этом все предыдущие фазы выполнятся, а последующие нет.
mvn deploy - выполнятся все фазы.
mvn clean package site - можно передавать сразу несколько фаз.
(Стандартные жизненные циклы могут быть существенно дополнены Maven-плагинами и Maven-архетипами.)
4. Что такое JDBC? Какие классы/интерфейсы относятся к JDBC?
Что такое JDBC?
JDBC (Java Database Connectivity) — это стандартный интерфейс для взаимодействия Java-приложений с реляционными базами данных. Он позволяет (программистам) использовать SQL-запросы для доступа к данным и управления ими.
(JDBC реализован в виде пакета java.sql, входящего в состав Java SE.)
Какие классы/интерфейсы относятся к JDBC?
java.sql.Driver - интерфейс, (который должен быть реализован любым классом, представляющим драйвер JDBC.) Отвечает за связь с БД. Напрямую работать с ним нам приходится крайне редко. Вместо этого мы чаще используем объекты DriverManager, которые управляют объектами этого типа.
java.sql.DriverManager - класс, управляет списком драйверов БД. Каждый запрос на соединение требует соответствующего драйвера. Первое совпадение даёт нам соединение.
1. java.sql.Connection - интерфейс, объект которого отвечает за соединение с БД (и режим работы с ней). Все взаимодействия с БД происходят исключительно через Connection.
2. java.sql.Statement - интерфейс, который предоставляет методы для выполнения SQL-запросов и получения результатов. Создаёт объект типа ResultSet, который содержит результаты запроса. Передаём в него либо Update либо Query.
java.sql.PreparedStatement - интерфейс, который предоставляет методы для выполнения предварительно скомпилированных SQL-запросов. Позволяет сделать некий шаблон запроса, подставлять в него какое-то значение и использовать его. Безопасен от SQL-инъекций.
java.sql.CallableStatement - предоставляет возможность вызова хранимой процедуры, расположенной на сервере, из Java™ - приложения. которые могут принимать входные параметры и возвращать выходные параметры. Добавляет методы для манипуляции выходными параметрами.
3. java.sql.ResultSet - интерфейс, который предоставляет методы для работы с результатами выполнения SQL-запросов. Экземпляры этого элемента содержат данные, которые были получены в результате выполнения SQL – запроса. Он работает как итератор и “пробегает” по полученным данным. Объект с результатом запроса, который вернула база. Внутри него таблица.
java.sql.SQLException - класс, который обрабатывает все исключения, которые могут возникнуть при работе с БД.
(java.sql.Types - класс, который содержит константы, определяющие различные типы данных в JDBC.